地址纠错方法、装置、计算机设备及可读介质与流程
本技术属于地理信息,更具体地,涉及一种地址纠错方法、装置、计算机设备及可读介质。
背景技术:
1、在完整的物流配送体系中,配送系统首先需要根据客户下单的地址进行层级匹配,匹配完成后由路由分发系统进行货物的路由分单。然而,由于中文地址写法多样,部分用户无法提供系统可直接识别的规范地址,影响后续的派件业务,甚至导致快件错分。
2、目前常用的解决方案是根据已有地址建立并维护白名单地址库(词典),并预先确定地址文本匹配规则,获取客户提供的地址之后,基于匹配规则将该地址与白名单地址库中的已有地址进行匹配,以此来获取标准地址。但是,这种规则匹配容易出现匹配错误,导致快件路由错误,增加物流成本;与此同时,需要实时维护词典和匹配规则,并且中文地址写法多样,难以建立全面穷举的地址文本与不同地址层级间多对一的映射关系地址库维护成本大。
技术实现思路
1、针对现有技术的至少一个缺陷或改进需求,本技术提供了一种地址纠错方法、装置、计算机设备及可读介质,其目的在于解决现有基于词典匹配的方式确定标准地址,容易出现匹配错误,且地址库维护成本大。
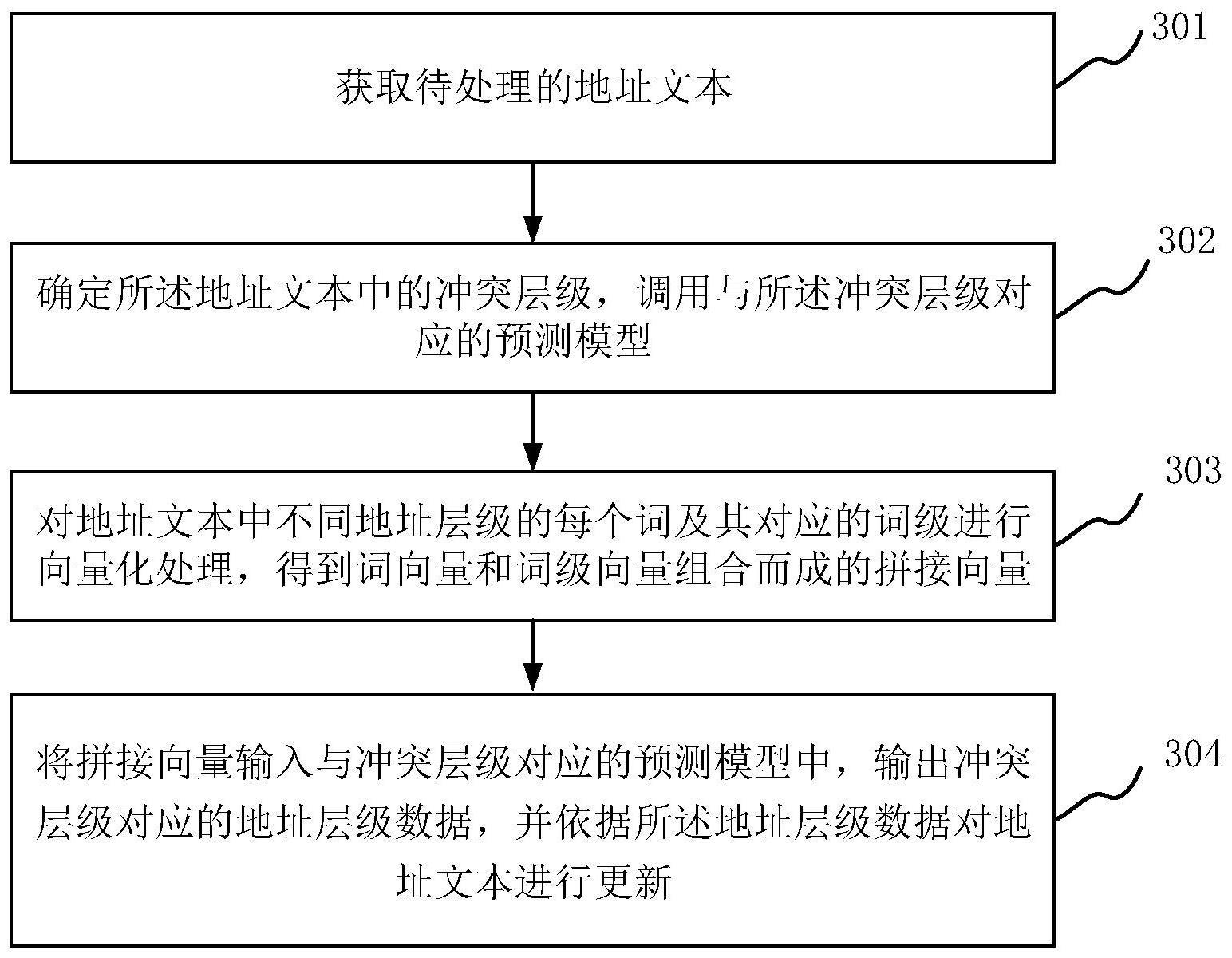
2、为实现上述目的,按照本技术的第一个方面,提供了一种地址纠错方法,该方法包括:
3、获取待处理的地址文本;
4、确定所述地址文本中的冲突层级,调用与所述冲突层级对应的预测模型;
5、对所述地址文本中不同地址层级信息中的每个词及其对应的词级进行向量化处理,得到由词向量和词级向量组合而成的拼接向量;
6、将所述拼接向量输入与冲突层级对应的所述预测模型中,输出冲突层级对应的地址层级数据,并依据所述地址层级数据对地址文本进行更新;其中,所述预测模型为利用具有冲突层级对应的地址层级标签的样本地址文本训练得到,各样本地址文本被处理为拼接向量后与其对应的地址层级标签输入预测模型中。
7、在本技术的一些实施例中,所述获取待处理的地址文本之后,所述方法还包括:
8、将所述地址文本与预先配置的白名单地址库中的标准地址进行匹配,所述白名单地址库用于存储标准地址的地址层级信息之间的关联关系,匹配成功则根据所述关联关系确定所述地址文本中冲突层级对应的地址层级信息。
9、在本技术的一些实施例中,所述确定所述地址文本中的冲突层级,包括:
10、对所述地址文本进行预处理,预处理包括地址文本规范化、地址分词和/或词级过滤;
11、对预处理后的地址文本进行分词处理,得到不同地址层级的地址层级信息;
12、根据各所述地址层级信息之间的层级关系,确定所述地址文本中的冲突层级。
13、在本技术的一些实施例中,所述将所述拼接向量输入与冲突层级对应的所述预测模型中,输出冲突层级对应的地址层级数据,并依据所述地址层级数据对地址文本进行更新,包括:
14、将所述拼接向量输入所述冲突层级对应的预测模型,通过所述预测模型对所述拼接向量卷积处理,得到所述冲突层级对应的候选地址层级数据,以及所述候选地址层级数据对应的置信度;所述预测模型包括一级城市预测模型、二级街道预测模型、三级社区预测模型、四级网点预测模型和五级兴趣面预测模型;
15、将置信度最大的候选地址层级数据设置为所述冲突层级对应的地址层级数据,并依据所述地址层级数据对地址文本进行更新。
16、在本技术的一些实施例中,所述预测模型的训练过程包括:
17、获取第一样本地址文本,所述第一样本地址文本具有冲突层级对应的地址层级标签;
18、对所述第一样本地址文本中不同地址层级的每个词及其对应的词级进行向量化处理,得到由样本词向量和样本词级向量组合而成的样本拼接向量;
19、根据各所述第一样本地址文本对应的样本拼接向量与冲突层级对应的地址层级标签得到第一训练样本集;
20、根据所述第一训练样本集进行模型训练,得到训练好的预测模型。
21、在本技术的一些实施例中,所述根据所述第一训练样本集进行模型训练得,到训练好的预测模型,包括:
22、通过待训练的预测模型,根据所述样本拼接向量生成冲突层级对应的地址层级预测数据;
23、计算所述冲突层级对应的地址层级数据与相应的地址层级标签之间的误差,并根据所述误差反向调整所述待训练的预测模型的模型参数;
24、返回至所述通过待训练的预测模型,根据所述样本拼接向量生成冲突层级对应的地址层级预测数据的步骤继续执行,直至满足迭代停止条件,停止迭代,得到已训练好的预测模型。
25、在本技术的一些实施例中,所述根据所述样本拼接向量生成冲突层级对应的地址层级预测数据具体包括:
26、对所述样本拼接向量进行特征提取,得到相应的最大池化特征向量、平均池化特征向量与权重特征向量;
27、根据所述最大池化特征向量、平均池化特征向量与权重特征向量,生成冲突层级对应的至少一个候选地址层级数据,且每个所述候选地址层级数据具有对应的置信度;
28、选择置信度最大的候选地址层级数据作为冲突层级对应的地址层级预测数据。
29、在本技术的一些实施例中,上述地址纠错方法还包括:
30、当满足模型更新条件时,获取第二训练样本集;所述第二训练样本集包括第二样本地址文本对应的样本拼接向量以及与冲突层级对应的地址层级标签;
31、根据所述第二训练样本集对所述预测模型进行迭代更新,得到更新后的预测模型,并将所述更新后的预测模型作为已训练好的预测模型。
32、按照本技术的第二个方面,还提供了一种地址纠错装置,该装置包括:
33、获取模块,用于获取待处理的地址文本;
34、冲突判断模块,用于确定所述地址文本中的冲突层级;
35、向量生成模块,用于对所述地址文本中不同地址层级信息中的每个词及其对应的词级进行向量化处理,得到由词向量和词级向量组合而成的拼接向量;
36、预测模块,用于将所述拼接向量输入与冲突层级对应的所述预测模型中,输出冲突层级对应的地址层级数据,并依据所述地址层级数据对地址文本进行更新。
37、按照本技术的第三个方面,还提供了一种计算机设备,其包括至少一个处理单元、以及至少一个存储单元,其中,所述存储单元存储有计算机程序,当所述计算机程序被所述处理单元执行时,使得所述处理单元执行上述任一项所述方法的步骤。
38、按照本技术的第四个方面,还提供了一种计算机可读介质,其存储有可由计算机设备执行的计算机程序,当所述计算机程序在计算机设备上运行时,使得所述计算机设备执行上述任一项所述方法的步骤。
39、总体而言,通过本技术所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
40、本技术提供的一种地址纠错方法、装置、计算机设备及可读介质,获取待处理的地址文本后,确定地址文本中的冲突层级并调用与冲突层级对应的预测模型;对地址文本中不同地址层级的每个词及其对应的词级进行向量化处理,得到由词向量和词级向量组合而成的拼接向量;根据拼接向量确定冲突层级对应的地址层级数据,并依据所述地址层级数据对地址文本进行更新;通过不同地址层级对应的预测模型对地址文本中出现冲突的层级数据进行纠错处理,得到标准地址,能够有效减少冲突地址层级信息导致的路由错分问题,从而能直接节约整个物流的成本开支。与此同时,采用深度学习算法能提高对层级结构识别的泛化能力及准确性,不需要依赖于地址库进行文本匹配,因此不需要实时更新数据库,减少了数据库的维护成本减少数据库维护成本。
- 还没有人留言评论。精彩留言会获得点赞!