一种分布式存储系统的参数调优方法、系统、设备、介质与流程
1.本发明涉及参数调优技术领域,尤其涉及一种分布式存储系统的参数调优方法、系统、设备、介质。
背景技术:
2.随着互联网规模的逐渐扩大,为了追求高可靠性、高扩展性和低成本的存储服务,越来越多的机构、公司、个人开始接受并使用分布式存储系统。随着用户越来越高的服务质量要求,如何在有限的硬件设施上发挥出系统的最大性能是很多运维人员都关心的问题。现有的分布式存储系统通常都具有复杂的软件体系结构,支持用户通过接口修改其内置参数,指导应用的执行过程,而对这些参数进行优化配置可以显著提升系统的性能。但是对于任何一个系统而言,都没有一种适应所有应用负载的通用的参数配置,即需要针对每一种用户负载分析其固有i/o特性,然后对分布式存储系统进行配置。由于参数空间的复杂性和应用负载的多样性,仅仅依靠传统运维手段从高维参数空间中为每一个用户应用匹配一组最优的参数配置是不切实际的。
3.aiops(art ificial intel l igence for it operat ions),即智能运维的出现为当前分布式存储系统的运维工作中的这些痛点提供了良好的解决方案,因为它能够利用机器学习智能化地分析用户负载,调整参数配置,并通过对多项指标的权衡分析,为用户提供智能的性能优化服务。但是,由于规模的逐渐扩张和内部结构的复杂,当使用aiops对分布式存储系统进行参数调优工作时,缺乏的高质量数据、复杂的系统结构及巨大的待分析数据量都会给aiops带来巨大的挑战。现有的调优方案对分布式存储系统的参数维度大以及参数关联复杂、目标之间相互影响等因素考虑不足,难以应对上述挑战,导致在利用机器学习算法对分布式存储系统进行参数优化时,不容易找到接近最优的配置参数,而且时间开销大。
4.因此,亟需一种能够快速对分布式存储系统进行参数优化的方法及系统。
技术实现要素:
5.本发明的目的在于提供一种分布式存储系统的参数调优方法、系统、设备、介质,基于贝叶斯优化先验初始化多目标进化算法的初代种群,能够提高优化的参数质量,加快迭代速度,快速对分布式存储系统进行参数优化。
6.为了实现上述目的,本发明提供如下技术方案:
7.一种分布式存储系统的参数调优方法,所述参数调优方法包括:
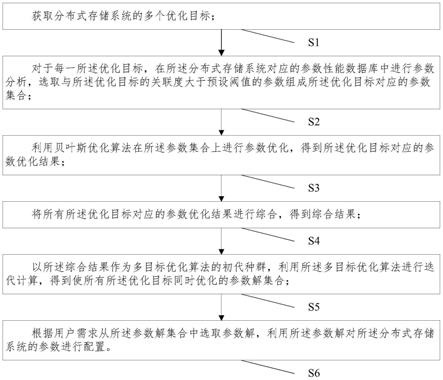
8.获取分布式存储系统的多个优化目标;所述优化目标包括时间和成本;
9.对于每一所述优化目标,在所述分布式存储系统对应的参数-性能数据库中进行参数分析,选取与所述优化目标的关联度大于预设阈值的参数组成所述优化目标对应的参数集合;所述参数-性能数据库包括多组参数的历史配置值集合和每一组所述历史配置值集合所对应的多个优化目标的历史性能值;
10.利用贝叶斯优化算法在所述参数集合上进行参数优化,得到所述优化目标对应的参数优化结果;
11.将所有所述优化目标对应的参数优化结果进行综合,得到综合结果;
12.以所述综合结果作为多目标优化算法的初代种群,利用所述多目标优化算法进行迭代计算,得到使所有所述优化目标同时优化的参数解集合;
13.根据用户需求从所述参数解集合中选取参数解,利用所述参数解对所述分布式存储系统的参数进行配置。
14.与现有技术相比,本发明提供的一种分布式存储系统的参数调优方法,通过针对多个优化目标建立独立的贝叶斯优化模型,然后进行参数综合,将优化得到的结果转化为先验知识,用于初始化多目标进化算法的初代种群,能够提高优化的参数质量,加快迭代速度。
15.一种分布式存储系统的参数调优系统,所述参数调优系统包括:
16.优化目标获取模块,用于获取分布式存储系统的多个优化目标;所述优化目标包括时间和成本;
17.参数分析子模块,用于对于每一所述优化目标,在所述分布式存储系统对应的参数-性能数据库中进行参数分析,选取与所述优化目标的关联度大于预设阈值的参数组成所述优化目标对应的参数集合;所述参数-性能数据库包括多组参数的历史配置值集合和每一组所述历史配置值集合所对应的多个优化目标的历史性能值;
18.参数优化子模块,用于利用贝叶斯优化算法在所述参数集合上进行参数优化,得到所述优化目标对应的参数优化结果;
19.参数综合模块,用于将所有所述优化目标对应的参数优化结果进行综合,得到综合结果;
20.多目标优化模块,用于以所述综合结果作为多目标优化算法的初代种群,利用所述多目标优化算法进行迭代计算,得到使所有所述优化目标同时优化的参数解集合;
21.偏好选择模块,用于根据用户需求从所述参数解集合中选取参数解,利用所述参数解对所述分布式存储系统的参数进行配置。
22.一种分布式存储系统的参数调优设备,包括:
23.处理器;以及
24.存储器,其中存储计算机可读程序指令,
25.其中,在所述计算机可读程序指令被所述处理器运行时执行上述的参数调优方法。
26.一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述参数调优方法的步骤。
27.与现有技术相比,本发明提供的参数调优系统、设备、介质的有益效果与上述技术方案所述参数调优方法的有益效果相同,此处不做赘述。
附图说明
28.此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
29.图1为本发明实施例1所提供的参数调优方法的流程示意图;
30.图2为本发明实施例1所提供的贝叶斯优化算法的流程示意图;
31.图3为本发明实施例1所提供的多目标进化算法的流程示意图;
32.图4为本发明实施例2所提供的参数调优系统的整体架构示意图;
33.图5为本发明实施例2所提供的单目标优化模块的总体设计示意图;
34.图6为本发明实施例2所提供的测试环境拓扑图;
35.图7为本发明实施例2所提供的用户并发数为32时,不同配置在吞吐率上的对比图;
36.图8为本发明实施例2所提供的用户并发数为32时,不同配置在延迟上的对比图;
37.图9为本发明实施例2所提供的用户并发数为8时,不同配置在吞吐率上的对比图;
38.图10为本发明实施例2所提供的用户并发数为8时,不同配置在延迟上的对比图;
39.图11为本发明实施例2所提供的在负载webfile上,最优吞吐率随迭代次数的变化图;
40.图12为本发明实施例2所提供的在负载webfile上,最优延迟随迭代次数的变化图;
41.图13为本发明实施例2所提供的在负载weblog上,最优吞吐率随迭代次数的变化图;
42.图14为本发明实施例2所提供的在负载weblog上,最优延迟随迭代次数的变化图;
43.图15为本发明实施例2所提供的在负载oltp上,最优吞吐率随迭代次数的变化图;
44.图16为本发明实施例2所提供的在负载oltp上,最优延迟随迭代次数的变化图;
45.图17为本发明实施例2所提供的在负载video上,最优吞吐率随迭代次数的变化图;
46.图18为本发明实施例2所提供的在负载video上,最优延迟随迭代次数的变化图。
具体实施方式
47.为了便于清楚描述本发明实施例的技术方案,在本发明的实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本发明中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其他实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
48.实施例1:
49.在详细介绍本实施例的技术方案之前,先对分布式存储系统以及aiops进行简要介绍。分布式存储系统,是将数据分散存储在多台独立的设备上的存储系统。分布式存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息。aiops,即智能运维,是将人工智能应用于运维领域,将数据分析和机器智能结合起来,从海量运维数据(日志、监控信息、应用信息等)中不断学习并做出高级决策,执行自动化运维操作。
50.分布式存储系统的参数调优主要存在以下几个特点:
51.(1)当部署云存储系统的硬件设备固定之后,用户对分布式存储系统多样化性能需求的满足依赖于准确高效的参数调优。但是对于任何一个系统而言,都没有一种适应所
有应用负载的通用的参数配置,即需要针对每一种用户负载分析其固有i/o特性,然后对分布式存储系统进行配置。
52.(2)现在的分布式存储系统通常都具有复杂的架构设计,含有巨大的参数量以及复杂的参数关系,且与硬件环境相关。
53.(3)分布式存储系统参数调优属于多目标优化问题。在多目标优化问题中,由于这些目标之间往往是相互冲突的,很难找到一组解使得所有目标都达到最优解,所以需要在多个目标之间进行最佳的权衡分析。
54.为了实现分布式存储系统的参数调优,现有的方法为:针对云环境中用户任务的执行时间和云服务的运营成本,设计了一个多目标优化系统mcamc(minimizing the cost and makespan of cloud service)。mcamc在优化过程中使用了非支配排序遗传算法,首先为每个任务随机选取资源分配方案作为初始种群,并对它们执行进化算法的交叉和变异操作生成下一代种群,通过快速非支配排序和拥挤度计算等一系列操作挑选符合用户时间和成本要求的资源分配策略,等到算法收敛时,mcamc会优化得到一组使多个目标都尽可能满足的非劣解,作为结果返回给用户。但由于mcamc事先并不知道哪种资源分配方案可能更优,所以只能采用随机初始化的方式,当面临大规模参数时,算法的计算速度会成为瓶颈。基于此,为了满足用户以更快速度获取一个接近用户需求的最优的分布式存储系统参数配置的需求,在保证参数质量的同时,如何智能化地分析不同用户负载的特性,并为其推荐一组满足多个性能指标的参数成为一个亟需解决的问题。
55.针对上述现有技术的缺陷,本实施例提供一种基于贝叶斯优化先验的分布式存储系统参数调优方法,通过针对多个优化目标建立独立的贝叶斯优化模型,然后进行参数综合,将综合结果转化为先验知识,以初始化多目标进化算法的初代种群,从而能够提高优化的参数质量,加快迭代速度。如图1所示,本实施例的参数调优方法包括:
56.s1:获取分布式存储系统的多个优化目标;所述优化目标包括时间和成本;
57.本实施例的优化目标根据用户需求而定,具体可为用户关于时间和成本的要求。
58.s2:对于每一所述优化目标,在所述分布式存储系统对应的参数-性能数据库中进行参数分析,选取与所述优化目标的关联度大于预设阈值的参数组成所述优化目标对应的参数集合;所述参数-性能数据库包括多组参数的历史配置值集合和每一组所述历史配置值集合所对应的多个优化目标的历史性能值;
59.考虑到分布式存储系统中的部分参数是不可修改的(如服务器ip地址、文件路径、端口号等),这些不可修改的参数对分布式存储系统的性能不产生任何影响,故在s2之前,本实施例的参数调优方法还包括:对参数-性能数据库进行预处理,对不可修改的参数进行手工统计,经过一系列参数过滤和清洗操作,去除参数-性能数据库中不可修改的参数,将不可修改的参数的取值全部删除,初步筛选出可能与系统性能相关的参数,得到预处理后的参数-性能数据库,并以预处理后的参数-性能数据库作为新的参数-性能数据库,执行s2。通过对参数进行初步筛选,能够进一步提高优化的参数质量,减少迭代次数。
60.s2中,在分布式存储系统对应的参数-性能数据库中进行参数分析可以包括:利用函数relation-extract在参数-性能数据库中分析选取与优化目标的关联度大于预设阈值的参数,进而直接将这些参数组成参数集合。或者,利用lasso回归分析计算参数-性能数据库中的每一参数与优化目标的关联度,再选取关联度大于预设阈值的参数组成参数集合,
进而对每个单个目标target均提取出与之关联度大的重要参数。
61.其中,使用一个函数relation-extract分析提取重要参数(即关联度大于预设阈值的参数)包括:x
important
=relation_extract(target,x);x
important
表示从全体样本空间x(即参数-性能数据库)中提取出与优化目标高度关联的参数集合。
62.从参数-性能数据库中获取优化目标对应的性能数据,然后利用lasso回归分析每个参数对优化目标性能的影响力(即关联度),返回影响力排名靠前的若干参数,组成参数集合。
63.s3:利用贝叶斯优化算法在所述参数集合上进行参数优化,得到所述优化目标对应的参数优化结果;
64.如图2所示,s3可以包括:
65.(1)根据开发人员提供的文档描述确定参数集合中每一参数的取值范围;
66.具体根据开发人员提供的文档描述为每个参数确定一个合理的取值范围。对无法量化计算的字符串和布尔型参数,将其转化成数值型。具体方法可为:布尔型参数采用简单的数值映射,即true对应1,false对应0;对于字符串类型的参数,若多个离散取值之间有大小意义,则按照大小关系映射到整数值上,类别信息则采用独热编码。通过对参数进行范围界定,能够进一步提高优化的参数质量,减少了迭代次数。同时,对无法量化计算的字符串和布尔型参数,转化成数值型,并对参数范围进行归一化,能有效提高模型的质量。
67.(2)对于每一参数,利用random库函数在参数的取值范围内随机采样,得到参数的取值;参数集合中所有参数的取值组成初始样本点;
68.由于分布式存储系统中参数的类型和取值都各不相同,为了尽可能使参数采样结果多样化,避免人为指定的局限性,引用random库函数对所有参数在其取值范围内随机采样。
69.(3)利用初始样本点对贝叶斯优化模型进行初始化,得到初始贝叶斯优化模型;利用初始贝叶斯优化模型对初始样本点进行评估,得到初始样本点的性能值;初始样本点的性能值即当参数集合内的参数取初始样本点的值时,所得到的与该参数集合相对应的优化目标的性能值。
70.(4)基于性能值修正高斯过程模型;所述高斯过程模型用于拟合目标性能的后验概率分布;
71.(5)基于高斯过程模型,利用采集函数在取值范围内进行采样以生成第一样本点;利用初始贝叶斯优化模型对第一样本点进行评估,得到第一样本点的性能值;
72.利用采集函数在每一参数的取值范围内进行采样,得到参数集合中各个参数的取值,所有参数的取值组成第一样本点。
73.(6)判断是否达到预设迭代终止条件;
74.预设迭代终止条件可为性能值达到目标值或者迭代次数达到预设迭代次数。
75.(7)若否,则以第一样本点的性能值作为性能值,返回“基于性能值修正高斯过程模型”的步骤;
76.(8)若是,则迭代过程中所涉及的所有第一样本点组成优化目标对应的参数优化结果,迭代结束。
77.本实施例利用初始样本点初始化模型,采集函数在参数的取值范围中选取下一个
合适的参数取值,并利用这个参数的评估结果更新高斯过程模型,当搜索到某个满足目标值的参数或者迭代到一定次数之后,贝叶斯优化模型终止,输出优化过程中性能最优的参数配置,得到每一优化目标的参数优化结果。
78.作为一种可选的实施方式,由于某些参数代表了特殊的含义或者参数间的依赖关系,需要对随机采样过程做改进。利用random库函数在参数的取值范围内随机采样可以包括:以参数间的依赖关系为约束,利用random库函数在参数的取值范围内随机采样。利用采集函数在取值范围内进行采样以生成第一样本点可以包括:以参数间的依赖关系为约束,利用采集函数在取值范围内进行采样以生成第一样本点。通过在生成初始样本点和第一样本点的过程中引入参数间的依赖关系这一约束,能够进一步提高优化的参数质量,减少了迭代次数。
79.举例而言,例如在openstack swift系统的代理节点的配置文件中参数concurrency_timeout的取值必须在0和另一参数node_timeout之间,node_timeout表示了代理节点等待存储节点响应的时间,如果超过node_timeout,存储节点还未返回任何响应信息,代理节点则会重新发起请求。当代理节点接收到用户的读请求时,可以设置与副本个数相等的多个并发线程,然后分别负责向不同存储节点发起读请求,并使用第一个响应的结果应答用户,concurrency_timeout表示多个线程之间触发的时间间隔,concurrency_timeout为0表示所有线程完全并发。如果采样规则没有满足concurrency_timeout小于node_timeout,则即使设置多线程同时访问存储节点,每次也只会有一个线程执行,因为第二个线程还没启动时,代理节点已经收到了响应结果。
80.s4:将所有所述优化目标对应的参数优化结果进行综合,得到综合结果;
81.在参数集合x
important
上针对目标target进行参数优化,并将参数优化结果进行综合,转为多目标优化的先验样本点。
82.对参数优化结果的综合操作具体为:
83.p0=σ(target,x
important
);
84.对特定目标在参数集合上执行bo(bayesian optimization,贝叶斯优化)算法,得到针对不同目标的参数优化结果,并利用σ对这些参数优化结果进行综合,得到初代种群p0。
85.具体的,s4可以包括:
86.(1)对于每一优化目标对应的参数优化结果,按照性能值对参数优化结果按行进行降序排列,并选取前n行组成待综合矩阵;
87.参数优化结果为所有第一样本点的组合,而第一样本点为参数集合中所有参数的取值,故参数优化结果为一个n*a的矩阵,n为贝叶斯优化的迭代次数,同样也是第一样本点的个数,a为参数集合中的参数个数。同时,每一第一样本点都对应一个性能值,故先按照性能值对n*a矩阵进行降序排序,截取前n组较优的参数,组成待综合矩阵。
88.(2)随机选取两个待综合矩阵,分别记为第一矩阵和第二矩阵;
89.为了便于后续描述,将第一矩阵记为t,第二矩阵记为l。t和l分别是一个n*p和n*q维的矩阵,p和q分别是与这两个优化目标相关联的参数的个数。
90.(3)判断第一矩阵和第二矩阵是否存在公共参数;公共参数为第一矩阵和第二矩阵中均含有的参数;
91.通常情况下,不同的优化目标有不同的参数,但也不排除存在某个参数对两个优化目标性能的影响都很大,对于这类公有参数,虽然无法得到使得两个优化目标性能都优化的具体的取值,但是可以确定的是将它们针对不同目标优化出来的解输入到多目标优化模块,至少可以使得其中一个目标接近最优。所以首先计算矩阵t和l的公共参数,并将公共参数的个数记为c。
92.(4)若不存在,则对第一矩阵和第二矩阵进行随机组合,得到综合矩阵;若存在,则判断公共参数的个数是否等于第一矩阵的参数个数或者是否等于第二矩阵的参数个数;
93.(5)若是,则对第一矩阵和第二矩阵进行替换组合,得到综合矩阵;若否,则对非公共参数进行随机组合的处理,对公共参数进行分别取原值和取平均值的处理,并将处理后的非公共参数和处理后的公共参数进行替换组合,得到综合矩阵;
94.具体的,经过∑算子操作之后,最终得到了一个m*(p+q-c)维的综合矩阵,m代表了先验中参数解的个数,其计算公式如下:
[0095][0096]
当0<c<min(p,q)时,针对这c个公共参数,通过分别取其原值或平均值可以组成三组不同的参数解,剩余的非公有参数,直接通过随机组合能生成n2个不同的参数解,最后将它们随机组合起来就有3n2个不同的参数解;而当c等于min(p,q)时,说明t和l的参数集合之间是包含与被包含的关系,此时综合后会生成2n组不同参数解;c=0代表无公共参数,则将t的p个参数和l的q个参数随机组合,会产生n2个不同参数解。
[0097]
(6)判断所有待综合矩阵是否均已被选取;
[0098]
(7)若是,则以综合矩阵作为综合结果;m个参数解即是初始单目标优化的综合结果,并将该综合结果作为多目标进化算法的初代种群。
[0099]
(8)若否,则随机选取一未被选取的待综合矩阵作为第一矩阵,以综合矩阵作为第二矩阵,返回“判断第一矩阵和第二矩阵是否存在公共参数”的步骤。
[0100]
s5:以所述综合结果作为多目标优化算法的初代种群,利用所述多目标优化算法进行迭代计算,得到使所有所述优化目标同时优化的参数解集合;
[0101]
具体的,如图3所示,s5可以包括:
[0102]
(1)以综合结果作为多目标优化算法的初代种群,对初代种群进行非支配排序、选择、交叉和变异,生成第一代子群;
[0103]
(2)将初代种群和第一代子群进行合并,得到合并后种群;
[0104]
p
now
=cross_muta(pi)+pi;
[0105]
其中,函数cross_muta表示种群中的选择、交叉和变异,pi为初代种群;p
now
为合并后种群。
[0106]
(3)对合并后种群进行快速非支配排序和拥堵度计算,挑选优良个体;将优良个体和初代种群进行合并,得到新父种群;
[0107]
p
i+1
={argmaxpnow(c_t(p
now
)-c_t(pi))}+pi;
[0108]
其中,p
i+1
为新父种群;argmaxpnow(c_t(p
now
)-c_t(pi))}为优良个体,函数c_t为适应度函数,在种群中适应度更高的个体被认为更优,直到c_t函数值趋于稳定或c_t(p
now
)
不再明显大于c_t(pi)时,说明迭代达到最优,此时获得一组使得多个优化目标同时优化的参数解。
[0109]
(4)将新父种群进行选择、交叉和变异,生成新子群;
[0110]
(5)判断当前迭代次数是否达到最大迭代次数;
[0111]
(6)若是,则以新父种群作为使所有优化目标同时优化的参数解集合,结束迭代;
[0112]
(7)若否,则以新父种群作为初代种群,以新子群作为第一代子群,返回“将初代种群和第一代子群进行合并,得到合并后种群”的步骤。
[0113]
s6:根据用户需求从参数解集合中选取参数解,利用参数解对分布式存储系统的参数进行配置。
[0114]
具体的,根据用户对目标性能的偏好和重视程度从参数解集合中挑选一组参数解作为最终的优化结果返回给用户,并利用这组参数自动化部署分布式存储系统,实现了多目标的参数自动调优。
[0115]
本实施例提供的一种基于贝叶斯优化先验的分布式存储系统参数调优方法,通过针对多个优化目标建立独立的贝叶斯优化模型,然后进行参数综合,将优化得到的结果转化为先验知识,用于初始化多目标进化算法的初代种群,能够提高优化的参数质量,加快迭代速度。
[0116]
实施例2:
[0117]
本实施例用于提供一种分布式存储系统的参数调优系统,如图4所示,参数调优系统(dsst系统)包括:先验生成模块、多目标优化模块和偏好选择模块。先验生成模块包含单目标优化模块和参数综合模块两个模块。如图5所示,单目标优化模块中的参数分析子模块用于分析参数-性能数据库中的数据,从而得到一组与目标高度相关的参数,然后利用参数优化子模块对这些参数进行优化,得到使目标应用性能最优的参数取值,参数综合模块将多个优化结果进行综合,转化成先验,将先验生成模块得到的样本导入多目标优化模块。多目标优化模块先进行交叉变异过程,然后将交叉变异生成的子代种群与初代种群合并,并对合并之后的种群执行快速非支配排序和拥挤度计算,然后挑选出优良个体,并与初代种群合并生成新父代种群。通过重复地执行这些步骤,种群中的个体越来越逼近最优解,最后模型能预测出若干组符合多个目标的参数解。偏好选择模块根据用户对目标性能的偏好和重视程度从解集中挑选一组参数作为最终的优化结果返回给用户,并利用这组参数自动化部署分布式存储系统,实现了多目标的参数自动调优。
[0118]
具体的,参数调优系统包括:
[0119]
优化目标获取模块,用于获取分布式存储系统的多个优化目标;所述优化目标包括时间和成本;
[0120]
参数分析子模块,用于对于每一所述优化目标,在所述分布式存储系统对应的参数-性能数据库中进行参数分析,选取与所述优化目标的关联度大于预设阈值的参数组成所述优化目标对应的参数集合;所述参数-性能数据库包括多组参数的历史配置值集合和每一组所述历史配置值集合所对应的多个优化目标的历史性能值;
[0121]
参数优化子模块,用于利用贝叶斯优化算法在所述参数集合上进行参数优化,得到所述优化目标对应的参数优化结果;
[0122]
参数综合模块,用于将所有所述优化目标对应的参数优化结果进行综合,得到综
合结果;
[0123]
多目标优化模块,用于以所述综合结果作为多目标优化算法的初代种群,利用所述多目标优化算法进行迭代计算,得到使所有所述优化目标同时优化的参数解集合;
[0124]
偏好选择模块,用于根据用户需求从所述参数解集合中选取参数解,利用所述参数解对所述分布式存储系统的参数进行配置。
[0125]
为了验证本实施例中的dsst系统的有效性,设计了如下验证实验:
[0126]
本实验是基于openstack swift分布式存储系统展开测试的,测试环境的网络拓扑结构如图6所示,openstack swift系统从架构上划分为两个层次:代理层(proxy nodes)与存储层(storage nodes),代理层负责restful请求的处理与用户身份的认证,存储层由一系列的存储节点组成,负责对象数据的存储,同时使用一台单独机器生成负载、记录性能。
[0127]
实验中使用的机器的软硬件配置如表1所示,在指定的机器上运行cosbench客户端,发送请求使openstack swift系统饱和,每个基准测试运行20分钟。
[0128]
表1测试环境配置
[0129][0130][0131]
本实验为反映分布式存储系统的真实环境特征,基于dell公司的白皮书和相关文献资料准备了如表2所示的四种应用负载,根据应用领域的不同,每一种负载有各自的特性,在对象的读写比例和平均存取大小存在差异。实验中使用流行的分布式存储系统基准测试工具cosbench作为工作负载生成器,按照不同的读写比例和大小生成对应的请求,发送给openstack swift系统的代理服务节点,代理节点接收请求之后经过处理,对相应的对象存储节点执行存取操作,然后再将结果返回给cosbench客户端。
[0132]
表2实验负载
[0133][0134]
(1)参数质量对比
[0135]
图7和图8分别显示了当用户并发数为32时,在四种配置下,openstack swift系统的吞吐率和延迟的对比,横坐标代表了不同应用负载,纵坐标表示观测的性能指标,吞吐率用单位时间内处理的请求数量(iops)衡量,延迟表示处理单个请求所需的平均时间,以ms计算。mcamc系统在吞吐率和延迟上获得了比默认和人工配置更好的性能,提升比例并不大,在负载webfile上存在高于人工配置的延迟,说明mcamc并没有搜索到使得系统延迟最低的参数解。本实施例的dsst系统优化的参数配置相比于其他三种配置,既能将系统吞吐率提升,又能降低延迟。
[0136]
图9和图10对比了当用户并发数为8时,四种配置对应的吞吐率和延迟的性能情况。mcamc系统在负载webfile和weblog上优化的参数相比于默认配置、人工配置,吞吐率有一定程度的提高,但延迟却增加,本实施例中的dsst系统既能够提高分布式存储系统的吞吐率,又能降低延迟,说明dsst能够在参数空间中搜索使得多项性能同时优化的参数解,使得调优的参数质量更高。
[0137]
表3总结了在不同负载上,dsst系统优化的参数相比于其他三种配置的性能优化比例(吞吐率上的提升比和延迟上的降低比)。针对吞吐率性能,dsst系统在负载webfile上实现了最高每秒钟处理1254.91个请求,相比于默认、人工和mcamc优化的配置将吞吐率最大提升了48.74%、36.89%、28.17%,最低也能将吞吐率分别提升11.93%、14.68%和9.78%。针对延迟性能,dsst在负载webfile上最低将延迟优化到38.96ms,相比于默认、人工和mcamc配置降低了47.16%、38.87%和41.11%,最差情况下也能将延迟分别降低19.20%、12.46%和7.48%。
[0138]
表3 dsst相比三种配置在吞吐率上的提升比和在延迟上的降低比例
[0139][0140]
综上所述,对比默认配置、人工配置和mcamc优化的配置,dsst最终优化的配置分
别能将吞吐率提升11.93~48.74%、14.68~36.89%、9.78~28.17%,将延迟降低19.20~47.16%、12.46~38.87%、7.48~41.11%,说明dsst系统不仅有效提高了吞吐率,还能降低延迟,证明了本实施例中提出的参数调优系统使用先验知识能够指导模型更精准地对分布式存储系统调参,使得优化的参数更接近最优解,质量更好。
[0141]
(2)参数调优效率对比
[0142]
图11-图18分别显示了在webfile、weblog、oltp和video四种应用负载上,dsst和mcamc前n次迭代过程中吞吐率和延迟的最优值的变化过程,实验针对每一种负载分别采集了mcamc和dsst迭代30次的结果,并标记了迭代过程中吞吐率和延迟最优点的坐标。
[0143]
如图11和图12所示,dsst和mcamc系统在优化负载webfile的过程中吞吐率和延迟的收敛过程,可以看出dsst系统在迭代过程中性能变化较明显,说明dsst搜索了比mcamc更广阔的参数空间。dsst优化过程中当吞吐率和延迟收敛到最优时,分别需要15和3次迭代,而mcamc分别需要29和30次,说明dsst在负载webfile上的优化效率高于mcamc。
[0144]
如图13和图14所示,在优化负载weblog时最优的吞吐率和延迟的变化情况,在相同的迭代次数时,dsst系统优化得到的参数对应的吞吐率都高于mcamc,而延迟都低于mcamc。同时当收敛至最优解时,dsst需要比mcamc少10次的迭代次数,说明dsst在优化负载weblog时能够更快地搜索到接近最优的解。
[0145]
如图15和图16所示,在优化负载oltp时,dsst的收敛至最优解时所需的迭代次数比mcamc少9次,且dsst在优化过程中达到的吞吐率的极大值明显高于mcamc,延迟的极小值也低于mcamc。
[0146]
如图17和图18所示,在负载video上,在吞吐率性能上两者接近。在延迟性能上,dsst收敛到最优时需要比mcamc多2次的迭代次数,但是延迟降低32.9%。
[0147]
综上所述,在四种负载上,相比于mcamc,dsst普遍能以更少的迭代次数搜索到质量更好的参数解。总体而言,在基于openstack swift系统和真实环境特征的负载,依据实施例1提出的一种基于贝叶斯优化先验的分布式存储系统参数调优方法所实现的调参系统对比默认参数和人工配置参数可以有效提高吞吐率,降低延迟,使得优化的参数更接近最优解。
[0148]
本实施例通过针对多个优化目标建立独立的贝叶斯优化模型,然后进行参数综合,将优化得到的结果转化为先验知识,用于初始化多目标进化算法的初代种群,能够提高优化的参数质量,加快迭代速度。
[0149]
实施例3:
[0150]
本实施例用于提供一种分布式存储系统的参数调优设备,包括:
[0151]
处理器;以及
[0152]
存储器,其中存储计算机可读程序指令,
[0153]
其中,在所述计算机可读程序指令被所述处理器运行时执行如实施例1所述的参数调优方法。
[0154]
实施例4:
[0155]
本实施例用于提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现实施例1所述参数调优方法的步骤。
[0156]
尽管在此结合各实施例对本发明进行了描述,然而,在实施所要求保护的本发明
过程中,本领域技术人员通过查看附图、公开内容、以及所附权利要求书,可理解并实现公开实施例的其他变化。在权利要求中,“包括”(comprising)一词不排除其他组成部分或步骤,“一”或“一个”不排除多个的情况。单个处理器或其他单元可以实现权利要求中列举的若干项功能。相互不同的从属权利要求中记载了某些措施,但这并不表示这些措施不能组合起来产生良好的效果。
[0157]
尽管结合具体特征及其实施例对本发明进行了描述,显而易见的,在不脱离本发明的精神和范围的情况下,可对其进行各种修改和组合。相应地,本说明书和附图仅仅是所附权利要求所界定的本发明的示例性说明,且视为已覆盖本发明范围内的任意和所有修改、变化、组合或等同物。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包括这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1