用于自然语言处理的域外数据扩充的制作方法
本公开总体上涉及聊天机器人系统,并且更具体地涉及用于在自然语言处理中针对训练聊天机器人系统进行域外数据扩充的技术。
背景技术:
1、为了获得即时反应,世界各地的许多用户使用即时消息传递或聊天平台。组织经常使用这些即时消息传递或聊天平台与客户(或最终用户)进行实时会话。然而,雇用服务人员与客户或最终用户进行实时交流对于组织来说可能是非常昂贵的。已经开始开发聊天机器人或机器人来模拟与最终用户的会话,尤其是通过因特网。最终用户可以通过最终用户已经安装并使用的消息传递应用程序与机器人交流。智能机器人(通常通过人工智能(ai)提供动力)可以在实时会话中更智能地且根据上下文进行交流,并且因此可以允许机器人与最终用户之间更加自然的会话以改善会话体验。不是最终用户学习机器人知道的如何作出响应的固定的一组关键词或命令,而是智能机器人可以能够基于自然语言的用户话语理解最终用户的意图并且相应地作出响应。
2、然而,很难构建聊天机器人,因为这些自动化解决方案需要某些领域中的特定知识和可能只在专业开发人员的能力范围内的某些技术的应用。作为构建这种聊天机器人的一部分,开发人员可以首先了解企业和最终用户的需求。开发人员然后可以分析并作出与例如以下各项有关的决策:选择要用于分析的数据集;准备用于分析的输入数据集(例如,在分析之前清理数据、提取、格式化和/或变换数据、执行数据特征工程等);识别用于执行分析的适当的一种或多种机器学习(ml)技术或一种或多个ml模型;以及改善技术或模型以基于反馈改善结果/效果。识别适当的模型的任务可以包括:在识别特定的模型(或多个模型)以供使用之前,开发多个模型(可能并行地)、迭代地利用这些模型进行测试和实验。进一步地,基于监督式学习的解决方案通常涉及训练阶段、随后是应用(即,推理)阶段和介于训练阶段与应用阶段之间的迭代循环。开发人员可以负责仔细地实施并监测这些阶段,以实现最佳解决方案。例如,为了训练一种或多种ml技术或一个或多个模型,需要精确的训练数据以使算法能够理解和学习某些模式或特征(例如,对于聊天机器人——需要意图提取和仔细的句法分析,而不仅仅是原始语言处理),该一种或多种ml技术或一个或多个模型将使用这些模式或特征来预测期望的结果(例如,从话语中推断出意图)。为了确保一种或多种ml技术或一个或多个模型正确学习这些模式和特征,开发人员可以负责针对该一种或多种ml技术或一个或多个模型来选择、丰富和优化训练数据集。
技术实现思路
1、本文所公开的技术总体上涉及聊天机器人。更具体且非限制性地,本文公开的技术涉及用于在自然语言处理中训练聊天机器人系统的训练数据集的关键词数据扩充的技术。聊天机器人可以将用户话语分类为不同的分类,如用户的预定义意图。聊天机器人的分类器可以包括经训练的ml模型,该ml模型基于输入(例如,用户话语)生成输出(例如,意图)。用户话语可以采取语音的形式。在这种情况下,经训练的ml模型可以被理解为实施改进的语音识别,其中,语音识别允许更准确地识别用户意图。当用于训练经训练的ml模型的训练数据不足时,聊天机器人可能会更频繁地确定错误的意图。本文公开的技术可以提供用于训练ml模型的关键词扩充的数据集,使得ml模型对无关的上下文更具弹性并且更准确地学习意图的模式或边界。
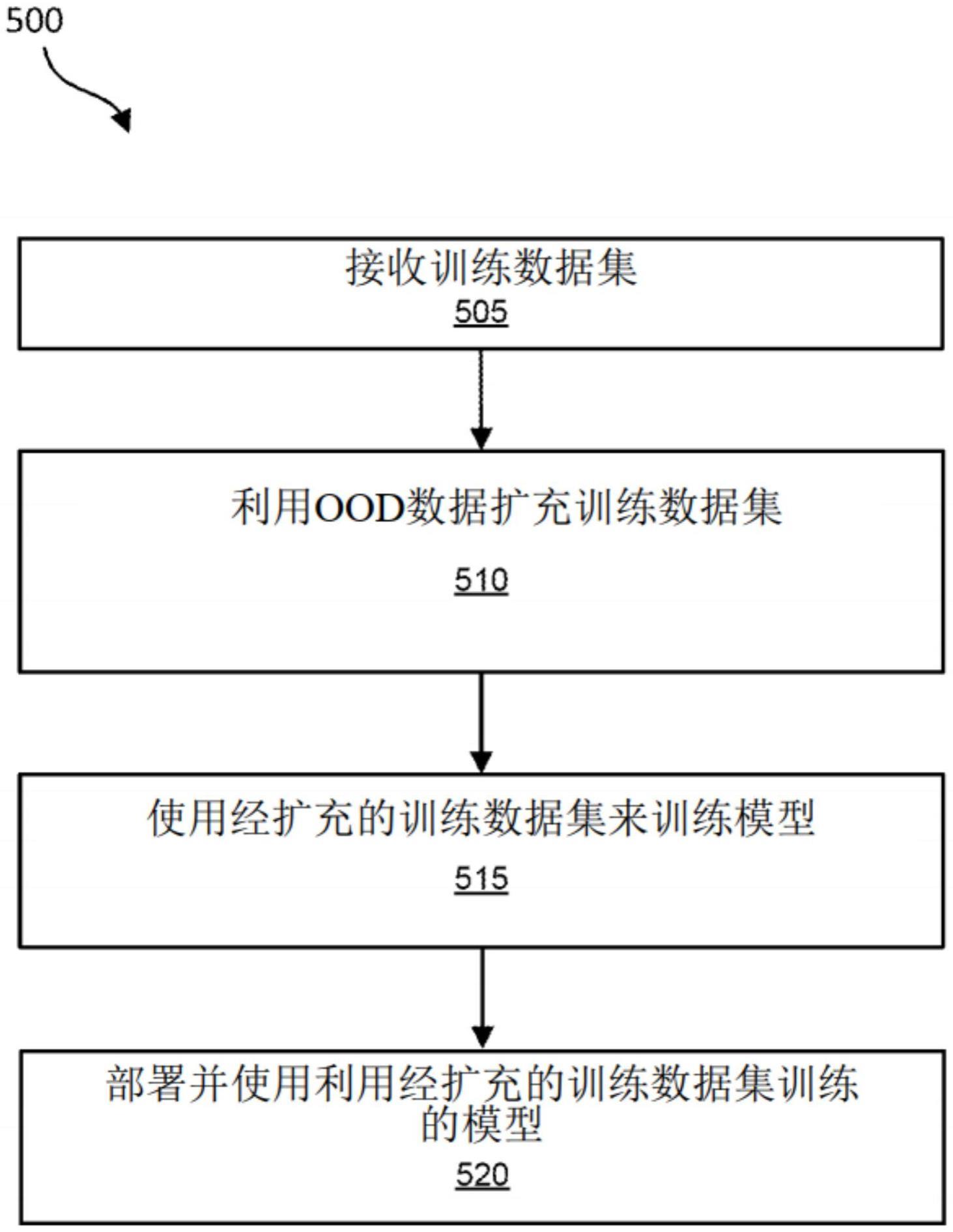
2、在各种实施例中,提供了一种计算机实施的方法,该计算机实施的方法包括:在数据处理系统处接收训练话语集,该训练话语集用于训练机器学习模型以识别一个或多个话语的一个或多个意图;由数据处理系统利用域外(ood)示例来扩充该训练话语集,其中,扩充包括:生成ood示例数据集,从该ood示例数据集中过滤掉具有与该训练话语集中的话语的上下文基本相似的上下文的ood示例,确定保留在过滤后的ood示例数据集内的每个ood示例的难度值,以及基于每个ood的难度值生成经扩充的话语批,该经扩充的话语批包括来自训练话语集的话语和来自过滤后的ood数据集的话语;以及由数据处理系统使用该经扩充的话语批来训练该机器学习模型,其中,训练包括基于该经扩充的话语批中的每一批内的ood示例的难度值将该经扩充的话语批馈送到机器学习模型。
3、在一些实施例中,基于距离测量来确定ood示例的上下文与训练话语集中的话语的上下文之间的基本相似性,以避免分类之间的冲突。
4、在一些实施例中,ood示例的上下文与训练话语集中的话语的上下文之间的基本相似性是使用多语言通用句子编码器(muse)单嵌入来确定的,并且其中,如果min(d_i)<预定阈值(其中,d_i=欧几里德距离(v_i,u)),则ood示例的上下文和训练话语集中的话语的上下文被确定为基本相似。
5、在一些实施例中,从d_i值得到难度值,使得简单的ood示例将具有高d_i值,而困难的ood示例将具有更接近预定阈值的较低d_i值。
6、在一些实施例中,该经扩充的话语批是基于以下约束生成的:(i)预定的批大小,(ii)在每一批内并入来自训练话语集的预定数量的域内话语示例,(iii)在每一批内并入来自过滤后的ood数据集的预定数量的ood话语示例,(iv)选择该预定数量的域内示例和该预定数量的ood话语示例以保持该预定的批大小,(v)并入每一批中的ood话语示例具有基本相似的难度值,以及可选地,(vi)来自过滤后的ood数据集的每个odd示例仅被并入该经扩充的话语批中的单个批中。
7、在一些实施例中,该方法进一步包括在聊天机器人系统中部署经训练的机器学习模型。
8、在一些实施例中,该经扩充的话语批是使用批平衡方案生成的。
9、在各种实施例中,提供了一种计算机实施的方法,该计算机实施的方法包括:由聊天机器人系统接收由与聊天机器人系统交互的用户生成的话语;使用部署在聊天机器人系统内的意图分类器来将该话语分类为与某意图相对应的意图类别,其中,意图分类器包括使用训练数据识别的多个模型参数,该训练数据包括:用于训练意图分类器以识别一个或多个话语的一个或多个意图的经扩充的训练话语集,其中,该经扩充的训练话语集被人工生成以包括来自训练话语集中的经扩充的话语,其中,经扩充的话语是具有与训练话语集中的话语的上下文显著不同的上下文的ood话语,其中,ood示例的上下文与训练话语集中的话语的上下文之间的显著不同是使用多语言通用句子编码器(muse)单嵌入来确定的,其中,如果min(d_i)=>预定阈值(其中,d_i=欧几里德距离(v_i,u)),则ood示例的上下文和训练话语集中的话语的上下文被确定为显著不同,并且其中,基于使成本函数最小化使用训练数据来识别该多个模型参数;以及使用意图分类器基于分类来输出意图。
10、在各种实施例中,提供了一种系统,该系统包括一个或多个数据处理器和包含指令的非暂态计算机可读存储介质,该指令在所述一个或多个数据处理器上执行时使该一个或多个数据处理器执行本文所公开的一种或多种方法的部分或全部。
11、在各种实施例中,提供了一种计算机程序产品,该计算机程序产品有形地体现在非暂态机器可读存储介质中并且包括被配置为使一个或多个数据处理器执行本文所公开的一种或多种方法的部分或全部的指令。
12、可以用多种方式并且在多种上下文中实施上文和下文所描述的技术。如下文更详细地描述的,参考以下附图提供了多种示例实施方式和上下文。然而,以下实施方式和上下文仅是许多实施方式和上下文中的一些。
- 还没有人留言评论。精彩留言会获得点赞!