一种基于稀疏时间序列数据的事件发生时间预测方法
1.本发明涉及机器学习技术,特别涉及基于时间序列数据的事件预测技术。
背景技术:
2.时间序列数据是一串按时间维度索引的数据,这类数据描述了某个被测量的主体在一个时间范围内的每个时间点上的测量值。对时序数据通常会包含三个部分,分别是:主体,时间点和测量值。稀疏表示的目的就是在给定的超完备字典中用尽可能少的原子来表示信息,可以获得信息更为简洁的表示方式,从而使我们更容易地获取信号中所蕴含的信息,更方便进一步对信号进行加工处理。基于稀疏时间序列数据的事件发生时间预测,用于根据稀疏表示的时间序列数据来预测某个时间在指定时间是否发生,该应用在生活中无处不在,从对自然环境、人体行为或者身体机能各方面的事件的判断上,比如天气预报与各种预警系统。
3.机器学习在时序数据预测上有很多的成果,在这方面应用最广泛的是循环神经网络。但是循环神经网络对数据的要求较高,需要数据是连续且不能存在空值,而且现有的循环神经网络模型都存在特异度较高而灵敏度较低的问题。其他还有随机森林和梯度提升树等模型,虽然模型的精度较高,但是无法处理时间序列数据,或者需要根据数据本身的特点手动构造,在不同的时间序列数据中无法通用,处理过程非常繁琐。
技术实现要素:
4.本发明所要解决的技术问题是,提供一种自动构造基于时间序列数据的特征来进行事件是否发生的预测方法。
5.本发明为解决上述技术问题所采用的技术方案是,一种基于稀疏时间序列数据的事件预测方法,包括:
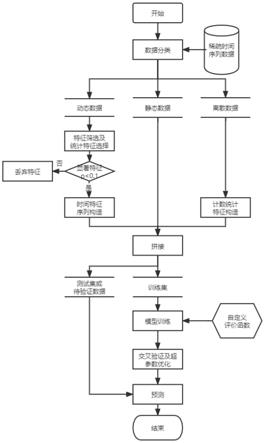
6.s1.对稀疏时间序列数据进行数据分类,将在观测时间长度内未发生变换的作为静态数据,持续随时间变化的作为动态数据,间断出现且只有0与1两种状态的作为离散数据;
7.s2.按数据类别进行特征提取:
8.对于静态数据,选取与事件相关的特征作为静态数据特征;
9.对于动态数据,先按事件是否发生进行分组,再对各动态数据提取数据特征,再计算数据特征的置信度,再按保留置信度小于0.1的数据特征的方式进行筛选;筛选后的数据特征作为原始动态特征,再将原始动态特征对应时间点之前的一段时间的数据特征作时序特征,原始动态特征和其对应的时序特征合并为最终的动态数据特征;
10.对于离散数据,先对离散数据进行独热编码作为离散数据的原始离散特征,再对每个原始特征统计在对应时间点之前的原始特征出现次数作为计数特征,原始离散特征和其对应的计数特征合并为最终的离散数据特征;
11.s3.将同一时间点的静态数据特征、时间特征序列和离散数据特征进行拼接形成
模型的输入特征,再按照事件是否发生进行贴标后形成训练数据;将观测时间内的训练数据形成训练集输入至事件发生预测模型中进行训练;
12.s4.将待预测的稀疏时间序列数据通过s1-s2步骤,将同一时间点的静态数据特征、时间特征序列和离散数据特征进行拼接形成模型的输入特征输入至训练完成的事件发生预测模型中,事件发生预测模型输出对应时间点是否发生事件的预测结果。
13.进一步的,事件发生预测模型由多个子模型组成,在事件发生预测模型训练过程中,使用多折交叉验证方法将训练集输入多个子模型训练,采用自定义评价函数和贝叶斯超参数优化训练子模型,并使用多个子模型输出的均值作为最后的预测值;
14.本发明方法运用统计特征筛选,以简单时间相关来构造特征。本发明的有益效果是:
15.(1)使用统计特征选择找出对模型具有显著影响的单维特征,排除了显著不相关的单个特征对最终预测模型性能可能带来的影响;
16.(2)简化特征构造方式,只需要构造简单时间特征和计数特征,避免了对每一个特征进行单独分析处理的麻烦,降低了特征选择的时间以及计算资源的消耗;
17.(3)使用梯度提升树作为基学习器并使用多折交叉验证,能更充分地学习数据特征之间的关系,从而提高模型的鲁棒性;
18.(4)使用自定义的目标函数和评价指标,提高了模型预测的精度;
19.(5)整个特征构造和训练步骤不涉及到具体某一个特征的处理方式,在不同的时间序列数据上都可以进行处理,并且精度相比于其他方法都有提升。
20.因此,本发明有比较明显的优势和较广泛的适用场景。
附图说明
21.图1为实施例流程图;
22.图2为实施例动态特征筛选流程;
23.图3为实施例的模型训练流程。
具体实施方式
24.下面进一步说明本发明的技术方案,但本发明所保护的内容不局限于以下所述。
25.基于稀疏时间序列数据的事件发生时间预测方法,包括了统计特征筛选、模型特征构造、自定义目标函数和评价函数等方法和步骤。利用简单的时间特征构造方式和新的目标函数,可以有效提高模型预测精度并解决模型特征无法通用的问题。
26.为了实现发明,如图1所示,具体包括以下步骤:
27.s1.对稀疏时间序列数据进行数据分类,将在观测时间长度内未发生变换的作为静态数据,持续随时间变化的作为动态数据,间断出现且只有0与1两种状态的作为离散数据;
28.s2:统计特征筛选和构造阶段
29.对于静态数据,选取和事件相关的特征作为静态特征fd;
30.对于动态数据,对训练数据按事件是否发生分组,检验不同分组中fi变量分布是否有显著差异,并构造时间序列特征,其执行过程如图2所示:
31.s201:若fi无法使用数字进行量化或者观测次数少于总事件发生次数则丢弃该特征。
32.s202:对于每一个特征fi,对分组之前的训练数据总体中使用ks检验fi分布是否服从正态分布。
33.s203:若服从正态分布(p》0.1,p值代表假设服从正态分布的概率,越小则说明原假设越不成立),则对分组之后的训练数据使用独立样本的t检验计算置信度值p;否则,使用mann-whitney u检验计算p值;
34.s204:如果fi统计检验p值小于0.1,则将fi加入已选择特征集合fm;
35.s205:对集合fm中每一个特征fi,设当前时间点为t,当前时间点的特征值为fi(t),添加新的特征fi(t-2),fi(t-4),fi(t)-fi(t-1),fi(t-1)-fi(t-3)作为输入模型所需特征,新特征和原始特征合并为最终特征集合f
mt
;
36.对离散的动态数据,添加计数特征:对于离散数据特征集合fn中每一个特征fj,设当前时间点为t,则当前时间点的特征值为fj(t),计算当前时间点之前特征计数总和添加当前时间点之前特征的次数总和作为计数特征,计数特征f
cj
(t)和原始特征fj(t)合并为最终特征f
nt
。
37.利用统计特征筛选特征以及和时间特征构造的方法,简化特征构造方式来提高模型实用性以及模型的预测精度。
38.s3:模型训练和预测阶段
39.对统计特征选择出来的集合fd、f
mt
、f
nt
进行拼接形成输入特征,再对输入特征贴标签形成训练数据,将采集到的训练数据形成训练集,结合应用梯队提升树学习方法,使用自定义目标函数训练事件发生预测模型由多个子模型组成,,事件发生预测模型由多个子模型组成,执行过程如图3所示:
40.s301:采用多折交叉验证训练多个子模型。在每一折内,由于训练数据事件发生和不发生的占比差距可能很大,所以对输入数据进行下采样使发生事件的数据条目数和未发生事件数据条目数相等。
41.s302:采用多折交叉验证训练多个模型。每一折内使用自定义目标函数sllse进行训练。sllse定义如下:f(y
p
,y
l
)=α(log(y
p
+1)-log(y
l
+1))2+(1-α)log((y
p-y
l
)2+1)。其中y
p
为预测值,y
l
为真实值,α为超参数,用于调节两个误差之间的比值,范围取0到1之间。sllse的一阶导数和二阶导数如下:
[0042][0043][0044]
相应的评价指标变为:
[0045]
其中n代表参与评价指标计算的总样本数。
[0046]
s303:训练好的子模型进行预测时将每一个模型的预测值求和取平均作为最终结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1