一种车型车架号检测与识别的方法
1.本发明涉及光学字符检测识别领域,特别涉及一种车型车架号检测与识别的方法。
背景技术:
2.据有效数据显示,我国汽车保有量为全球第一,增长量也稳居前列,汽车产业正在迅速 地发展起来,与汽车相关的行业也在不断地发展。同时,汽车相关的智能产业也在逐步发展, 将机器学习等新型领域的知识带入到车辆行业的工作之中,能够极大的减轻部分重复性的工 作量。
3.车架号,即车辆识别号码(vehicle identification number),简称vin,是一组由十七位 字母或数字组成,用于汽车上的一组独一无二的号码,可以识别汽车的生产商、引擎、底盘 序号及其他性能等资料。作为车辆的识别身份证,其印刻在车身的多个位置,例如:发动机 舱附件、仪表盘附近、挡风玻璃附近。
4.当前使用的众多方法主要针对于仪表盘和挡风玻璃处的车架号识别。由于缺乏合适的图 像采集设备,采集人员收集车架号较为困难。由于收集方式的限制,需要检验的车辆车架号 往往印刻在不容易获取的地方,由于角度的限制,很难让工作人员规范的收集数据,只能通 过手机等工具进行简易拍摄,致使车架号图像的角度不一,这给我们的工作带来了一定的难 度;而且由于车身大多是金属,致使车架号存在区域腐蚀严重,且由于人工拍摄需要闪光灯, 反光也让车架号的存在识别不清的问题;另外,不同车型的字体、间隔等均有所差距。这些 问题都容易造成车架号识别不清或者无法识别的情况出现。
技术实现要素:
5.针对现有技术存在的上述问题,本发明要解决的技术问题是:由于拍摄角度不同或者车 辆自身条件造成对被识别图片上的信息识别不清的问题。
6.为解决上述技术问题,本发明采用如下技术方案:一种车型车架号检测与识别的方法, 包括如下步骤:
7.s1:构建车架号检测与识别模型,所述车架号检测与识别模型包括文本检测模块,文本 方向分类模块和字符识别模块三个模块;
8.文本检测模块用于确定车架号在图像区域,并确定车架号在图像区域四角的坐标;
9.文本方向分类模块用于将车架号所在图像区域外的部分裁减掉,并对车架号所在图像区 域进行角度对齐,使车架号所在图像区域内的字符处于正立状态;
10.字符识别模块用于对经过角度对齐后的车架号所在图像区域进行识别并输出识别的字符;
11.s2:对字符识别模块进行预训练得到次优字符识别模块;
12.s3:分别对文本检测模块,文本方向分类模块和次优字符识别模块进行训练得到
最优文 本检测模块,最优文本方向分类模块和最优字符识别模块;
13.s4:将待检测车辆的车架号图片依次输入最优文本检测模块,最优文本方向分类模块和 最优字符识别模块,得到该待检测车辆的17位车架号。
14.作为优选,所述s2对字符识别模块进行预训练得到次优字符识别模块的具体步骤如下:
15.s21:通过text_renderer工具生成的数据集q作为预训练样本数据集,预训练样本数据集 中的数据为模拟数据,该模拟数据包括生成的模拟图片和模拟图片对应的17位字符,所述 17位字符为模拟17位车架号的字母和/或数字,所述17位字符为模拟17位车架号的字母和/ 或数字,将一张模拟图片中17位字符打上标签,一张模拟图片和对应的17位标签作为一个 预训练样本;
16.s22:根据车架号的特性生成字典文件,该字典文件这是一个包含了车架号中可能出现的 所有字符的文本文件;
17.s23:初始化字符识别模块中的参数;
18.s24:将预训练样本数据集中的所有预训练样本顺序打乱,将所有预训练样本平均分为n 个batch;
19.s25:将一个batch中的所有预训练样本全部输入字符识别模块中,对于每个预训练样本 会得到m个包含所有字符概率分布y
t
,y
t
表示第t个字符被识别为字典中的所有字符的概 率,这些字符概率之和为1,取最大概率值对应的字符作为t位置的识别字符,t=1,2,
…
17, 所有的y
t
构成后验概率矩阵,作为损失函数的输入;
20.s26:计算当前batch的损失,方法如下:
21.将当前batch中所有预训练样本和s25得到的每个预训练样本的后验概率矩阵输入到ctc 的损失函数进行损失求解,得到当前batch的损失;
22.s27:判断是否到达最大迭代次数,如果到达最大迭代次数则当前化字符识别模块即为次 优化字符识别模块,否则,否则根据s25计算的当前batch的损失,采用梯度下降法反向传 播更新字符识别模块的参数,并返回s24。
23.作为优选,所述s3训练文本检测模块得到最优文本检测模块的过程如下:
24.s311:获取多张真实车辆的车架号图片组成车架号图片集a,对a内的图片人工打上标 签即车架号所在图像区域和车架号所在图像区域四角的坐标,a中的一张图片和对应的标签 作为一个一号样本,所有一号样本构成一号样本数据集;
25.s312:初始化文本检测模块的参数;
26.s313:将一号样本数据集中的一号样本顺序打乱,将所有一号样本平均分为m个batch;
27.s314:将一个batch中所有一号样本全部输入文本检测模块中,每个一号样本在文本检 测模块的检测过程中会得到一个阀值图、一个概率图,根据阈值图和概率图,利用db公式 最终得到每个一号样本的文本概率分布二值图;
28.s315:将一个batch中所有一号样本的标签与对应的图片结合生成对应该一号样本的gt 图,即ground-truth图,用于标注真实的文本区域像素点的分布;
29.s316:计算当前batch中s314输出的一号样本的文本概率分布二值图与对应一号样本的 gt图的损失;
30.s317:判断是否到达最大迭代次数,如果到达最大迭代次数则当前文本检测模块即为最 优文本检测模块,否则根据当前batch的损失采用梯度下降法反向传播更新文本检测模块的 参数,并返回s314。
31.作为优选,所述s3训练文本方向分类模块得到最优文本方向分类模块的过程如下:
32.s321:获取多张真实车辆的车架号图片组成车架号图片集b,对b内的图片人工标注架 号所在图像区域和车架号所在图像区域四角的坐标,并根据车架号所在图像区域中字符的正 反人工打上0或1的标签,其中0表示b内的图片为0
°
,即图片中的字符为正态,不需要旋 转,1表示b内的图片为180
°
,即图片中的字符为倒立态,需要旋转;
33.b中的一张图片和对应的标签作为一个二号样本,所有二号样本构成二号样本数据集;
34.s322:初始文本方向分类模块的参数;
35.s323:将二号样本数据集中的二号样本顺序打乱,将所有二号样本平均分为n个batch;
36.s324:将一个batch中的所有二号样本全部输入文本方向分类模块中,得到每个二号样 本的输出值,输出值位于0到1之间,当输出值大于我们设定的阈值,设定文本方向分类模 块的输出为1,反之为0;
37.s325:计算当前batch中每个二号样本的输出值与对应二号样本标签的损失;
38.s326:判断是否到达最大迭代次数,如果到达最大迭代次数则文本方向分类模块即为最 优文本方向分类模块,否则根据当前batch的损失采用梯度下降法反向传播更新字符识别模 块的参数,并返回s324。
39.作为优选,所述s3训练次优字符识别模块得到最优字符识别模块的过程如下:
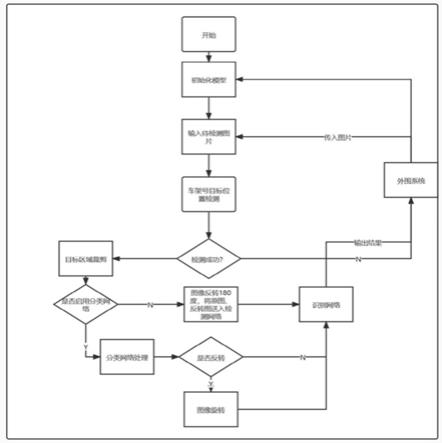
40.s331:获取多张真实车辆的车架号图片组成车架号图片集c,对c内的图片人工标注车 架号所在图像区域,按照车架号所在图像区域对c中的图片进行截取,然后将截取的所有图 片进行旋转,确保截取的每张图片中的字符都处于正态;
41.将每张字符处于正态的截取的图片,将该截取的图片中的17位字符打上标签,截取的图 片和对应的17位标签为作为一个三号样本,所有三号样本构成三号样本数据集;
42.s332:将三号样本数据集中的所有三号样本顺序打乱,将所有三号样本平均分为p个batch;
43.s333:将一个batch中的所有三号样本全部输入字符识别模块中,对于每个三号样本会 得到m个包含所有字符概率分布y
t
,y
t
表示第t个字符被识别为字典中的所有字符的概率, 这些字符概率之和为1,取最大概率值对应的字符作为t位置的识别字符,t=1,2,
…
17,所有 的y
t
构成后验概率矩阵,作为损失函数的输入;
44.s334:计算当前batch的损失,方法如下:
45.将当前batch中所有三号样本和s233得到的每个三号样本的后验概率矩阵输入到ctc的 损失函数进行损失求解,得到当前batch的损失;
46.s335:判断是否到达最大迭代次数,如果到达最大迭代次数则当前次优化字符识别模块 即为最优化字符识别模块,否则根据s334计算的当前batch的损失,采用梯度下降法反向传 播更新次优字符识别模块的参数,并返回s333。
47.作为优选,所述文本检测模块采用的是db检测网络模型。
48.作为优选,所述文本方向分类模块采用的是mobilenetv3网络模型。
49.作为优选,所述字符识别模块采用的是crnn网络模型。
50.相对于现有技术,本发明至少具有如下优点:
51.1.本发明是将机器学习与发动机位置的车架号识别结合起来的方法,针对性的解决在车 辆测试、年检等过程中,位于发动机位置的车架号难以识别的问题。本发明提出的方法中文 本检测模块,文本方向分类模块和字符识别模块均可更换,可以随时引入新的网络以提升模 型的效果。
52.2.针对车架号角度多样不一,本发明将文本检测模块引入到对车架号检测中,在已有数 据的情况下,为了增强检测网络鲁棒性,采取了针对文本检测的数据增强策略。针对车架号 图像的特点以及检测的需求,将网络的输出的位置信息限制在一个车架号,提升了检测结果 的准确性。
53.3.针对检测网络输出图像可能反向的问题,本发明将分类网络引入到对截取车架号图像 的分类之中,用二分类的方法解决图片存在的角度问题。本发明采用了轻量级的网络,降低 网络计算量,加快了检测时间。
54.4.针对文本识别的任务,本发明使用端到端的识别方法对字符进行识别,综合了识别的 准确率与推理速度。
附图说明
55.图1为本发明运行流程图。
56.图2为文本检测模块文本检测网络输出的二值图
57.图3为文本检测模块筛选检测结果函数的函数图。
58.图4为人工拍摄的待检测的车架号原始图像,框内即为车架号。
59.图5为经过文件检测模块调整大小后车架号图像。
60.图6为文本检测模块文本检测网络输出的概率图。
61.图7为文本检测模块文本检测网络输出的二值图。
62.图8为文本检测网络输出结果切割后的图片。
具体实施方式
63.下面结合附图对本发明作进一步详细说明。
64.一种车型车架号检测与识别的方法,包括如下步骤:
65.s1:构建车架号检测与识别模型,所述车架号检测与识别模型包括文本检测模块,文本 方向分类模块和字符识别模块三个模块;具体的,所述文本检测模块采用的是db检测网络 模型,所述文本方向分类模块采用的是mobilenetv3网络模型,所述字符识别模块采用的是 crnn网络模型。
66.文本检测模块用于确定车架号所在图像区域,并确定车架号所在图像区域四角的坐标;
67.文本方向分类模块用于将车架号所在图像区域外的部分裁减掉,并对车架号所在图像区 域进行角度对齐,使车架号所在图像区域内的字符处于正立状态;
68.字符识别模块用于对经过角度对齐后的车架号所在图像区域进行识别并输出识别的字符;
69.具体的,文本检测模块采用db检测网络,文本检测模块用于对输入网络的原始图片进 行文本区域检测,以确定车架号在图像区域所处的位置,通过文本检测模块得到车架号所在 车架号所在图像区域,并返回矩形区域的四点坐标。
70.文本方向分类模块采用mobilenetv3网络,文本方向分类模块用于根据文本检测网络返 回的坐标,对原图进行裁减,裁剪之后的图像输入到本网络中,网络判断齐角度,即0
°
或180
°
, 0
°
表示裁剪后图像中的字符处于正立状态,180
°
表示裁剪后图像中的字符处于倒立状态,如 果裁剪后的图像为180
°
,则对其进行旋转,使其成为0
°
。
71.字符识别模块采用crnn网络,字符识别模块用于对文本方向分类网络输出的图像进行 文本内容的识别,最终输出车架号图片包含的17位字符。文本识别模块的字典长度为37, 即(10位数字,26位大写字母以及空格),把文本识别看成分类的话,字典便是分类的类别。 输出的字符只能是字典中的符号。
72.s2:对字符识别模块进行预训练得到次优字符识别模块。
73.s3:分别对文本检测模块,文本方向分类模块和次优字符识别模块进行训练得到最优文 本检测模块,最优文本方向分类模块和最优字符识别模块;文本检测模块,文本方向分类模 块和优字符识别模块可以同时训练,也可以依次训练。
74.s4:将待检测车辆的车架号图片依次输入最优文本检测模块,最优文本方向分类模块和 最优字符识别模块,得到该待检测车辆的17位车架号。
75.具体的,文本检测模块中的检测网络输出概率图,经过后处理操作将网络输出的概率图 转换成点坐标信息。后处理操作是本领域常见的现有技术。
76.最优文本方向分类模块根据得到的四个点的坐标信息对待检测车辆的车架号图片进行裁 剪,将获得的裁剪后图片送入到最优文本方向分类模块,根据分类结果确定是否旋转,即当 输出的分类结果为180
°
则旋转-180
°
,当输出的结果为0
°
,则不操作,确保输入最优字符识别 模块的图片中的所有字符都处于正立状态。最终,将旋转好的图片送入到最优字符识别模块, 最优字符识别模块输出该待检测车辆的17位车架号。
77.具体的,所述s2对字符识别模块进行预训练得到次优字符识别模块的具体步骤如下:由 于文本识别模块的训练缓慢且难以收敛,因此可以对文本识别模块先进行预训练,最后再利 用真实数据集对预训练后的文本识别模型进行微调,以获得最优文本识别模型。
78.s21:通过text_renderer工具生成的数据集q作为预训练样本数据集,预训练样本数据集 中的数据为模拟数据,该模拟数据包括生成的模拟图片和模拟图片对应的17位字符,所述 17位字符为模拟17位车架号的字母和/或数字,将一张模拟图片中17位字符打上标签,一张 模拟图片和对应的17位标签作为一个预训练样本;数据集q内有50万张以上模拟记录有真 实车架号的图片,为了方便区分将通过text_renderer工具生成的图片记为模拟图片),这些数 据集在形式上与车架号数据集类似,以帮助文本识别算法的学习。
79.s22:根据车架号的特性生成字典文件,该字典文件这是一个包含了车架号中可能出现的 所有字符的文本文件;在本发明中,该字典文件是指26位大写字母和10位数字,以及1位 空格字符,字符总个数为37。
80.s23:初始化字符识别模块中的参数;
81.s24:将预训练样本数据集中的所有预训练样本顺序打乱,将所有预训练样本平均分为n 个batch,n=预训练样本总数/batch。
82.s25:将一个batch中的所有预训练样本全部输入字符识别模块中,对于每个预训练样本 会得到m个包含所有字符概率分布y
t
,y
t
表示第t个字符被识别为字典中的所有字符的概 率,这些字符概率之和为1,取最大概率值对应的字符作为t位置的识别字符,t=1,2,
…
17, 所有的y
t
构成后验概率矩阵,作为损失函数的输入;
83.s26:计算当前batch的损失,方法如下:
84.将当前batch中所有预训练样本和s25得到的每个预训练样本的后验概率矩阵输入到ctc 【ctc即connectionist temporal classification是一种现有方法】的损失函数进行损失 求解,得到当前batch的损失;
85.s27:判断是否到达最大迭代次数,如果到达最大迭代次数则当前化字符识别模块即为次 优化字符识别模块,否则,否则根据s25计算的当前batch的损失,采用梯度下降法反向传 播更新字符识别模块的参数,并返回s24。
86.具体的,所述s2训练文本识别模块得到次优文本识别模块的过程如下:
87.我们首先将截取的图像大小在保持长宽比的情况下缩放为(32,320,3),图像首先被送入主 干网络resnet34,以获取输入图像的特征,图像特征图的大小为(1,80,512)。
88.特征x=(x1,x2,x3,
…
,x
t
)将进入双向rnn(blstm)网络,此时我们将双向rnn的最大 时间长度t设置为80,即有80个时间输入,每个输入的列向量维度为512,对应上文特征提 取网络的输出,即得到由m=80个包含所有字符概率分布y
t
构成的后验概率矩阵。
89.根据后验概率矩阵,和相应的文本标签我们便能得到对应的损失函数。loss=
ꢀ‑
inp(y|x)=∏p(pathk),代表x从序列到序列的映射函数变换后是文本y的所有路径集合, 其中x表示后验概率矩阵,y表示真实标签,p表示概率。
90.具体的,所述s3训练文本检测模块得到最优文本检测模块的过程如下:
91.s311:获取多张真实车辆的车架号图片组成车架号图片集a,对a内的图片人工打上标 签即车架号所在图像区域和车架号所在图像区域四角的坐标,a中的一张图片和对应的标签 作为一个一号样本,所有一号样本构成一号样本数据集;
92.s312:初始化文本检测模块的参数;
93.s313:将一号样本数据集中的一号样本顺序打乱,将所有一号样本平均分为m个batch;
94.s314:将一个batch中所有一号样本全部输入文本检测模块中,每个一号样本在文本检 测模块的检测过程中会得到一个阀值图、一个概率图,根据阈值图和概率图,利用db公式 最终得到每个一号样本的文本概率分布二值图;
95.s315:将一个batch中所有一号样本的标签与对应的图片结合生成对应该一号样本的gt 图,即ground-truth图,用于标注真实的文本区域像素点的分布;
96.s316:计算当前batch中s314输出的一号样本的文本概率分布二值图与对应一号样本的 gt图的损失;
97.s317:判断是否到达最大迭代次数,如果到达最大迭代次数则当前文本检测模块即为最 优文本检测模块,否则根据当前batch的损失采用梯度下降法反向传播更新文本检测模块的 参数,并返回s314。
98.所述s314得到的文本概率分布二值图可以表示为:
[0099][0100]
其中代表文本概率分布二值图中坐标(i,j)的像素值,p
i,j
代表坐标(i,j)概率,t
i,j
代表 坐标(i,j)阈值,k表示超参数,此即为db公式。
[0101]
然后计算概率图损失ls、阈值图损失l
t
和二值图损失lb,就具体计算公式如下:
[0102][0103][0104]
其中,s
l
为一号样本的图片上所有像素点的集合,yi为第i个一号样本的图片上像素点标 注信息,这些像素点的标注信息可能为1或0,1表示位于文本区域中,0表示或不位于文本 区域中,xi为当前文本检测模块输出,rd为阈值像素点的集合,为所有yi的集合,如果把可 视话即可成图2,白色区域代表文本区域,里面的点标注信息为1。这个部分的标注信息是 由上述认为标记文件的四个点生成的;
[0105]
ls和lb均采用二值交叉熵损失函数bceloss计算,lt为阀值图损失,采用l1 distance 损失的形式获得
[0106]
将一号样本的标注信息进行损失求解,表达式如下:
[0107]
l=ls+α
×
lb+β
×
l
t
[0108]
其中α和β均表示超参数,是人为设定的权重,可以分别设为1和10。
[0109]
具体的,所述s3训练文本方向分类模块得到最优文本方向分类模块的过程如下:
[0110]
s321:获取多张真实车辆的车架号图片组成车架号图片集b,对b内的图片人工标注车 架号所在图像区域和车架号所在图像区域四角的坐标,并根据车架号所在图像区域中字符的 正反人工打上0或1的标签,其中0表示b内的图片为0
°
,即图片中的字符为正态,不需要 旋转,1表示b内的图片为180
°
,即图片中的字符为倒立态,需要旋转;
[0111]
b中的一张图片和对应的标签作为一个二号样本,所有二号样本构成二号样本数据集;
[0112]
s322:初始文本方向分类模块的参数;
[0113]
s323:将二号样本数据集中的二号样本顺序打乱,将所有二号样本平均分为n个batchn= 二号样本总数/batch。
[0114]
s324:将一个batch中的所有二号样本全部输入文本方向分类模块中,得到每个二号样 本的输出值,输出值位于0到1之间,当输出值大于我们设定的阈值【具体可以将阈值设定 为0.5】,设定文本方向分类模块的输出为1,反之为0。
[0115]
s325:计算当前batch中每个二号样本的输出值与对应二号样本标签的损失。
[0116]
s326:判断是否到达最大迭代次数,如果到达最大迭代次数则文本方向分类模块即为最 优文本方向分类模块,否则根据当前batch的损失采用梯度下降法反向传播更新字
符识别模 块的参数,并返回s324。
[0117]
具体的,所述s3训练次优字符识别模块得到最优字符识别模块的过程如下:
[0118]
s331:获取多张真实车辆的车架号图片组成车架号图片集c,对c内的图片人工标注车 架号所在图像区域,按照车架号所在图像区域对c中的图片进行截取,然后将截取的所有图 片进行旋转,确保截取的每张图片中的字符都处于正态;
[0119]
将每张字符处于正态的截取的图片,将该截取的图片中的17位字符打上标签,截取的图 片和对应的17位标签为作为一个三号样本,所有三号样本构成三号样本数据集;
[0120]
s332:将三号样本数据集中的所有三号样本顺序打乱,将所有三号样本平均分为p个batch;
[0121]
s333:将一个batch中的所有三号样本全部输入字符识别模块中,对于每个三号样本会 得到m个包含所有字符概率分布y
t
,y
t
表示第t个字符被识别为字典中的所有字符的概率, 这些字符概率之和为1,取最大概率值对应的字符作为t位置的识别字符,t=1,2,
…
17,所有 的y
t
构成后验概率矩阵,作为损失函数的输入;s334:计算当前batch的损失,方法如下:
[0122]
将当前batch中所有三号样本和s233得到的每个三号样本的后验概率矩阵输入到ctc 【ctc即connectionist temporal classification是一种现有方法】的损失函数进行损失 求解,得到当前batch的损失;。
[0123]
s335:判断是否到达最大迭代次数,如果到达最大迭代次数则当前次优化字符识别模块 即为最优化字符识别模块,否则根据s334计算的当前batch的损失,采用梯度下降法反向传 播更新次优字符识别模块的参数,并返回s333。
[0124]
实施例:
[0125]
[训练的标注]
[0126]
文本检测是使用db网络进行检测,本方法的实现准备了40000张图片,使用 ppocrlabel图片标注软件进行标注,用于训练模型。同时,我们使用labelme工具对文 本方向分类数据集和文本识别数据集进行标注。
[0127]
[训练]
[0128]
本发明的组成主要有三个需要训练的网络,针对不同的网络,我们采取了不同的配置策 略。
[0129]
文本检测部分是使用db检测网络进行检测进行检测,本方法的实现准备了40000余张 图片,使用ppocrlabel图片标注软件进行标注,用于训练模型,训练集:测试集:验证集 =8:1:1。使用论文中给出的训练方法,在batch=16,的配置下使用服务器的nvidia 3090gpu 从学习率0.001开始,随着epoch的增加学习率阶梯衰减,在达到200epoch时学习率已经衰 减到之前的0.1倍,总共训练了200个epoch,达到了测试最高的准确度,输出文本最佳检测 模型。整个训练耗时20小时左右。
[0130]
文本分类部分是使用mobilenetv3网络进行文本方向分类,本方法的实现准备了10000 余张图片,使用labelme图片标注软件进行标注,用于训练模型,训练集:测试集:验证集 =8:1:1。使用论文中给出的训练方法,在batch=512,的配置下使用服务器的nvidia 3090 gpu从学习率0.001开始,随着epoch的增加学习率阶梯衰减,在达到400epoch时学习率 已经衰减到之前的0.1倍,总共训练了500个epoch,达到了测试最高的准确度,输出文本
最 佳检测模型。整个训练耗时10小时左右。
[0131]
文本识别部分是使用crnn网络进行文本识别,首先,我们需要在生成的文本数据集上 进行预训练,在nvidia 3090gpu,batch=512,从学习率0.001开始,训练20个小时,提 取最佳的模型作为预训练模型。其次,本方法的实现准备了30000余张图片,使用labelme 图片标注软件进行标注,用于微调模型,训练集:测试集:验证集=8:1:1。使用论文中给 出的训练方法,在batch=512,的配置下使用服务器的nvidia3090gpu从学习率0.001开 始,随着epoch的增加学习率阶梯衰减,在达到100epoch时学习率已经衰减到之前的0.1倍, 总共训练了200个epoch,达到了测试最高的准确度,输出文本最佳检测模型。整个训练耗时 5小时左右。
[0132]
获取先验知识。从数据集中使用polygon.area获取各个图像中车架号区域面积,算取平 均值s
avg
。同时,获取目标框长宽比的均值d
avg
。通过s
avg
=polygon.area(points)计算得到 的面积与先验面积作为一个判断条件,随着当前目标面积与先验面积比值越接近一,面积得 分area_socre越高。同时,随着当前目标长宽比与先验长宽比值越接近一,面积得分wh_socre 越高。其中越高。其中分别为位置分数和长宽比分数的系数,我们设置为2,1。
[0133][0134][0135][0136]
(1)文本检测模块。
[0137]
在推理过程中,预处理会将图5缩放到网络需要的固定的大小得到图5(640*640),调 整过后的图像首先被送入到检测网络db中,经过fpn网络进行特征下采样,对下采样的特 征依次上采样并于上一层的特征融合得到图像的最终特征图f,特征图的大小为 (batch,256,160,160)。
[0138]
f(batch,256,160,160)先经过卷积层,将通道压缩为输入的1/4,然后经过bn和激活层 relu,得到的特征图shape为(batch,64,160,160);将得到的特征图进行反卷积操作,卷积核 为(2,2),得到的特征图shape为(batch,256,320,320),此时为原图的1/2大小;再进行反卷积 操作,同第二步,不同的是输出的特征图通道为1,得到的特征图shape为(batch,640,640), 此时为原图大小。最后经过sigmoid函数,输出概率图,probability map。
[0139]
然后,我们可以使用概率图,即图7映射来生成文本边界框。边界区域形成过程包括三个步骤: (1)对概率映射进行恒定阈值(0.2)二值化,得到二值映射图8;(2)从二进制映射得到连 接区域(收缩文字区域);(3)收缩区域用偏移vatti clipping裁剪算法(vati1992)进行扩张。
[0140][0141]
最终得到需求的文本区域位置信息,即长方形矩形的四顶点坐标。通过输出的位置信息我们 可以对原图进行旋转切割并获得我们需要识别文本的剪切图图像,需要注意的是,由于车架 号的存在方向为0
°
到360
°
,最后旋转的图像可能为0
°
或180
°
,即正向或反
向,如图8。
[0142][0143]
vatti clipping裁剪算法中:d
′
为概率图的的边向外扩充的长度,其中a
′
、l
′
是收缩区域的 面积、周长,r
′
依经验设置为1.5(使得对应收缩比例r=0.4)。参数都是人为设定的。
[0144]
(2)文本分类模块
[0145]
在方向分类网络中,综合考虑时间和准确率,我们选取了mobilenetv3(small)作为我们 的分类网络,将裁剪后的原图大小调整为3*48*192以满足mobilenetv3的网络结构。我们设 置了“0”和“180”两个分类类别。
[0146]
将调整后的图形送入到分类网络中,图像经过多次卷积进行特征下采样,最终经过全连 接层获取检测的结果。根据分类网络的分类结果,我们将图像进行旋转映射变换,然后送入 到文本识别网络中对文本中的所有字符进行判别。
[0147]
(3)文本识别模块
[0148]
文本识别模块在结果对多个文本识别算法的测试之后,我们选取了crnn作为我们的文 本识别网络。我们首先将截取的图像大小在保持长宽比的情况下缩放为(32,320,3),图像首先 被送入主干网络resnet34,以获取输入图像的特征,图像特征图的大小为(1,80,512)。
[0149]
接下来,特征x=(x1,x2,x3,
…
,x
t
)将进入双向rnn(blstm)网络,此时我们将双向rnn 的最大时间长度t设置为80,即有80个时间输入,每个输入的列向量有dim=512。
[0150]
lstm的每一个时间片后接softmax,输出y是一个后验概率矩阵,定义为: y=(y1,y2,...,y
t
),对y每一列进行argmax()(即获取y
*
中分值最大的index)操作,获取index 之后即可与我们配置的字典文件进行对应,即可获得输出字符。
[0151]
预测值输入ctc,ctc通过对预测值中的所有字符排列组合,使用动态规划算法求出最 有可能的序列,以减少重复数字的出现,以达到对重复的字符进行去重的处理,获取最终的 预测结果。
[0152]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施 例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进 行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利 要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1