图像识别装置、图像识别方法以及识别词典生成方法与流程
1.本发明涉及图像识别装置、图像识别方法以及识别词典生成方法。
背景技术:
2.已知有使用模式匹配等图像识别技术从拍摄车辆周围的图像中检测行人等对象物的技术。例如,提出了如下技术:根据拍摄图像生成近距离用、中距离用和远距离用的三个图像,并对三个图像分别进行使用了共同的识别词典的图案匹配,由此来提高检测精度(例如,参照专利文献1)。
3.现有技术文献
4.专利文献
5.专利文献1:日本特开2019-211943号公报。
技术实现要素:
6.发明所要解决的问题
7.在拍摄图像中包含对象物的区域的图像尺寸能够主要根据到对象物的距离而较大地变化。当对象物远时,包含对象物的区域的图像尺寸变小,当对象物近时,包含对象物的区域的图像尺寸变大。如果想要使用共用的识别词典来检测具有不同图像尺寸的对象物,则检测精度可能降低。
8.本发明是鉴于上述情况而完成的,提供一种在基于识别词典的图像识别处理中提高对象物的检测精度的技术。
9.用于解决问题的手段
10.本发明的一个方式的图像识别装置包括:图像获取部,获取拍摄图像;识别处理部,计算识别得分,所述识别得分表示在拍摄图像的一部分区域中包含预定对象物的可能性;以及判定处理部,基于由识别处理部计算的识别得分,来判定在拍摄图像中是否包含预定对象物,所述识别处理部a)当一部分区域的图像尺寸小于阈值时,使用第一识别词典数据来计算在一部分区域中的预定对象物的识别得分,所述第一识别词典数据是通过将具有小于预定值的图像尺寸的图像作为输入图像、并将表示在输入图像中包含预定对象物的可能性的识别得分作为输出的机器学习生成的;以及b)当一部分区域的图像尺寸为阈值以上时,使用第二识别词典数据来计算在一部分区域中的预定对象物的识别得分,所述第二识别词典数据是通过将具有预定值以上的图像尺寸的图像作为输入图像、并将表示在输入图像中包含预定对象物的可能性的识别得分作为输出的机器学习生成的。
11.本发明的另一方面是一种图像识别方法。该方法包括以下步骤:获取拍摄图像;计算识别得分,所述识别得分表示在拍摄图像的一部分区域中包含预定对象物的可能性;以及基于计算出的识别得分来判定在拍摄图像中是否包含所述预定对象物,在计算识别得分的步骤中,a)当一部分区域的图像尺寸小于阈值时,使用第一识别词典数据来计算在所述一部分区域中的预定对象物的识别得分,所述第一识别词典数据是通过将具有小于预定值
的图像尺寸的图像作为输入图像、并将表示在输入图像中包含预定对象物的可能性的识别得分作为输出的机器学习生成的;以及b)当一部分区域的图像尺寸为阈值以上时,使用第二识别词典数据来计算在一部分区域中的预定对象物的识别得分,所述第二识别词典数据是通过将具有预定值以上的图像尺寸的图像作为输入图像、并将表示在输入图像中包含预定对象物的可能性的识别得分作为输出的机器学习生成的。
12.本发明的又一方面是一种识别词典生成方法。该方法包括以下步骤:通过将具有小于预定值的图像尺寸的图像作为输入图像、并将表示在输入图像中包含预定对象物的可能性的识别得分作为输出的机器学习,来生成第一识别词典数据;以及通过将具有预定值以上的图像尺寸的图像作为输入图像、并将表示在输入图像中包含预定对象物的可能性的识别得分作为输出的机器学习,来生成第二识别词典数据。
13.发明效果
14.根据本发明,能够在基于识别词典的图像识别处理中提高对象物的检测精度。
附图说明
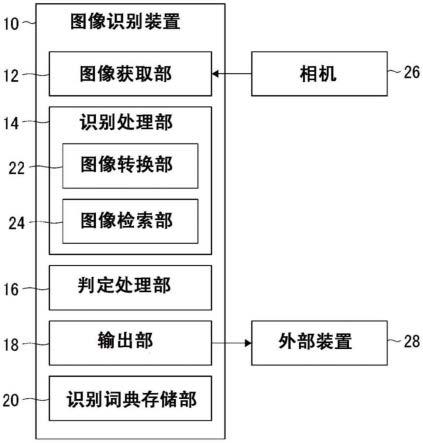
15.图1是示意性地示出实施方式涉及的图像识别装置的功能结构的框图。
16.图2是示出图像获取部所获取的拍摄图像的示例的图。
17.图3是示出输出部生成的输出图像的示例的图。
18.图4是示意性地示出图像转换部生成的多个转换图像的图。
19.图5是示出多个转换图像的图像尺寸的一例的表。
20.图6是示意性地示出图像检索部进行的图像检索处理的图。
21.图7的(a)是示意性地示出转换图像中的切取区域的图像尺寸的图,图7的(b)是示意性地示出拍摄图像中的检索区域的图像尺寸的图。
22.图8是示出图像检索处理的检索条件的一例的表。
23.图9是示出实施方式涉及的图像识别方法的流程的流程图。
24.图10的(a)至图10的(d)是示出学习用图像的示例的图。
25.图11是示出实施方式涉及的识别词典生成方法的流程的流程图。
具体实施方式
26.以下,参照附图对本发明的实施方式进行说明。该实施方式所示的具体数值等只不过是用于容易理解发明的例示,除了特别说明的情况以外,并不限定本发明。另外,在附图中,与本发明没有直接关系的要素省略图示。
27.在详细说明本实施方式之前,先表述概要。本实施方式是使用识别词典数据来判定在获取的图像中是否包含预定对象物的图像识别装置。图像识别装置例如搭载在车辆上,获取拍摄车辆前方的图像。图像识别装置根据所获取的图像,检测行人或骑车人(骑自行车的人)等对象物。识别词典数据按作为检测对象的对象物的每种类型来准备。在本实施方式中,针对同一类型的对象物(例如,行人)准备多个识别词典数据,通过区分使用多个识别词典数据来提高对象物的检测精度。
28.图1是示意性地示出实施方式涉及的图像识别装置10的功能结构的框图。图像识别装置10包括图像获取部12、识别处理部14、判定处理部16、输出部18和识别词典存储部
20。在本实施方式中,例示了将图像识别装置10搭载在车辆上的情况。
29.在本实施方式中所示的各功能块,在硬件上能够通过以计算机的cpu和存储器为首的元件和机械装置来实现,在软件上通过计算机程序等来实现,在此,将其描绘为通过它们的协作来实现的功能块。因此,本领域技术人员应当理解,这些功能块可以通过硬件、软件的组合以各种形式实现。
30.图像获取部12获取相机26拍摄的拍摄图像。相机26搭载在车辆上,拍摄车辆周围的图像。相机26例如拍摄车辆前方的图像。相机26也可以拍摄车辆的后方,也可以拍摄车辆的侧方。图像识别装置10可以具备相机26,也可以不具备相机26。
31.相机26构成为对车辆周围的红外线进行拍摄。相机26是所谓的红外热成像仪,其对车辆周围的温度分布进行图像化,从而能够确定车辆周围存在的热源。相机26可以构成为检测波长2μm~5μm左右的中红外线,也可以构成为检测波长8μm~14μm左右的远红外线。另外,相机26也可以构成为拍摄可见光。相机26也可以构成为拍摄红色、绿色和蓝色的彩色图像,或者也可以构成为拍摄可见光的单色图像。
32.图2示出图像获取部12所获取的拍摄图像30的示例。图2示出在交叉路口用红外线相机拍摄停车中的车辆的前方时的图像,在拍摄图像30中包含有正在车辆前方的人行横道上通行的行人30a和骑车人30b。
33.识别处理部14计算识别得分,该识别得分表示在由图像获取部12获取的拍摄图像的一部分区域中包含预定对象物的可能性。识别处理部14例如确定图2的包含行人30a的区域,并计算表示在确定的区域中包含行人的可能性的识别得分。识别得分例如在0~1的范围内计算,在一部分区域中包含预定对象物的可能性越高则数值越大(即,接近于1的值),在一部分区域中包含预定对象物的可能性越低则数值越小(即,接近于0的值)。
34.判定处理部16基于识别处理部14计算出的识别得分,判定拍摄图像30中是否包含预定对象物。例如,在由识别处理部14计算出的识别得分为预定基准值以上的情况下,判定处理部16判定为在识别得分为基准值以上的区域中存在预定对象物。另外,在没有成为基准值以上的识别得分的区域的情况下,判定处理部16判定为不存在预定对象物。
35.输出部18输出基于判定处理部16的判定结果的信息。在判定处理部16判定为存在预定对象物的情况下,输出部18生成附加了强调检测出的对象物的框等的输出图像。输出部18生成的输出图像显示在显示器等外部装置28上。在判定处理部16判定为存在预定对象物的情况下,输出部18也可以生成警告音。输出部18生成的警告音从扬声器等外部装置28输出。图像识别装置10也可以具备外部装置28,也可以不具备外部装置28。
36.图3是示出输出部18生成的输出图像38的示例的图。输出图像38是在拍摄图像30上重叠了检测框38a、38b的图像。输出图像38的第一检测框38a重叠在拍摄图像30的与行人30a对应的位置上。输出图像38的第二检测框38b重叠在拍摄图像30的与骑车人30b对应的位置。
37.识别词典存储部20存储识别处理部14计算识别得分时使用的识别词典数据。识别词典存储部20存储与对象物的类型对应的多种识别词典数据。例如,在识别词典存储部20中存储行人用的识别词典数据、骑车人用的识别词典数据、动物用的识别词典数据以及车辆用的识别词典数据等。识别词典数据是通过使用了将图像作为输入、将识别得分作为输出的模型的机器学习而生成的。作为用于机器学习的模型,可以使用卷积神经网络(cnn)
等。
38.识别处理部14包括图像转换部22和图像检索部24。图像转换部22对图像获取部12所获取的拍摄图像30的图像尺寸进行转换,生成图像尺寸不同的多个转换图像。图像检索部24切取由图像转换部22生成的转换图像的一部分区域,并计算表示在所切取的区域中包含预定对象物的可能性的识别得分。图像检索部24通过改变切取区域的位置来依次计算识别得分,从而检索识别得分高的区域。通过检索图像尺寸不同的多个转换图像,能够检测出拍摄图像30中包含的不同尺寸的对象物。
39.图4是示意性地示出图像转换部22生成的多个转换图像32的图。图像转换部22从拍摄图像30生成多个即n张转换图像32(32_1、
……
、32_i、
……
、32_n)。多个转换图像32通过放大或缩小原始拍摄图像30的图像尺寸来生成。多个转换图像32可以被称为“图像金字塔”,其被分层以具有金字塔结构。
40.在本文中,“图像尺寸”可以用图像的纵向和横向的像素数来定义。例如,第一转换图像32_1是通过以第一转换倍率k1放大拍摄图像30来生成的。如果将拍摄图像30的纵向的图像尺寸设为h0,则第一转换图像32_1的纵向的图像尺寸h1为h1=k1·
h0。同样地,如果将拍摄图像30的横向的图像尺寸设为w0,则第一转换图像32_1的横向的图像尺寸w1为w1=k1·
w0。此外,第n转换图像32_n是通过以第n转换倍率kn缩小拍摄图像30来生成的。第n转换图像32_n的纵向和横向的图像尺寸hn、wn为hn=kn·
h0、wn=kn·
w0。多个转换图像32各自的纵向和横向的图像尺寸hi和wi与转换倍率ki互不相同(i=1~n)。另外,多个转换图像32各自的纵向和横向的图像尺寸的比率(纵横比)hi∶wi是共用的。
41.图5是示出多个转换图像32的图像尺寸的一例的表。在图5中,例示了多个转换图像32的张数n=19,拍摄图像30的纵向和横向的图像尺寸为720
×
1280(h0=720像素,w0=1280像素)的情况。转换倍率ki被设定为等比级数,公比r=k
i+1
/ki被设定为约0.9。在图5的示例中,为了在i=1~10时将转换倍率ki设定为超过1的值以放大拍摄图像30。另一方面,在i=11~19时,将转换倍率ki设定为小于1的值,以缩小拍摄图像30。另外,多个转换图像32的张数n、转换倍率ki和拍摄图像30的图像尺寸h0和w0的具体数值不限于图5所示的示例,可以适当地设置任意值。此外,转换倍率ki可以不是等比级数,也可以是等差级数。转换倍率ki也可以用值根据编号i阶段性变化的任意数列来定义。
42.图6是示意性地示出图像检索部24进行的图像检索处理的图。图像检索部24提取作为转换图像32的一部分的切取区域34,并且计算表示在切取区域34中包含预定对象物的可能性的识别得分。图像检索部24通过使用了识别词典数据的图像识别处理来计算识别得分。图像检索部24读取识别词典数据以生成模型,将切取区域34的图像数据输入到模型中,并且使模型输出所输入的切取区域34的识别得分。图像检索部24如箭头s所示的那样一边在切取区域34错开位置一边将切取区域34的图像数据依次输入到模型中,从而遍布转换图像32的整个区域来计算识别得分。
43.切取区域34的形状和尺寸根据识别词典数据的种类来确定。例如,在行人用的识别词典数据的情况下,确定为切取区域34是长方形、切取区域34的纵向和横向的图像尺寸的比率a∶b设定为约2∶1。在用于骑车人或用于汽车时,切取区域34的纵向和横向的图像尺寸的比率a∶b也可以是不同于行人用的值。切取区域34的纵向和横向的图像尺寸对于每个识别词典数据设定固定值。切取区域34的图像尺寸例如与在用于生成识别词典数据的机器
学习中使用的学习用图像的图像尺寸一致。
44.图像检索部24针对图像尺寸不同的多个转换图像32,切取针对每个识别词典数据设定的预定尺寸a
×
b的切取区域34来执行图像检索处理。图7的(a)是示意性地示出转换图像32中的切取区域34的图像尺寸a
×
b的图。在图7的(a)的示例中,将包含图2的行人30a的区域作为切取区域34。由于转换图像32是通过以预定转换倍率ki放大或缩小原始拍摄图像30而获得的图像,因此当以原始拍摄图像30为基准时作为检索对象的区域的尺寸是通过以转换倍率的倒数1/ki缩小或放大切取区域34而获得的尺寸。图7的(b)是示意性地示出拍摄图像30中的检索区域36的图像尺寸的图。如图所示,以拍摄图像30为基准时的检索区域36的图像尺寸为(a/ki)
×
(b/ki),是将切取区域34的尺寸a
×
b除以转换倍率ki而得到的值。其结果,通过对具有不同图像尺寸的多个转换图像32执行具有预定尺寸a
×
b的切取区域34的图像检索,可以在改变拍摄图像30中的检索区域36的图像尺寸的同时执行图像检索。由此,能够检索尺寸不同对象物。
45.在本实施方式中,针对相同类型的对象物准备多个识别词典数据,并且切取区域34的图像尺寸按每个识别词典数据是不同的。例如,在行人用的第一识别词典数据中,将切取区域34的图像尺寸设定得相对小,在行人用的第二识别词典数据中,将切取区域34的图像尺寸设定得相对大。例如,行人用的第一识别词典数据的切取区域34的图像尺寸是80
×
40(a=80像素,b=40像素),行人用的第二识别词典数据的切取区域34的图像尺寸是160
×
80(a=160像素,b=80像素)。第一识别词典数据用于识别低分辨率的对象物图像,是主要用于检测位于远处的对象物的远处用数据。另一方面,第二识别词典数据用于识别高分辨率的对象物图像,是主要用于检测位于附近的对象物的附近用数据。
46.图像检索部24针对图像尺寸不同的多个转换图像32的每一个,使用一个以上的识别词典数据执行图像检索处理。图像检索部24针对多个转换图像32的每一个,使用第一识别词典数据和第二识别词典数据的至少一个来执行图像检索处理。图像检索部24根据以拍摄图像30为基准时的检索区域36的图像尺寸是否为预定阈值以上,区分使用第一识别词典数据和第二识别词典数据。具体而言,在检索区域36的图像尺寸小于阈值的情况下,使用低分辨率用的第一识别词典数据。另一方面,在检索区域36的图像尺寸为阈值以上的情况下,使用高分辨率用的第二识别词典数据。
47.成为阈值的图像尺寸能够根据第一识别词典数据和第二识别词典数据的切取区域34的图像尺寸来决定。成为阈值的图像尺寸例如可以设定为第一识别词典数据的切取区域34的图像尺寸(例如80
×
40)的4倍以下(320
×
160以下)或3倍以下(240
×
120以下)。成为阈值的图像尺寸例如可以设定为第二识别词典数据的切取区域34的图像尺寸以上(例如160
×
80以上)。作为阈值的图像尺寸的一例是200
×
100。
48.图8是示出图像检索处理的检索条件的一例的表,对于多个检索条件1~26,示出了所使用的识别词典数据、所使用的转换图像32的编号i、转换图像32的转换倍率ki以及检索区域36的纵向的图像尺寸(检索尺寸)。检索条件1~19使用低分辨率用的第一识别词典数据。由于第一识别词典数据的切取区域34的纵向的图像尺寸是80像素,所以在检索条件1~19中以拍摄图像30为基准的检索区域36的纵向的图像尺寸是80/ki。检索条件1的检索尺寸为27像素,检索条件19的检索尺寸为199像素。这样,在使用第一识别词典数据的检索条件1~19中,检索区域36的检索尺寸小于阈值(200像素)。
49.图8的检索条件20~26使用高分辨率用的第二识别词典数据。由于第二识别词典数据的切取区域34的纵向的图像尺寸是160像素,所以在检索条件20~26中以拍摄图像30为基准的检索区域36的纵向的图像尺寸是160/ki。检索条件20的检索尺寸是203像素,并且检索条件26的检索尺寸是397像素。这样,在使用第二识别词典数据的检索条件20~26中,检索区域36的检索尺寸为阈值(200像素)以上。
50.图8的检索条件1~26也可以根据转换图像32的编号i(或转换倍率ki)进行分类。在转换图像32的编号i=1~12的情况下,即,在转换倍率ki为预定阈值(例如0.8)以上的情况下,仅使用低分辨率用的第一识别词典数据执行图像检索处理。另一方面,在转换图像32的编号i=13~19的情况下,即,在转换倍率ki小于预定阈值(例如0.8)的情况下,使用低分辨率用的第一识别词典数据和高分辨率用的第二识别词典数据双方来执行图像检索处理。
51.图像检索部24基于检索条件1~26所示的各个条件,执行图像检索处理。通过对拍摄图像30执行基于全部检索条件1~26的图像检索处理,能够检测出各种尺寸的对象物。此外,通过组合使用切取区域34的尺寸不同的多个识别词典数据,能够提高对象物的检测精度。假设,在仅使用第一识别词典数据的情况下,在将检索区域36的尺寸设为阈值以上时,必须将拍摄图像30过度(例如小于1/3或小于1/4)地缩小而在失去特征量的状态下进行图像检索,因此识别精度降低。同样,在仅使用第二识别词典数据的情况下,在将检索区域36的尺寸设为小于阈值时,必须以将拍摄图像30过度(例如超过3倍或超过4倍)放大后的粗略图像进行图像检索,因此识别精度降低。根据本实施方式,通过组合多个识别词典数据,能够限缩将拍摄图像30放大或缩小的转换倍率ki的范围。在图8的示例中,能够将转换倍率ki设在1/3倍以上且3倍以下的范围内。其结果,能够防止因过度放大或缩小拍摄图像30而导致的识别精度的降低。
52.图9是示出实施方式涉及的图像识别方法的流程的流程图。当获取拍摄图像30时(s10),初始化检索条件(s12)。如果在检索条件中预定检索尺寸小于阈值(s14的“是”),则通过使用第一识别词典数据的图像检索来计算识别得分(s16)。另一方面,如果检索尺寸为阈值以上(s14的“否”),则通过使用第二识别词典数据的图像检索来计算识别得分(s18)。如果图像检索没有结束(s20的“否”),则更新检索条件(s22),重复s14~s18的处理。如果图像检索结束(s20的“是”),则基于计算出的识别得分检测对象物(s24)。
53.接着,对识别词典数据的生成方法进行说明。在本实施方式中,针对相同类型的对象物生成多个识别词典数据。例如,作为行人用的识别词典数据,生成低分辨率用(远处用)的第一识别词典数据和高分辨率用(附近用)的第二识别词典数据。多个识别词典数据可以通过使要输入到用于机器学习的模型中的学习用图像的图像尺寸彼此不同来生成。例如,在生成第一识别词典数据的情况下,将具有小于预定值的图像尺寸的学习用图像用作输入。另一方面,在生成第二识别词典数据的情况下,将具有预定值以上的图像尺寸的学习用图像用作输入。这里,作为基准的“预定值”的图像尺寸是第二识别词典数据的切取区域34的图像尺寸,例如是160
×
80。
54.用于机器学习的模型可以包括与输入图像的图像尺寸(像素数)对应的输入、输出识别得分的输出、以及连接输入和输出间的中间层。中间层可以包括卷积层、池化(pooling)层、全连接层等。中间层可以是多层结构,也可以构成为能够执行所谓的深度学习。用于机器学习的模型可以使用卷积神经网络(cnn)来构建。另外,用于机器学习的模型
不限于上述模型,也可以使用任何机器学习模型。
55.用于机器学习中的模型在硬件上可以通过以计算机的cpu和存储器为首的元件和机械装置来实现,在软件上通过计算机程序等来实现,但在此,将其描绘为通过它们的协作来实现的功能块。因此,本领域技术人员应当理解,这些功能块可以通过硬件、软件的组合以各种形式实现。
56.图10的(a)~(d)是示出学习用图像的示例的图,示出用于生成行人用的识别词典数据的学习用图像的示例。图10的(a)、(b)示出用于生成第一识别词典数据的学习用图像41~46,图10的(c)、(d)示出用于生成第二识别词典数据的学习用图像51~56。如图所示,第一识别词典数据用的学习用图像41~46的图像尺寸相对小,相对地是低分辨率。第一识别词典数据用的学习用图像41~46的图像尺寸的一例是80
×
40。另一方面,第二识别词典数据用的学习用图像51~56的图像尺寸相对大,相对地是高分辨率。第二识别词典数据用的学习用图像51~56的图像尺寸的一例是160
×
80。
57.作为学习用图像,可以使用由与图1的相机26相同的相机拍摄的图像,并且可以使用切取拍摄图像的一部分区域而获得的图像。学习用图像可以是切取拍摄图像的一部分区域而获得的图像本身,也可以是通过将切取了拍摄图像的一部分区域的原始图像的图像尺寸进行转换而获得的图像。学习用图像也可以是通过将切取了拍摄图像的一部分区域的原始图像缩小到适合于模型的输入图像尺寸而获得的图像。用于生成第一识别词典数据的第一模型的输入图像尺寸例如是80
×
40,用于生成第二识别词典数据的第二模型的输入图像尺寸例如是160
×
80。另外,作为学习用图像,优选不使用将切取了拍摄图像的一部分区域的原始图像放大后的图像。即,作为原始图像,优选不使用比模型的输入图像尺寸小的图像尺寸的图像。当原始图像的图像尺寸小于模型的输入图像尺寸时,机器学习的精度可能降低。
58.在生成识别词典数据的机器学习中,可以使用将正确图像和非正确图像输入到模型中的有监督学习。图10的(a)的学习用图像41、42、43是第一识别词典数据用的正解图像,包含成为识别对象的行人。在正确图像中包含向前的行人、横向的行人、向后的行人等各种行人。在将正确图像输入到模型的情况下,执行学习,使得从模型输出的识别得分变大(例如接近1)。
59.图10的(b)的学习用图像44、45、46是第一识别词典数据用的非正确图像,虽然不是行人,但包含容易误认为是行人的对象物。在非正确图像中包含纵向长的建筑物等,包含铁塔、电线杆、路灯等。在将非正确图像输入到模型的情况下,执行学习,使得从模型输出的识别得分变小(例如接近0)。
60.第二识别词典数据的学习也同样,可以使用将图10的(c)的正解图像51、52、53以及图10的(d)的非正解图像54、55、56输入到模型中的有监督学习。另外,可以通过仅使用正确图像的机器学习来生成识别词典数据,也可以通过无监督学习来生成识别词典数据。
61.图11是示出实施方式涉及的识别词典生成方法的流程的流程图。获取学习用图像(s30),如果学习用图像的图像尺寸小于预定值(s32中的“是”),则将学习用图像输入到第一模型中以执行机器学习(s34)。如果学习用图像的图像尺寸为预定值以上(s32中的“否”),则将学习用图像输入到第二模型中以执行机器学习(s36)。在步骤s34和s36中,在学习用图像的图像尺寸与要输入到第一模型或第二模型的图像尺寸不一致的情况下,可以在
转换(例如,缩小)学习用图像的图像尺寸之后将其输入到模型。重复s30至s36的处理,直到第一模型和第二模型的机器学习结束(s38中的“否”)。在机器学习结束的情况下(s38中的“是”),从第一模型生成第一识别词典数据(s40),从第二模型生成第二识别词典数据(s42)。第一识别词典数据例如包含用于构建已学习的第一模型的各种参数。第二识别词典数据例如包含用于构建已学习的第二模型的各种参数。
62.根据本实施方式,可以根据学习用图像的图像尺寸生成多个识别词典数据。具体而言,能够将低分辨率的学习用图像作为输入来生成第一识别词典数据,将高分辨率的学习用图像作为输入来生成第二识别词典数据。其结果,能够准备专用于低分辨率的图像识别的第一识别词典数据和专用于高分辨率的图像识别的第二识别词典数据,能够提高识别各种图像尺寸的对象物的精度。
63.以上,参照上述实施方式对本发明进行了说明,但本发明并不限定于上述实施方式,将实施方式所示的各结构适当组合或置换后的结构也包含在本发明中。
64.在上述实施方式中,作为行人用的识别词典数据,示出了使用低分辨率用的第一识别词典数据和高分辨率用的第二识别词典数据的情况。在其他实施方式中,针对与行人不同类型的对象物(骑车人、车辆、动物等)可以使用多个识别词典数据。此外,也可以针对第一类型的对象物(例如行人或骑车人)使用多个识别词典数据,另一方面,针对第二类型的对象物(例如车辆或动物)仅使用单一的识别词典数据。
65.在上述实施方式中,说明了从拍摄图像30生成转换图像32,并提取作为转换图像32的一部分区域的切取区域34来执行图像检索处理的情况。在其他实施方式中,也可以提取作为拍摄图像30的一部分区域的检索区域36,并将检索区域36的图像尺寸转换为识别词典数据的输入图像尺寸来执行图像检索处理。在这种情况下,也可以通过根据图8的检索条件1~26改变检索区域36的图像尺寸来识别具有各种图像尺寸的对象物。识别处理部14也可以在执行提取拍摄图像30的一部分区域的处理之后,根据所设的转换倍率ki转换一部分区域的图像尺寸。
66.在上述实施方式中,示出了作为相同类型的对象物用的多个识别词典数据使用两个识别词典数据的情况。在其他实施方式中,也可以使用三个以上的识别词典数据用于相同类型的对象物。例如,作为行人用的识别词典数据也可以使用低分辨率用、中分辨率用、高分辨率用的三个识别词典数据。在这种情况下,在拍摄图像30的检索区域36的图像尺寸成为第一范围的情况下可以使用低分辨率用的第一识别词典数据,在拍摄图像30的检索区域36的图像尺寸成为比第一范围大的第二范围的情况下可以使用中分辨率用的第二识别词典数据,在拍摄图像30的检索区域的图像尺寸成为比第二范围大的第三范围的情况下可以使用高分辨率用的第三识别词典数据。
67.在其他实施方式中,作为相同类型的对象物用的识别词典数据,也可以组合使用多个第一识别词典数据和多个第二识别词典数据。多个第一识别词典数据分别构成为切取区域34的图像尺寸稍有不同。例如,也可以使用切取区域34的图像尺寸为80
×
40、84
×
42以及88
×
44的三个第一识别词典数据。多个第一识别词典数据的切取区域34的图像尺寸之差约为5%,比第一识别词典数据与第二识别词典数据的切取区域34的图像尺寸之差(100%)小。这样,通过使用图像尺寸稍有不同的多个第一识别词典数据,能够提高图像识别的精度。同样地,也可以使用切取区域34的图像尺寸为160
×
80、168
×
84以及196
×
88的三个第
二识别词典数据。在这种情况下,作为阈值的图像尺寸也可以设为多个第一识别词典数据的切取区域34的图像尺寸的最小值(例如80
×
40)的4倍以下(320
×
160以下)或3倍以下(240
×
120以下)。此外,作为阈值的图像尺寸也可以设为多个第二识别词典数据的切取区域34的图像尺寸的最小值以上(例如160
×
80以上)。作为阈值的图像尺寸的一例是200
×
100。
68.在上述实施方式中,示出了对多个转换图像32的全部(例如i=1~19)执行使用了第一识别词典数据的图像检索处理并对多个转换图像32的一部分(例如i=13~19)执行使用了第二识别词典数据的图像检索处理的情况。在其他实施方式中,也可以对多个转换图像32的一部分(例如i=1~17)执行使用了第一识别词典数据的图像检索处理,并对多个转换图像32的另外一部分(例如i=11~19)执行使用了第二识别词典数据的图像检索处理。例如,是将作为上述阈值的图像尺寸设为160
×
80的情况。在这种情况下,也可以存在仅使用第一识别词典数据进行图像检索的转换图像32(i=1~10)、使用第一识别词典数据和第二识别词典数据两者进行图像检索的转换图像32(i=11~17)、仅使用第二识别词典数据进行图像检索的转换图像32(i=18~19)。
69.在上述实施方式中,示出了将图像识别装置10搭载在车辆上的情况。在其他实施方式中,图像识别装置10的设置场所没有特别限定,可以用于任意的用途。
70.产业上的可用性
71.根据本发明,能够在基于识别词典的图像识别处理中提高对象物的检测精度。
72.符号说明
73.10
……
图像识别装置、12
……
图像获取部、14
……
识别处理部、16
……
判定处理部、18
……
输出部、20
……
识别词典存储部、22
……
图像转换部、24
……
图像检索部、30
……
拍摄图像、32
……
转换图像、34
……
切取区域、36
……
检索区域。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1