一种基于多尺度特征融合的视频行人重识别方法
vision and pattern recognition,2017,pp.907-915.)。
8.2017年,zhang等人提出了alignedreid,一个超越人类表现的局部块对齐的方法,均匀分块后通过计算局部块最短路径各部分自动对齐,无需监督和姿态估计。(参考文件:x.zhang,h.luo,and x.fan et al,“alignedreid:surpassing human-level performance in person re-identification,”arxiv preprint arxiv:1711.08184,2017.)
9.2018年,sun等人提出了均匀分块的part-based convolutional baseline(pcb)方法,探讨了较优的块间组合方式,并且进一步提出了基于软划分的refined part pooling(rpp)方法,用注意力机制来对齐各个局部分块。(参考文件:y.sun,l.zheng,yi.yang,q.tian,and s.wang,“beyond part models:person retrieval with refined part pooling(and a strong convolutional baseline),”in proceedings of the european conference on computer vision(eccv),2018,pp.501-518.)
10.2018年,wei等人提出了glad(global-local-alignment descriptor)网络,glad网络在提取到关键点后,将行人分为三个部分分别是头部、上身和下身,提取局部特征,辅助全局特征。(参考文件:l.wei,s.zhang,h.yao,w.gao,and q.tian.“glad:global-local-alignment descriptor for scalable person re-identification,”ieee transactions on multimedia,2018,pp.1-1.)
11.值得注意的是,这些局部特征的方法都是针对基于图像的行人重识别问题而提出的,将这些方法转化并应用到视频行人重识别问题上是一个有价值的研究方向。
12.典型的基于视频的行人重识别系统由一个图像级的特征提取器和一个用来聚合时间特征的提取模块组成。最近的大多数基于视频的人reid方法都基于深度神经网络,并且研究工作主要集中在时间建模部分,即研究如何将一系列图像级特征聚合到视频级特征中。高继扬博士的研究结果表明,在其他模块一致的条件下,时序注意力加权(temporal attention,ta)的方法精确度最高。(参考文件:j.gao and r.nevatia,“revisiting temporal modeling for video-based person reid,”in proceedings of the ieee conference on computer vision and pattern recognition(cvpr),2018.)所以本发明采用时序注意力的时序建模框架,在图像级特征提取器中引入局部特征,将不同尺度的特征进行拼接并依据时序注意力机制进行特征融合,提高视频行人重识别的准确度。
技术实现要素:
13.旨在克服复杂图像级表观特征在视频行人重识别任务中难以进行有效的时序融合的问题,通过提出一种基于多尺度特征融合的视频行人重识别网络模型,同步提取不同尺度的图像级行人表观特征和时序注意力权重,使得图像序列的多尺度特征经过时序模块处理后生成的视频级行人重识别特征能具有更高的区分度。
14.主要从图像级行人重识别表观特征复杂度的角度来研究视频行人重识别问题。大尺度的表观特征关注行人的全局信息而小尺度的表观特征更关注行人的局部信息,因此有理由推断,将不同尺度的特征有效组织起来能够为重识别任务提供更加丰富的特征信息,进而提高重识别的准确度。
15.以pcb-rpp局部特征提取方法为基础,对多尺度特征融合的思想进行了实验验证,以resnet50为骨干网络,设置两个分支,分别提取全局特征和局部特征,最后将全局特征向
量和局部特征向量拼接成多尺度特征向量。如表1所示,在market-1501数据集上多尺度特征的重识别准确率优于单一尺度的全局特征和局部特征。
16.表1多尺度特征融合验证结果
[0017] maprank1rank5rank10resnet50全局特征77.992.196.997.8pcb-rpp局部特征79.191.897.198.0多尺度特征79.892.596.998.0
[0018]
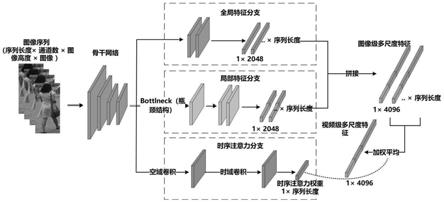
基于以上考虑,本发明提出一种基于多尺度特征融合的视频行人重识别网络模型,该模型由一个共享骨干网络和三个分支组成。其中骨干网络在resnet50基础上进行改造,骨干网络末端连接三个分支,即全局特征分支、局部特征分支和时序注意力分支,分别提取全局特征、局部特征和时序注意力权重,模型将每一帧内的全局特征向量和局部特征向量进行拼接得到多尺度图像级特征向量,最后依据时序注意力权重对每一帧多尺度特征向量进行加权融合得到视频级行人重识别向量。
[0019]
本发明的主要内容具体包括以下步骤:
[0020]
步骤1:基于多尺度融合的视频行人重识别网络设计
[0021]
所设计的基于多尺度特征融合的视频行人重识别网络模型如图1所示,该模型由一个共享骨干网络和三个分支组成。
[0022]
骨干网络在resnet50网络的的基础上取消了最后一层残差结构中的下采样操作,使得输出的特征图尺寸扩大为原来的二倍,从而为局部特征的提取提供了更充分的划分空间。
[0023]
从骨干网络末端得到的特征图上引出三条支路,分别用于提取全局特征、局部特征以及时序信息。
[0024]
在全局特征分支上,特征图经过一次卷积、归一化和池化操作后生成一组2048维的全局特征向量。
[0025]
在局部特征分支上,特征图经过bottleneck解耦后以pcb-rpp算法进行软划分,生成一组2048维的局部特征向量,其中两个局部特征各占1024维。
[0026]
在时序注意力分支上,特征图先后经过时域卷积和空域卷积,生成输入图片序列长度的时序注意力得分,得到时序融合所需要的时序权重。
[0027]
此外,局部分支的的首部添加了两层bottleneck结构,bottleneck为resnet50的基本残差结构,如图2所示。在局部特征支路前端添加此结构能降低全局特征与局部特征之间的耦合,否则两条支路同时由骨干网络输出端直接引出,会使网络在训练时难以收敛。而选择bottleneck结构的原因在于该结构能用足够的深度来解除特征之间的耦合关系,同时残差结构大大降低了网络加深带来的计算负荷。
[0028]
将网络全局特征分支与局部特征分支得到的每一帧的全局特征向量与局部特征向量进行拼接,生成4096维的单帧融合特征;再依据时序注意力分支得到的不同帧的时序注意得分进行加权平均,得到最终的4096维的视频级行人重识别特征向量。
[0029]
步骤2:多特征独立训练策略设计
[0030]
由于网络模型最终生成的特征向量由多个特征向量拼接融合而成,为保证多特征的训练效果,应针对融合后的特征向量进行划分并单独训练。
[0031]
(1)分类器设计
[0032]
训练阶段,为模型输出的时序融合后的特征向量中的每一个拼接部分单独设置一个分类器,即对每个尺度的特征单独训练、分类器参数不共享。其中,分类器为神经网络的全连接层。
[0033]
(2)损失函数
[0034]
对于每一个尺度的特征,其训练用的损失函数由两部分组成,如式(1)所示。
[0035]
lossi=loss
cross entropy
+loss
triplet
ꢀꢀꢀ
(1)
[0036]
其中,loss
cross entropy
和loss
triplet
分别代表交叉熵损失函数和三元组损失函数。
[0037]
最终的损失函数由各部分特征的损失函数求和而得,如式(2)所示。
[0038][0039]
其中,n代表拼接前特征的数量,本发明使用一个全局特征和两个局部特征,因此n为3。
[0040]
(3)训练方法
[0041]
由于局部分支按照pcb-rpp思想进行特征划分,因此模型的训练分为两个阶段:第一阶段,局部特征分支先采取硬划分的方式将特征图均匀分为上下两个局部特征;第二阶段的训练在第一阶段训练收敛的基础上进行,即使用一个分类器代替第一阶段的均匀划分方法,将特征图上的每个点以概率的形式分配给每一个局部特征。
[0042]
此外,两个训练阶段中,网络模型的所有参数均参与迭代。
[0043]
步骤3:网络模型结构参数优化
[0044]
对局部特征数量、局部特征尺寸以及bottleneck数量三个参数对模型性能的影响做对比实验,在mars数据集上进行训练和测试。
[0045]
具体按照局部特征数量、局部特征尺寸和bottleneck数量的先后顺序进行实验优化,每项参数得到优化后固定其优化结果进入下一项参数的优化实验。
附图说明
[0046]
图1是基于多尺度特征融合的视频行人重识别网络模型图。
[0047]
图2是bottleneck结构示意图。
[0048]
图3是实验中使用的数据集样本示例。
[0049]
图4是本发明对图像序列特征提取的可视化热力图。
具体实施方式
[0050]
下面将结合附图和具体的实验实施方式对本发明的技术方案、实验方法和测试结果作更进一步的详细说明。
[0051]
下面具体对实验步骤进行说明。
[0052]
步骤一:构建三分支的卷积神经网络,将训练集样本输入到网络中进行训练,观察训练情况,不断迭代得到训练模型。
[0053]
步骤二:根据训练结果进行测试,对于query中的每一组查询图像序列,从gallery库中查找与其具有相同id的行人图像序列,组成结果序列,并同时计算得到相应的评价指
标。
[0054]
步骤三:根据评价指标,对网络结构参数进行对比实验,确定最优的网络结构参数。
[0055]
下面具体描述实验情况和得到的结论。
[0056]
3.1行人重识别数据集和评价指标
[0057]
接下来对reid实验所使用的测试数据集和评价指标进行介绍。如图3所示,本发明所提出方法在market-1501和mars两个大型公开数据集上进行了测试。其中,market-1501包括由6个摄像头拍摄到的1501个行人、32668个检测到的行人矩形框,训练集有751人,包含12,936张图像,平均每个人有17.2张训练数据;测试集有750人,包含19732张图像,平均每个人有26.3张测试数据。mars基于视频的reid最大的数据集,训练集有625个行人的8298个小段轨迹,包含509914张图片;测试集有636个行人的12180个小段轨迹,包含681089张图片。
[0058]
在行人重识别任务中,测试过程通常是给定一张(视频reid给定一组)待查询的图像(query),然后将其与候选集(gallery)中的图像按照模型计算相似度,再根据相似度从大到小排成一个序列,越靠前的图像与查询图像越接近。为了评价行人重识别算法的性能,目前的做法是在公开数据集上计算相应指标,然后与其他模型对比。cmc曲线(cumulative matching characteristics)和map(mean average precision)是最常用的两个评价标准。
[0059]
在实验中,主要选择了cmc曲线中最常用的rank-1、rank-5和map指标,其中,rank-k是指搜索结果中最靠前(置信度最高)的k张图有正确结果的概率,而map指标实际上相当于一个平均水平,map越高,就说明与query是同一人的查询结果在整个排序列表中是相对越靠前的,说明模型效果也越好。
[0060]
3.2 reid实验主要的参数配置
[0061]
具体训练参数如下:
[0062]
学习率衰减策略使用lr_scheduler.steplr函数,以0.0003为初始学习率,每训练100个epochs学习率衰减为之前的十分之一;视频片段序列长度设置为4,从数据集中随机选取;批大小设置为32;pcb阶段和rpp阶段均各训练400个epochs。
[0063]
3.3重识别网络实验结果
[0064]
基于上述的评价指标和实验细节,基于mars测试进行了测试,得到了每项参数的对比实验结果。
[0065]
(1)局部特征数量
[0066]
实验中的其他参数配置如下:全局特征向量尺寸为2048、局部特征向量尺寸为2048。
[0067]
测试结果如表2所示,两个局部特征性能最优,当局部特征数量增加时,特征尺度变小,对于细粒度的局部特征来说,人在行走时四肢的变化较大,时序加权融合会造成局部信息的模糊。
[0068]
表2局部特征数量对性能的影响
[0069]
数量maprank-1rank-5275.082.093.8373.481.192.9
471.379.192.2
[0070]
(2)局部特征尺寸
[0071]
实验中的其他参数配置如下:局部特征数量为2、bottleneck数量为1、全局特征向量长度为2048。
[0072]
测试结果如表3所示,将局部特征的尺寸缩小一半后,性能有了明显提升,说明全局特征对于重识别性能的影响更大。
[0073]
表3局部特征尺寸对性能的影响
[0074]
尺寸maprank-1rank-5204875.082.093.8102477.783.894.3
[0075]
(3)bottleneck数量
[0076]
实验中的其他参数配置如下:局部特征数量为2、全局特征向量尺寸为2048、局部特征向量尺寸为1024。
[0077]
测试结果如表4所示,在局部特征支路前端添加bottleneck结构能降低全局特征与局部特征之间的耦合,两层bottleneck结构表现性能最好,三层的情况会使得网络难以收敛。
[0078]
表4 bottlencek数量对性能的影响
[0079]
数量maprank-1rank-5077.182.793.8177.783.894.3278.785.194.6374.181.393.3
[0080]
综上所述,使用两个尺寸缩小一半的局部特征并且设置两层bottleneck的情况下,本发明的模型性能最优。
[0081]
3.4特征提取可视化
[0082]
为了观察网络全局特征以及局部特征支路是否按照设计预期提取了图像序列中的不同尺度的特征,本发明使用class activation mapping算法(参考文件:b.zhou,a.khosla,a.lapedriza,a.oliva and a.torralba,"learning deep features for discriminative localization,"in proceedings of the ieee conference on computer vision and pattern recognition(cvpr),2016,pp.2921-2929.)来对不同特征在图像序列上的敏感区域进行可视化,结果如图4所示,全局特征对人的全身进行了特征提取,而两个局部特征则分别专注于头部以及腿部特征,说明各个尺度的特征有效地提取了行人不同位置和不同粒度的特征。
[0083]
3.5与其他方法的比较
[0084]
在不使用re-ranking等技巧的条件下,在mars数据集上,本发明与主流方法的比较中达到了一个有竞争力的水平,如表5所示,本发明与baseline相比,map与rank-1指标分别提升了3.3%和3.4%。
[0085]
表5与其他方法的对比结果
[0086][0087]
综上所述,本发明提出了一种基于多尺度特征融合的视频行人重识别模型,该模型的时间信息处理模块采用了时序注意力的特征聚合方法,单帧特征提取模块能有效提取与之适应的多尺度融合特征,既提高特征的区分度的同时又能与时间信息处理模块有效合作。此外,对模型中局部特征的数量以及尺寸进行了对比实验,得到了本发明的算法框架下最优的局部特征参数。还优化了骨干网络与不同尺度特征提取分支之间的连接结构,降低了不同分支对骨干网络依赖的耦合性。最终,通过测试,本发明相比baseline性能显著提高,并且达到了一个有竞争力的水平。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1