一种融合相邻节点方差的图神经网络CTR预估算法的制作方法
一种融合相邻节点方差的图神经网络ctr预估算法
技术领域
1.本发明涉及的是图神经网络,互联网推荐系统领域,具体涉及一种融合相邻节点方差的图神经网络ctr预估算法。
背景技术:
2.互联网推荐系统在电商、广告、视频等领域有着广泛的应用,通过用户特征、物品特征、用户与物品两者之间的交互,推荐系统可以判断用户对物品的喜好程度,从而将最合适的物品推荐给用户,提高物品点击率与用户满意度。
3.近年来,基于图神经网络的推荐系统迅速发展。相比于传统的深度学习模型,图神经网络能够在由用户、物品组成的图中探索更复杂高阶的交互关系,有助于推荐系统提高性能。图神经网络一般使用消息传播机制,即聚合邻居节点的表征以更新中心节点的表征。常规的聚合方法有最大值、(加权)平均等,这些方法都默认忽略了一个图结构数据特有的问题,即不考虑多个邻居之间差异的大小隐含的信息。本专利针对这一问题,提出一种融合相邻节点方差的图神经网络,进行用户-物品点击率预测。
4.在图结构数据中会出现这样一种情况:两个节点具有相似的特征,这两个节点的邻居的均值也相似,但是他们邻居节点的差异可能不同。例如,两个商家的顾客的注册时长均值差不多,但其中一个商家的顾客的注册时长差异很小,那此商家有可能存在虚假交易套利的情况。常规的图神经网络聚合方法只考虑邻居节点的特征本身,而未考虑到邻居节点之间的差异性也是中心节点的一种特征,忽视了这种在传统结构化数据及图片数据中都不存在的问题。
5.综上所述,本发明设计了一种融合相邻节点方差的图神经网络ctr预估算法。
技术实现要素:
6.针对现有技术上存在的不足,本发明目的是在于提供一种融合相邻节点方差的图神经网络ctr预估算法,可以在建模时将邻居节点的差异性纳入考虑,获得更好的用户与物品表征,进而改善推荐系统的性能,提高点击率预测的准确性。
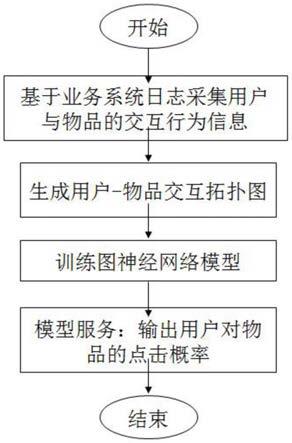
7.为了实现上述目的,本发明是通过如下的技术方案来实现:一种融合相邻节点方差的图神经网络ctr预估算法,包括以下步骤:
8.(1)采集用户与物品的点击交互行为,以及点击发生时间、物品展示形式等上下文信息;
9.(2)生成用户-物品交互拓扑图,以用户、物品作为节点,用户对物品的点击作为边,其他信息作为节点的特征,生成交互拓扑图g=(v,e);
10.(3)训练图神经网络模型;
11.(a)建立一个l层的图神经网络,在每层中使用邻居节点表征的均值与方差拼接成聚合信息,用于更新中心节点的表征;
12.(b)经过l层图神经网络获得用户与物品的表征后,把有连接的用户-物品对记为
正样本,没有连接的用户-物品对记为负样本,把用户表征与物品表征的内积经过logistic函数的值作为用户-物品是否有连接的预测值,输入损失函数进行模型训练;
13.(4)对于候选的用户-物品对,使用上述模型进行前向传播,得到用户是否点击物品的预测值。
14.所述的步骤(3)利用python处理用户-物品交互拓扑图,进行图神经网络训练,具体包括:
15.(a)图神经网络由l层特征变换组成,第t层的计算方法为:记为节点v在t-1层的表征,为节点v的所有邻居节点在t-1层的表征。
16.(b)计算节点v的邻居的方差信息,在每个表征维度计算节点v的邻居表征的方差,如果节点v只有一个邻居,则邻居的方差信息规定为0向量。数学表示为:
[0017][0018]
其中表示的第i个分量。
[0019]
(c)计算节点v的邻居的聚合信息,将节点v的邻居的表征均值(计算方法与方差信息相同)与表征方差拼接到一起形成聚合信息向量。数学表示为:
[0020][0021]
(d)将节点v邻居的聚合信息向量与节点v的表征一起输入全连接层进行变换,然后经过sigmoid激活函数激活,得到节点v在这一层的新表征。数学表示为:
[0022][0023]
(e)重复a)-d)步骤l层以后获得拓扑图中每个节点的表征。把有连接的用户-物品对记为正样本,没有连接的用户-物品对记为负样本,把用户表征与物品表征的内积经过logistic函数的值作为用户-物品是否有连接的预测值,数学表示为:
[0024][0025]
将其输入损失函数中,优化损失函数进行模型训练,保存训练好的模型参数。
[0026]
本发明具有以下有益效果:
[0027]
相比与传统结构化数据与图片数据,图结构数据有一个这两者都不具备的特点,即邻居节点的差异性也是中心节点的一种特征。传统的图神经网络忽略了这一点,因为无论是平均池化、最大值池化还是注意力机制,都无法提取所有邻居的整体统计信息,导致对信息的利用不充分。
[0028]
本发明首次认识到该问题,并创新性地提出新的邻居信息聚合方法,将邻居节点的差异性纳入算法的处理范围,可以更充分地提取用户-物品交互图的信息,让用户表征、物品表征蕴含更准确丰富的信息,提升点击率预测的准确性。
附图说明
[0029]
下面结合附图和具体实施方式来详细说明本发明;
[0030]
图1为本发明的整体流程图;
[0031]
图2为本发明的交互拓扑图(浅色为用户节点,深色为物品节点);
[0032]
图3为本发明的图神经网络示意图。
具体实施方式
[0033]
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
[0034]
参照图1-3,本具体实施方式采用以下技术方案:一种融合相邻节点方差的图神经网络ctr预估算法,包括以下步骤:
[0035]
1.基于业务系统日志,提取用户与物品的点击交互行为,并采集点击时的上下文信息,例如点击发生时间、物品展示形式等等。
[0036]
2.将采集的信息导入图数据库,生成用户-物品交互拓扑图:以用户、物品作为节点,用户对物品的点击作为边,其他信息作为节点的特征,生成交互拓扑图g=(v,e),其中v表示用户节点与物品节点,e表示边,如图2所示。
[0037]
3.利用python处理用户-物品交互拓扑图,进行图神经网络训练,如图3所示。
[0038]
a)图神经网络由l层特征变换组成,第t层的计算方法为:记为节点v在t-1层的表征,为节点v的所有邻居节点在t-1层的表征。
[0039]
b)计算节点v的邻居的方差信息,在每个表征维度计算节点v的邻居表征的方差,如果节点v只有一个邻居,则邻居的方差信息规定为0向量。数学表示为:
[0040][0041]
其中表示的第i个分量。
[0042]
c)计算节点v的邻居的聚合信息,将节点v的邻居的表征均值(计算方法与方差信息相同)与表征方差拼接到一起形成聚合信息向量。数学表示为:
[0043][0044]
d)将节点v邻居的聚合信息向量与节点v的表征一起输入全连接层进行变换,然后经过sigmoid激活函数激活,得到节点v在这一层的新表征。数学表示为:
[0045][0046]
e)重复a)-d)步骤l层以后获得拓扑图中每个节点的表征。把有连接的用户-物品对记为正样本,没有连接的用户-物品对记为负样本,把用户表征与物品表征的内积经过logistic函数的值作为用户-物品是否有连接的预测值,数学表示为:
[0047][0048]
将其输入损失函数中,优化损失函数进行模型训练,保存训练好的模型参数。
[0049]
4.模型服务。对于候选的用户-物品对,使用上述模型进行前向传播,得到用户是否点击物品的预测值,即ctr预测值。
[0050]
实施例1:一种融合相邻节点方差的图神经网络ctr预估算法,包括以下步骤:
[0051]
1、基于业务系统日志,提取用户与物品的点击交互行为,并采集点击时的上下文
信息,例如点击发生时间、物品展示形式等等。
[0052]
a)根据实际场景需要,业务系统日志中记录的点击交互行为包括但不限于用户点击进入商品页面、浏览商品广告一定时长等。
[0053]
b)采集上下文信息,例如用户的年龄、性别、注册时长等,商品的分类、价格、广告文本、页面色调等。
[0054]
c)对于采集到的类别型数据,可以通过onehot编码或embedding转化为数值型数据;对于采集到的文本型数据,可以通过word2vec转化为数值型数据;将得到的数值型数据拼接到一起作为用户与商品的初始特征向量。
[0055]
2、将采集的信息导入图数据库,生成用户-物品交互拓扑图:以用户、物品作为节点,用户对物品的点击作为边,其他信息作为节点的特征,生成交互拓扑图g=(v,e),其中v表示用户节点与物品节点,e表示边,如图2所示。
[0056]
3、利用python处理用户-物品交互拓扑图,进行图神经网络训练,如图3所示。
[0057]
d)先通过mlp(多层感知机)对用户与商品特征进行预处理,使其特征维数相同,可为64维或128维。
[0058]
e)图神经网络模块一般由2到3层特征变换组成,第t层的计算方法为:记为节点v在t-1层的表征,为节点v的所有邻居节点在t-1层的表征。
[0059]
f)计算节点v的邻居的方差信息,在每个表征维度计算节点v的邻居表征的方差,如果节点v只有一个邻居,则邻居的方差信息规定为0向量。数学表示为:
[0060][0061]
其中表示的第i个分量。
[0062]
g)计算节点v的邻居的聚合信息,将节点v的邻居的表征均值(计算方法与方差信息相同)与表征方差拼接到一起形成聚合信息向量。数学表示为:
[0063][0064]
h)将节点v邻居的聚合信息向量与节点v的表征一起输入全连接层进行变换,然后经过sigmoid激活函数激活,得到节点v在这一层的新表征。数学表示为:
[0065][0066]
i)重复b)-e)步骤2到3层以后获得拓扑图中每个节点的表征。把有连接的用户-物品对记为正样本,没有连接的用户-物品对记为负样本。由于用户点击物品的概率远小于不点击的概率,负样本的数量将远大于正样本,通过下采样,只选取一部分的负样本(例如总数不多于正样本的20倍)与正样本一起进行下一步计算。
[0067]
j)把正负样本对的用户表征与物品表征进行内积计算,再输入logistic函数,其输出作为用户-物品是否有连接的预测值,数学表示为:
[0068][0069]
将其输入损失函数中,使用梯度下降优化损失函数进行模型参数的训练,保存训练好的模型。损失函数一般选为交叉熵损失函数,数学表示为:
[0070][0071]
4、模型服务。对于需要预测的用户-物品对,使用模型训练时相同的信息转换方法得到初始特征向量,并将用户-物品对加入训练时所使用的交互拓扑图中,使用训练好的模型进行前向传播,得到用户是否点击物品的预测值,即ctr预测值。一个用户也可对应多个候选物品,分别预测其点击率,将点击率top10的物品返回给用户。
[0072]
本实施例邻居节点特征的方差信息纳入算法中,更充分地提取用户-物品交互拓扑图中的信息,有效提高ctr预估的准确性。本实施例提出了一种新的邻居节点信息的聚合方法,可让用户、物品节点的表征学到邻居的方差信息,从而更充分地表示中心节点的特征,并提高算法的预测性能。
[0073]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1