MongoDB数据库分片方法、电子设备及存储介质与流程
mongodb数据库分片方法、电子设备及存储介质
技术领域
1.本技术涉及计算机技术领域,特别是涉及一种mongodb数据库分片方法、电子设备及计算机可读存储介质。
背景技术:
2.mongodb数据库作为一个分布式文件存储的数据库,由于其高性能、高可用、高扩展特性使得其在计算机技术领域得到广泛的应用。应用端可以通过服务器向mongodb数据库写入/存储数据,也可以通过服务器向mongodb数据库读取/查询数据。
3.用户端有数据存储需求时,向服务器发送存储指令,服务器响应于存储指令,将数据存放在mongodb数据库。有数据查询需求时,向服务器发送查询指令,服务器响应于查询指令,从mongodb数据库获取数据并返回给用户端。
4.对于大数据集和高吞吐量的业务场景,通过会用到mongodb分片集群,将数据进行水平扩展,以将不同的数据块分散写入在不同的分片服务器。但是现有的分片方式,无法充分发挥mongodb分片集群的写入能力。
技术实现要素:
5.本技术提供一种mongodb数据库分片方法、电子设备及计算机可读存储介质,能够解决现有的分片方式无法充分发挥mongodb分片集群的写入能力的问题。
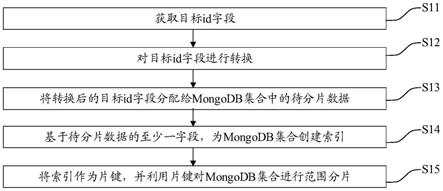
6.为解决上述技术问题,本技术采用的一个技术方案是:提供一种特征匹配方法。该方法包括:获取目标id字段,目标id字段为自增id字段或者自减id字段;对目标id字段进行转换,转换后的相邻的目标id字段所属的范围不同;将转换后的目标id字段分配给mongodb集合中的待分片数据;基于待分片数据的至少一字段,为mongodb集合创建索引,至少一字段包括转换后的目标id字段;将索引作为片键,并利用片键对mongodb集合进行范围分片。
7.为解决上述技术问题,本技术采用的另一个技术方案是:提供一种电子设备,该电子设备包括处理器、与处理器连接的存储器,其中,存储器存储有程序指令;处理器用于执行存储器存储的程序指令以实现上述方法。
8.为解决上述技术问题,本技术采用的又一个技术方案是:提供一种计算机可读存储介质,存储有程序指令,该程序指令被执行时能够实现上述方法。
9.通过上述方式,本技术未直接基于目标id字段进行范围分片,而是先对目标id字段进行转换,使得转换后的相邻的目标id字段的差值大于差值阈值,再基于转换后的目标id字段进行范围分片,即基于转换后的目标id字段为mongodb集合创建索引,将索引作为片键进行范围分片。由此,范围分片方式下,相邻的待分片数据大概率不会被写入同一分片服务器,mongodb分片集群不会存在写入瓶颈的问题,能够充分发挥mongodb分片集群的写入能力。
附图说明
10.图1是本技术mongodb数据库分片方法一实施例的流程示意图;
11.图2是本技术mongodb数据库分片方法另一实施例的流程示意图;
12.图3是图2中s22的具体流程示意图;
13.图4是对目标id字段进行转换的示意图;
14.图5是自增id获取装置的结构示意图;
15.图6是本技术mongodb数据库分片方法又一实施例的流程示意图;
16.图7是获取id字段序列的流程示意图;
17.图8是现有的范围分片方式的示意图;
18.图9是本技术的分片方式的示意图;
19.图10是本技术电子设备一实施例的结构示意图;
20.图11是本技术计算机可读存储介质一实施例的结构示意图。
具体实施方式
21.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术的一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
22.本技术中的术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”、“第三”的特征可以明示或者隐含地包括至少一个该特征。本技术的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
23.在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,在不冲突的情况下,本文所描述的实施例可以与其它实施例相结合。
24.在介绍本技术提供的分片方法之前,先对mongodb分片集群的原理进行简要介绍:
25.mongodb分片集群由多个分片服务器(shard server)组成,每个分片服务器承载多个mongodb数据库,每个mongodb数据库以数据块(chunk)为单位存储数据,每个数据块包括0到多条数据记录。本技术后文将要写入mongodb数据库的数据组成的集合称为mongodb集合,在单个分片服务器的存储容量不足、负载不足、吞吐量达到上限等情况时,需要对该mongodb集合进行分片,即对mongodb集合中的数据分片,以将该mongodb集合中的数据分散写入至不同的分片服务器。
26.对mongodb集合的分片是基于片键进行的。片键是每条数据记录都必须包含的,且建立了索引的单个或多个字段。现有的分片方式有两种,一种是范围分片,另一种是哈希分片。哈希分片即选择单个字段作为索引字段,计算索引字段的哈希值,以哈希值作为片键。范围分片是选择一个或多个字段作为索引字段,将该索引字段作为片键。每个分片服务器对应一片键范围,哈希分片/范围分片会基于片键所属的片键范围,将数据写入至不同的分片服务器。
27.哈希分片方式下,即使索引字段的值十分接近,对应的哈希值也可能不属于同一索引范围。因此哈希分片能够使得数据均匀分布。但是,哈希分片只适用于将单个字段作为索引字段而进行分片,且数据的查询效率低。
28.范围分片方式下,数据的查询效率高。当mongodb集合的数据的片键分布不均匀时,写入各个分片服务器的数据分布不均匀。特别是对于片键具有单调性的数据,片键相邻的待分片数据大概率被写入在同一个分片服务器。例如,如果片键单调递增,所有新插入的待分片数据都会被写入以maxkey为上限值的片键范围的分片服务器。如果索引字段单调递减,后续所有的待分片数据都会被写入以minkey为下限值的分片服务器。由此,该以maxkey为上限值的片键范围的分片服务器,或者以minkey为下限值的片键范围的分片服务器,会成为整个mongodb分片集群写入能力的瓶颈。
29.从而,现有的范围分片方式下,会导致mongodb分片集群写入瓶颈,无法充分发挥mongodb分片集群的写入能力。
30.为了解决范围分片方式下,mongodb分片集群写入瓶颈的问题,充分发挥mongodb分片集群的写入能力,本技术提供的分片方法如下:
31.图1是本技术mongodb数据库分片方法一实施例的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图1所示的流程顺序为限。如图1所示,本实施例可以包括:
32.s11:获取目标id字段。
33.目标id字段为自增id字段或者自减id字段。
34.自增id字段每次递增1,自减id字段每次递减1。
35.s12:对目标id字段进行转换。
36.转换后的相邻的目标id字段的差值大于差值阈值。
37.可以利用移位、倒序、相或和相与等位运算实现对目标id字段的转换。通过对目标id字段转换,实现了相邻的目标id字段的跳变。
38.s13:将转换后的目标id字段分配给mongodb集合中的待分片数据。
39.s14:基于待分片数据的至少一字段,为mongodb集合创建索引。
40.至少一字段包括转换后的目标id字段。
41.s14中,若至少一字段仅包括转换后的目标id字段,则可以直接将转换后的目标id字段作为索引。若至少一字段包括多个字段,即除了包括转换后的目标id字段之外,还包括其他整形数字段,则可以将多个字段的组合作为索引(复合索引),其中,转换后的目标字段处在组合的第一位。
42.s15:将索引作为片键,并利用片键对mongodb集合进行范围分片。
43.可以理解的是,目标id字段是自增的或者自减的(具有单调性),相邻的两个目标id字段差值为1,因此如果基于目标id字段进行范围分片,即直接将目标id字段作为索引分配给待分片数据,并将索引作为片键实现对待分片数据的范围分片,相邻的待分片数据大概率被集中写入同一分片服务器,无法充分发挥mongodb分片集群的写入能力。
44.为此,本技术未直接基于目标id字段进行范围分片,而是先对目标id字段进行转换,使得转换后的相邻的目标id字段的差值大于差值阈值,再基于转换后的目标id字段进行范围分片,即基于转换后的目标id字段为mongodb集合创建索引,将索引作为片键进行范
围分片。由此,范围分片方式下,相邻的待分片数据大概率不会被写入同一分片服务器,mongodb分片集群不会存在写入瓶颈的问题,能够充分发挥mongodb分片集群的写入能力。
45.进一步地,转换后的目标id字段具有周期递增性或者周期递减性,相应地,将转换后的目标id字段作为索引/片键,索引/片键具有周期递增性或者周期递减性。其中,若目标id字段为自增id字段,则转换后的目标id字段具有周期递增性,索引/片键具有周期递增性。若目标id字段为自减id字段,则转换后的目标id字段具有周期递减性,索引/片键具有周期递减性。由此,通过对目标id字段转换,实现了目标id字段的周期跳变。该周期跳变算法具有单值函数的特性,同时定义域和值域相同。由此,基于转换后的目标id字段创建索引,将索引作为片键进行分片,能够在提高mongodb集群的写入能力的同时,提高mongodb集群的读取能力(具体原理通过后面的例子说明)。从而,能够在继承哈希分片的优点的同时,保留范围分片的优点。
46.在索引/片键具有周期递增性或者周期递减性的情况下,可以对上述实施例进一步扩展,具体如下:
47.图2是本技术mongodb数据库分片方法另一实施例的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图2所示的流程顺序为限。本实施例是对s12的进一步扩展。如图2所示,本实施例可以包括:
48.s21:截取目标id字段的m位二进制数的低n位值。
49.其中,n+1<m。
50.可以利用相与操作将目标id字段的的m位二进制数0到n-1位值截取下来,作为低n位值。n可以是4、5、6、7、8等等。
51.例如,用id_increase表示目标id字段,用id_jump表示转换后的目标id字段。如果想截取id_increase的m位二进制数的低8位,可以将id_increase的m位二进制数和0xff运算,即可得到id_increase的m位二进制数的低8位值。
52.s22:对低n位值进行倒序。
53.经过倒序,可以使得相邻的两个目标id字段转换为的两个片键之间的跳变范围更大,从而有利于后续根据片键进行范围分片。倒序可以通过相与操作、相或操作和移位操作实现。
54.结合参阅图3,s22可以包括以下子步骤:
55.s221:截取低n位值的最低位值。
56.假设用id_low_n表示低n位值,用id_low_1表示最低位值,用id_invert表示倒序结果。可以利用与运算从id_low_n截取id_low_1,例如,id_low_n&1。
57.s222:更新倒序结果为倒序结果与最低位值的相或结果。
58.例如,更新id_invert为id_invert与id_low_1相或的结果。
59.s223:将倒序结果左移一位,并将低n位值右移1位。
60.s224:判断是否循环执行n次。
61.若是,则结束;若否,则跳转至s221,以循环执行上述步骤,直至循环次数达到n次。
62.倒序结果的初始值为0,最终值为第n次的倒序结果。倒序前和倒序后的低n位值具有一一对应的关系。
63.s23:将倒序后的低n位值左移m-n-1位,并将截取后的m位二进制数右移n位。
64.上述s21~s23对目标id字段的m位二进制数的处理,仅涉及数值位,不涉及符号位。因此,s21~s23的处理是相对数值位来说的。
65.s24:对倒序后的低n位值的左移结果和截取后的m位二进制数的右移结果进行相或操作,得到转换后的目标id字段。
66.假设用id_left表示倒序后的低n位值的左移结果,用id_right表示将截取后的目标id字段的右移结果。可以将id_left和id_right进行相或操作,得到转换后的目标id字段的m位二进制数,进而得到转换后的目标id字段。
67.下面结合图4,以一个具体实例的方式,对s21~s24进行详细说明。
68.目标id字段是256020,用64位二进制数表示为“0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0011 1110 1000 0001 0100”。将该二进制数的第0到7位值“0001 0100”作为第一部分,第8到62位作为第二部分,第63位作为第三部分。第一部分为低8位值,第三部分为符号位。将该二进制数的第一部分截取,对第一部分倒序,得到“0010 1000”。将“0010 1000”移动到第三部分之后、第二部分之前,得到片键的二进制数“0 0010 1000 000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0011 1110 1000”,将片键的二进制数转换为十进制得到1441151880758559720。
69.如下表1示出了对目标id字段256000~256511的转换结果:
70.表1
71.id_increaseid_jump25600010002560014611686018427388904256002230584300921369495225625591873432398358128402562561001256257461168601842738890525625823058430092136949532565119187343239835812841
72.如表1所示,256000被转换为1000,256001被转换为4611686018427388904。未转换之前256000和256001相邻,差值为1,转换之后1000和4611686018427388904的差值为4611686018427387904;
…
;因此,相邻的id_increase转换为id_jump之后,发生了巨大的跳变。
73.由此,如果以id_increase进行分片,由于256000、256001、256002、相邻,因此基于id_increase进行分片,256000、256001、256002、大概率会被分到同一个分片服务器中。而如果基于id_jump进行分片,由于1000、4611686018427388904和2305843009213694952、各不相邻,因此大概率会被写入不同的分片服务器。由此,基于id_jump进行分片,能够充分发挥mongodb集群的写入能力。
74.并且,id_jump具有周期递增性,即id_jump每隔28增加1。因此,id_jump为1000、1001的待分片数据大概率被分到同一分片服务器上,从而要查询id_jump为1000、1001的待分片数据时,由于这部分数据都分布在同一个分片服务器上,不用广播到每个分片服务器中去查询,故查询效率高。由此,能够在提高mongodb集群的写入能力的同时,提高mongodb
集群的读取能力。
75.为了更加直观地展示转换效果,下面结合表2进行说明:
76.表2
77.区间第63位第55-62位第0-54位范围000000 0000000
…
00
–
111
…
1100000000000000000-36028797018963967101000 0000000
…
00
–
111
…
114611686018427387904-4647714815446351871200100 0000000
…
00
–
111
…
112305843009213693952-2341871806232657919
……………
25400111 1111000
…
00
–
111
…
114575657221408423936-461168601842738790325501111 1111000
…
00
–
111
…
119187343239835811840-9223372036854775807
78.如表2所示,对id_jump划分得到256个区间/范围,id_jump每隔28增加1,由此id_jump在256个范围循环。例如第0个id_jump在范围0,第1个id_jump跳变至范围1,
……
,第256个id_jump会回到范围0。从而,根据id_jump进行分片,会使得id_jump相邻的待分片数据被分配到不同的分片服务器,并且由于周期递增特性使得待分片数据在的mongodb集群的分布尽可能均匀。
79.进一步地,上述s11中,可以从mongdb数据库的自增id字段获取装置获取目标id字段。图5是自增id获取装置的一示意图。如图5所示,自增id获取装置包括存储单元和获取单元。存储单元是mongdb数据库存储的一个集合(后文称为自增id字段集合),用于存储待分片的mongodb集合的名称,以及下一可用的id字段(后文也称为第二起始id字段)。存储单元存储的数据结构可以示意为:
[0080][0081]
其中,_id字段存储mongodb集合的名称,file_info代表待分片的mongodb集合的名称;next_id字段存储下一可用的id字段,256000代表下一可用的id字段。
[0082]
作为一实施例,可以利用获取单元从存储单元获取下一可用的id字段,作为目标id字段;修改存储单元存储的下一可用的id字段为下一可用的id字段加1,以供下一次需要获取新的目标id字段时使用。该方式下,针对每个待分片数据,都需要从存储单元获取下一可用的id字段,作为对应的目标id字段,更新存储单元存储的下一可用的id字段。因此,针对每个待分片数据,都需要访问存储单元/mongodb数据库,获取目标id字段需要消耗的资源多。
[0083]
作为另一实施例,为了减少对mongodb数据库的访问次数,减少获取目标id字段需要消耗的资源,可以利用获取单元通过如下方式获取目标id字段:
[0084]
图6是本技术mongodb数据库分片方法又一实施例的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图6所示的流程顺序为限。本实施例是对s11的进一步扩展,如图6所示,本实施例可以包括:
[0085]
s31:判断可用id字段的剩余量是否小于或者等于0。
[0086]
例如,用remain表示剩余量,可以利用获取单元判断是否满足remain≤0。
[0087]
若是,则执行s32~s35;若否,则执行s34~s35。
[0088]
s32:获取第二起始id字段,并更新第一起始id字段为第二起始id字段,并重置剩余量为预设数量。
[0089]
s33:更新第二起始id字段为第二起始id字段与预设数量之和。
[0090]
例如,预设数量为1000,可以令第二起始id字段next_id=next_id+1000。
[0091]
s34:基于第一起始id字段和剩余量计算目标id字段。
[0092]
可以计算预设数量与剩余量之差,作为偏移量;计算偏移量与第一起始id字段之和,作为自增id字段。
[0093]
例如,用offset表示偏移量,用start表示第一起始id字段。由此,可以采用下式计算得到自增id字段id_increase:
[0094]
offset=1000-remain;
[0095]
id_increase=start+offset。
[0096]
s35:更新剩余量为剩余量减1。
[0097]
即,令remain=remain-1。
[0098]
第一起始id字段(start)、可用id字段的剩余量(remain)、偏移量(offset)的初始值均是0。第二起始id字段的初始值可以是0,也可以是预设数量(对可以作为目标id字段的值进行了保留,以供其他需要)。
[0099]
通过本实施例的实施,获取单元每次从存储单元获取第二起始id字段作为第一起始id字段之后,将存储单元存储的第二起始id字段修改为第二起始id字段与预设数量之和。由此,获取单元每次从存储单元获取了预设数量个可用的id字段,当预设数量个可用的id字段用完之后,才会再次访问存储单元。故,能够减少对mongodb数据库的访问次数,减少获取目标id字段需要消耗的资源。
[0100]
如下结合图7,以一个例子的形式,对s31-s35进行详细说明。
[0101]
设置remain、start和offset的初始值均为0,next_id的初始值是1000,预设数量是1000。
[0102]
1)判断是否满足remain≤0。若是,则进入2);若否,则进入4)。
[0103]
2)获取next_id,start=next_id,remain=1000。
[0104]
3)next_id=next_id+1000。
[0105]
4)offset=1000-remain,id_increase=start+offset。
[0106]
5)remain=remain-1。
[0107]
如下结合图8和图9,以自增id字段为256000、256001、256002为例,对现有的范围分片方式与本技术的分片方式进行比较:
[0108]
图8是现有的范围分片方式的示意图,结合参阅图8,分片服务器a的范围为minkeyx≤id≤100000、数据块为chunka,分片服务器b的范围为100000≤id≤256000、数据块为chunkb,分片服务器c的范围为256000≤id≤maxkey,数据块为chunkc。基于自增id字段进行范围分片时,三个待分片数据均被写入chunkc。
[0109]
图9是本技术的分片方式的示意图,结合参阅图9,分片服务器a的片键范围为minkeyx≤id≤100000、数据块为chunka,分片服务器b的片键范围为100000≤id≤
2341871806232657919、数据块为chunkb,分片服务器c的片键范围为4611686018427388904≤id≤maxkey,数据块为chunkc。先分别对自增id字段256000、256001、256002进行转换(周期跳变),对应得到转换后的自增id字段1000、4611686018427388904和23058435843009213694952。基于转换后的目标id字段进行分片时,将该三个待分片数据分别写入chunka、chunkc和chunkb。
[0110]
图10是本技术电子设备一实施例的结构示意图。如图10所示,该电子设备包括处理器21、与处理器21耦接的存储器22。
[0111]
其中,存储器22存储有用于实现上述任一实施例的方法的程序指令;处理器21用于执行存储器22存储的程序指令以实现上述方法实施例的步骤。其中,处理器21还可以称为cpu(central processing unit,中央处理单元)。处理器21可能是一种集成电路芯片,具有信号的处理能力。处理器21还可以是通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0112]
图11是本技术计算机可读存储介质一实施例的结构示意图。如图11所示,本技术实施例的计算机可读存储介质30存储有程序指令31,该程序指令31被执行时实现本技术上述实施例提供的方法。其中,该程序指令31可以形成程序文件以软件产品的形式存储在上述计算机可读存储介质30中,以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本技术各个实施方式方法的全部或部分步骤。而前述的计算机可读存储介质30包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质,或者是计算机、服务器、手机、平板等终端设备。
[0113]
在本技术所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0114]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。以上仅为本技术的实施方式,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1