用于实时交互和指导的系统和方法与流程
用于实时交互和指导的系统和方法
1.相关申请的交叉引用
2.本技术要求于2020年2月28日提交的美国临时申请no.62/982,793的权益,该临时申请的内容通过援引被全部纳入于此。
3.领域
4.所描述的各实施例一般涉及用于实时交互的系统和方法,尤其涉及基于视频数据的实时锻炼指导。
5.背景
6.由真人教练提供的健身指导和/或训练的成本非常高,并且对于许多用户来说是遥不可及的。
7.与自动化虚拟助手的交互以几种不同的形式存在。首先,可以使用智能扬声器,诸如的alexa、的siri和的assistant。然而,这些虚拟助手只允许基于语音的交互,并且只识别简单的查询。其次,存在许多服务机器人,但大部分缺乏复杂的人类交互能力,且为基本的“带身体的眼盲的聊天机器人”。
8.这些助手不提供视觉交互,包括使用来自用户设备的视频数据的视觉交互。例如,现有的虚拟助手无法理解周围的视频场景、无法理解视频中的对象和动作、无法理解视频内的空间和时间关系、无法理解视频中展示的人类行为、无法理解和生成视频中的口语、无法理解视频中描述的空间和时间、不具有以视觉为基础的概念、关于真实世界事件的原因、不具有记忆力或无法理解时间。
9.创建提供视觉交互的虚拟助手的一个挑战是确定训练数据的方法,因为标记数据的各定量方面(例如人类审查者对视频数据的速度标记)是固有的主观确定。这使得利用此类标记来标记大量视频变得困难,特别是当多个人参与到该过程中时(在标记大型数据集时这种情况很常见)。
10.仍然需要改进的虚拟助理,其具有改进的与人类的交互以用于个人指导,包括使用与智能设备(诸如智能手机)的相机的视频交互。
11.概述
12.如果神经网络配置成实时处理显示用户执行身体活动的相机流,则该神经网络可被用于实时指教和指导。此类网络可以通过提供实时反馈和/或通过收集有关用户活动的信息(诸如计数或强度测量)来驱动指教或指导应用。
13.在第一方面,提供了一种用于在用户设备处向用户提供反馈的方法,该方法包括:提供反馈模型;在该用户设备处接收视频信号,该视频信号包括至少两个视频帧,该至少两个视频帧中的第一视频帧在该至少两个视频帧中的第二帧之前被捕捉;生成包括该至少两个视频帧的该反馈模型的输入层;基于该反馈模型和该输入层来确定与该至少两个视频帧中的该第二视频帧相关联的反馈推断;以及使用该用户设备的输出设备来向该用户输出该反馈推断。
14.在一个或多个实施例中,该反馈模型可包括骨干网络和至少一个头部网络。
15.在一个或多个实施例中,该骨干网络可以是三维卷积神经网络。
16.在一个或多个实施例中,该至少一个头部网络中的每个头部网络可以是神经网络。
17.在一个或多个实施例中,该至少一个头部网络可包括全局活动检测头部网络,该全局活动检测头部网络可以用于基于该骨干网络的层确定该视频信号的活动分类;并且该反馈推断可包括该活动分类。
18.在一个或多个实施例中,该活动分类可包括选自锻炼分数、卡路里估计和锻炼形式反馈的群中的至少一者。
19.在一个或多个实施例中,锻炼分数可以是基于全局活动检测头部网络的多个活动标记的softmax输出的加权和来确定的连续值。
20.在一个或多个实施例中,该至少一个头部网络可包括离散事件检测头部网络,该离散事件检测头部网络用于基于该骨干网络的层从该视频信号确定至少一个事件,该至少一个事件中的每个事件可包括事件分类;并且该反馈推断可包括该至少一个事件。
21.在一个或多个实施例中,该至少一个事件中的每个事件可进一步包括时间戳,该时间戳对应于该视频信号;并且该至少一个事件可对应于用户锻炼重复的一部分。
22.在一个或多个实施例中,该反馈推断可包括锻炼重复计数。
23.在一个或多个实施例中,该至少一个头部网络可包括局部活动检测头部网络,该局部活动检测头部网络用于基于该骨干网络的层从该视频信号确定至少一个边界框并确定与该至少一个边界框中的每个边界框对应的活动分类;并且该反馈推断可包括该至少一个边界框以及与该至少一个边界框中的每个边界框对应的该活动分类。
24.在一个或多个实施例中,该反馈推断可包括针对一个或多个用户的活动分类,该边界框对应于该一个或多个用户。
25.在一个或多个实施例中,该视频信号可以是从该用户设备的视频捕获设备接收的视频流,并且该反馈推断可以是在接收该视频流时近乎实时地提供的。
26.在一个或多个实施例中,该视频信号可以是从该用户设备的存储设备接收的视频样本。
27.在一个或多个实施例中,该输出设备可以是音频输出设备,并且该反馈推断可以是对用户的音频提示。
28.在一个或多个实施例中,该输出设备可以是显示设备,并且该反馈推断可以是作为叠加在该视频信号上的字幕来提供的。
29.在第二方面,提供了一种用于在用户设备处向用户提供反馈的系统,该系统包括:存储器,该存储器包括反馈模型;输出设备;处理器,该处理器与该存储器和该输出设备通信,其中该处理器被配置成;在该用户设备处接收视频信号,该视频信号包括至少两个视频帧,该至少两个视频帧中的第一视频帧在该至少两个视频帧中的第二帧之前被捕捉;生成包括该至少两个视频帧的该反馈模型的输入层;基于该反馈模型和该输入层来确定与该至少两个视频帧中的该第二视频帧相关联的反馈推断;以及使用该输出设备来向该用户输出该反馈推断。
30.在一个或多个实施例中,该反馈模型可包括骨干网络和至少一个头部网络。
31.在一个或多个实施例中,该骨干网络可以是三维卷积神经网络。
32.在一个或多个实施例中,该至少一个头部网络中的每个头部网络可以是神经网
络。
33.在一个或多个实施例中,该至少一个头部网络可包括全局活动检测头部网络,该全局活动检测头部网络用于基于该骨干网络的层确定该视频信号的活动分类;并且该反馈推断可包括该活动分类。
34.在一个或多个实施例中,该活动分类可包括选自锻炼分数、卡路里估计和锻炼形式反馈的群中的至少一者。
35.在一个或多个实施例中,锻炼分数可以是基于全局活动检测头部网络的多个活动标记的softmax输出的加权和来确定的连续值。
36.在一个或多个实施例中,该至少一个头部网络可包括离散事件检测头部网络,该离散事件检测头部网络用于基于该骨干网络的层从该视频信号确定至少一个事件,该至少一个事件中的每个事件可包括事件分类;并且该反馈推断可包括该至少一个事件。
37.在一个或多个实施例中,该至少一个事件中的每个事件可进一步包括时间戳,该时间戳对应于该视频信号;并且该至少一个事件可对应于用户锻炼重复的一部分。
38.在一个或多个实施例中,该反馈推断可包括锻炼重复计数。
39.在一个或多个实施例中,该至少一个头部网络可包括局部活动检测头部网络,该局部活动检测网络用于基于该骨干网络的层从该视频信号确定至少一个边界框并确定与该至少一个边界框中的每个边界框对应的活动分类;并且该反馈推断可包括该至少一个边界框以及与该至少一个边界框中的每个边界框对应的该活动分类。
40.在一个或多个实施例中,该反馈推断可包括针对一个或多个用户的活动分类,该边界框对应于该一个或多个用户。
41.在一个或多个实施例中,该视频信号可以是从该用户设备的视频捕获设备接收的视频流,并且该反馈推断是在接收该视频流时近乎实时地提供的。
42.在一个或多个实施例中,该视频信号可以是从该用户设备的存储设备接收的视频样本。
43.在一个或多个实施例中,该输出设备可以是音频输出设备,并且该反馈推断是对用户的音频提示。
44.在一个或多个实施例中,该输出设备可以是显示设备,并且该反馈推断可以是作为叠加在该视频信号上的字幕来提供的。
45.在第三方面,提供了一种用于生成反馈模型的方法,该方法包括:向多个标记用户传送多个视频样本,该多个视频样本中的每个视频样本包括视频数据,该多个标记用户中的每个标记用户接收该多个视频样本中的至少两个视频样本;从该多个标记用户接收多个排名响应,该多个排名响应中的每个排名响应指示由相应标记用户基于排名标准从传送给该相应标记用户的该至少两个视频样本中选择的相对排名;基于该多个排名响应和该排名标准来确定该多个视频样本中的每个视频样本的排序标记;基于每个视频样本的相应排序标记将多个视频样本整理到多个桶中;确定该多个桶中的每个桶的分类标记;基于该多个桶、每个相应桶的分类标记和每个相应桶的视频样本来生成反馈模型。
46.在一个或多个实施例中,生成该反馈模型可以包括应用基于梯度的优化来确定该反馈模型。
47.在一个或多个实施例中,该反馈模型可包括至少一个头部网络。
48.在一个或多个实施例中,该至少一个头部网络中的每个头部网络可以是神经网络。
49.在一个或多个实施例中,该方法可进一步包括确定来自该多个标记用户的足够数目的多个排名响应已被接收到。
50.在一个或多个实施例中,该排名标准可包括选自锻炼速度、重复和运动范围的群中的至少一者。
51.在一个或多个实施例中,排名标准可以与特定类型的身体锻炼相关联。
52.在第四方面,提供了一种用于生成反馈模型的系统,该系统包括:存储器,该存储器包括多个视频样本;网络设备;与该存储器和该网络设备通信的处理器,该处理器被配置成:使用该网络设备向多个标记用户传送多个视频样本,该多个视频样本中的每个视频样本包括视频数据,该多个标记用户中的每个标记用户接收该多个视频样本中的至少两个视频样本;使用该网络设备从该多个标记用户接收多个排名响应,该多个排名响应中的每个排名响应指示由相应标记用户基于排名标准从传送给该相应标记用户的该至少两个视频样本中选择的相对排名;基于该多个排名响应和该排名标准来确定该多个视频样本中的每个视频样本的排序标记;基于每个视频样本的相应排序标记将多个视频样本整理到多个桶中;确定该多个桶中的每个桶的分类标记;基于该多个桶、每个相应桶的分类标记和每个相应桶的视频样本来生成反馈模型。
53.在一个或多个实施例中,该处理器可被进一步配置成应用基于梯度的优化来确定该反馈模型。
54.在一个或多个实施例中,该反馈模型可包括至少一个头部网络。
55.在一个或多个实施例中,该至少一个头部网络中的每个头部网络可以是神经网络。
56.在一个或多个实施例中,该处理器可被进一步配置成:确定来自该多个标记用户的足够数目的多个排名响应已被接收到。
57.在一个或多个实施例中,该排名标准可包括选自锻炼速度、重复和运动范围的群中的至少一者。
58.在一个或多个实施例中,排名标准可以与特定类型的身体锻炼相关联。
59.附图简述
60.现在将参照附图详细描述本发明的优选实施例,其中:
61.图1是根据一个或多个实施例的用于实时交互和指导的用户设备的系统示图;
62.图2是根据一个或多个实施例的用于实时交互和指导的方法示图;
63.图3是根据一个或多个实施例的用于实时交互和指导的场景示图;
64.图4是根据一个或多个实施例的包括虚拟化身的用于实时交互和指导的用户界面示图;
65.图5是根据一个或多个实施例的用于实时交互和指导的用户界面示图;
66.图6是根据一个或多个实施例的用于实时交互和指导的用户界面示图;
67.图7是根据一个或多个实施例的用于实时交互和指导的另一用户界面示图;
68.图8是根据一个或多个实施例的用于锻炼评分的表格示图;
69.图9是根据一个或多个实施例的用于锻炼评分的另一表格示图;
70.图10是根据一个或多个实施例的用于生成反馈模型的系统示图;
71.图11是根据一个或多个实施例的用于生成反馈模型的方法示图;
72.图12是根据一个或多个实施例的用于确定反馈推断的模型示图;
73.图13是根据一个或多个实施例的用于确定反馈推断的可步进卷积示图;
74.图14是根据一个或多个实施例的用于生成反馈模型的时间标记的用户界面示图;
75.图15是根据一个或多个实施例的用于生成反馈模型的成对标记的用户界面示图;
76.图16是成对排名标记与人工标注排名准确性的比较,其中成对排名是通过将每个视频与10个其他视频进行比较而产生的;
77.图17是根据一个或多个实施例的用于实时交互和指导的另一用户界面。
78.示例性实施例的描述
79.应当理解,阐述了许多具体细节以便提供对本文描述的示例实施例的透彻理解。然而,本领域普通技术人员将理解,没有这些具体细节也可以实践本文描述的实施例。在其他实例中,没有详细描述众所周知的方法、过程和组件,以免混淆本文描述的各实施例。此外,本说明书和附图不应被视为以任何方式限制本文描述的各实施例的范围,而是仅仅描述了本文描述的各实施例的实现。
80.应当注意,在本文中使用时,诸如“基本上”、“约”和“大约”之类的程度术语是指所修饰的术语的合理偏差量,使得最终结果不会显著改变。如果这种偏差不会否定它所修饰的术语的含义,则这些程度术语应被解释为包括所修饰的术语的偏差。
81.此外,如本文所使用的,措辞“和/或”旨在表示包含性或。也就是说,例如,“x和/或y”旨在表示x或y或两者。作为进一步的示例,“x、y和/或z”旨在表示x或y或z或其任何组合。
82.本文描述的系统和方法的各实施例可以以硬件或软件或两者的组合来实现。这些实施例可以在可编程计算机上执行的计算机程序中实现,每个计算机包括至少一个处理器、数据存储系统(包括易失性存储器或非易失性存储器或其他数据存储元件或其组合)和至少一个通信接口。例如但不限于,可编程计算机(以下称为计算设备)可以是服务器、网络设备、嵌入式设备、计算机扩展模块、个人计算机、膝上型计算机、个人数据助理、蜂窝电话、智能电话设备、平板计算机、无线设备或能够被配置成执行本文描述的方法的任何其他计算设备。
83.在一些实施例中,通信接口可以是网络通信接口。在组合元件的各实施例中,通信接口可以是软件通信接口,诸如用于进程间通信(ipc)的那些通信接口。在其他实施例中,可以存在实现的通信接口的组合,诸如硬件、软件及其组合。
84.程序代码可被应用于输入数据以执行本文描述的功能并生成输出信息。输出信息以已知方式应用于一个或多个输出设备。
85.每个程序可以用高级规程或面向对象的编程和/或脚本语言或两者来实现以与计算机系统通信。然而,如果需要,这些程序可以用汇编语言或机器语言来实现。在任何情形中,语言可以是编译语言或解释语言。每个此类计算机程序可以存储在通用或专用可编程计算机可读的存储介质或设备(例如rom、磁盘、光盘)上,用于在计算机读取存储介质或设备以执行本文描述的过程时配置和操作计算机。系统的各实施例也可以被认为被实现为配置有计算机程序的非瞬态计算机可读存储介质,其中如此配置的存储介质使得计算机以特定和预定义的方式操作以执行本文描述的各功能。
86.此外,所描述的各实施例的系统、过程和方法能够分布在计算机程序产品中,该计算机程序产品包括承载用于一个或多个处理器的计算机可用指令的计算机可读介质。该介质可以以各种形式提供,包括一个或多个软盘、压缩碟、磁带、芯片、有线传输、卫星传输、互联网传输或下载、磁性和电子存储介质、数字和模拟信号等。计算机可用指令也可以是各种形式,包括编译代码和非编译代码。
87.如本文所描述的,术语“实时”指从用户设备到用户的基本实时反馈。本文中的术语“实时”可以包括较短的处理时间(例如100ms到1秒),并且术语“实时”可以表示“近似实时”或“接近实时”。
88.首先参考图1,其示出了根据一个或多个实施例的用于实时交互和指导的用户设备100的系统示图。用户设备100包括通信单元104、处理器单元108、存储器单元110、i/o单元112、用户界面引擎114和电源单元116。用户设备100具有显示器106,其也可以是用户输入设备,诸如与屏幕集成的电容式触摸传感器。
89.处理器单元108控制用户设备100的操作。处理器单元108可以是可根据本领域技术人员已知的用户设备100的配置、目的和要求来提供足够处理能力的任何合适的处理器、控制器或数字信号处理器。例如,处理器单元108可以是高性能通用处理器。在替换实施例中,处理器单元108可以包括一个以上处理器,且每个处理器被配置成执行不同的专用任务。在替换实施例中,可以使用专用硬件来提供由处理器单元108提供的一些功能。例如,处理器单元108可以包括标准处理器,诸如的处理器、的处理器或微控制器。
90.通信单元104可以包括有线或无线连接能力。通信单元104可以包括根据诸如ieee 802.11a、802.11b、802.11g或802.11n等标准利用4g、lte、5g、cdma、gsm、gprs或蓝牙协议进行通信的无线电。通信单元104可以被用户设备100用来与其他设备或计算机通信。
91.处理器单元108还可执行用于生成各种用户界面的用户界面引擎114,其一些示例在本文中示出和描述,诸如图3、4、5、6和7中所示的各界面。任选地,在用户设备是诸如图10中的1016的用户设备的情况下,诸如图14和15的用户界面可被生成。
92.用户界面引擎114被配置成生成界面以供用户在执行身体活动、举重或其他类型的动作时接收反馈推断。反馈推断可以与由用户设备收集的视频信号一起被基本实时提供。反馈推断可以由用户界面引擎114叠加在由i/o单元112接收的视频信号上。任选地,用户界面引擎114可以提供用于标记视频样本的用户界面。由用户界面引擎114生成的各种界面在显示器106上被显示给用户。
93.显示器106可以是基于led或lcd的显示器并且可以是支持姿势的触敏用户输入设备。
94.i/o单元112可以包括鼠标、键盘、触摸屏、指轮、轨迹板、轨迹球、读卡器、语音识别软件等中的至少一者,这同样取决于用户设备100的特定实现。在一些情形中,这些组件中的一些组件可以相互集成。
95.i/o单元112可进一步从用户设备100的视频输入设备(诸如相机(未示出))接收视频信号。相机可以在使用用户设备的用户执行诸如身体活动等的动作时生成该用户的视频信号。相机可以是cmos有源像素图像传感器等。来自图像输入设备的视频信号的格式可使用h.263编码器以3gp格式提供给视频缓冲器124。
96.电源单元116可以是向用户设备100供电的任何合适的电源,诸如电源适配器或可
充电电池组,这取决于本领域技术人员已知的用户设备100的实现。
97.存储器单元110包括用于实现操作系统120、程序122、视频缓冲器124、骨干网络126、全局活动检测头部128、离散事件检测头部130、局部活动检测头部132、反馈引擎134的软件代码。
98.存储器单元110可以包括ram、rom、一个或多个硬盘驱动器、一个或多个闪存驱动器或一些其他合适的数据存储元件,诸如磁盘驱动器等。存储器单元110被用于存储本领域技术人员公知的操作系统120和程序122。例如,操作系统120为用户设备100提供各种基本操作过程。例如,操作系统120可以是移动操作系统,诸如的android操作系统或的ios操作系统,或另一操作系统。
99.程序122包括各种用户程序,使得用户可以与用户设备100交互以执行各种功能,诸如但不限于与用户设备交互、用相机记录视频信号以及向用户显示信息和通知。
100.骨干网络126、全局活动检测头部128、离散事件检测头部130和局部活动检测头部132可作为来自的或的play的软件应用提供给用户设备100。在图12中更详细地描述了骨干网络126、全局活动检测头部128、离散事件检测头部130和局部活动检测头部132。
101.视频缓冲器124从i/o单元112接收视频信号数据并将其存储以供骨干网络126、全局活动检测头部128、离散事件检测头部130和局部活动检测头部132使用。视频缓冲器124可以经由i/o单元112从相机设备接收流式视频信号数据,或者可以接收存储在用户设备100的存储设备上的视频信号数据。
102.缓冲器124可以允许快速访问视频信号数据。缓冲器124可以具有固定大小并且可以使用先进先出替换策略来替换缓冲器124中的视频数据。
103.骨干网络126可以是机器学习模型。骨干网络126可以是预训练的并且可以在提供给用户设备100的软件应用中提供。例如,骨干网络126可以是神经网络,诸如卷积神经网络。卷积神经网络可以是三维神经网络。卷积神经网络可以是可步进卷积神经网络。骨干网络可以是骨干网络1204(见图12)。
104.全局活动检测头部128可以是机器学习模型。全局活动检测头部128可以是预训练的并且可以在提供给用户设备100的软件应用中提供。例如,全局活动检测头部128可以是神经网络,诸如卷积神经网络。卷积神经网络可以是三维神经网络。卷积神经网络可以是可步进卷积神经网络。全局活动检测头部128可以是全局活动检测头部1208(见图12)。
105.离散事件检测头部130可以是机器学习模型。离散事件检测头部130可以是预训练的并且可以在提供给用户设备100的软件应用中提供。例如,离散事件检测头部130可以是神经网络,诸如卷积神经网络。卷积神经网络可以是三维神经网络。卷积神经网络可以是可步进卷积神经网络。离散事件检测头部130可以是离散事件检测头部1210(见图12)。
106.局部活动检测头部132可以是机器学习模型。局部活动检测头部132可以是预训练的并且可以在提供给用户设备100的软件应用中提供。例如,局部活动检测头部132可以是神经网络,诸如卷积神经网络。卷积神经网络可以是三维神经网络。卷积神经网络可以是可步进卷积神经网络。局部活动检测头部132可以是局部活动检测头部1212(见图12)。
107.反馈引擎134可以与骨干网络126、全局活动检测头部128、离散事件检测头部130
和局部活动检测头部132协作,以鉴于用户设备100的视频输入设备为执行动作的用户生成反馈推断。
108.反馈引擎134可以执行图2的方法以便鉴于用户设备100的视频输入设备基于用户动作来为用户确定反馈。
109.反馈引擎134可为用户设备100的用户生成反馈,包括音频、视听和视觉反馈。创建的反馈可以包括使用户改善他们的身体活动的提示、关于他们的身体活动的形式的反馈、指示用户执行锻炼的成功程度的锻炼评分、用户消耗的卡路里估计、用户活动的重复计数。此外,鉴于连接到i/o单元112的视频输入设备,反馈引擎134可以为多个用户提供反馈。
110.接下来参考图2,示出了根据一个或多个实施例的用于实时交互和指导的方法示图200。
111.用于实时交互和指导的方法200可包括在用户设备处向用户输出反馈推断(包括经由音频或视觉提示)。为了确定反馈推断,可以接收视频信号,该视频信号可以由反馈引擎使用反馈模型进行处理(见图12)。
112.方法200可以提供关于由用户执行的活动或锻炼的基本实时反馈。反馈可以由化身提供或叠加在用户的视频信号上,使得他们可以看到并纠正他们的锻炼形式。例如,反馈可以包括用户的姿势信息(使得他们可以基于所收集的视频信号来纠正姿势),或者基于所收集的视频信号的锻炼的反馈。这对于指导可能是有用的,其中“教练”化身提供有关如何执行活动(例如,锻炼)的形式和其他方面的实时反馈。
113.在202,提供反馈模型。
114.在204,在该用户设备处接收视频信号,该视频信号包括至少两个视频帧,该至少两个视频帧中的第一视频帧在该至少两个视频帧中的第二视频帧之前被捕捉。
115.在206,生成包括该至少两个视频帧的该反馈模型的输入层。
116.在208,基于该反馈模型和该输入层来确定与该至少两个视频帧中的该第二视频帧相关联的反馈推断。
117.在一个或多个实施例中,反馈推断可使用该用户设备的输出设备被输出给该用户。
118.在一个或多个实施例中,该反馈模型可包括骨干网络和至少一个头部网络。在图12中更详细地描述了模型架构。
119.在一个或多个实施例中,该骨干网络可以是三维卷积神经网络。
120.在一个或多个实施例中,该至少一个头部网络中的每个头部网络可以是神经网络。
121.在一个或多个实施例中,该至少一个头部网络可包括全局活动检测头部网络,该全局活动检测头部网络用于基于该骨干网络的层确定该视频信号的活动分类;并且该反馈推断可包括该活动分类。
122.在一个或多个实施例中,该活动分类可包括选自锻炼分数、卡路里估计和锻炼形式反馈的群中的至少一者。
123.在一个或多个实施例中,该反馈推断可包括重复分数,该重复分数是基于该活动分类和从离散事件检测头部接收的运动重复计数来确定的;并且其中该活动分类可包括锻炼分数。
124.在一个或多个实施例中,该锻炼分数可以是基于跨多个活动标记的softmax输出向量与跨多个活动标记的标量奖励值向量之间的内积来确定的连续值。
125.在一个或多个实施例中,该至少一个头部网络可包括离散事件检测头部网络(参见例如图12),该离散事件检测头部网络用于基于该骨干网络的层从该视频信号确定至少一个事件,该至少一个事件中的每个事件可包括事件分类;并且该反馈推断包括该至少一个事件。
126.在一个或多个实施例中,该至少一个事件中的每个事件可进一步包括时间戳,该时间戳对应于该视频信号;并且该至少一个事件对应于用户锻炼重复的一部分。
127.在一个或多个实施例中,该反馈推断可包括锻炼重复计数。
128.在一个或多个实施例中,该至少一个头部网络可包括局部活动检测头部网络(参见图12),该局部活动检测头部网络用于基于该骨干网络的层从该视频信号确定至少一个边界框并确定与该至少一个边界框中的每个边界框对应的活动分类;并且该反馈推断可包括该至少一个边界框以及与该至少一个边界框中的每个边界框对应的该活动分类。
129.在一个或多个实施例中,该反馈推断可包括针对一个或多个用户的活动分类,该边界框对应于该一个或多个用户。
130.接下来参考图3,示出了根据一个或多个实施例的用于实时交互和指导的场景示图300。
131.所示的场景示图300提供了在用户设备上使用软件应用来辅助锻炼活动的示例视图。用户302操作用户设备304,该用户设备304运行包括如图12所示描述的反馈模型的软件应用。用户设备304捕捉由反馈模型处理的视频信号以便生成反馈推断,诸如形成反馈306。当用户302正在执行活动时,相关联的反馈推断306被输出给用户302,并且是基本实时的。输出可以是对用户302的音频提示、来自虚拟助理或化身的消息、或叠加在视频信号上的字幕的形式。
132.用户设备304可以由健身中心、健身教练、用户302自己或其他个人、团体或企业提供。用户设备304可用于健身中心、家中、室外或用户302可使用用户设备304的任何地方。
133.用户设备304的软件应用可被用于提供有关用户302完成的锻炼的反馈。锻炼可以是瑜伽、普拉提、重量训练、体重锻炼或其他身体锻炼。当用户302完成锻炼时,软件应用可从用户302的用户设备304的视频输入设备或相机获得视频信号。所提供的反馈可以向用户302提供用于指示重复次数、设定次数、正面激励、可用的锻炼修正、形式纠正、重复速度、身体部位的角度、步幅或身体放置的宽度、锻炼深度的反馈,或其他类型的反馈。
134.软件应用可以以反馈的形式向用户302提供信息以在锻炼期间改进用户302的形式。输出可以包括对肢体放置、保持历时、身体定位的纠正,或仅可在软件应用可以通过来自用户设备304的视频信号检测用户302的身体放置的情况下才能获得的其他纠正。
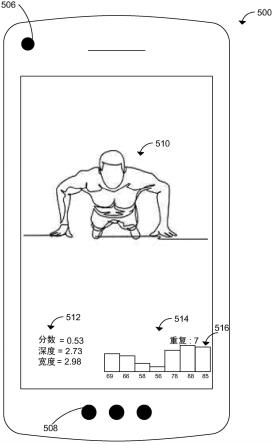
135.软件应用可以以化身、虚拟助理等形式向用户302提供反馈推断306。化身可以向用户302提供适当的身体和肢体放置、提高或降低难度级别的锻炼修正的视觉表示、或其他视觉表示。反馈推断306可进一步包括对用户302的音频提示。
136.软件应用可以以由用户设备304的相机拍摄的视频信号的形式向用户302提供反馈推断306。视频信号可以具有叠加在该视频信号上的反馈推断306,其中反馈推断306包括上述反馈选项中的一者或多者。
137.接下来参考图4,示出了根据一个或多个实施例的包括虚拟化身408的用于实时交互和指导的场景示图400。房间402被示为在用户设备404上使用软件应用时包含用户406,而用户设备404表示从用户设备404输出给用户406的内容。
138.用户406可在用户设备404上操作包括如图12所示描述的反馈模型的软件应用。用户设备404捕捉由反馈模型处理的视频信号以便生成虚拟化身408。虚拟化身408可被输出给用户406以引导用户406完成锻炼例程、个人锻炼等。虚拟化身408还可向用户406提供反馈,诸如重复次数、设定次数、正面激励、可用的锻炼修正、形式纠正、重复速度、身体部位的角度、步幅或身体放置的宽度、锻炼深度,或其他类型的反馈。通过用户设备404提供给用户406的反馈(未示出)可以是视觉表示或音频表示。
139.接下来参考图5,示出了根据一个或多个实施例的用于实时交互和指导的用户界面示图500。
140.用户510操作用户界面500,该用户界面500运行包括如图12所示描述的反馈模型的软件应用。用户界面500通过相机506捕捉由反馈模型处理的视频信号并且可以生成反馈推断514和活动分类512。相关联的反馈推断514和活动分类512可在用户510执行活动期间和/或执行活动之后被输出给用户510。如图所示,输出可以是叠加在视频信号上的字幕。
141.视频信号可以由全局活动检测头部和离散事件检测头部处理以分别生成反馈推断514和活动分类512。反馈推断可以包括重复计数、步幅或身体放置的宽度,或如前描述的其他类型的反馈。活动分类可以包括形式反馈、公平锻炼评分和/或卡路里估计。全局活动检测头部和离散事件检测头部可以定义用户510的运动以输出运动的视觉表示516。
142.用户界面500可以向用户510提供由用户界面500的相机506拍摄的视频信号形式的输出。视频信号可以具有叠加在视频信号上的反馈推断514、活动分类512和/或运动的视觉表示516。
143.接下来参考图6,示出了根据一个或多个实施例的用于实时交互和指导的用户界面示图600。
144.用户610操作用户界面600,该用户界面600运行包括如图12所示描述的反馈模型的软件应用。用户界面600通过相机606捕捉由反馈模型处理的视频信号并且可以生成活动分类512。活动分类612可在用户610执行活动期间和/或执行活动之后被输出给用户610。输出可以是叠加在视频信号上的字幕。
145.视频信号可由离散事件检测头部处理以生成活动分类612。活动分类可以包括公平锻炼评分、卡路里估计和/或形式反馈,诸如身体放置的角度、重复速度,或如前文描述的其他类型的反馈。
146.用户界面600可以向用户610提供由用户界面600的相机606拍摄的视频信号形式的输出。视频信号可以具有叠加在视频信号上的活动分类612。
147.接下来参考图7,示出了根据一个或多个实施例的用于实时交互和指导的另一用户界面示图700。
148.用户710操作用户界面700,该用户界面700运行包括如图12所示描述的反馈模型的软件应用。用户界面700通过相机706捕捉由反馈模型处理的视频信号并且可以生成活动分类712。活动分类712可在用户710执行活动期间和/或执行活动之后被输出给用户710。输出可以是叠加在视频信号上的字幕。
149.视频信号可由离散事件检测头部处理以生成活动分类712。活动分类可以包括公平锻炼评分、卡路里估计和/或形式反馈,诸如步幅或身体放置的宽度、重复速度,或如前文描述的其他类型的反馈。
150.用户界面700可以向用户710提供由用户界面700的相机706拍摄的视频信号形式的输出。视频信号可以具有叠加在视频信号上的活动分类712。
151.接下来参考图10,示出了根据一个或多个实施例的用于生成反馈模型的系统示图1000。该系统可以具有辅助设备1002、网络1004、服务器1006和用户设备1016。虽然示出了三个用户设备1016,但可能存在三个以上用户设备。
152.用户设备1016通常可对应于与图1中相同类型的用户设备,除了其中经下载的软件应用包括标记引擎而不是骨干网络126、活动头部128、130和132以及反馈引擎134。标记引擎可在用户设备1016处由标记用户使用(参见图10)。具有标记引擎的用户设备1016可以被称为标记设备1016。标记引擎可以从应用商店下载,诸如的play或the的服务器1006可以操作图11的方法以便基于来自用户设备1016的标记数据来生成反馈模型。
153.标记用户(未示出)可以各自操作用户设备1016a到1016c以便标记训练数据,包括视频样本数据。用户设备1016与服务器1006进行网络通信。用户可以向服务器1006发送或接收训练数据,包括视频样本数据和标记数据。
154.网络1004可以是能够携带数据的任何网络或网络组件,包括互联网、以太网、光纤、卫星、移动、无线(例如wi-fi、wimax)、ss7信令网络、固定线路、局域网(lan)、广域网(wan)、直接点对点连接、移动数据网络(例如,通用移动电信系统(umts)、3gpp高级长期演进(高级lte)、微波接入全球互通(wimax)等)和其他,包括这些的任何组合。
155.辅助设备1002可以是具有与其他设备通信的能力的任何双向通信设备,包括移动设备,诸如运行的操作系统或的操作系统的移动设备。辅助设备1002可以允许在服务器1006处生成管理模型,以及将包括视频样本数据的训练数据委托给用户设备1016。
156.每个用户设备1016包括并执行软件应用(诸如标记引擎)以参与数据标记。软件应用可以是由服务器1006提供的用于数据标记的web应用,或者它可以是例如经由应用商店(诸如的或的app)安装在用户设备1016上的应用。
157.如图所示,用户设备1016被配置成使用网络1004与服务器1006通信。例如,服务器1006可以为在用户设备1016上运行的应用提供web应用或应用编程接口(api)。
158.服务器1006是任何联网的计算设备或系统,包括处理器和存储器,并且能够与网络(诸如网络1004)进行通信。服务器1006可包括彼此可通信地耦合的一个或多个系统或设备。计算设备可以是个人计算机、工作站、服务器、便携式计算机或这些的组合。
159.服务器1006可以包括用于存储在用户设备1016处从标记用户接收的视频样本数据和标记数据的数据库。
160.数据库可以存储标记用户信息、视频样本数据和其他相关信息。数据库可以是结构化查询语言(sql)(诸如postgresql或mysql),或者不仅仅是sql(nosql)数据库(诸如mongodb、或者图形数据库等)。
161.接下来参考图11,示出了根据一个或多个实施例的用于生成反馈模型的方法示图1100。
162.反馈模型的生成可能涉及神经网络的训练。神经网络的训练可以使用标有活动或有关视频内容的其他信息的视频剪辑。针对训练,可以使用“全局”标记和“局部”标记两者。全局标记可能包含有关训练视频剪辑中的多个(或所有)帧的信息(例如,剪辑中进行的活动)。局部标记可能包含指派给剪辑中特定帧的时间信息,诸如活动的开始或结束。
163.在实时应用(诸如指导)中可以使用三维卷积。每个三维卷积可在推断时变成“可步进”模块,其中每个帧只能被处理一次。在训练期间,可以以“因果”方式应用三维卷积。“因果”方式可以指在卷积神经网络中来自未来的信息不可能渗入到过去中(参见例如图13以了解更多细节)。这可能还涉及对离散事件检测头部的训练,其需要及时标识精确时间位置处的活动。
164.在1102,向多个标记用户传送多个视频样本,该多个视频样本中的每个视频样本包括视频数据,该多个标记用户中的每个标记用户接收该多个视频样本中的至少两个视频样本。
165.在1104,从该多个标记用户接收多个排名响应,该多个排名响应中的每个排名响应指示由相应标记用户基于排名标准从传送给该相应标记用户的该至少两个视频样本中选择的相对排名。
166.在1106,基于该多个排名响应和该排名标准来确定该多个视频样本中的每个视频样本的排序标记。
167.在1108,基于每个视频样本的相应排序标记将多个视频样本整理到多个桶中。
168.在1110,确定该多个桶中的每个桶的分类标记。
169.在1112,基于该多个桶、每个相应桶的分类标记和每个相应桶的视频样本来生成反馈模型。
170.在一个或多个实施例中,生成该反馈模型可以包括应用基于梯度的优化来确定该反馈模型。
171.在一个或多个实施例中,该反馈模型可包括至少一个头部网络。
172.在一个或多个实施例中,该至少一个头部网络中的每个头部网络可以是神经网络。
173.在一个或多个实施例中,该方法可进一步包括确定来自该多个标记用户的足够数目的多个排名响应已被接收到。
174.在一个或多个实施例中,该排名标准可包括选自锻炼速度、重复和运动范围的群中的至少一者。
175.在一个或多个实施例中,该排名标准可以与特定类型的身体锻炼相关联。
176.方法1100可以描述成对标记方法。在许多交互式应用中,特别是与指导相关的交互式应用中,在对应于线性顺序(或排名)的标记上训练识别头部可能很有用。例如,网络可以提供与执行锻炼的速度相关的输出。另一示例是在执行运动时对运动范围的识别。与其他类型的标记类似,可以通过人工标记为给定视频生成对应于线性顺序的标记。
177.成对标记允许标记用户一次标记两个视频(v1和v2)并且仅提供有关顺序的相对判断。例如,在速度标记的情形中,标记可能相当于确定是否v1》v2(视频v1中的运动中显示的
速度高于视频v2中的运动中显示的速度),反之亦然。给定足够大数目的此类成对标记,可对示例数据集进行整理。在实践中,将每个视频与10个其他视频进行比较通常足以产生与人类判断密切相关的排名(参见例如图16)。然后可以将各个视频排名分组到任意数量的桶中,并且可以为每个桶指派分类标记。
178.接下来参考图12,示出了根据一个或多个实施例的用于确定反馈推断的模型示图1200。模型1200可以是神经网络架构并且可以从视频信号接收两个或更多个视频帧1202作为输入。模型1200具有骨干网络1204,其可以优选地是生成运动特征1206的三维卷积神经网络,运动特征1206是一个或多个检测头部的输入,包括全局活动检测头部1208、离散事件检测头部1210和局部活动检测头部1212。
179.由于视频信号中的大多数视觉概念彼此相关,因此共用神经网络结构(诸如模型1200中所示)可以通过迁移学习利用共性,并且可以包括共享骨干网络1204和单独的因任务而异的头部1208、1210和1212。迁移学习可包括确定可用于扩展模型1200的能力的运动特征1206,因为骨干网络1204可以在接收视频信号时被重新用于处理视频信号,并且进一步在顶部训练新的检测头部。
180.骨干网络1204从视频信号中接收至少一个视频帧1202。骨干网络1204可以是在其顶部联合训练多个头部的共享骨干网络。模型1200可以具有端到端训练的架构,具有包括像素数据作为输入和活动标记作为输出(而不是利用边界框、姿势估计或逐帧分析的形式作为中间表示)的视频帧。骨干网络1204可以执行如图13中描述的可步进卷积。
181.每个头部网络1208、1210和1212可以是具有1、2或更多个全连通层的神经网络。
182.全局活动检测头部1208被连接到骨干网络1204的层并生成细粒度活动分类输出1214,其可被用于向用户提供反馈1220,包括形式反馈推断、锻炼评分推断和卡路里估计推断。
183.反馈推断1220可以与全局活动检测头部1208的单个输出神经元相关联,并且可以应用阈值,高于该阈值将触发相应的形式反馈。在其他情形中,可以对多个神经元的softmax值求和以提供反馈。
184.当检测头部1208的分类输出1214与给定反馈所需的相比具有更细粒度时(换言之,当多个神经元对应于执行活动的多个不同变体时),可以发生合并。
185.一种类型的反馈推断1220是锻炼分数。为了公平地对执行特定锻炼的用户进行评分,反馈模型1208的多元分类输出1214可以通过计算跨各个类的softmax输出向量(图8中的pi)和将标量奖励值(图8的wi)与每个类相关联的“奖励”向量之间的内积来被转换为单个连续值。更具体地,可以为与所考虑的锻炼相关的每个活动标记指派权重(参见图8)。与正确形式(或更高强度)相对应的标记可能会收到较高的奖励,而与不良形式相对应的标记可能会获得较低的奖励。如此,内积可能与形式、强度等相关。
186.参考图8和图9,示出了在对“高抬腿”的形式准确性和强度进行评分的上下文中解说这一点的表格示图,其中wi对应于奖励权重,而pi对应于分类输出。具体而言,图8解说了考虑形式、速度和强度的总体奖励,而图9解说了仅考虑执行锻炼的速度的奖励。
187.图8和9的评分办法可被用于对形式以外的度量进行评分,包括诸如速度/强度或瞬时卡路里消耗率之类的度量。
188.锻炼分数1220可以针对用户健身锻炼表现的多个不同方面(例如形式或强度)进
一步分离强度和形式评分(或为任何其他度量集评分)。在此情形中,与特定方面(诸如形式)无关的输出神经元可以从softmax计算中移除(参见例如图9)。通过这样做,概率质量可以被重新分布到与所考虑的方面相关的其他神经元,并且先前描述的公平评分办法可被用于获得关于当前特定方面的分数。
189.在另一度量示例中,可以估计用户燃烧的卡路里1220。卡路里估计1220可以是上文描述的评分办法的一种特殊情形,其可被用于动态估计在相机前锻炼的人的卡路里消耗率。在此情形中,每个活动标记可被赋予一权重,该权重与该活动的任务代谢当量(met)值成比例(参见参考文献(4)、(5))。假设人的体重是已知的,这可被用于推导出瞬时卡路里消耗率。
190.神经网络头部可被用于从给定训练数据集预测met值或卡路里消耗,其中活动用此信息标记。这可允许系统在测试时推广到新的活动。
191.返回参考图12,在一个或多个实施例中,该至少一个头部网络可包括离散事件检测头部网络1210,该离散事件检测头部网络1210用于基于该骨干网络的层从该视频信号确定至少一个事件,该至少一个事件中的每个事件可包括事件分类;并且该反馈推断包括该至少一个事件。
192.离散事件检测头部1210可被用于在特定活动内执行事件分类1216。例如,两个此类事件可能是锻炼(诸如俯卧撑)的中间点以及俯卧撑重复的结束。与上文讨论的识别头部相比(它通常输出在最后几秒钟期间连续执行的活动的摘要),离散事件检测头部可以被训练为在事件发生的准确时间位置触发很短时间段(通常为一帧)。这可被用于确定动作的时间范围,并且例如实时对到目前为止执行的锻炼重复的数目1222进行计数。
193.这也可以允许行为策略,该行为策略可以响应于观察到的输入的序列执行连续的动作序列。行为策略的示例应用是姿势控制系统,其中姿势的视频流被转换为控制信号,例如用于控制娱乐系统。
194.通过将离散事件计数与锻炼评分相结合,该网络可被用于向用户提供重复计数,其中每个计数通过对所执行的重复的形式/强度/等的评估来加权。这些加权计数可以例如使用条形图516来传达给用户。这在图5中被解说。由离散事件计数和锻炼评分的组合产生的度量可被称为重复分数。
195.局部活动检测头部1212可以确定围绕人体和面部的边界框1218,并且可预测每个边界框的活动标记1224,例如,确定面部是否例如“正在微笑”或“正在说话”或身体是否“正在跳跃”或“正在跳舞”。此头部的主要动机是允许系统和方法同时与多个用户进行可察觉的交互。
196.当多个用户存在于视频帧1202中时,对输入视频中执行的每个活动执行空间局部化而不是执行单个全局活动预测1220可能是有用的。对输入视频中执行的每个活动执行空间局部化也可以用作辅助任务,以使全局动作分类器对异常背景条件和用户定位更加强健。预测边界框1218以对对象进行局部化是已知的图像理解任务。与图像理解相比,视频中的活动理解可以使用在空间和时间上扩展的三维边界框。为了训练,三维边界框可以将局部化表示为信息以及活动标记。
197.除了由活动识别头部产生的全局活动预测之外,局部化头部可被用作动作分类器架构中的单独头部以从中间特征产生局部活动预测。生成训练所需的三维边界框的一种方
法是将图像的现有对象局部化器逐帧应用于训练视频。可以推断出注释,而无需对已知显示单个人执行动作的那些视频进行任何进一步标记。在此情形中,视频的已知全局动作标记也可以是边界框的活动标记。
198.活动标记可以按身体部位(例如,面部、身体等)来分割,并可被附加到对应的边界框(例如,“正在微笑”和“正在跳跃”标记将分别被附加到面部和身体边界框)。
199.接下来一起参考图12和13,示出了根据一个或多个实施例的模型1200的可步进卷积示图1300,该可步进卷积用于确定反馈推断。可步进卷积示图1300示出了输出序列和输入序列。输入序列可以包括来自与接收到的视频帧相关联的各种时间戳的输入。例如,帧1306示出了网络基于时间t 1304处的输入、时间t-1 1308处的输入和时间t-2 1310处的输入进行推断输出1302。输出1302基于输入1310、1308和1304的可步进卷积。如可步进卷积示图1300中所示的输入层和输出层可以对应于骨干网络中的各层,或至少一个检测头部(参见图12)。
200.可步进卷积可被模型1200(参见图12)用于处理视频信号,诸如流式(实时)视频信号。在从用户设备的视频输入设备接收到流式视频的情形中,模型可以在接收到新视频帧时不断地更新其预测。与无状态的常规三维卷积相比,可步进卷积可以维持内部状态,该内部状态存储来自输入视频信号序列的过去信息(诸如中间视频帧表示,或视频帧本身的输入表示)以用于执行后续推断步骤。对于大小为k的内核(k在图13中等于3,即在时间t 1302处的推断),最后k-1个输入元素(k-1在图13中等于2)(包括在时间t-1 1308处的输入和在时间t-2 1310处的输入)被要求执行下一推断步骤,并因此必须被内部保存。因此,网络的输入表示包括在前的输入。一旦计算出新的输出,就需要更新内部状态以准备下一推断步骤。在下面的示例中,这意味着在内部状态中存储在时间步长t-1 1308和t 1304处的2个输入。内部状态可以是缓冲器124(见图1)。
201.可以使用多种神经网络架构和层。三维卷积可能有助于确保输入视频的运动模式和其他时间方面被有效地处理。将三维和/或二维卷积分解为“外积”和逐元素运算可能有助于减少计算足迹。
202.此外,其他网络架构的各方面可被并入模型1200(参见图12)。其他架构可以包括那些用于图像(不是视频)处理的架构,诸如参考文献(6)和(10)中描述的架构。为此,可通过添加时间维度来“膨胀”二维卷积(参见例如参考文献(7))。最后,时间和/或空间跨步可被用于减少计算足迹。
203.接下来参考图14,示出了根据一个或多个实施例的用于时间标记以生成反馈模型的用户界面示图1400。
204.用户界面示图1400提供用户1420完成身体锻炼的示例视图。锻炼可以是瑜伽、普拉提、重量训练、体重锻炼或其他身体锻炼。图14所示的示例是俯卧撑锻炼的示例。
205.用户1420可以操作包括用于生成反馈模型的时间标记的软件应用。用户设备捕捉由反馈模型处理的视频信号以便基于用户1420的移动和位置来生成时间标记。时间标记可被覆盖在视频帧上并被输出回用户1420。
206.参考图14中所示的示例,第一视频帧1402包括处于俯卧撑位置的用户1420。时间标记界面可被用于将事件标签1424、1426、1428指派给特定视频帧。可以基于用户1420的移动和位置来指派事件标签1424、1426、1428。第一视频帧1402显示用户1420处于时间标记界
面已标识为“背景”标签1424的位置。“背景”标签1424可以是提供给视频帧的默认标记,其中时间标记界面尚未标识特定事件。
207.视频帧1404中的时间标记界面已经确定用户1420已经完成了俯卧撑重复。“高位”标签1426已被识别为视频帧1404的事件标记。
208.视频帧1410中的时间标记界面已经确定用户1420正处于俯卧撑重复的中间点。“低位”标签1428已被识别为视频帧1404的事件标记。
209.事件分类器1422可被显示在用户界面上,作为对将基于用户1420的移动和位置来标识的即将发生的事件标记的建议。随着用户1420向软件应用提供更多视频信号输入,事件分类器1422可以随着时间而改进
210.图14中示出了示例实施例,其中用户1420完成俯卧撑锻炼。在其他实施例中,用户1420可以完成如前文所提及的其他锻炼。在这些其他实施例中,每个视频帧的事件标记可对应于用户1420的移动和身体位置。
211.标识逐帧事件的时间注释可以使得能够学习特定在线行为策略。在健身用例的上下文中,在线行为策略的一个示例可能是重复计数,这可能涉及精确标识某个动作的开始和结束。对视频进行标记以获得逐帧标记可能是耗时的,因为这需要检查每一帧以寻找特定事件的存在。如在用户界面1400中所示,通过使用基于对神经网络(神经网络被迭代训练以标识特定事件)的预测来显示建议的标记过程可以使标记过程更高效。此界面可被用于快速发现视频样本中的感兴趣帧。
212.接下来参考图15,示出了根据一个或多个实施例的用于成对标记以生成反馈模型的用户界面示图1500。
213.多个视频信号1510可以通过标记用户界面1502被输出给一个或多个标记用户。标记用户可以比较多个视频信号1510以基于指定标准提供多个排名响应。排名响应可以从标记用户的用户设备被传送到服务器。指定标准可以包括用户正在执行锻炼的速度、用户执行锻炼的形式、用户执行的重复次数、用户的运动范围或其他标准。
214.在图15所示的示例中,标记用户可以比较两个视频信号1510并基于指定的标准来选择用户。标记用户可以通过使用标记用户界面1502选择第一指示符1508或第二指示符1512来指示相对排名,其中每个指示符对应于一特定用户。
215.在基于指定标准指示相对排名之后,标记用户可以通过选择“下一步(next)”1518来指示他们已经完成了所请求的任务。可能会要求标记用户为任何预定数量的用户提供排名响应。在图15所示的实施例中,需要从标记用户得到25个排名响应。标记用户界面1502可以提供标记用户当前正在完成的响应编号1516和排名响应的完成百分比1504的表示。标记用户可以通过选择“上一步(prev)”1514来查看和/或更新先前完成的排名响应。一旦标记用户完成了所需数目的排名响应,标记用户就可以选择“提交(submit)”1506。
216.接下来参考图17,示出了根据一个或多个实施例的包括虚拟化身的用于实时交互和指导的用户界面示图1700。
217.用户设备捕捉由如图12所示描述的反馈模型处理的视频信号以便生成虚拟化身。出于前文提及的原因,虚拟化身可被输出给用户。如前文提及的,虚拟化身可进一步向用户提供反馈。
218.用户界面可以向用户提供虚拟化身的视图和时间维度。时间维度可被用于向用户
通知锻炼的剩余时间、总练习的剩余时间、已完成的锻炼的百分比、已完成的总练习的百分比,或与锻炼定时相关的其他信息。
219.此处仅以示例的方式描述了本发明。可在不脱离本发明的精神和范围的情况下对这些示例性实施例进行各种修改和变化,本发明的精神和范围仅由所附权利要求限制。
220.参考文献:
221.(1)towards situated visual ai via end-to-end learning on video clips(经由对视频剪辑的端到端学习的面向位置的视觉人工智能),https://medium.com/twentybn/towards-situated-visual-ai-via-end-to-end-learning-on-video-clips-2832bd9d519f
222.(2)how we construct a virtual being’s brain with deep learning(我们如何通过深度学习构建虚拟人类大脑),https://towardsdatascience.com/how-we-construct-a-virtual-beings-brain-with-deep-learning-8f8e5eafe3a9
223.(3)putting the skeleton back in the closet(把骨架放回壁橱),https://medium.com/twentybn/putting-the-skeleton-back-in-the-closet-1e57a677c865
224.(4)metabolic equivalent of task(任务代谢当量),https://en.wikipedia.org/wiki/metabolic_equivalent_of_task
225.(5)the compendium of physical activities tracking guide(身体活动跟踪指南汇编),http://prevention.sph.sc.edu/tools/docs/documents_compendium.pdf
226.(6)higher accuracy on vision models with efficientnet-lite(使用efficientnet-lite的更高精度的视觉模型),https://blog.tensorflow.org/2020/03/higher-accuracy-on-vision-models-with-efficientnet-lite.html
227.(7)quo vadis,action recognition?a new model and the kinetics dataset(quo vadis,行动识别?新模型和动力学数据集),https://arxiv.org/abs/1705.07750
228.(8)you only look once:unified,real-time object detection(您只需看一次:统一的实时对象检测),https://arxiv.org/abs/1506.02640
229.(9)yolov3:an incremental improvement(yolov3:一种增量改进),https://arxiv.org/abs/1804.02767
230.(10)mobilenetv2:inverted residuals and linear bottlenecks(mobilenetv2:反向残差和线性瓶颈),https://arxiv.org/abs/1801.04381
231.(11)depthwise separable convolutions for machine learning(用于机器学习的逐深度可分离卷积),https://eli.thegreenplace.net/2018/depthwise-separable-convolutions-for-machine-learning/
232.(12)tsm:temporal shift module for efficient video understanding(tsm:用于高效视频理解的时间位移模块),https://arxiv.org/abs/1811.08383
233.(13)jasper:an end-to-end convolutional neural acoustic model(jasper:端到端卷积神经声学模型),https://arxiv.org/abs/1904.03288
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1