一种公文智能写作方法与流程
1.本发明属于计算机应用领域,具体涉及一种文本纠错方法。
背景技术:
2.随着大规模自然语言处理模型的发展与落地,gpt等模型已取代了传统的神经网络,实现了机器模型对文本数据的理解。上亿级别的模型参数量能够拟合人理解文本的过程,学习到文本内在的逻辑与表达。基于这种能力,在政务领域中进行智能写作是一个新兴的技术研究方向。在进行政务公文写作时,需要构思政策性、程式化的语句表达,需要参考大量的公文文献作为辅助素材。传统的公文素材辅助,系统只能解析用户输入的关键词,通过正则表达式、文本相似度计算等基础检索算法,关联出最符合要求的文本片段集合推送给用户。这种算法只能推荐公文素材中的固有文本表达,无法学习到公文的内在深层表述逻辑,不具有智能创作能力。
技术实现要素:
3.发明目的:本发明的目的在于提供一种公文智能写作方法。
4.技术方案:本发明所述的一种公文智能写作方法,该方法包括步骤如下:
5.(1)获取若干公文文本数据,经过文本筛选处理后,形成公文训练数据集;
6.(2)利用现有文本语料数据对生成式预训练语言模型进行第一阶段训练后,获取生成式预训练语言模型的初始参数,再利用步骤(1)中获取的公文训练数据集对生成式预训练语言模型进行微调,使模型收敛;
7.(3)当用户输入文本片段开始公文写作时,利用微调后的生成式预训练语言模型对后续字符位置的内容进行预测。
8.优选的,步骤(1)中在指定公文发布网站上获取公文文本数据,并按照设定周期获取指定网站内新发布的公文文本数据。
9.优选的,步骤(1)中文本筛选处理的步骤如下:
10.(a)将获取的每篇公文文本内的标签、空格、分隔符删除;
11.(b)利用自然语言处理算法对公文文本进行分词处理,将停用词比例高于第一设定比例的公文以及非中文字符占比超过第二设定比例的公文删除;
12.(c)将每篇公文文本内容按照自然段落进行分割,公文训练数据集中每条训练语句为一个自然段落。
13.优选的,步骤(2)中结合目标领域的专业词典,在训练过程中对文本数据切分词时保留完整的语义片段。
14.优选的,步骤(2)中生成式预训练语言模型微调阶段,将文本切分词语处理后的公文训练数据集按照设定比例划分为训练集、验证集和测试集,利用训练集对生成式预训练语言模型训练若干个周期,使模型收敛。
15.优选的,步骤(2)中将公文文本按照内容质量划分为若干个等级并设置对应的权
重系数,生成式预训练语言模型训练过程中,通过损失函数结合训练文本对应的权重系数计算模型的损失。
16.优选的,步骤(2)中,在生成式预训练语言模型微调阶段中对模型进行验证时,在验证集中随机抽取设定数量的训练语句形成验证子集。
17.优选的,步骤(3)中当用户输入文本片段后,将用户输入的字符输入训练好的生成式预训练语言模型中,生成式预训练语言模型预测下个字符位置的内容并按顺序往后预测,直到标点符号为止,按照所有预测字符的概率得分乘积计算联合概率,由高到低输出若干个候选文本片段供用户选择。
18.优选的,步骤(3)中将生成式预训练语言模型输出的若干个候选文本片段与公文标题进行匹配,将与标题最为匹配的文本内容作为第一推荐结果输出给用户。
19.优选的,生成式预训练语言模型输出的候选文本片段与公文标题进行匹配的方法具体步骤如下:
20.(s1)将清洗后的数据中的每篇公文文本分割为标题和正文两部分,再以标点符号正则表达式将正文切分为分句;
21.(s2)将每一个分句与分句所属的文本标题配对拼接,形成标签为1的训练正样本;
22.(s3)将每一个分句与两个随机文本标题配对拼接,去除训练正样本,形成标签为0的训练负样本;
23.(s4)将正样本与负样本随机乱序,输入bert模型中进行微调训练,更新 bert模型权重;
24.(s5)将生成式预训练语言模型输出的候选文本片段输入到训练好的bert 模型中,根据输出分值获取与标题最为匹配的文本内容。
25.进一步的,步骤(1)中,利用基于python程序和scrapy框架编写相应的公文爬虫程序,将不同公文网的ip地址与公文板块名称存储在mysql数据库中,每天定时以增量更新的方式进行爬取。爬虫程序后台用redis数据库存储所有爬虫请求,防止重复发送。爬取后的公文文本以文件的形式存储在服务器上,相关的索引信息存储在mysql数据库中。
26.进一步的,对获取的文本筛选处理,将每篇公文文本其中的《br》、《head》 等尖括号内容以正则表达式进行识别去除,并将空格、分隔符去除;再利用自然语言处理算法对每篇公文利用hanlp工具包进行分词处理,将结果与停用词表进行比对,统计每篇文档停用词出现比例,将比例高于70%的公文删除。同时利用正则表达式,识别每篇文章中的非中文字符,将非中文字符占比高于20%的公文删除。被删除的公文内容信息大部分均为无意义信息,对后续的生成式预训练语言模型训练过程价值较低。
27.进一步的,由于公文段落之间的语义联系相对不密切,因此将筛选后的每篇公文内容按照段落进行分割,每一个自然段落为一条训练语句,获取不少于80 万条训练语句组成公文训练数据集。
28.进一步的,生成式预训练语言模型采用采用26亿参数的gpt模型,包含 32层transformers的decoder单元,其中每个单元结构的注意力头为32个、隐藏层尺寸为2560。transformers的decoder单元底层采用单向mask的self-attention 机制,能够有效地捕捉每一个输入字符与前文的联系,并且重点关注某些强关联性的片段,从而学习到文本字符之间的潜在逻辑。gpt模型最大输入序列长度为1024,按照自然段落进行分割的训练语句均
能够被gpt模型进行处理。
29.进一步的,对gpt模型进行第一阶段训练过程中,利用北京智源研究院开源cpm预训练模型参数作为训练数据,第一阶段训练过程能够学习到中文文本的基础语言逻辑。第一阶段训练结束后,利用生成的公文训练数据集进行公文领域的语言逻辑微调,学习更深层的公文文本特征。
30.微调阶段,26亿参数的gpt模型分布在8张卡上进行分布式训练,采用4 份模型并行与2份数据并行,对分词后处理后的不少于80万条公文训练数据以 8:1:1划分训练集、验证集、测试集,训练2个epoch,持续时间为3周,使模型收敛。
31.由于公文领域的写作需要保证一定的用词规范与专业术语,例如在政务领域的公文撰写中,分词处理过程中融入政务领域的专业词典,在文本切词时保留完整的语义片段,避免了模型在训练的时候将专业词汇分割,影响语义的整体性与专业性。
32.进一步的,在gpt模型微调过程中,采用交叉熵函数作为损失函数,计算模型的损失,由于每个网站爬取的公文质量参差不齐,为了使得模型学习到更优质的公文文本表达,根据每个渠道的公文质量,按照爬取的网站和网页版块,将公文样本分为若干个等级,每个等级对应不同的全总系数,在计算每个训练样本的损失时,将损失乘上对应的权重系数,以放大或缩小对应训练样本的损失,以使模型的参数梯度下降的方向更加趋向于优质的公文样本。
33.进一步的,在gpt模型微调阶段进行模型验证时,由于验证集数据规模较大,导致验证时间过长,因此每次验证在验证集中随机抽取1000条数据进行验证,减小了验证集的规模,提高了验证效率。
34.进一步的,当用户输入文本片段后,gpt模型会预测下个字符位置的输出,按照模型预测概率得分的从高到低进行排序,选取分数最高的字符以及分数不低于最高分90%的所有字符作为该位置上的候选字符,确保了语义联想的丰富性。然后按照每个候选字符分别继续往下预测,对于后续生成的每个字符,也采取相同的候选字符筛选方式,直到预测到标点符号为止,形成了智能联想的文本片段集合。
35.进一步的,对于每次的预测形成的若干候选文本片段,通过与本文标题进行关联,进一步提高了预测的准确性,步骤s2和步骤s3中,训练正样本由一个分句与分句所属的文本标题配对拼接,中间以[sep]标记作为分割,表示分句属于配对标题;训练负样本由一个分句与两个随机文本标题配对拼接,中间以[sep] 标记作为分割,表示分句不属于配对标题;
[0036]
将训练正样本和训练负样本随机乱序后作为输入对bert模型进行微调训练,训练中,在bert输出的[cls]位之后叠加全连接网络,经过softmax函数,输出标签为1和标签为0的分值,与真实的标签计算损失误差,利用梯度下降算法,更新模型权重。
[0037]
将gpt模型预测得到的候选文本片段输入训练好的bert模型,将候选文本与用户输入的标题进行拼接够输入bert模型,选取得分最高的候选文本作为推荐候选文本。
[0038]
有益效果:本技术所述的技术方案中通过对生成式预训练语言模型进行两次训练,进而获得符合公文写作领域预测的模型,其中第一次训练能够使模型获得中文文本的基础语言逻辑,微调阶段则能够使模型获得公文写作更深层的特征。利用得到的生成式预训练语言模型自动对用户输入的文本进行联想补全,能够提升工作效率、优化公文写作质
量。
[0039]
进一步的,生成式预训练语言模型输出的候选文本经过和标题进行匹配,能够获得更精准的文本推荐。
附图说明
[0040]
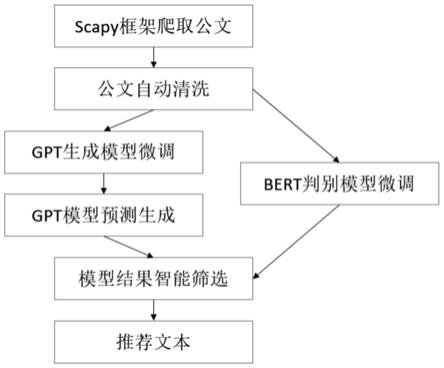
图1为本发明中公文智能写作方法的工作流程图;
具体实施方式
[0041]
下面结合附图和实施例对本发明的技术方案做进一步详细说明。
[0042]
一种公文智能写作方法,该种智能写作方法应用在政务公文写作,如图1 所示,具体步骤如下:
[0043]
步骤1,基于python程序和scrapy框架编写相应的政务公文爬虫程序,将全国各地的政务网的ip地址与公文板块名称存储在mysql数据库中,每天定时以增量更新的方式进行爬取,爬虫程序后台用redis数据库存储所有爬虫请求,防止重复发送,爬取获得的公文文本以文件的形式存储在服务器上,相关的索引信息存储在mysql数据库中。
[0044]
步骤2,对爬取得到的每篇政务公文,将文本中的《br》、《head》等尖括号内容以正则表达式进行识别去除,并将空格、分隔符去除;再利用自然语言处理算法,对每篇公文利用hanlp工具包进行分词处理,将结果与停用词表进行比对,统计每篇文档停用词出现比例,将比例高于70%的文章删除。同时利用正则表达式,识别每篇文章中的非中文字符,将非中文字符占比高于20%的文章删除。最后将每篇政务公文按照自然段落进行分割,每个自然段落为一条训练语句,得到 100万条训练语句形成公文训练数据集。
[0045]
步骤3,构建生成式预训练语言模型,生成式预训练语言模型采用26亿参数的gpt模型,该种gpt模型包含32层transformers的decoder单元,其中每个单元结构的注意力头为32个、隐藏层尺寸为2560。transformers的decoder 单元底层采用单向mask的self-attention机制;该种gpt模型的最大输入序列长度为1024,能够覆盖公文训练数据集中每条训练语句。
[0046]
步骤4,加载北京智源研究院开源cpm预训练模型参数作为微调训练的初始参数,完成第一阶段训练,该预训练参数由100g互联网文本语料训练得到,通过第一阶段训练后,gpt模型学习到了中文文本的基础语言逻辑。
[0047]
步骤5,将公文训练数据集中的训练语句分词处理后按照8:1:1划分训练集、验证集、测试集,将训练接数据输入完成第一阶段训练的gpt模型进行微调阶段训练,gpt模型分布在8张卡上进行分布式训练,采用4份模型并行与2份数据并行,训练2个epoch,持续时间为3周,使模型收敛。微调阶段训练过程中,采用交叉熵函数作为损失函数,计算模型的损失。考虑到每个网站爬取的公文质量参差不齐,根据每个渠道的公文质量,按照爬取的网站和网页版块,将每个公文样本分为5个等级,对应5级权重系数w,分别为0.6,0.8,1,1.2,1.4。在利用损失函数计算每个训练样本的损失时,将损失乘上对应的权重系数w,以放大或缩小对应的损失,以使模型的参数梯度下降的方向更加趋向于优质的公文样本。
[0048]
步骤6,训练标题和文本关联模型,该模型采用中文预训练模型bert,根据用户输入的标题,在选取最贴近用户意图的文本表达,bert模型具体训练步骤如下:
[0049]
步骤6.1,将清洗之后的数据中的每篇文档分割为标题、正文两部分,再以标点符号正则表达式将正文切分为分句;
[0050]
步骤6.2,将每一个分句与分句所属的文本标题配对拼接,中间以[sep]标记作为分割,形成训练正样本,样本对应的标签为1,用于表示分句文本属于标题;
[0051]
步骤6.3,将每一个分句分别与两个随机文本标题配对拼接,中间以[sep] 标记作为分割,去除其中的正样本,形成训练负样本,样本对应的标签为0,用于表示分句文本不属于标题;
[0052]
步骤6.4,将正样本与负样本随机乱序,输入bert模型中进行微调训练,训练中,在bert输出的[cls]位之后叠加全连接网络,经过softmax函数,输出标签为1和标签为0的分值,与真实的标签计算loss误差,利用梯度下降算法,更新模型权重。
[0053]
步骤7,智能写作预测阶段,将用户输入的文本片段输入到训练好的gpt 模型中,预测下个字符位置的输出,按照概率得分的从高到低进行排序,选取分数最高的字符以及分数不低于最高分90%的所有字符作为该位置上的候选字符,然后按照每个候选字符分别继续往下预测,对于后续生成的每个字符,也采取相同的候选字符筛选方式,直到预测到标点符号为止,形成了智能联想的文本片段集合。再将全部候选文本与用户输入的标题进行拼接,输入到bert模型中,选取输出分值最高的文本第一顺位推荐给用户,同时输出其他候选字符用于用户备选。
[0054]
本实施例中,为了保证公文领域写作的用词规范和专业术语,在对文本进行分词过程中,融入政务领域的专业词典,在文本切分词时保留完整的语义片段,避免了模型在训练的时候将专业词汇分割,影响语义的整体性与专业性。
[0055]
本实施例中,gpt模型进行微调阶段训练中,验证阶段采用随机抽样的方式进行验证,每次验证在验证集中随机抽取1000条数据用于模型验证,以减小验证集的规模。
[0056]
综上,该种公文智能写作方法能够自动收集海量公文数据,并完成公文文本数据自动筛选和清洗;通过对gpt模型进行两个阶段的训练,对公文文本的深层语义信息进行捕捉,学习到公文的语句的表征特点;写作过程中结合bert模型,计算推荐文本集合中文本片段与用户自定义标题之间的关联分数,选取与用户标题语义最为匹配的推荐片段,极大提高了匹配文本推荐的精准度。该种公文智能写作方法能够学习到公文的内在深层表述逻辑,具有智能创作能力。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1