一种大规模集群运维监控方法与流程
1.本发明涉及移动通信技术领域,特别涉及一种大规模集群运维监控方法。
背景技术:
2.随着科技信息产业的发展,特别是大数据等新兴信息技术的出现和迅猛发展,越来越多的公司业务在集群中运行,企业的日常运行也越来越离不开集群服务器以及各类运行在上面的业务软件的支持。因此,对集群中的各个设备以及软件进行运维监控,及时发现问题,具有重大意义。
3.但目前的企业运维监控平台目前存在如下问题。
4.(1)缺乏易于部署与配置的机制,当监控的主机越来越多时,添加主机非常麻烦,且程序消耗过多主机系统资源;
5.(2)监控无法定制化或自由度低,往往只能针对主机硬件、网络、存储和计算资源的监控,很难针对具体业务场景或应用程序进行监控,定制化监控成本高;
6.(3)监控程序消耗的资源比较多,如果监控的主机非常多时,易出现监控超时甚至监控程序卡死;
7.(4)受限于单台主监控端的存储和计算资源限制,历史数据的查询和留存周期短。
技术实现要素:
8.现有技术中,大规模集群监控时,缺乏易于部署和配置的机制、监控无法定制化或自由度低及定制化监控成本高,监控程序消耗资源多且历史数据查询留存周期短。
9.针对上述问题,提出一种大规模集群运维监控方法,通过在主控端部署ansible分发工具,并利用ansible分发工具将监控信息采集程序分发给集群中被监控主机;利用监控信息采集程序获取集群中被监控主机数据信息。本技术中大规模集群运维监控部署简单、全流程可追溯,历史数据追溯时间长,监控程序稳定性高,监控告警时延可控,提高了监控效率,解决了现有技术存在的问题。
10.一种大规模集群运维监控方法,用于对大规模集群进行监控,包括:
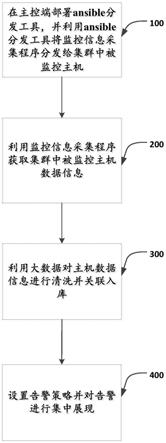
11.步骤100、在主控端部署ansible分发工具,并利用所述ansible分发工具将监控信息采集程序分发给集群中被监控主机;
12.步骤200、利用监控信息采集程序获取集群中被监控主机数据信息;
13.步骤300、利用大数据对所述主机数据信息进行清洗并关联入库;
14.步骤400、设置告警策略并对告警进行集中展现。
15.结合本发明所述的大规模集群运维监控方法,第一种可能的实施方式中,所述步骤100包括:
16.步骤110、对所述ansible分发工具进行第一文件配置,以获取被监控主机第一信息;
17.步骤120、对所述ansible分发工具进行第二文件配置,以获取被监控主机第二信
息;
18.其中,所述第一文件配置为inventory文件配置,第一信息为被监控主机信息,所述第二文件配置为json格式文件配置,第二信息包括单个特定监测主机的账号密码、数据路径、程序名称、配置参数值、状态监测脚本路径。
19.结合本发明第一种可能的实施方式,第二种可能的实施方式中,所述步骤100还包括:
20.步骤130、嵌套使用所述ansible分发工具中的多个分发模块;
21.步骤140、启动分发程序,将所述监控信息采集程序并发给集群中被监控主机;
22.其中,所述分发模块包括ping模块、setup模块、script模块、register模块及command模块。
23.结合本发明第二种可能的实施方式,第三种可能的实施方式中,所述步骤200包括:
24.步骤210、采用python编写所述监控信息采集程序;
25.步骤220、在所述监控信息采集程序嵌入拉取模块及定制模块;
26.其中,所述拉取模块用于控制端主程序从被监控主机拉取数据信息,所述定制模块用于通过程序定制使得所述监控信息采集程序支持python格式文件、java格式文件。
27.结合本发明第三种可能的实施方式,第四种可能的实施方式中,所述步骤200还包括:
28.步骤230、被监控主机执行所述监控信息采集程序,对采集的数据信息大小进行判断;
29.步骤240,若所述采集的数据信息值小于规定阈值,则利用所述ansible分发工具返回值采集;
30.步骤250,若所述采集的数据信息大小大于规定阈值,则自定义脚本在被监控主机端以文档形式推送回主程序。
31.结合本发明第三种可能的实施方式,第五种可能的实施方式中,所述步骤200还包括:
32.步骤260、被监控主机执行所述监控信息采集程序,对采集的数据信息大小进行判断;
33.步骤270、若所述采集的数据信息值小于规定阈值,则利用主程序注册变量拉回。
34.结合本发明第四种可能的实施方式,第六种可能的实施方式中,所述步骤300包括:
35.步骤310、所述监控信息采集程序从获取的数据信息中提取特定字段,并对特定字段进行列表存储,获取存储列表;
36.步骤320、将被监控主机中的监控对象抽象多个对象子表;
37.步骤330、根据数据清洗算法,对获取的数据信息进行清洗;
38.步骤340、将清洗后的数据与对象子表进行批量关联。
39.结合本发明第六种可能的实施方式,第七种可能的实施方式中,所述步骤310包括:
40.步骤311、建立hive表,对所述监控信息采集程序推送过来的hdfs数据进行分类;
41.步骤312、从分类后的hdfs数据提取字段数据信息并将所述字段数据信息存储在所述hive表中。
42.结合本发明第七种可能的实施方式,第八种可能的实施方式中,所述步骤400包括:
43.步骤410、对被监控主机多维度监控;
44.步骤420、根据对被监控主机监控维度,对监控数据进行多维度告警。
45.结合本发明第八种可能的实施方式,第九种可能的实施方式中,所述步骤400还包括:
46.步骤430、将告警结果进行历史记录;
47.步骤440、通过web页面告警、短信告警、邮件告警对所述告警结果进行集中呈现。
48.实施本发明中的大规模集群运维监控方法,通过在主控端部署ansible分发工具,并利用ansible分发工具将监控信息采集程序分发给集群中被监控主机;利用监控信息采集程序获取集群中被监控主机数据信息;利用大数据对主机数据信息进行清洗并关联入库;设置告警策略并在控制端进行集中展现。有益效果如下:
49.(1)部署简单、全流程可追溯。不需要提前在被监控主机上安装任何程序,采集完成后机器也无文件残留,对监控主机影响小,同时采集、提取到监控告警每一步流程均有实时结果反馈,方便监控缺失、故障的情况下问题定位、解决。
50.(2)历史数据追溯时间长。历史数据保存在hive表中,以分区表的形式存储,数据留存周期可达十数年甚至更长。
51.(3)监控程序稳定性高,监控告警时延可控。采用多线程异步的方式发送采集指令,大部分采集数据通过被检测端主动推送回采集服务器,只有少部分数据通过拉取的方式获得,最大程度保证不阻塞在采集程序。在数据提取模块,依靠大数据集群的算力,同时提取任务不仅有数据驱动,还有时间驱动,保证监控数据能在规定时间处理完毕,提高了监控效率。
附图说明
52.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
53.图1是本发明中大规模集群运维监控方法第一实施例示意图;
54.图2是本发明中大规模集群运维监控方法第二实施例示意图;
55.图3是本发明中大规模集群运维监控方法第三实施例示意图;
56.图4是本发明中大规模集群运维监控方法第四实施例示意图;
57.图5是本发明中大规模集群运维监控方法第五实施例示意图;
58.图6是本发明中大规模集群运维监控方法第六实施例示意图;
59.图7是本发明中大规模集群运维监控方法第七实施例示意图;
60.图8是本发明中大规模集群运维监控方法第八实施例示意图;
61.图9是本发明中大规模集群运维监控方法第九实施例示意图;
62.图10是本发明中大规模集群运维监控方法第十实施例示意图;
63.图11是本发明中大规模集群运维监控系统框架实施例示意图;
具体实施方式
64.下面将结合发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的其他实施例,都属于本发明保护的范围。
65.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
66.现有技术中,大规模集群监控时,缺乏易于部署和配置的机制、监控无法定制化或自由度低及定制化监控成本高,监控程序消耗资源多且历史数据查询留存周期短。
67.针对上述问题,提出一种大规模集群运维监控方法。
68.一种大规模集群运维监控方法,如图1,图1是本发明中大规模集群运维监控方法第一实施例示意图,用于对大规模集群进行监控,包括:步骤100、在主控端部署ansible分发工具,并利用ansible分发工具将监控信息采集程序分发给集群中被监控主机;步骤200、利用监控信息采集程序获取集群中被监控主机数据信息;步骤300、利用大数据对主机数据信息进行清洗并关联入库;步骤400、设置告警策略并对告警进行集中展现。
69.通过在主控端部署ansible分发工具,并利用ansible分发工具将监控信息采集程序分发给集群中被监控主机;利用监控信息采集程序获取集群中被监控主机数据信息。本技术中大规模集群运维监控部署简单、全流程可追溯,历史数据追溯时间长,监控程序稳定性高,监控告警时延可控,提高了监控效率,解决了现有技术存在的问题。
70.优选地,如图2,图2是本发明中大规模集群运维监控方法第二实施例示意图,步骤100包括:步骤110、对ansible分发工具进行第一文件配置,以获取被监控主机第一信息;步骤120、对ansible分发工具进行第二文件配置,以获取被监控主机第二信息;其中,第一文件配置为inventory文件配置,第一信息为被监控主机信息,第二文件配置为json格式文件配置,第二信息包括单个特定监测主机的账号密码、数据路径、程序名称、配置参数值、状态监测脚本路径。
71.在主控端部署ansible工具,配置工具中的inventory文件添加主机信息,针对具体业务监控而言,还需要配置json格式文件,其中应包含但不限于单个特定监测主机的账号密码(password)、数据路径(data_path)、程序名称(program_name)、配置参数值(spe_parameter)、状态监测脚本路径(status_shell)等。
72.优选地,如图3,图3是本发明中大规模集群运维监控方法第三实施例示意图,步骤100还包括:步骤130、嵌套使用ansible分发工具中的多个分发模块;步骤140、启动分发程序,将监控信息采集程序并发给集群中被监控主机;其中,分发模块包括ping模块、setup模块、script模块、register模块及command模块。
73.优选地,如图4,图4是本发明中大规模集群运维监控方法第四实施例示意图,步骤
200包括:步骤210、采用python编写监控信息采集程序;步骤220、在监控信息采集程序嵌入拉取模块及定制模块;其中,拉取模块用于控制端主程序从被监控主机拉取数据信息,定制模块用于通过程序定制使得监控信息采集程序支持python格式文件、java格式文件。
74.监控信息采集程序主程序由python编写,调用scheduler包实现定时拉取功能;分发程序由main.yml启动,嵌套使用ansible的ping、setup、script、register、command等功能,进行程序分发,可实现稳定、高并发的把采集程序发送到各个主机;监控信息采集程序可以原生支持shell脚本,通过定制化模块可支持python、java程序等,十分便于采集机器硬件信息、业务数据达到检查、业务程序状态检查等信息。
75.优选地,在一个实施方式中,如图5,图5是本发明中大规模集群运维监控方法第五实施例示意图,步骤200还包括:步骤230、被监控主机执行监控信息采集程序,对采集的数据信息大小进行判断;步骤240、若采集的数据信息值小于规定阈值,则利用ansible分发工具返回值采集;步骤250、若采集的数据信息大小大于规定阈值,则自定义脚本在被监控主机端以文档形式推送回主程序。
76.优选地,在另一个实施方式中,如图6,图6是本发明中大规模集群运维监控方法第六实施例示意图,步骤200还包括:步骤260、被监控主机执行监控信息采集程序,对采集的数据信息大小进行判断;步骤270、若采集的数据信息值小于规定阈值,则利用主程序注册变量拉回。
77.数据通过网络并行传输,并在被控端执行监控信息采集程序,当采集信息较小时直接由ansible返回值或内部注册变量采集,当信息量较大时可自定义脚本在被控端另起进程已文档形式后台推送回主机,避免主程序卡死;后由主程序进行监控信息数据达到和质量检查,集中推送回大数据集群中。
78.传统的监控平台当服务器超过1000台以后就经常罢工,有时候监控数据不能及时显示,有时候告警迟迟不来。本技术中的分发程序都采用多线程异步的方式发送采集指令,大部分采集数据通过被检测端主动推送回采集服务器,只有少部分数据通过拉取的方式获得,最大程度保证不阻塞在采集程序。在数据提取模块,依靠大数据集群的算力,同时提取任务不仅有数据驱动,还有时间驱动,保证监控数据能在规定时间处理完毕。
79.优选地,如图7,图7是本发明中大规模集群运维监控方法第七实施例示意图,步骤300包括:步骤310、监控信息采集程序从获取的数据信息中提取特定字段,并对特定字段进行列表存储,获取存储列表;步骤320、将被监控主机中的监控对象抽象多个对象子表;步骤330、根据数据清洗算法,对获取的数据信息进行清洗;步骤340、将清洗后的数据与对象子表进行批量关联。
80.优选地,如图8,图8是本发明中大规模集群运维监控方法第八实施例示意图,步骤310包括:步骤311、建立hive表,对监控信息采集程序推送过来的hdfs数据进行分类;步骤312、从分类后的hdfs数据提取字段数据信息并将字段数据信息存储在hive表中。
81.监控集群中的数据提取模块主要依靠大数据集群冗余的算力和存储能力完成数据清洗和关联。(1)建立hive表,对采集模块推送过来的hdfs数据分类并提取有用字段导入到hive表中。(2)对监控对象抽象成子表,比如机器健康度表(磁盘\io\内存\cpu占用率\文件打开数等)、业务数据质量表(文件名\达到数据\所属时间\延时时间\文件个数\数据总量等)、程序运行状态表(程序名\程序运行节点\状态\jvm情况\日志路径\是否报错等)等。
(3)建立清洗算法进行数据清洗,以批处理的形式进行数据关联,针对各类监控对象实体可使用sql、python、java等语言编写任务。
82.优选地,如图9,图9是本发明中大规模集群运维监控方法第九实施例示意图,步骤400包括:步骤410、对被监控主机多维度监控;步骤420、根据对被监控主机监控维度,对监控数据进行多维度告警。
83.优选地,如图10,图10是本发明中大规模集群运维监控方法第十实施例示意图,步骤400还包括:步骤430、将告警结果进行历史记录;步骤440、通过web页面告警、短信告警、邮件告警对告警结果进行集中呈现。
84.在对被监控主机多维度监控实施方式中,可以将告警分为分钟粒度、小时粒度与天粒度。优选的,分钟粒度主要有:网络丢包告警、宕机告警、磁盘满载告警、内存不足告警、程序死亡告警、流量异常等重大告警;小时粒度主要有:程序遇错告警、业务数据延迟告警,业务数据断传告警等;优选地,天粒度主要有:集群任务完成度告警、数据总量告警、程序处理总量告警等。形成任务运行监控、资源监控、磁盘监控、网络监控、数据质量监控等。
85.优选地,在一个实施方式中,本技术还包括:
86.在监控集群中对被监控主机进行自定义监控,筛选重复监控业务;
87.对被监控主机进行业务系统的运行逻辑。
88.本技术公开一种大规模集群运维监控系统,如图11,图11是本发明中大规模集群运维监控系统框架实施例示意图,包括数据收集模块、数据提取模块、监控告警模块。数据收集模块主要完成基础数据收集。利用ansible分发工具,可以实现数据收集的方式有很多种,可以通过模块返回值实现,也可以通过模块内部注册变量实现,还可以通过自定义脚本实现。数据提取模块主要完成数据的筛选过滤和关联入库,将需要的数据从数据收集模块计算提取到监控告警模块中,主要把文本文件、数据库文件等传入大数据集群中进行清洗、计算和持久化。监控告警模块主要完成告警规则设置、告警阈值设置、告警联系方式设置等,并将告警结果进行集中展现和历史记录。告警方式可支持web页面告警、短信告警、邮件告警等。
89.实施本发明中的大规模集群运维监控方法,通过在主控端部署ansible分发工具,并利用ansible分发工具将监控信息采集程序分发给集群中被监控主机;利用监控信息采集程序获取集群中被监控主机数据信息;利用大数据对主机数据信息进行清洗并关联入库;设置告警策略并在控制端进行集中展现。有益效果如下:
90.(1)部署简单、全流程可追溯。不需要提前在被监控主机上安装任何程序,采集完成后机器也无文件残留,对监控主机影响小,同时采集、提取到监控告警每一步流程均有实时结果反馈,方便监控缺失、故障的情况下问题定位、解决。
91.(2)历史数据追溯时间长。历史数据保存在hive表中,以分区表的形式存储,数据留存周期可达十数年甚至更长。
92.(3)监控程序稳定性高,监控告警时延可控。采用多线程异步的方式发送采集指令,大部分采集数据通过被检测端主动推送回采集服务器,只有少部分数据通过拉取的方式获得,最大程度保证不阻塞在采集程序。在数据提取模块,依靠大数据集群的算力,同时提取任务不仅有数据驱动,还有时间驱动,保证监控数据能在规定时间处理完毕,提高了监控效率。
93.以上仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1