多层多口提升机的调度方法与流程
1.本发明涉及物流技术领域,尤其涉及提升机的调度方法。
背景技术:
2.随着工业生产及物流配送的优化升级,物流提升机的效率已经成为工业、物流行业关注的重点问题。提升机的运行效率一直是整个自动化运输体系的痛点,提高提升机的运行效率能够有效弥补智能物流运输的效率短板,实现自动化物流运输速度的整体攀升。
3.多层多口多任务的提升机优化控制本质是为调度问题,即多任务运行路径最优解问题。在最优解算法之中,常见的算法包括遗传算法、模拟退火算法、爬山算法、粒子群算法等。模拟退火算法局部搜索能力强,运行时间短,但缺乏全局搜索能力,容易受到参数影响。爬山算法原理简单、效率高,但对于多约束大规模问题往往无法得到最优解。粒子群算法适合求解数学问题,算法简单计算方便,但存在陷入局部最优的问题。遗传算法可以较好的处理约束,不受局部最优限制,全局搜索能力强,可以无限逼近全局最优解,但算法相对复杂,收敛能力较弱。
技术实现要素:
4.本发明所要解决的技术问题在于提供一种多层多口提升机的调度方法,其能实现提升机呼梯任务的高效分配,提高多层多口提升机的作业效率。
5.本发明实施例提供了一种多层多口提升机的调度方法,包括以下步骤:
6.获取呼梯任务;
7.若只有一组呼梯任务,则直接执行;若呼梯任务数量大于1且不大于m,则以接货距离总长最短为目标采用全排列算法确定各呼梯任务的执行顺序,按照确定的执行顺序执行多组呼梯任务,m等于5或6;若呼梯任务数量大于m,则以接货距离总长最短为优化目标,采用自适应遗传算法对呼梯任务的执行顺序进行优化,按照优化后的执行顺序执行多组呼梯任务。
8.本发明至少具有以下优点:
9.1、本发明实施例依据实时调度呼梯任务数,实时分配调度算法,当呼梯任务数数量较少时,采用全排列算法,当呼梯任务数数量较多时,采用遗传算法,采用组合算法的方式有效地实现了多层多口多任务提升机调度系统的控制时间、效率最优设计,解决了遗传算法在低任务数量时耗时过长、影响提升机整体工作效率地问题;
10.2、本发明实施例针对遗传算法在实际控制中表现出的重复收敛特性不佳,早熟现象严重,最大误差过大等问题,改进了遗传算法执行机制,充分优化了遗传算子的筛选,有效地提高了遗传算法的重复收敛特性,降低了最大误差,降低了早熟概率,满足了实际控制需求。
附图说明
11.图1示出了一种多层多口提升机的示意图。
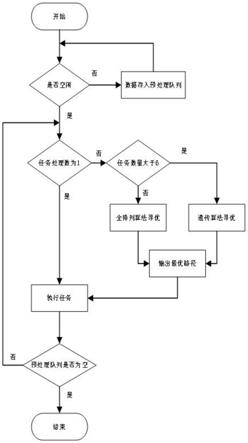
12.图2示出了根据本发明实施例的多层多口提升机的调度方法的流程示意图。
13.图3示出了全排列算法的原理示意图。
14.图4示出了根据本发明实施例的改进的遗传算法的示意图。
具体实施方式
15.图1示出了一种多层多口提升机的示意图。在图1的示例中,该提升机为多层双口提升机,系统的双边设计结构相同,图1仅示出了其单边结构,包含运输端、输送端以及操作台三部分,其中运输端为提升机轿厢内部分,输送端为过渡输送部分,部分现场有多节输送段。
16.提升机运行采用一货一梯模式,轿厢单次只运送一拖标准货物。用户通过操作台,录入货物运输楼层信息,并将货物置于输送线,完成货物运送楼层数据录入,提升机根据货物路径信息,将货物运输至指定楼层。
17.假定提升机运行前所在位置为a,n点运行任务起点终点坐标为(bn,cn),则n条任务的所有运行路径x
l
为:
18.x
l
=|a-b1|+|b
1-c1|+|c
1-b2|+
…
+|b
n-cn|
19.由于提升机采用一货一梯模式,每一条任务都需要完成接货、送货、出货一整套运输流程,且水平输送线运行节奏要远大于提升机运行节拍,因此不考虑提升机的加减速时间以及接货等待时间,仅从运行路程角度考虑提升机最优解问题。
20.根据提升机运行模型可知,无论调度任务如何分配,提升机任务系统内的运行距离都是固定的,受调度影响的距离仅为当前出货口至下一条任务进货口的距离,因此仅需对接货距离总长进行最优排序即可。接货距离总长xi:
21.xi=|a-b1|+|c
1-b2|+
…
+|c
n-1-bn|。
22.请参阅图2,根据本发明实施例的多层多口提升机的调度方法包括以下步骤:
23.获取呼梯任务;
24.若只有一组呼梯任务,则直接执行;若呼梯任务数量大于1且不大于m,则以接货距离总长最短为目标采用全排列算法确定各呼梯任务的执行顺序,按照确定的执行顺序执行多组呼梯任务,m等于5或6;若呼梯任务数量大于m,则以接货距离总长最短为优化目标,采用自适应遗传算法对呼梯任务的执行顺序进行优化,按照优化后的执行顺序执行多组呼梯任务。
25.在一个具体的实施方式中,本实施例的调度方法建立了呼梯任务预处理队列与任务执行队列,货物呼梯成功后,将根据提升机实际运行情况,动态处理呼梯任务。当提升机处于空闲状态,任一呼梯命令呼入之后,都将直接执行,不进行排序操作;若提升机处于运行状态,则新接收的呼梯请求将会暂存至任务预处理队列,待提升机当前任务执行完毕后,再进行呼梯任务排序处理。呼梯任务排序根据任务数量分三种情况:
26.1.只有一组呼梯任务,直接执行;
27.2.呼梯任务数量大于1且不大于6,执行全排列算法,最大720条排序计算,绝对最优。
28.3.呼梯任务数量大于6,采用改进的自适应遗传算法排序,计算数量主要由进化代数及任务数量决定,相对最优。
29.全排列算法是将所有呼梯任务可能发生的运行路径全部生成,随后以此计算其路径距离。全排列算法的基本原理如图3所示,以0,1,2三个数字为例,每一个数字代表一个元素(即一组呼梯任务),两个元素的排列有2种可能,即1,0/0,1两种;三个元素的全排列有6种队列,这6种队列的由来,可以想像成为将2这个元素,依次插入到1,0/0,1这两个已知的队列之中去,因此如图3所示,这6种队列将是:2,1,0/1,2,0/1,0,2/2,0,1/0,2,1/0,1,2。以此类推,当出现第四个元素的时候,将这个元素依次插入到这6组队列种,每组队列将产生4组新队列,由此可生成24组新队列。依此类推,可以完成任意位元素的全队列排序。按此逻辑完成所有呼梯任务的全排列数组后,代入路径距离,并利用冒泡算法,取出最优解。
30.本实施例采用组合算法的排序方式,可以在低任务数时,提高系统计算、执行效率,同时确保排序的最优解。当任务数量过大,若依然采用全排列算法将耗费巨大计算时长,因此根据计算条目,以6条任务为分界点,根据实时呼梯任务数,合理分配处理算法。
31.在本实施例中,所述的获取呼梯任务包括:
32.将接收到的呼梯请求作为呼梯任务放入任务队列中,呼梯请求包括进货楼层、出货楼层、进货口和出货口。
33.请参阅图4。本实施例中,采用自适应遗传算法对呼梯任务的执行顺序进行优化包括以下步骤:
34.s1、以一组呼梯任务执行顺序作为种群中的一个遗传个体,生成初始种群na;
35.s2、对初始化种群na进行优化,得到优化后的初始种群nc;
36.s3、对优化后的初始种群nc迭代地进行自适应遗传操作,直至满足预设的迭代终止条件,输出满足迭代终止条件时的最优解作为优化后的呼梯任务的执行顺序。
37.在本实施例中,上述的步骤s1具体包括:
38.生成染色体:pi=(bi,ci),bi为第i个呼梯任务的进货楼层,ci为第i个呼梯任务的出货楼层,1≤i≤n,n为呼梯任务总数;
39.根据呼梯任务排序,生成作为所述遗传个体的基因:p
j’={p1,p2…
pn};
40.生成初始种群na:na={p1’
,p2’
...p
m’};m为种群规模。
41.在本实施例中,上述的步骤s2具体包括:
42.对初始种群na进行单次遗传操作,得到新的种群nb,将种群规模为m的na与种群规模为m的nb混合,择优输出种群规模为m的新初始种群nc。
43.上述的择优输出种群规模为m的新初始种群nc包括以下步骤:
44.计算混合种群(混合种群的规模为2m)的平均适应度,高于平均适应度的基因进入下一代种群nc,低于平均适应度的基因被丢弃;若提前满足种群规模(即已经选出了m个基因)则终止选取;若混合种群剩余待挑选基因的总数等于新种群剩余需求总数(即剩余待挑选的基因数量=m-已经被选中的基因数量)则停止挑选,将剩余基因全部纳入新种群之中。
45.上述的对初始种群na进行单次遗传操作生成种群nb具体包括以下步骤:
46.计算每个基因的适应度f:
47.f=1/xi,xi为接货距离总长,即适应度f等于接货距离总长的倒数;1≤i≤n,n为呼梯任务总数;
48.计算每个基因的选中概率f
p
:
49.即单基因适应度/种群适应度的和,m为种群规模;
50.通过遍历式轮盘赌规则选择下一次进化的基因,将选择出的基因作为母体,通过交叉操作得到新的基因,并且对选择出的基因进行变异操作得到新的基因,生成种群nb。
51.所述的通过遍历式轮盘赌选择选择下一次进化的基因包括:进行m轮选择,每一轮选择在[0,1]区间随机生成一个随机数,将每个随机数依次与种群中的m个基因的选中概率进行比较,直到找到选中概率比随机数大的基因,则停止比较并选择该基因进入下一代遗传种群;在下一轮选择中,从上一轮被选基因的下一个基因开始依次将种群中的各基因的选中概率与随机数进行比较,如果比较到种群中最后一个基因仍未找到选中概率比随机数大的基因,则再返回种群中的第一个基因进行比较。现有技术中,在每一轮选择中都是从种群中的第一个基因开始与随机数进行比较,找到选中概率比随机数大的基因,则停止比较,这种方式容易产生局部最优解。而本实施例在下一轮选择中,是从上一轮被选基因的下一个基因开始与随机数进行比较,能够避免局部最优解的产生。
[0052]
在本实施例中,上述的步骤s3具体包括:
[0053]
s31、计算种群中的作为遗传个体的每个基因的适应度f:
[0054]
f=1/xi,xi为接货距离总长,即适应度f等于接货距离总长的倒数;
[0055]
s32、计算每个基因的选中概率f
p
:
[0056]
m为种群规模,即选中概率f
p
等于单个基因适应度/种群适应度的和;
[0057]
s33、通过遍历式双基因轮盘赌选择下一次进化的基因,将选择出的基因作为母体,通过自适应交叉操作得到新的基因,并且对选择出的基因进行自适应变异操作得到新的基因,生成新的种群;
[0058]
所述的通过遍历式双基因轮盘赌选择选择下一次进化的基因包括:进行m轮选择,每一轮选择在[0,1]区间随机生成两个随机数,将每个随机数依次与种群中的m个基因的选中概率进行比较,直到找到选中概率比随机数大的基因,则停止比较并保留该基因,将根据该两个随机数所获得两条基因做对比,选择选中概率较大的那条基因进入下一代遗传种群;在下一轮选择中,从上一轮被选基因的下一个基因开始依次将种群中的各基因的选中概率与随机数进行比较,如果比较到种群中最后一个基因仍未找到选中概率比随机数大的基因,则再返回种群中的第一个基因进行比较。
[0059]
基本遗传算法在算子选择中,就近选出一组个体之后,便会重新开始下一次的个体选择,容易只选中初始种群前部相对高适应度的个体。因此假定初始种群的规模为m,第s个选择算子筛选出的个体是初始化种群第n个个体(n《m),则第s1个算子的选择从初始种群第n+1个个体进行筛选,直到完成所有初始化种群筛选,再重新遍历筛选。在本实施例的选择计算中,选择算子的择优不再是只碰到一组满足约束条件的算子便直接输出,而是保持第一组优秀算子,继续筛选一组优秀算子,两组算子择优输出,如此可充分利用计算效率。
[0060]
本实施例中,用于自适应交叉计算的自适应交叉概率pc的计算公式为:
[0061][0062]
用于自适应变异计算的自适应变异概率pm的计算公式为:
[0063][0064]
其中:pc为交叉概率,pm为变异概率,f
′
为即将交叉的两组基因中适应度较大的值,
avg
为种群适应度平均值,f
max
为种群适应度最大值,f为变异后的基因的适应度,p1、2、k1、k2均为控制参数,控制参数p1、2、k1、k2均为预先人为设定。
[0065]
现有的自适应遗传算法的自适应交叉概率pc和自适应变异概率pm更偏向于改变低适应度个体,对于高适应度个体几乎不发生改变,使得算法收敛于局部值可能增加,而本实施例的自适应交叉概率pc和自适应变异概率pm利用指数形式的计算公式,提高了交叉概率及变异概率变化的平稳性,避免计算因子的大幅度变化情况;
[0066]
s34、将上一代的最优解加入种群,通过冒泡排序后筛选出该种群最优解,若最优解仍然为上一代最优解,则丢弃最后一组基因,将上一代最优解纳入遗传种群,传给下一代;若最优解非上一代最优解,则随机取出一组基因与上一代最优解做对比,择优纳入种群;步骤s34对应于图4中的最优适应度遗传因子加入;
[0067]
s35、判断新形成的种群是否已满足预设的迭代终止条件,若未满足预设的迭代终止条件则返回步骤s31,若已满足预设的迭代终止条件则将种群中适应度最大的基因作为最优解输出。在本实施例中,预设的迭代终止条件为种群的遗传代数达到预设的终止遗传代数。
[0068]
综上所述,本实施例所采用的改进的自适应遗传算法与一般的遗传算法的主要区别如下:
[0069]
(1).优化初始化组群;
[0070]
(2).优化选择;
[0071]
(3).自适应参数
[0072]
将固定交叉、变异概率更换为自适应遗传参数;
[0073]
(4).精英主义
[0074]
为防止进化过程中最优解被交叉或变异破坏,将适应度最优解直接作为最终算子参与最短路径的排序并遗传给下一代。
[0075]
本发明实施例采用组合算法可以有效降低系统低任务数时的执行时间,确保低任务数的执行队列绝对最优;而当呼梯任务数数量较多时,采用遗传算法,可以在有限的时间内,相对准确的输出执行任务,确保整个系统的执行效率。
[0076]
经验证,组合算法相较于单一算法可以有效减少系统计算时间,提高系统整体执行效率,将系统执行效率发挥至最优。而改进后的遗传算法,能够获得较优的重复收敛性,最大误差大幅降低,异常耗时次数明显减小,能够适应实际控制需求。
[0077]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1