基于深度学习的文本数据分类方法
1.本发明涉及文本分类技术领域,具体是基于深度学习的文本数据分类方法。
背景技术:
2.随着我国社会政治经济的迅速发展,人民生活水平的不断提高和移动互联网的迅速发展,人民百姓表 达民情民意的意愿的需求也不断增强。为了更好为人民百姓解难,快速有效地了解处理人民百姓实际面对 地困难和问题,吸纳人民百姓提出的具有切实价值的意见,许多城市均设立开通市长公开电话平台,通过 拨打市民政务服务热线,受理处将市民的建议、投诉记录为文本,并根据记录的内容,再将其派发到对应 职能部门的办理处进行限期处理,处理结果再由相应网络部门对提出意见或提起投诉的市民进行反馈.市长 公开电话很好地缓解了市民反映问题难、流程复杂,以及不知道向谁投诉地问题,并且极大地提高了处理 市民问题的效率。
3.但随着市长公开电话平台工作的深入展开,人民百姓对其信赖程度不断提高,受理的电话数量也随之 增加。大量的电话受理量加之需要处理的投诉意见等通信文本数据复杂多样,派分的处理部门数量多达上 百个,极大的提高了受理处的人员培训使用成本和处理压力。就目前而言,依赖人工受理的方式已经无法 满足实际工作的需要,文本自动分类技术的加入成为必然.。
技术实现要素:
4.鉴于上述技术缺点,本发明提供了基于深度学习的文本数据分类方法。
5.为解决背景技术所提出的问题,本发明的技术方案如下:
6.基于深度学习的文本数据分类方法,包括如下步骤:
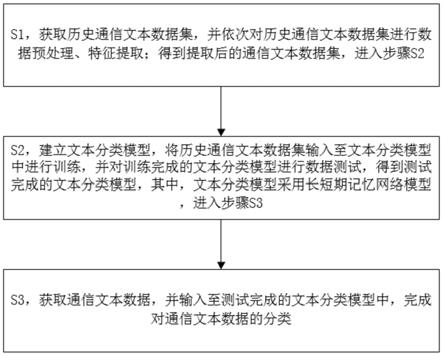
7.s1,获取历史通信文本数据集,并依次对历史通信文本数据集进行数据预处理、特征提取;得到提取 后的通信文本数据集,进入步骤s2;
8.s2,建立文本分类模型,将历史通信文本数据集输入至文本分类模型中进行训练,并对训练完成的文 本分类模型进行数据测试,得到测试完成的文本分类模型,其中,文本分类模型采用长短期记忆网络模型, 进入步骤s3;
9.s3,获取通信文本数据,并输入至测试完成的文本分类模型中,完成对通信文本数据的分类。
10.作为优选的,步骤s1中所述的对历史通信文本数据集进行特征提取,其数学表达式如下:
[0011][0012]
[0013]
其中,d表示由训练集文本中所有出现的词汇在排除低频词后组成的集合,d
t
为d中的第t个元 素。表示在空间中第t个单位坐标向量。
[0014]
作为优选的,步骤s2中所述的文本分类模型采用adaboost提升算法,其数学表达式如下:
[0015][0016]
其中,ζ
α
表示从样本空间的子集到样本空间子集的映射,即从自变量(集合)中按照时序剔除比例为 α的元素。ψ表示由从样本空间的子集到函数(分类器)集的映射。
[0017]
作为优选的,步骤s2中所述的文本分类模型,其计算公式如下:
[0018][0019]it+1
=σ(wi·
[h
t
,x
t+1
]
t
+bi)
[0020][0021][0022]ot+1
=σ(wo[h
t
,x
t+1
]
t
+bo)
[0023]ht+1
=o
t+1
·
tanh(c
t+1
)
[0024]
其中,二维权重向量与bf为未知参数,h为输出状态值,c为细胞状态值;二 维权重向量bi和bc均为未知参数;二维权重向量 与bo为参数。
[0025]
作为优选的,步骤s2中所述的文本分类模型,其训练过程如下:
[0026]
定义分类交叉熵损失函数:
[0027][0028][0029]
其中,k为分类的水平数,为n行k列的矩阵,是文本分类模型的估计结果,并采用自适应矩估计 算法(adam)对搭建好的模型进行优化训练,即最小化上述损失,adam基于ptyhon的keras模块实现。
[0030]
本发明的有益效果是:本发明提出了基于深度学习的文本数据分类方法,本发明采用长短期记忆神经 网络的提升算法,不仅克服了背景技术所存在的问题,并且在处理文本分类时能够达到良好的效果。
附图说明
[0031]
图1为本发明提供的:市长公开电话平台文本数据特征示意图;
[0032]
图2为本发明提供的:rnn与lstm重复元结构示意图;
[0033]
图3为本发明提供的:提升算法示意图;
[0034]
图4为本发明提供的:adaboost算法示意图;
[0035]
图5为本发明提供的:训练用时与准确率散点示意图;
[0036]
图6为本发明提供的:流程示意图。
具体实施方式
[0037]
下面结合本发明的附图1-6,对本发明实施例中的技术方案进行清楚、完整地描述,本领域技术人员 可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施 方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进 行各种修饰或改变。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的 所有其他实施例,都属于本发明保护的范围。
[0038]
循环神经网络的构造使其可以学习到文本中的顺序信息,而对于文本中词的长依赖问题,即一个词与 之前临近的几个词相关性较小,但与之前较远处的一些词相关的问题,在实践过程中循环神经网络无法学 习到此种特征,为解决这种长依赖问题,1997年hochreiter等人在循环神经网络的基础上引入长短期记忆 网络。
[0039]
如图1、2、6所示,长短期记忆网络(long short term memory networks,lstm)与标准的循环神经网络 的不同在于重复元内部山单层变为多层,设定好初始输出状态值h0与初始细胞状态值c0,产生第t+1个 输出状态值h
t+1
时,输入h
t
与x
t+1
到忘记门,即下式
[0040][0041]
计算f
t
,其中二维权重向瞿wf=[w1,w2]与bf为未知参数.
[0042]
忘记门计算的f
t
作为细胞状态c
t
在之后计算中的系数,决定上一细胞状态c
t
中的信息应该被丢弃多 少,之后进入输入门,即通过下式:
[0043]it+1
=σ(wi·
[h
t
,x
t+1
]
t
+bi)
[0044][0045]
计算i
t+1
与其中二维权重向星wi=[w1,w2]和wc=[w1,w2]与bi和bc为未知参数。
[0046]
输入门计算的作为新的细胞状态的候选状态,在之后的计算中用于更新细胞状态c
t+1
,反映 的是新的输入x
t+1
的信息,通过计算得到的i
t+1
作为在之后计算中的系数,决定候选细胞状态在更新c
t+1
时,哪些新的信息应该被留下,即通过下式:
[0047]
[0048]
更新细胞状态c
t+1
,
[0049]
最后进入输出门,完成一次循环,即通过下式:
[0050]ot+1
=σ(wo[h
t
,x
t+1
]
t
+bo)
[0051]ht+1
=o
t+1
·
tanh(c
t+1
)
[0052]
更新输出状态值h
t+1
,其中二维权重向量wo=[w1,w2]与bo为参数,至此lstm中的循环神经元完整 地完成一次循环。
[0053]
长短期记忆循环神经网络由于其特性,可以有效的学习含有复杂相关性和顺序信息的文本数据。长短 期记忆循环神经网络的特点也正好契合了市长公开电话文本数据的数据特点,加之长短期记忆循环神经网 络具有良好稳定性和容错性良好,适合作为市长公开电话文本自动分类的解决方法。
[0054]
但长短期记忆循环神经网的结构使得循环神经网络层在计算时必须是线性运算的,会增加学习时的时 间代价,因此在进一步利用长短期记忆循环神经网络处理如同市长公开电话文本数据这样的大规模数据时, 学习的时间代价是必须要考虑的。
[0055]
统计机器学习中的提升方法,可以一定程度上适应文本数据的类不平衡,并提升自动分类器的效果, 而这正与市长公开电话文本数据具有分类目标多,且各类数据量的分布极不平衡的特点相契合,在市长公 开电话文本数据中所含数据量大的类别对于最终文本自动分类方法的影响更加显著,而所含数据量小的类 别则容易被文本自动分类方法忽略,导致文本自动分类效果降低,准确率提升困难的重要原因,在已有的 自动分类方法的菲础之上再进一步的使用提升算法可以提升最终的分类效果。
[0056]
提升方法一般指的是基于弱学习算法,即在概率近似正确(probably approximately correct,pac)学习的 框架中,学习的结果仅仅比随机猜略好的方法,多次学习得到多个弱分类器,再组合弱分类器,构成一个 强分类器,即在pac框架下,学习的结果准确率非常高的方法。提升方法中最具有代表性的就是adaboost 算法。
[0057]
如图3所示,adaboost算法在产生多个弱分类器时,采用的是样本重抽样的方法,其关键在于反复调 整训练数据被抽样的概率。首先赋予所有训练数据相同的被抽到的权重,重抽样产生一个子训练集,并训 练出一个弱分类器,之后每次对训练样本的重抽样,都会先提高上一个产生的弱分类器分类错误的样本被 抽到的权重,再根据新抽出的训练样本得到下一个弱分类器,最后所有的弱分类器采取加权多数表决的方 法。其中分类准确率高的弱分类器的权值较高,组合为一个分类器。
[0058]
考虑在市长公开电话文本数据自动分类的问题中,在使用提升算法时,只在训练集的子集上进行训练 会损失大晕全局信息,而长短期记忆循环神经网络适合数据具有相关性和顺序信息的特征,并且作为强分 类器,已经具有较好的结果,因此最终由提升算法产生的组合分类器若包含全模型,即在全部训练集上学 习得到的菲于长短期记忆神经网络的分类器,则最终的组合模型可以更好地反映全局信息,提升分类效果。
[0059]
如图4所示,采用提升算法增加计算量,长短期记忆神经网络在训练时循环神经网络层在计算时必须 是线性的运算,会增加学习时的时间代价,因此针对市长公开电话文本数据类不均衡和数据总量大的特征, 以及前段提及的长短期记忆神经网络对于数据的特点,在全部训练集上学习得到的基于长短期记忆神经网 络的分类器开始,采用提升算法,训练数据di的数量单调地减少,在需要大量子分类器组合时,即能够反 应全局信息,又可
减少计算量,节约时间成本。
[0060]
市长公开电话文本数据类不均衡的特点致使所含数据量大的类别对于分类效果的影响更加显著,而所 含数据量小的类别则易被忽视,基于长短期记忆神经网络的提升算法在每次迭代时,新的训练集d
i+1
保留 了上一次迭代产生的分类器mi分类错误的所有训练数据d
(1)
,并且按时序剔除分类器mi分类正确的训练 数据d
(1)
中比例为α的数据,基于新的数据集d
i+1
训练产生的分类器m
i+1
,增加了对于分类器mi分类错误 的数据的关注,这其中就包括上一次迭代所使用的训练集di中包含数据偏小的类别。最终所有的分类器 {m1,m2,
…
,mn}以多数表决的方法产生的组合分类器m相对于m1能够更好地处理数据类不均衡的特 点,提高分类效果。
[0061]
特别要说明的是,将{m1,m2,
…
,mn}以多数表决的方法产生一个组合分类器m实际上是对于分类器 {m1,m2,
…
,mn}的均权线性加和,实际操作时可以赋予各个分类器以不同的权重以达到更好的分类效果。 但最好的权重与数据本身的特性和背景有关,没有特定的客观取法,可以参考的是以分类器mi在训练集 di或者对照集s上的准确率,亦或是训练集di所包含的数据量作为mi的权重。
[0062]
基于2005年1月至2016年12月的市长公开电话的文本数据,数据总晕2401316条,分类目标113 个,每条数据为类别加中文文本格式,分别以2016年1月到12月每个月的数据作为12个测试集,对应 的以2015年12月以及之前的数据到2016年11月以及之前的数据作为12个训练集,对多种具有代表性 的文本自动分类方法测试。
[0063]
梯度提升决策树(gradient boosted decision trees,gbdt)模型lightgbm、人工神经网络文本分类器 fasttext以及使用提升方法的fasttext和基于过采样方法的fasttext、朴素贝叶斯方法(naive bayes)以及使 用提升方法的朴素贝叶斯方法,长短期记忆循环神经网络(lstm)以及使用提升方法的长短期记忆循环神 经网络,数据做相同的切词、清洗、检验等预处理技术,同一方法12次测试的参数均采用同一组,不针对 每次测试调试。
[0064]
但从准确率的表现来看,使用提升方法的长短期记忆循环神经网络表现最佳,其次是长短期记忆循环 神经网络。从稳定性上看,长短期记忆循环神经网络表现最佳,在12个测试集上的准确率的分布最为集 中,而使用提升方法的长短期记忆循环神经网络、fasttext以及使用提升方法的fasttext均有较好的稳定 性,准确率的分布相对于朴素贝叶斯以及使用提升方法的朴素贝叶斯更加集中。
[0065]
如图5所示,横轴为以秒为单位的训练时间的对数,纵轴为准确率,长短期记忆循环神经网络牺牲较 少的准确率的情况下,大幅减少了训练时间。
[0066]
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对 其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导 或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都 应在本发明所附权利要求的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1