一种基于深度学习的密码字典生成技术
1.本发明涉及密码数据技术领域,具体为一种基于深度学习的密码字典生成技术。
背景技术:
2.互联网发展的同时伴随着各种安全事件,有很多密码数据集被泄露,被泄露的用户密码也反映出用户设置密码的一些信息。有了这些数据集,密码攻击、密码生成、用户密码习惯等方面的研究层出不穷,其中密码生成已成为提高社会工程学中身份验证效率的新兴问题,并且在检查安全漏洞中起着重要作用。
3.与传统方法相比,越来越多的研究人员证明神经网络中的方法对于密码猜测更为准确和实用。同时,学习人类创造的密码,可以训练生成更符合人类生成密码习惯的模型,通过得到的模型去生成“拟人化”的密码字典,使生成的密码字典在密码猜测过程中表现更好。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种基于深度学习的密码字典生成技术,可以生成更符合人类生成密码的习惯的密码字典,使基于深度学习的密码猜测相较于遍历弱密码字典、暴力破解密码等传统方法能有更好的效果。
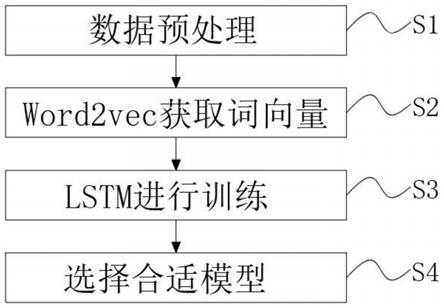
5.为实现以上目的,本发明通过以下技术方案予以实现:一种基于深度学习的密码字典生成技术,具体包括以下步骤:
6.s1、对于密码数据集进行清洗,筛选出符合实验要求的密码,筛选出包含的字符是字母、数字、符号的组合,并且长度是8-16位的密码。并且将数据集分成训练集、验证集和测试集;
7.s2、word2vec对于密码进行词嵌入处理获得组成密码的字符对应的字符向量,对下一步输入lstm神经网络做准备;
8.s3、用获取s2生成的字符向量,组成由字符向量组成的输入列表,不足16位的用空格字符向量补全,作为整个模型的输入;根据字符对应的ascii码作为标签,包含除去第一位的所有字符,由固定数值m补足16位;
9.s4、将s3中处理好的向量输入到lstm神经网络模型中,设置好输出列表的大小,选择交叉熵来计算模型的损失,通过数次训练得到损失小效果优的模型参数,用作密码字典的生成;
10.s5、使用s4得到的模型,进行密码字典生成。
11.优选的,所述s1中,筛选方法是筛选出包含的字符是字母、数字、符号的组合,并且长度是8-16位的密码,并且将数据集分成训练集、验证集和测试集。
12.优选的,所述s3中,最终,我们需要确定输出什么值,这个输出将会基于细胞状态,但是也是一个过滤后的版本,首先,运行一个sigmoid层来确定细胞状态的哪个部分将输出出去,接着,把细胞状态通过tanh进行处理(得到一个在-1到1之间的值)并将它和sigmoid
门的输出相乘,最终仅仅会输出确定输出的那部分。
13.优选的,所述s5中,密码字典生成具体包括以下步骤:
14.s1、获取所有密码数据的首字母出现的概率,用以后面使用,初始化一个空集s;
15.s2、设置密码字典大小为n,以s内的密码数量count(s)是否小于n为条件循环生成密码序列;
16.s3、初始化空集password,在概率最大的前λ个字符中随机选取一个并添加到password中;
17.s4、以password内的字符数量是否小于等于最大密码长度为条件循环生成密码字符;将password的内容加载到模型当中预测函数得到下一个字符的概率;
18.s5、在概率最大的前λ个字符中随机选取一个并添加到password中直至随机选取的字符为m或password的字符数量等于最大密码长度;
19.s6、当循环等于密码字典大小时,即得到了预期的大小为n的密码字典。
20.有益效果
21.本发明是为了优化已有的遍历弱密码字典、暴力破解等非智能的密码破解方式;相较于pcfg(概率上下文无关文法)、马尔可夫模型、gan等,lstm在自然语言处理方面有更好的表现,故本发明将组成密码的字符当作自然语言当中的单词来进行处理,应用lstm方法可以得到符合人类设置密码习惯的、命中率更高的密码字典,可以对弱密码字典、密码爆破效果有一定的提升,可以应用于各种安全场景。
附图说明
22.图1为本发明深度学习的密码字典生成技术的流程图;
23.图2为本发明lstm神经网络示意图;
24.图3为本发明密码字典生成流程图。
具体实施方式
25.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.请参阅图1-3,本发明提供一种技术方案:一种基于深度学习的密码字典生成技术,具体包括以下步骤:
27.s1、对于密码数据集进行清洗,筛选出符合实验要求的密码,筛选出包含的字符是字母、数字、符号的组合,并且长度是8-16位的密码。并且将数据集分成训练集、验证集和测试集;
28.s2、word2vec对于密码进行词嵌入处理获得组成密码的字符对应的字符向量,对下一步输入lstm神经网络做准备;
29.s3、用获取s2生成的字符向量,组成由字符向量组成的输入列表,不足16位的用空格字符向量补全,作为整个模型的输入;根据字符对应的ascii码作为标签,包含除去第一位的所有字符,由固定数值m补足16位;
30.s4、将s3中处理好的向量输入到lstm神经网络模型中,设置好输出列表的大小,选择交叉熵来计算模型的损失,通过数次训练得到损失小效果优的模型参数,用作密码字典的生成;
31.s5、使用s4得到的模型,进行密码字典生成,同时本说明书中未作详细描述的内容均属于本领域技术人员公知的现有技术。
32.本发明中,所述s1中,筛选方法是筛选出包含的字符是字母、数字、符号的组合,并且长度是8-16位的密码,并且将数据集分成训练集、验证集和测试集。
33.本发明中,所述s3中,最终,我们需要确定输出什么值,这个输出将会基于细胞状态,但是也是一个过滤后的版本,首先,运行一个sigmoid层来确定细胞状态的哪个部分将输出出去,接着,把细胞状态通过tanh进行处理(得到一个在-1到1之间的值)并将它和sigmoid门的输出相乘,最终仅仅会输出确定输出的那部分。
34.本发明中,所述s5中,密码字典生成具体包括以下步骤:
35.s1、获取所有密码数据的首字母出现的概率,用以后面使用,初始化一个空集s;
36.s2、设置密码字典大小为n,以s内的密码数量count(s)是否小于n为条件循环生成密码序列;
37.s3、初始化空集password,在概率最大的前λ个字符中随机选取一个并添加到password中;
38.s4、以password内的字符数量是否小于等于最大密码长度为条件循环生成密码字符;将password的内容加载到模型当中预测函数得到下一个字符的概率;
39.s5、在概率最大的前λ个字符中随机选取一个并添加到password中直至随机选取的字符为m或password的字符数量等于最大密码长度;
40.s6、当循环等于密码字典大小时,即得到了预期的大小为n的密码字典。
41.需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
42.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1