目标部件检测数据集的构建方法、检测方法、装置及设备
1.本发明涉及图像处理和计算机视觉技术领域,尤其涉及一种目标部件检测数据集的构建方法、目标检测方法、装置、计算机可读存储介质及终端设备。
背景技术:
2.目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时,目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。在进行目标检测方面的神经网络开发时,不可避免的需要用到训练数据,目前,在目标检测中使用的比较有名的数据集主要包括pascal voc、ms coco和imagenet。
3.pascal voc挑战赛是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。pascal voc为图像识别和分类提供了一整套标准化的优秀的数据集,该数据集可以用于图像分类、目标检测、图像分割。pascal voc挑战赛的其中一项任务是person layouttaster competition,即预测人体部位(头、手、脚等)的边界框和对应的标签,用于该任务的图像,被额外的标注上了人的身体部位(头、手、脚等)。
4.ms coco数据集是微软开发维护的大型图像数据集,coco数据集是目前最常用于图像检测定位的数据集,是一个新的图像识别、分割和字幕数据集,其对于图像的标注信息不仅包括类别、位置信息,还包括对图像的语义文本描述。
5.imagenet数据集是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库,由美国斯坦福的计算机科学家通过模拟人类的识别系统建立。imagenet数据集是按照wordnet架构组织的大规模带标签图像数据集,大约包括1500万张图片,2.2万类,每张图片都经过严格的人工筛选与标记。
6.但是,现有的目标检测所使用的数据集,例如上述提及的各种数据集,包括了许多机器人无需操作的物体类别,并且使用水平边界框(horizontal bounding box)标注整个物体,对物体的认知比较模糊,这就使得在机器人抓取物体时难以确定抓取物体的准确位置,导致机器人抓取成功率过低。
技术实现要素:
7.本发明实施例所要解决的技术问题在于,提供一种目标部件检测数据集的构建方法、目标检测方法、装置、计算机可读存储介质及终端设备,通过对目标物体进行部件拆解及标注,能够获得更准确的物体信息,从而在实际应用中提高机器人的抓取成功率。
8.为了解决上述技术问题,本发明实施例提供了一种目标部件检测数据集的构建方
法,包括:
9.根据预设的物体类别,从预设的公开数据集中获取第一组图像,其中,所述第一组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体;
10.根据所述物体类别,通过图像采集获取第二组图像,其中,所述第二组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体;
11.根据预设的部件拆解标准,对所述第一组图像和所述第二组图像中的每一张图像中的每一个目标物体进行部件拆解,获得拆解后的第一组图像和拆解后的第二组图像;
12.根据所述拆解后的第一组图像和所述拆解后的第二组图像,构建初始数据集;
13.对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集。
14.进一步地,所述方法通过以下步骤对第i个目标物体的第j个拆解部件进行子类标注:
15.基于所述第i个目标物体所在的目标图像生成所述第j个拆解部件所对应的矩形边界框;
16.根据所述第j个拆解部件在所述目标图像中的位置,对所述矩形边界框进行调整,获得所述第j个拆解部件所对应的旋转边界框,其中,在基于所述目标图像建立的图像坐标系中,所述旋转边界框表示为(x,y,w,h,θ),(x,y)表示所述旋转边界框的中心点坐标,(w,h)表示所述旋转边界框的宽度和高度,θ表示所述旋转边界框相对于x轴的旋转角度,0≤θ<π。
17.进一步地,所述根据所述物体类别,通过图像采集获取第二组图像,具体包括:
18.获取每一种物体类别在所述第一组图像中对应的图像数量;
19.针对图像数量小于预设的数量阈值的物体类别,通过图像采集获取第二组图像。
20.进一步地,所述对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集,具体包括:
21.将所述初始数据集划分为第一数据集和第二数据集,并对所述第一数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注;
22.将标注后的第一数据集划分为训练集和测试集,并根据所述训练集对预设的网络模型进行训练,根据所述测试集对训练后的网络模型进行优化;
23.根据优化后的网络模型对所述第二数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注;
24.根据标注后的第一数据集和标注后的第二数据集,获得所述目标部件检测数据集。
25.进一步地,在所述根据优化后的网络模型对所述第二数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注之后,所述方法还包括:
26.对所述第二数据集中的每一张图像的标注结果进行检验,并对标注缺陷的图像进行校正;
27.则,所述根据标注后的第一数据集和标注后的第二数据集,获得所述目标部件检测数据集,具体为:
28.根据标注后的第一数据集和检验校正后的第二数据集,获得所述目标部件检测数
据集。
29.为了解决上述技术问题,本发明实施例还提供了一种目标检测方法,包括:
30.根据预设的目标部件检测数据集对预设的目标部件检测模型进行训练,其中,所述目标部件检测数据集采用上述任一项所述的目标部件检测数据集的构建方法获得,所述目标检测模型为上述实施例所述的优化后的网络模型;
31.根据训练好的目标检测模型对待检测图像进行目标检测,获得目标物体的部件检测结果。
32.为了解决上述技术问题,本发明实施例还提供了一种目标部件检测数据集的构建装置,用于实现上述任一项所述的目标部件检测数据集的构建方法,所述装置包括:
33.第一组图像获取模块,用于根据预设的物体类别,从预设的公开数据集中获取第一组图像,其中,所述第一组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体;
34.第二组图像获取模块,用于根据所述物体类别,通过图像采集获取第二组图像,其中,所述第二组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体;
35.图像部件拆解模块,用于根据预设的部件拆解标准,对所述第一组图像和所述第二组图像中的每一张图像中的每一个目标物体进行部件拆解,获得拆解后的第一组图像和拆解后的第二组图像;
36.初始数据集构建模块,用于根据所述拆解后的第一组图像和所述拆解后的第二组图像,构建初始数据集;
37.目标部件检测数据集构建模块,用于对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集。
38.为了解决上述技术问题,本发明实施例还提供了一种目标检测装置,用于实现上述实施例所述的目标检测方法,所述装置包括:
39.目标检测模型训练模块,用于根据预设的目标部件检测数据集对预设的目标检测模型进行训练,其中,所述目标部件检测数据集采用上述任一项所述的目标部件检测数据集的构建方法获得,所述目标检测模型为上述实施例所述的优化后的网络模型;
40.目标物体检测模块,用于根据训练好的目标检测模型对待检测图像进行目标检测,获得目标物体的部件检测结果。
41.本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序;其中,所述计算机程序在运行时控制所述计算机可读存储介质所在的设备执行上述任一项所述的目标部件检测数据集的构建方法,或者,上述实施例所述的目标检测方法。
42.本发明实施例还提供了一种终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现上述任一项所述的目标部件检测数据集的构建方法,或者,上述实施例所述的目标检测方法。
43.与现有技术相比,本发明实施例提供了一种目标部件检测数据集的构建方法、目标检测方法、装置、计算机可读存储介质及终端设备,根据预设的物体类别,从预设的公开
数据集中获取第一组图像;根据所述物体类别,通过图像采集获取第二组图像;根据预设的部件拆解标准,对所述第一组图像和所述第二组图像中的每一张图像中的每一个目标物体进行部件拆解,获得拆解后的第一组图像和拆解后的第二组图像;根据所述拆解后的第一组图像和所述拆解后的第二组图像,构建初始数据集;对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集;本发明实施例构建了一个适用于机器人抓取的目标部件检测数据集,主要包括了可用于机器人抓取物体的图像,通过对数据集中的图像所包含的目标物体进行部件拆解及标注,增加了物体各个部件的空间结构的表达关系,能够获得更准确的物体信息,从而在实际应用中提高了机器人的抓取成功率。
附图说明
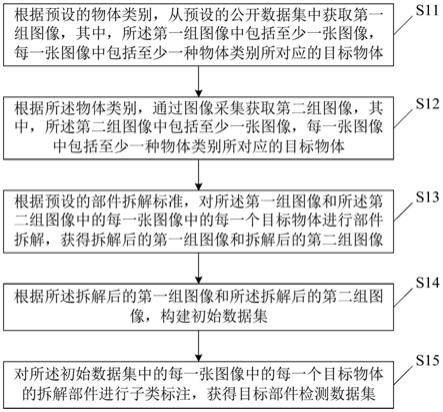
44.图1是本发明提供的一种目标部件检测数据集的构建方法的一个优选实施例的流程图;
45.图2是本发明提供的一种目标检测方法的一个优选实施例的流程图;
46.图3是本发明提供的一种目标部件检测数据集的构建装置的一个优选实施例的结构框图;
47.图4是本发明提供的一种目标检测装置的一个优选实施例的结构框图;
48.图5是本发明提供的一种终端设备的一个优选实施例的结构框图。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本技术领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.本发明实施例提供了一种目标部件检测数据集的构建方法,参见图1所示,是本发明提供的一种目标部件检测数据集的构建方法的一个优选实施例的流程图,所述方法包括步骤s11至步骤s15:
51.步骤s11、根据预设的物体类别,从预设的公开数据集中获取第一组图像,其中,所述第一组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体。
52.具体的,本发明实施例预先设置了若干种物体类别,每一种物体类别对应一种目标物体,则可以根据预先设置的物体类别,从预先设置的公开数据集中筛选出包含上述物体类别的图像,并根据筛选出的图像相应获得第一组图像;可以理解的,第一组图像中包括至少一张图像,并且每一张图像中包括至少一种物体类别所对应的目标物体。
53.需要说明的是,预先设置的物体类别一般为适合机器人操作的物体类别,主要从人对物体操作的复杂程度出发,选取单人可进行简单操作的物体作为目标物体,并设置对应的物体类别,同时,目标物体的结构简单,重量、体积都不能过大,并且目标物体是日常生活中常见的、操作频率比较高的物体,例如生活中常见的杯子、瓶子、门等;如果人对物体的操作比较复杂,则不予考虑,例如自行车、汽车等操作比较复杂的机械或者电子设备。
54.示例性的,公开数据集主要为ms coco和openimage,可以从这两个数据集中筛选出包含预设的物体类别的图像,并且在实际筛选过程中,可以按照对目标物体不同的使用频率,将筛选出的包含目标物体的图像数量分为不同的等级;例如,生活中最常见的杯子、瓶子、门等,这类目标物体的使用频率较高,则筛选出的包含这类目标物体的图像的数量较多,而其他使用频率较低或者结构特征比较简单的物体,则筛选出数量相对减少的图像。
55.步骤s12、根据所述物体类别,通过图像采集获取第二组图像,其中,所述第二组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体。
56.具体的,除了从公开数据集中筛选出包含上述物体类别的图像之外,还可以基于上述物体类别,通过图像采集设备在不同的场景下对不同的目标物体进行图像采集,相应获得第二组图像;可以理解的,第二组图像中包括至少一张图像,并且每一张图像中包括至少一种物体类别所对应的目标物体。
57.步骤s13、根据预设的部件拆解标准,对所述第一组图像和所述第二组图像中的每一张图像中的每一个目标物体进行部件拆解,获得拆解后的第一组图像和拆解后的第二组图像。
58.具体的,本发明实施例还根据目标物体的部件功能或者结构特征,预先设置了对目标物体进行部件拆解的部件拆解标准,则可以根据预先设置的部件拆解标准,分别对获得的第一组图像中的每一张图像中所包含的每一个目标物体进行部件拆解,相应获得拆解后的第一组图像,以及,分别对获得的第二组图像中的每一张图像中所包含的每一个目标物体进行部件拆解,相应获得拆解后的第二组图像。
59.可以理解的,本发明实施例中的拆解,不是对图像的拆解,而是基于选定的物体类别所对应的目标物体,对图像中所包含的目标物体的各个部件进行拆解,以将同一个目标物体拆解为不同的拆解部件,并且同一个目标物体包括至少一个拆解部件。
60.步骤s14、根据所述拆解后的第一组图像和所述拆解后的第二组图像,构建初始数据集。
61.具体的,在获得拆解后的第一组图像和拆解后的第二组图像之后,可以对拆解后的第一组图像和拆解后的第二组图像进行整理合并处理,相应构建获得初始数据集。
62.步骤s15、对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集。
63.具体的,在获得初始数据集之后,分别对初始数据集中的每一张拆解后的图像中所包含的每一个目标物体的拆解部件进行子类标注,相应获得标注后的初始数据集,该标注后的初始数据集即为最终获得的目标部件检测数据集。
64.示例性的,假设选定的适合机器人操作的物体类别共包括45种物体类别,对应45种目标物体,根据设置好的物体部件拆解标准(部件拆解标准基于各个部件的功能或结构特征),分别对初始数据集中的每一张图像中所包含的每一个目标物体的各个部件进行拆解;例如,对于一个手钻,可以拆解为手钻把手(drill handle)、手钻主体(drill body)以及钻头(drill bits)三部分;对于一个瓶子,可以拆解为瓶身(bottle body)、瓶颈(bottle neck)以及瓶盖(bottle cap)三部分,其他目标物体按照同样的标准进行拆解;相应的,共将45种物体类别拆解为88个子类别;其中,45种物体类别(目标物体)及其对应的部件拆解情况以及在初始数据集中的图像数量如表1所示。
65.可以理解的,在对图像中所包含的目标物体的各个拆解部件进行子类标注时,不是对目标物体整体进行标注,而是对拆解获得的各个拆解部件进行标注,例如,一张图像中同时包括瓶子、盘子、刀、叉子四类目标物体,则依次对瓶盖、瓶颈、瓶身、盘沿、盘子中心、刀把、刀头、叉子头、柄进行子类标注。
66.表1 45种物体类别数据表
67.68.[0069][0070]
本发明实施例所提供的一种目标部件检测数据集的构建方法,根据预设的物体类别,从预设的公开数据集中获取第一组图像;根据所述物体类别,通过图像采集获取第二组图像;根据预设的部件拆解标准,对所述第一组图像和所述第二组图像中的每一张图像中的每一个目标物体进行部件拆解,获得拆解后的第一组图像和拆解后的第二组图像;根据所述拆解后的第一组图像和所述拆解后的第二组图像,构建初始数据集;对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集;本发明实施例构建了一个适用于机器人抓取的目标部件检测数据集,主要包括了可用于机器人抓取物体的图像,通过对数据集中的图像所包含的目标物体进行部件拆解及标注,增加了物体各个部件的空间结构的表达关系,能够获得更准确的物体信息,从而在实际应用中提高了机器人的抓取成功率。
[0071]
在另一个优选实施例中,所述方法通过以下步骤对第i个目标物体的第j个拆解部件进行子类标注:
[0072]
基于所述第i个目标物体所在的目标图像生成所述第j个拆解部件所对应的矩形边界框;
[0073]
根据所述第j个拆解部件在所述目标图像中的位置,对所述矩形边界框进行调整,获得所述第j个拆解部件所对应的旋转边界框,其中,在基于所述目标图像建立的图像坐标系中,所述旋转边界框表示为(x,y,w,h,θ),(x,y)表示所述旋转边界框的中心点坐标,(w,h)表示所述旋转边界框的宽度和高度,θ表示所述旋转边界框相对于x轴的旋转角度,0≤θ<π。
[0074]
具体的,结合上述实施例,在对初始数据集进行数据集标注时,需要对初始数据集中的每一张拆解后的图像中所包含的每一个目标物体的每一个拆解部件进行子类标注,下面以对第i个目标物体的第j个拆解部件进行子类标注为例(i和j均为大于0的正整数),对具体的标注过程进行说明:
[0075]
确定第i个目标物体所在的目标图像,并基于该目标图像建立图像坐标系,例如,以目标图像的左上顶点为坐标原点,以沿目标图像水平向右的方向为x轴正方向,以沿目标图像垂直向下的方向为y轴正方向;则,在该图像坐标系中,先针对第i个目标物体的第j个拆解部件生成对应的矩形边界框(rectangular bounding box),矩形边界框表示为(x0,y0,w0,h0,θ0),其中,(x0,y0)表示矩形边界框的中心点坐标初始值,(w0,h0)表示矩形边界
框的宽度初始值和高度初始值,θ0表示矩形边界框相对于x轴顺时针的旋转角度初始值;再根据第i个目标物体的第j个拆解部件在目标图像中的位置,对矩形边界框的相关初始值进行调整,获得第i个目标物体的第j个拆解部件所对应的旋转边界框(oriented bounding box),其中,旋转边界框表示为(x,y,w,h,θ),(x,y)表示旋转边界框的中心点坐标,(w,h)表示旋转边界框的宽度和高度,θ表示旋转边界框相对于x轴顺时针的旋转角度,θ的表达方式可以采用弧度制,取值范围为0≤θ<π。
[0076]
需要说明的是,本发明实施例通过对图像中所包含的每一个目标物体的每一个拆解部件进行子类标注,并且在标注过程中使用旋转边界框进行标注,使得旋转边界框刚好包含完整的拆解部件而又不包含多余的背景信息,相比于现有技术使用水平边界框(horizontal bounding box)进行标注,获得了更多更准确的物体信息,例如目标物体的摆放角度、对目标物体的抓取部位等,增加了物体各个部件的空间结构的表达,解决了在机器人抓取物体任务中,抓取位置难以定位、物体角度无法确定的问题,从而提高了机器人的抓取成功率。
[0077]
在又一个优选实施例中,所述根据所述物体类别,通过图像采集获取第二组图像,具体包括:
[0078]
获取每一种物体类别在所述第一组图像中对应的图像数量;
[0079]
针对图像数量小于预设的数量阈值的物体类别,通过图像采集获取第二组图像。
[0080]
具体的,结合上述实施例,在通过图像采集获取第二组图像时,可以在获得的第一组图像的基础上,获取每一种物体类别在第一组图像中所对应的图像数量,并将每一种物体类别在第一组图像中所对应的图像数量与预先设置的数量阈值进行比较,相应获得图像数量小于预先设置的数量阈值的物体类别,将这些物体类别作为待补充物体类别,则,针对图像数量小于预先设置的数量阈值的待补充物体类别,可以通过图像采集的方式获取包含待补充物体类别的第二组图像,即针对第一组图像中包含的图像数量较少的待补充物体类别,通过图像采集的方式采集包含待补充物体类别的图像,以将包含待补充物体类别的图像的数量补充至一定的数量。
[0081]
可以理解的,第二组图像中包括至少一张图像,并且每一张图像中包括至少一种待补充物体类别所对应的目标物体。
[0082]
在又一个优选实施例中,所述对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集,具体包括:
[0083]
将所述初始数据集划分为第一数据集和第二数据集,并对所述第一数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注;
[0084]
将标注后的第一数据集划分为训练集和测试集,并根据所述训练集对预设的网络模型进行训练,根据所述测试集对训练后的网络模型进行优化;
[0085]
根据优化后的网络模型对所述第二数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注;
[0086]
根据标注后的第一数据集和标注后的第二数据集,获得所述目标部件检测数据集。
[0087]
具体的,结合上述实施例,在对初始数据集中的每一张图像中所包含的每一个目标物体的拆解部件进行子类标注时,首先,将初始数据集划分为第一数据集和第二数据集,
在实际划分时,可以随机选择初始数据集中的部分图像(例如一半数量的图像)组成第一数据集,剩下的部分图像(例如另一半数量的图像)组成第二数据集;接着,对第一数据集中的每一张图像中所包含的每一个目标物体的拆解部件进行子类标注(标注方法与上述实施例相同),相应获得标注后的第一数据集,并将标注后的第一数据集划分为训练集和测试集,以根据训练集对预先设置的网络模型进行训练,根据测试集对训练后的网络模型进行优化,相应获得优化后的网络模型;然后,将第二数据集输入优化后的网络模型中,根据优化后的网络模型对第二数据集中的每一张图像中所包含的每一个目标物体的拆解部件进行子类标注,相应获得标注后的第二数据集;最后,对标注后的第一数据集和标注后的第二数据集进行整理合并,相应获得目标部件检测数据集。
[0088]
需要说明的是,预先设置的网络模型主要由特征提取网络和传递网络构成,特征提取网络用于提取训练集中的图像的特征,该特征主要包括图像中目标物体的颜色、形态学、纹理和空间分布等特征,传递网络指的是用于目标检测的卷积神经网络(cnn),可以对图像中的目标物体的子类别进行定位与检测。
[0089]
在根据训练集对预先设置的网络模型进行训练时,先将训练集中的图像输入到特征提取网络中,从图像中提取特征,再将提取到的图像的特征输入到传递网络中,并将传递网络的输出与训练集中的图像被标注的类别标签进行拟合,通过反向传播方式,对网络进行端到端的训练,相应获得训练后的网络模型。
[0090]
在根据测试集对训练后的网络模型进行优化时,将测试集中的图像输入到训练后的网络模型中,判断网络模型的好坏,网络模型的好坏可以由两个评价指标来决定,即检测速度与检测准确率,将测试集中的图像输入到训练后的网络模型后,会得到当前网络模型对测试集图像的检测速度与检测准确率,若这两个评价指标大于一定的阈值,则认为当前网络模型的性能达到要求,即判定网络模型好;若判定网络模型不好,则需要对网络结构、网络参数、损失函数等进行调整,重复上述训练及优化步骤,直至训练后的网络模型的性能达到要求时为止,相应获得优化后的网络模型。
[0091]
作为上述方案的改进,在所述根据优化后的网络模型对所述第二数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注之后,所述方法还包括:
[0092]
对所述第二数据集中的每一张图像的标注结果进行检验,并对标注缺陷的图像进行校正;
[0093]
则,所述根据标注后的第一数据集和标注后的第二数据集,获得所述目标部件检测数据集,具体为:
[0094]
根据标注后的第一数据集和检验校正后的第二数据集,获得所述目标部件检测数据集。
[0095]
具体的,结合上述实施例,在获得标注后的第二数据集之后,还可以对第二数据集中的每一张图像所对应的标注结果进行检验,以判断每一个目标物体的标注结果是否合格,若不合格,即对应的图像存在标注缺陷,则对存在标注缺陷的图像进行校正,相应获得检验校正后的第二数据集;至此,完成了对初始数据集的全部标注工作,相应的,对标注后的第一数据集和检验校正后的第二数据集进行整理合并,即可获得目标部件检测数据集。
[0096]
需要说明的是,标注缺陷的图像一般存在于由网络模型生成相应的标注信息的图像,这部分图像的标注信息可能不会十分准确,这与具体的网络结构有关,例如,旋转边界
框的中心坐标选取不合适、宽度和高度不准确、旋转角度不合适等原因,均会导致旋转边界框对目标物体的定位不准确,对应的图像存在标注缺陷,这时就需要对旋转边界框的中心坐标、宽度、高度、旋转角度进行校正;例如,可以进行人工校正,具体操作方法为:手工调整旋转边界框的位置、大小以及旋转角度,使得旋转边界框刚好包含完整的拆解部件,而没有多余的背景信息。
[0097]
本发明实施例还提供了一种目标检测方法,参见图2所示,是本发明提供的一种目标检测方法的一个优选实施例的流程图,所述方法包括步骤s21至步骤s22:
[0098]
步骤s21、根据预设的目标部件检测数据集对预设的目标检测模型进行训练,其中,所述目标部件检测数据集采用上述任一实施例所述的目标部件检测数据集的构建方法获得,所述目标检测模型为上述实施例所述的优化后的网络模型;
[0099]
步骤s22、根据训练好的目标检测模型对待检测图像进行目标检测,获得目标物体的部件检测结果。
[0100]
具体的,结合上述实施例,本发明实施例预先设置了目标部件检测数据集和目标检测模型,其中,目标部件检测数据集为采用上述任一实施例所述的目标部件检测数据集的构建方法所获得的目标部件检测数据集,目标检测模型为采用上述实施例所述的经过第一数据集进行训练及优化处理后所获得的优化后的网络模型,在此基础上,根据预先设置的目标部件检测数据集对预先设置的目标检测模型进行训练,相应获得训练好的目标检测模型,将训练好的目标检测模型应用到实际环境中,利用图像采集设备获得待检测图像,则将待检测图像输入到训练好的目标检测模型中,利用训练好的目标检测模型对待检测图像进行目标检测,完成对待检测图像中所包含的每一个目标物体的各个部件的检测任务,相应获得目标物体的部件检测结果。
[0101]
需要说明的是,目标检测模型本身为上述优化后的网络模型,本发明实施例是通过目标部件检测数据集对优化后的网络模型再次进行训练,具体的训练步骤包括:(1)将目标部件检测数据集划分为训练集和测试集;(2)先将训练集中的图像输入到特征提取网络中,从图像中提取特征,再将提取到的图像的特征输入到传递网络中;(3)将传递网络的输出与训练集中的图像被标注的类别标签进行拟合,通过反向传播方式,对网络进行端到端的训练,相应获得训练后的网络模型;(4)将测试集中的图像输入到训练后的网络模型中,判断网络模型的好坏,网络模型的好坏可以由两个评价指标来决定,即检测速度与检测准确率,将测试集中的图像输入到训练后的网络模型后,会得到当前网络模型对测试集图像的检测速度与检测准确率,若这两个评价指标大于一定的阈值,则认为当前网络模型的性能达到要求,即判定网络模型好;若判定网络模型不好,则需要对网络结构、网络参数、损失函数等进行调整,重复上述训练及优化步骤,直至训练后的网络模型的性能达到要求时为止,获得训练好的目标检测模型。
[0102]
本发明实施例所提供的一种目标检测方法,构建了一个适用于机器人抓取的目标部件检测数据集,主要包括了可用于机器人抓取物体的图像,通过对数据集中的图像所包含的目标物体进行部件拆解及标注,并且在标注过程中使用旋转边界框进行标注,使得旋转边界框刚好包含完整的拆解部件而又不包含多余的背景信息,相比于现有技术使用水平边界框进行标注,获得了更多更准确的物体信息,例如目标物体的摆放角度、对目标物体的抓取部位等,增加了物体各个部件的空间结构的表达,解决了在机器人抓取物体任务中,抓
取位置难以定位、物体角度无法确定的问题,从而提高了机器人的抓取成功率。
[0103]
本发明实施例还提供了一种目标部件检测数据集的构建装置,用于实现上述任一实施例所述的目标部件检测数据集的构建方法,参见图3所示,是本发明提供的一种目标部件检测数据集的构建装置的一个优选实施例的结构框图,所述装置包括:
[0104]
第一组图像获取模块11,用于根据预设的物体类别,从预设的公开数据集中获取第一组图像,其中,所述第一组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体;
[0105]
第二组图像获取模块12,用于根据所述物体类别,通过图像采集获取第二组图像,其中,所述第二组图像中包括至少一张图像,每一张图像中包括至少一种物体类别所对应的目标物体;
[0106]
图像部件拆解模块13,用于根据预设的部件拆解标准,对所述第一组图像和所述第二组图像中的每一张图像中的每一个目标物体进行部件拆解,获得拆解后的第一组图像和拆解后的第二组图像;
[0107]
初始数据集构建模块14,用于根据所述拆解后的第一组图像和所述拆解后的第二组图像,构建初始数据集;
[0108]
目标部件检测数据集构建模块15,用于对所述初始数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注,获得目标部件检测数据集。
[0109]
优选地,所述目标部件检测数据集构建模块15具体包括图像部件标注单元,用于通过以下步骤对第i个目标物体的第j个拆解部件进行子类标注:
[0110]
基于所述第i个目标物体所在的目标图像生成所述第j个拆解部件所对应的矩形边界框;
[0111]
根据所述第j个拆解部件在所述目标图像中的位置,对所述矩形边界框进行调整,获得所述第j个拆解部件所对应的旋转边界框,其中,在基于所述目标图像建立的图像坐标系中,所述旋转边界框表示为(x,y,w,h,θ),(x,y)表示所述旋转边界框的中心点坐标,(w,h)表示所述旋转边界框的宽度和高度,θ表示所述旋转边界框相对于x轴的旋转角度,0≤θ<π。
[0112]
优选地,所述第二组图像获取模块12具体包括:
[0113]
图像数量获取单元,用于获取每一种物体类别在所述第一组图像中对应的图像数量;
[0114]
第二组图像获取单元,用于针对图像数量小于预设的数量阈值的物体类别,通过图像采集获取第二组图像。
[0115]
优选地,所述目标部件检测数据集构建模块15还包括:
[0116]
第一数据集标注单元,用于将所述初始数据集划分为第一数据集和第二数据集,并对所述第一数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注;
[0117]
网络模型训练单元,用于将标注后的第一数据集划分为训练集和测试集,并根据所述训练集对预设的网络模型进行训练,根据所述测试集对训练后的网络模型进行优化;
[0118]
第二数据集标注单元,用于根据优化后的网络模型对所述第二数据集中的每一张图像中的每一个目标物体的拆解部件进行子类标注;
[0119]
目标部件检测数据集获取单元,用于根据标注后的第一数据集和标注后的第二数
programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,通用处理器可以是微处理器,或者所述处理器10也可以是任何常规的处理器,所述处理器10是所述终端设备的控制中心,利用各种接口和线路连接所述终端设备的各个部分。
[0133]
所述存储器20主要包括程序存储区和数据存储区,其中,程序存储区可存储操作系统、至少一个功能所需的应用程序等,数据存储区可存储相关数据等。此外,所述存储器20可以是高速随机存取存储器,还可以是非易失性存储器,例如插接式硬盘,智能存储卡(smart media card,smc)、安全数字(secure digital,sd)卡和闪存卡(flash card)等,或所述存储器20也可以是其他易失性固态存储器件。
[0134]
需要说明的是,上述终端设备可包括,但不仅限于,处理器、存储器,本领域技术人员可以理解,图5结构框图仅仅是上述终端设备的示例,并不构成对终端设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件。
[0135]
综上,本发明实施例所提供的一种目标部件检测数据集的构建方法、目标检测方法、装置、计算机可读存储介质及终端设备,构建了一个适用于机器人抓取的目标部件检测数据集,主要包括了可用于机器人抓取物体的图像,通过对数据集中的图像所包含的目标物体进行部件拆解及标注,并且在标注过程中使用旋转边界框进行标注,使得旋转边界框刚好包含完整的拆解部件而又不包含多余的背景信息,相比于现有技术使用水平边界框进行标注,获得了更多更准确的物体信息,例如目标物体的摆放角度、对目标物体的抓取部位等,增加了物体各个部件的空间结构的表达,解决了在机器人抓取物体任务中,抓取位置难以定位、物体角度无法确定的问题,从而提高了机器人的抓取成功率。
[0136]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1