一种神经网络模型的时间预估方法及相关产品与流程
1.本披露涉及神经网络领域,尤其涉及一种神经网络模型的时间预估方法及相关产品。
背景技术:
2.近年来,深度学习加速器被不断提出,并如同通用处理器一样,正在由单核向多核扩展。这种扩展后的多核结构可以在训练阶段支持数据并行的方式来提高数据吞吐量,加快训练速度。然而,在推理阶段,相比吞吐量深度神经网络对端到端的时延有着更高的要求,这往往决定了加速器在某个场景下的可用性。传统的数据并行方案不能满足推理场景下对加速器小数据、低延迟的要求。
3.在多核处理系统中,根据系统的可用核数可以将网络的输入数据拆分成不同的规模,在不同的核上进行计算;不同的数据拆分策略可能有不同的性能表现。因此,为了解决在多核处理器上进行多核拆分运算过程中的拆分策略选择问题,拆分策略的选择需要预估执行该神经网络模型所需的时间。因此,急需解决该时间预估问题。
技术实现要素:
4.为了解决该技术问题,本披露实施例提供了一种神经网络模型的时间预估方法及相关产品。
5.第一方面,提供一种神经网络模型的时间预估方法,所述方法包括如下步骤:
6.确定所述神经网络模型的网络信息、输入数据尺寸、权值数据尺寸以及运算策略;
7.依据所述网络信息、输入数据尺寸、权值数据尺寸以及运算策略预估所述运算策略对应的执行时间。
8.第二方面,提供一种神经网络模型的时间预估装置,所述装置包括:
9.确定单元,用于确定所述神经网络模型的网络信息、输入数据尺寸、权值数据尺寸以及运算策略;
10.计算单元,用于依据所述网络信息、输入数据尺寸、权值数据尺寸以及运算策略预估所述运算策略对应的执行时间。
11.第三方面,提供一种计算芯片,所述计算芯片包括:如上述所述的装置。
12.第四方面,提供一种电子设备,所述电子设备包括如上述所述的芯片或如上述所述的装置。
13.第五方面,提供一种计算机可读存储介质,存储用于电子数据交换的计算机程序,其中,所述计算机程序使得计算机执行如上述所述的方法。
14.本技术提供的技术方案进行时间预估,预估拆分以后的神经网络模型的运行时间,从而为拆分策略选取阶段提供合理的性能依据,能够大大提高拆分策略选择的效率和系统的运行性能。
附图说明
15.图1是人工智能处理器架构模型示意图;
16.图2是本技术提供的一种神经网络模型的时间预估方法流程图;
17.图3是本技术提供的一种神经网络模型的时间预估的装置示意图。
具体实施方式
18.为了使本技术领域的人员更好地理解本披露方案,下面将结合本披露实施例中的附图,对本披露实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本披露一部分实施例,而不是全部的实施例。基于本披露中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本披露保护的范围。
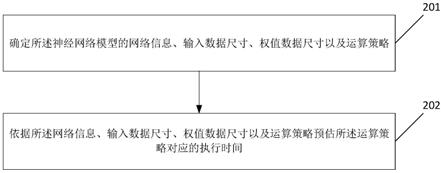
19.如图1所示,人工智能处理器架构模型示意图。该加速器模型的工作方式不需要与host端协同执行神经网络运算,而是在host端编译整个神经网络模型,生成全部的神经网络加速器指令,运行时在host端准备好输入、权值、常数数据,由神经网络加速器执行全网络,并将最终输出返还至host端。所以,该模型在功能上是一个通用的神经网络加速器,并且在神经网络框架中,无需对计算图进行host端与device端的工作负载划分与分配调度。
20.在图1中,包含了scratchpad存储单元,神经网络运算单元(nfu)和控制单元(cu)。控制单元负责读取指令序列,译码,发往各个部件执行,由图中的带尾箭头所示。cu对神经网络运算单元和存储单元是分别控制的,即可以使得两种部件同时在执行指令,互相overlap延迟,提升加速器的性能。存储单元按照功能划分为权值缓存单元(sb)和输入输出神经元缓存单元(nb)。神经网络运算单元包含了向量运算单元(vfu)和矩阵运算单元(mfu)。其中,矩阵运算单元分别读取sb和nb中的数据,进行卷积运算、全连接运算以及矩阵乘运算等需要乘、累加的操作,输出结果存放至nb中。向量运算单元读取nb中的数据,进行向量的算术运算、逻辑运算、比较运算、激活运算、数据转置、数据类型转换等向量化的运算,输出结果存放至nb中。寄存器(reg)与控制单元、运算单元和存储单元连接,支持数据从运算结果导出、从存储单元读取以及指令中的立即数赋值,用于io指令中地址的索引和运算指令中的规模配置以及跳转条件判断等功能。
21.基于加速器模型各部件的特性,可以据此提出一个isa的模型,指令集是单指令多数据流(simd)的,包含上述运算单元负责执行的计算(cp)类指令,和用于数据搬移的输入输出(io)类指令,以及一些其他的配置(config)类、控制跳转类(control)指令。配置类指令包含对激活操作的自定义配置,以及对寄存器的配置操作等。控制跳转类指令负责各部件的同步指令、条件或无条件跳转指令等。其中io、cp类的指令在分别发射至对应的功能部件后,可以并行执行,通过控制类指令中的同步指令进行不同功能部件、不同类型指令之间的同步。
22.在加速器处理神经网络模型时,首先需要通过io类的数据加载(load)指令,将必要的数据从片外(off-chip)内存load到片上(on-chip)存储中,再通过相应的cp指令,执行神经网络运算,最终通过存储(store)指令,将结果返还至片外内存中。
23.如图2所示,为本技术提供的一种神经网络模型的时间预估方法流程图。所示预估方法包括如下步骤:
24.步骤201):确定所述神经网络模型的网络信息、输入数据尺寸、权值数据尺寸以及
运算策略;
25.步骤202):依据所述网络信息、输入数据尺寸、权值数据尺寸以及运算策略预估所述运算策略对应的执行时间。
26.在本实施例中,所述依据所述网络信息、输入数据尺寸、权值数据尺寸以及运算策略预估所述运算策略对应的执行时间具体包括:
27.依据所述网络信息、输入数据尺寸、权值数据尺寸、运算策略以及硬件参数预估io时间以及运算时间;所述执行时间等于io时间与运算时间之间的最大值。
28.其中,预估io时间具体包括:
29.依据所述网络信息、输入数据尺寸、权值数据尺寸确定所述神经网络模型每层输入数据尺寸、每层权值数据尺寸;依据所述运算策略确定每层的拆分策略、每层的数据读写重复次数以及每层的存储参数;
30.依据所述拆分策略确定每层输入数据的基本尺寸、每层权值数据的基本尺寸;
31.依据所述每层输入数据的基本尺寸、每层权值数据的基本尺寸、每层的存储参数以及每层的数据读写重复次数计算得到每层的io子时间,所有层的io子时间的和为所述io时间。
32.具体地,本时间预估方法基于算子层面,在每一个算子的运行过程中,时间开销主要包括io和计算两个主要部分;在人工智能处理器处理过程中,采用lcs(load-compute-store)软流水技术来加速网络层的运行速度,通过软流水技术,在io和计算同时进行的情况下,io时间和计算时间可以相互隐藏时间;因而在理想情况下,我们可以预设io时间和计算时间中的开销较大者可以覆盖另一个开销较小的部分。而根据mlu的不同特性对io和计算时间进行分别的预估。
33.首先是io时间,对数据采用四维张量进行描述,四个维度分别为n(batch),c(channel),h(height),w(weight),输入和输出分别描述为ni,ci,hi,wi和no,co,ho,wo;用len表示输入输出的类型所占的字节数,如float16占两个字节而fix8占一个字节,故而输入输出的字节数分别为:
34.inputbytes=len(input)*ni*ci*hi*wi*repeat_times
35.outputbytes=len(output)*no*co*ho*wo*repeat_times
36.表达式中,repeat_times表示输入或输出可能重复输入输出的次数,取决于具体的算子信息,而io时间预估则通过输入输出的字节数和设备的ddr带宽之商来进行预估:
37.io_time=(inputbytes+outputbyte s)/ddr_bandwidth
38.而若涉及nfu上的运算时,还需要考虑加载kernel所花费的时间:
39.kernel_time=kernelbytes/llc_bandwidth
40.以上涉及的ddr带宽和llc带宽信息由上层模块传入。
41.运算时间具体包括:
42.依据所述网络信息、输入数据尺寸、权值数据尺寸确定所述神经网络模型每层输入数据尺寸、每层权值数据尺寸,依据所述运算策略确定每层的拆分策略、每层运算的类型以及每层的运算参数;
43.依据所述拆分策略确定每层输入数据的基本尺寸、每层权值数据的基本尺寸;
44.依据所述每层输入数据的基本尺寸、每层权值数据的基本尺寸计算得到每层的运
算量,依据每层计算量、每层频率和数据类型时间参数计算得到每层运算子时间,所有层的运算子时间之和为所述运算时间。
45.具体地,对于计算时间,则采用运算量来进行预估,在人工智能处理器上,使用乘加来作为运算量的评估单位,一次乘法和一次加法称为一次乘加(1mac),人工智能处理器在一个时钟周期(cycle)对于fp16的数据可以处理256mac,对于fix8数据可以处理512mac,因而通过计算过程中所需要的时钟周期数和处理频率信息,可以预估出算子的实际计算时间:
46.compute_time=compute_amounts/mac/frequency
47.上述表达式中,mac通过输入数据的类型进行选取,frequency信息通过上层传入,而计算量则通过乘加的次数来得出,以卷积操作为例,卷积操作除了输入数据以外,还需要输入权值数据,权值数据同样以四维张量进行描述,表示为co,ci,kx,ky,对于每一个输出的数据,需要输入数据和权值进行乘加操作进行,计算量为ci*kx*ky,因而总体的计算量为:
48.compute_amounts=ci*kx*ky*no*co*ho*wo
49.结合算子计算时间计算表达式,可以得到该算子计算时间的预估结果。
50.由于lcs软流水技术,io和计算时间互相隐藏时间,因此通过选取io时间和计算时间的较大者,可以作为该算子层面的运行预估时间。
51.综上,本技术方案首先会对神经网络进行预处理,并设置相应的人工智能处理器信息;然后将输入的神经网络逐层匹配到对应的算子,将每一个算子计算获得的预估运行时间设置到网络层的相关属性中;最后累加每一层的预估运行时间,返回网络的预估运行时间。
52.如图3所示,为本技术提供的一种神经网络模型的时间预估的装置示意图。所述装置包括:
53.确定单元301,用于确定所述神经网络模型的网络信息、输入数据尺寸、权值数据尺寸以及运算策略;
54.计算单元302,用于依据所述网络信息、输入数据尺寸、权值数据尺寸以及运算策略预估所述运算策略对应的执行时间。
55.本技术实施例披露一种计算芯片,所述计算芯片包括:如图3所示的装置。
56.本技术实施例还披露一种计算机可读存储介质,存储用于电子数据交换的计算机程序,其中,所述计算机程序使得计算机执行如图2所示的方法。
57.本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
58.本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产
生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
59.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
60.这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1