一种基于外部三元组和抽象关系的图像描述生成方法
1.本文发明涉及图像描述生成方法,具体来讲是一种基于外部三元组和抽象关系的图像描述生成方法,属于图像描述生成领域。
背景技术:
2.图像描述生成是计算机视觉和自然语言处理相结合的综合性任务,具有极大的挑战性。受到自然语言处理领域编码解码器、注意力机制与基于强化学习的训练目标启发,现代图像描述生成模型取得了惊人的进展,研究者对图像描述生成领域的关注也日益增长。在一些评价指标上甚至超过了人类。
3.图像描述生成方法的技术不断发展,但是存在一个从未解决但是不容忽视的问题,就是现有模型仅是对图像中显著目标的简单描述,生成的效果甚至不如对图像进行一系列的目标检测。在上下文推理的过程中,人会利用之前学习到的知识,帮助我们更好完成地完成推理。此外,有研究表明,基于视觉的语言生成并非是端到端的,而是与高层抽象符号有关。如果把视觉场景抽象成符号,生成过程就会变得清晰。受此启发,本文从图像描述中提取三元组,构建外部关系库,根据图像的目标类别查询相似关系,为模型提供先验知识。同时,将三元组进行抽象聚类,生成抽象关系,提高模型预测的准确性。
技术实现要素:
4.本发明的目的是针对现有技术的不足,提供一种基于外部三元组和抽象关系的图像描述生成方法,以解决传统的图像描述生成方法无法生成的描述过于简单的问题,并且在原有基础上提高预测准确性。
5.本发明有益效果如下:
6.本发明从图像描述中提取三元组,构建外部关系库,将与图像相关的相似关系融入模型中,使模型生成描述的表述更加丰富。
7.本发明根据文本相似度将三元组聚类,生成抽象关系并融入模型中,使得模型生成的描述更加准确。
附图说明
8.图1是本发明的整体实施方案流程图
9.图2是本发明的构建外部三元组与抽象关系示意图
10.图3是本发明的场景图生成示意图
11.图4是本发明的图像描述生成示意图
12.图5是本发明的整体结构示意图
具体实施方式
13.下面结合附图对本发明作进一步描述。
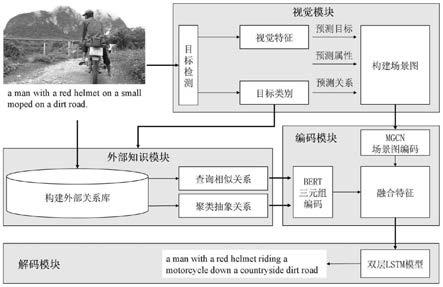
14.参照图1和5所示是本发明的整体实施方案流程图。
15.为了解决这些问题,本发明在构建了外部关系库,根据图像目标类别从库中查询相似关系与抽象关系,与场景图特征相融合。具体来说,首先使用开放域知识抽取工具,提取图像描述文本中的三元组,构建外部关系库,并对三元组进行特征编码。根据三元组中关系的文本相似度,将相似度高的三元组聚类为一类,称之为抽象关系。同时,模型对图像进行目标检测,得到目标视觉特征与语义标签。模型根据文本相似度,在外部关系库中查询主语或宾语与语义标签相似的三元组。然后,模型利用目标视觉特征,对图像的目标、属性、关系分别进行预测,生成场景图,并利用多模态图卷积神经网络融合视觉特征与文本特征,对目标、属性、关系进行特征编码。最后,融合场景图目标、属性、关系编码特征与相似关系和抽象关系的编码特征,输入到双层lstm序列生成模型中,得到最终的图像描述。
16.参照图1和5所示,一种基于外部三元组和抽象关系的图像描述生成方法,包括以下步骤:
17.一种基于外部三元组和抽象关系的图像描述生成方法,包括以下步骤:
18.步骤(1)使用开放域知识抽取工具,提取图像描述文本中的三元组,构建外部关系库,并对三元组进行特征编码;
19.步骤(2)根据三元组中关系rel的文本相似度,将文本相似度高于设定阈值的三元组聚类为一类,称之为抽象关系r
abs
;
20.步骤(3)对图像进行目标检测,得到目标视觉特征集合v与目标类别集合w;根据文本相似度,在外部关系库中查询主语或宾语(即目标obj)与目标类别相似的三元组,称之为相似关系r
sim
;
21.步骤(4)利用目标视觉特征v,对图像的目标obj、属性attr、关系rel分别进行预测,生成场景图;并利用多模态图卷积神经网络mgcn融合目标视觉特征与目标类别w的词向量,对目标obj、属性attr、关系rel进行特征编码;
22.步骤(5)图像描述生成模型用于融合场景图编码特征与关系编码特征,得到融合特征;所述的关系编码特征包括相似关系的编码特征和抽象关系的编码特征;融合特征输入到图像描述生成模型的双层lstm解码器中进行训练,挑选最优训练模型;将图像输入训练好的图像描述生成模型,输出对应的图像描述。
23.进一步的,如图2所示,步骤(1)所述具体实现过程如下:
24.1-1使用mscoco与visual genome数据集中的图像文本描述,利用开放域知识抽取工具openie,提取图像文本描述中的三元组r={subject,predicate,object},构建外部关系库;
25.1-2使用预训练语言模型bert对图像文本描述进行编码,得到所有图像文本描述中每个单词的特征编码;设图像文本描述由k个单词构成,则该段图像文本描述的特征向量为{e0,e1,e2,...,ek,...,ek},其中ek表示第k个单词的特征编码,为768维特征向量;
26.1-3由于提取的三元组是在图像文本描述中出现过的单词,假设三个单词在图像文本描述中的位置为i,j,k,则三元组的编码特征d为三元组在描述对应位置的特征编码的平均值,如公式(1)所示;
27.28.进一步的,步骤(2)所述具体实现过程如下:
29.2-1计算文本相似度,使用余弦相似度作为计算函数,假设两个三元组的编码特征分别为di′
,dj′
,则两个三元组的相似度如公式(2)所示;
[0030][0031]
其中,i
′
、j
′
表示第i
′
、j
′
个三元组,取值范围为1到n
t
,n
t
表示三元组的个数;
[0032]
2-2使用无监督文本聚类算法,将文本相似度大于设定阈值的三元组聚为一类,称之为抽象关系r
abs
;
[0033]
2-3对抽象关系r
abs
进行特征表示,假设抽象关系r
abs
存在k1个三元组,则抽象关系即三元组集合则该类抽象关系r
abs
的特征编码如公式(3)所示;
[0034][0035]
其中,d
′k′
表示三元组r
′k′
对应的编码特征。
[0036]
进一步的,步骤(3)所述具体实现过程如下:
[0037]
3-1使用在visual genome数据集上预先训练的faster rcnn对图像进行目标检测,faster rcnn能够获得目标类别w以及相应目标在图像中的区域以及特征;针对图像i,取faster rcnn最终输出并得到的目标类别集合w={w1,w2,...,ws},ws∈rd以及目标视觉特征集合v={v1,v2,...,vs},vs∈rd,如公式(4)所示;
[0038]
w,v=faster rcnn(i)#(4)
[0039]
3-2根据目标类别集合w,按照公式(2)计算文本相似度,在外部关系库中查询与目标类别相似的三元组,称之为相似关系r
sim
;
[0040]
3-3与抽象关系类似,对相似关系r
sim
进行特征表示,假设相似关系存在k2个三元组,则相似关系即三元组集合组,则相似关系即三元组集合则该类相似关系r
sim
的特征编码如公式(5)所示;
[0041][0042]
其中,d
″k″
表示三元组d
″k″
对应的编码特征。
[0043]
进一步的,如图3所示,步骤(4)所述具体实现过程如下:
[0044]
4-1利用目标视觉特征v,对图像的目标obj、属性attr、关系rel分别进行预测,生成场景图;对于目标,利用faster rcnn进行目标检测;对于属性,利用预先训练的属性分类器进行属性预测;对于关系,利用motifs场景图生成模型进行关系检测;最终分别得到目标obj、属性attr、关系rel的类别词向量eo,ea,er以及它们对应的视觉特征vo,va,vr;
[0045]
4-2为了获得更好的节点特征,融合对应类别词向量与视觉特征,通过公式(6)得到新的融合节点特征uo,ua,ur,其中w1,w2是融合参数;
[0046]
u=relu(w1e+w2v)-(w1e-w2v)2#(6)
[0047]
4-3将融合后的融合节点特征uo,ua,ur输入到多模态图卷积神经网络mgcn中进行
编码,得到场景图编码特征如公式(7)至公式(9)所示;
[0048][0049][0050][0051]
其中,fr,fa,fo为参数相互独立的网络,该网络由全连接层与一层relu层构成;o
x
为第x个目标节点,r
x,y
为第x个目标与第y个目标的关系节点,oy为第y个目标的目标节点;a
x,l
为第x个目标节点的第l个属性节点;sbj(o
x
)为与第x个目标节点相连的主语节点集合,o
p
为其中的主语目标;obj(o
x
)为第x个目标节点的宾语节点集合,oq为其中的宾语目标;na
x
,nr
x
分别为第x个目标的属性节点数量与关系节点数量;u是融合节点特征。
[0052]
进一步的,如图4所示,步骤(5)所述具体实现过程如下:
[0053]
5-1将归纳偏置融入到图像描述生成模型中,模型融合场景图编码特征与关系的编码特征,得到最终的融合特征v^,如公式(10)所示;
[0054]
v^=dα=d
·
softmax(d
t
v`)#(10)
[0055]
其中,d是相似关系编码特征d
sim
与抽象关系编码特征d
abs
的拼接,v
′
是场景图编码特征的拼接;
[0056]
5-2在mscoco数据集上进行端到端的训练,epoch设置为20,学习率为0.00001,batch size为16,使用adam优化器渐进式的调整学习率;在推理过程中使用波束搜索,波束大小为5;利用标准的交叉熵损失来训练模型,公式(11)所示;
[0057][0058]
其中,t为输入序列的长度,y
t
的为输入第t个特征后生成的单词,y
1:t
为真实描述的第1至t个单词,θ为模型参数;
[0059]
5-3将测试图像输入到模型中,获得图像描述。
[0060]
基于本专利发明的图像描述生成方法与现有的基准模型和基于先验知识的图像描述生成模型进行对比,对比结果如表(1)所示:
[0061]
模型b@1b@4mrcsup-down79.836.327.759.6120.121.4sgae81.039.028.458.9129.122.2本专利81.539.728.960.1130.224.1
[0062]
其中,up-down是现有的基准模型,sgae是基于先验知识的图像描述生成模型;b@n表示bleu@n(n=1,4),m表示metor,r表示rouge-l,c表示cider-d,s表示spice,均为图像描述模型的评价指标,评价指标越高,说明生成的描述越准确。从表中可得,本专利在上述评
价指标上均与其他模型有较高的提升,说明基于外部三元组和抽象关系的图像描述生成方法在提高图像描述生成上发明有效。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1