音频数据转录训练学习算法标识图像数据中可见医疗设备的制作方法
本发明涉及一种训练学习算法来确定医疗设备身份的计算机实施方法和通过使用训练过的学习算法来确定医疗设备身份的计算机实施方法、一种相应的计算机程序、存储此程序的计算机可读存储介质和执行此程序的计算机以及一种包括电子数据存储设备和上述计算机的医疗系统。
背景技术:
1、在手术室中,光学器械识别与跟踪是一种用于计算机辅助手术的技术。借助机器学习,可以自动化器械标识过程,用于进行情境手术器械托盘跟踪。适当的数据预处理可以实现泛化灵活的可能用途。
2、迄今为止,
3、-一旦用户拿起器械,必须手动输入器械类型;
4、-可以通过用于跟踪的光学标记的类型来标识器械类型;
5、-可以通过确定器械形状并与器械形状数据库进行比较来标识器械类型;
6、-可以通过读取专用标记图案(例如条形码或qr码)并与存储标记/器械身份的数据库进行比较来标识器械类型;或
7、-可以根据可明确分配的音频信号(例如语音识别、关键词识别)来标识器械类型。
8、但这关系到以下局限性:
9、-一旦拿起器械后必须进行的手动输入步骤会阻碍无缝工作流程。
10、-所有现有方法都需要器械形状或专用标记图案的预定义数据库;这些数据库的存在并不一致,也不允许情境动作。
11、-纯语音控制的通用性不足使系统在各种情境下工作。
12、-手动医疗设备监控容易出错。
技术实现思路
1、本发明目的是提供一种改进的器械标识和/或监控手段。
2、本发明可用于例如有关图像指导手术或视频路由系统(如和brainlab ag的所有产品)的流程。
3、下文公开了本发明各方面、示例和示例性步骤及其实施例。根据本发明可组合本发明不同示例性特征,只要技术上适宜可行即可。
4、发明示例简述
5、下文对本发明具体特征予以简要描述,不应理解为本发明仅限于本部分中描述的特征或特征组合。
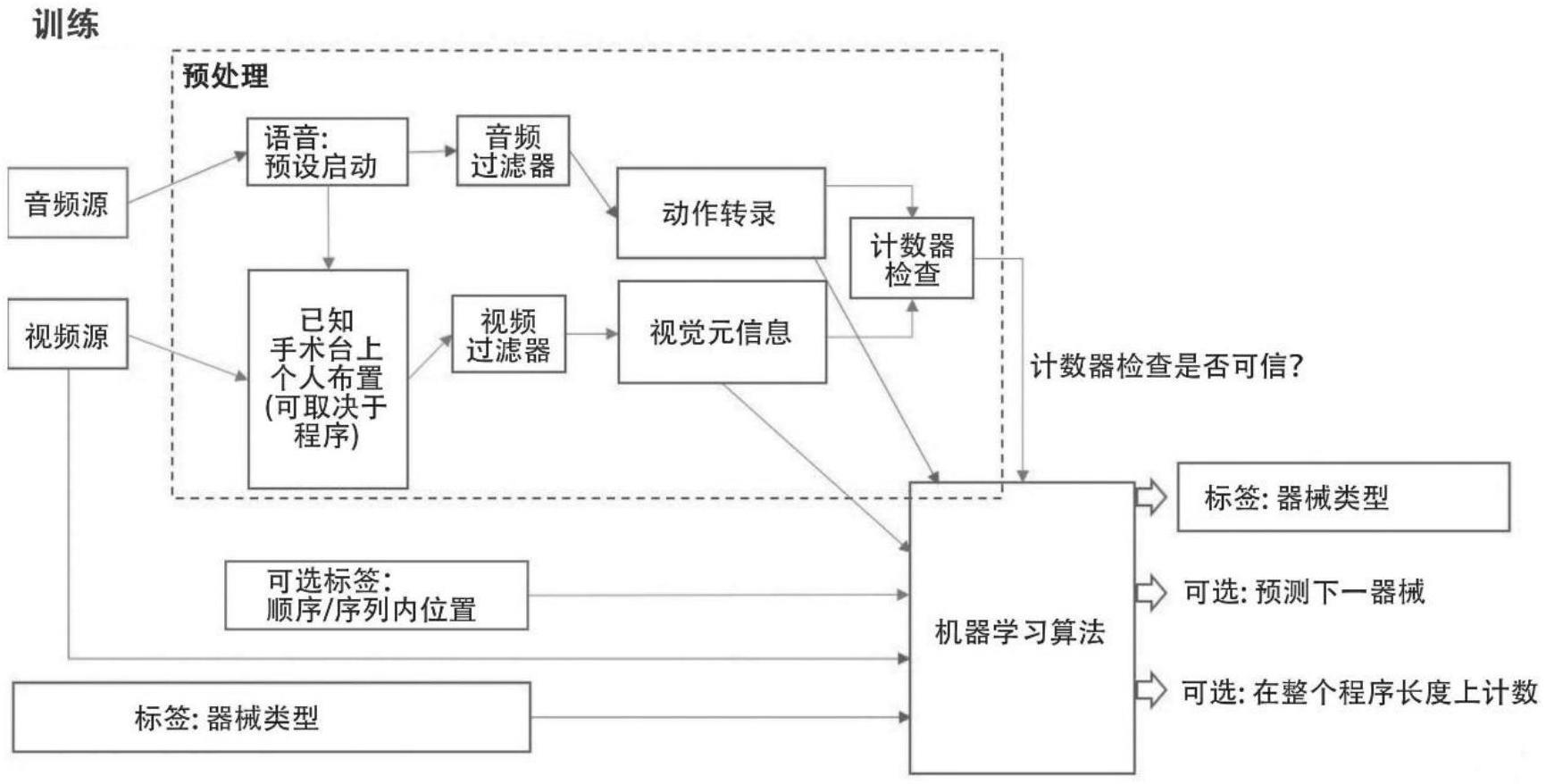
6、本公开方法包括基于音频数据和图像数据训练学习算法,其中音频数据和图像数据经预处理生成音频信息和图像信息的时间同步转录,以允许学习算法标识图像数据中可见的医疗设备,如医疗仪器或器械台上医疗器械,向用户输出相应信息。本公开实施例包括额外预测下一个待用器械以及计数已用器械。本公开方法还包括使用训练算法来标识医疗设备。
7、
技术实现要素:
概述
8、本发明内容中,例如通过参照本发明可行实施例对本发明一般特征予以描述。
9、一般而言,为了实现上述目的,第一方面,本发明提出一种训练学习算法来确定医疗设备身份的计算机实现医疗方法。上述方法包括在至少一台计算机(例如,至少一台计算机作为导航系统的一部分)的至少一个处理器上执行以下由至少一个处理器执行的示例性步骤。
10、(例如第一)示例性步骤中,获取训练音频数据,该训练音频数据描述音频标识符,该音频标识符描述医疗设备身份。医疗设备例如是医疗器械或在医疗环境下使用的任何其他设备。
11、(例如第二)示例性步骤中,获取训练图像数据,训练图像数据描述一系列时间上连续的数字图像,这些数字图像包括描述医疗设备身份的视觉标识符。
12、(例如第三)示例性步骤中,基于训练音频数据确定训练音频元数据,该训练音频元数据描述音频标识符的训练转录。例如,训练转录包括以下至少一种关于语音信号的信息,例如检测到语音信号的信息、语音信号、字符串变量、关于语音信号声源方向的信息、关于语音信号发声人的信息。
13、(例如第四)示例性步骤中,获取设备标签数据,设备标签数据描述与音频标识符和视觉标识符中至少一项相关联的标签,该标签描述医疗设备身份。
14、(例如第五)示例性步骤中,确定标签身份数据,该标签身份数据描述用于建立视觉标识符、音频标识符和标签之间关系的学习算法的模型参数,其中通过将训练音频元数据和设备标签数据输入关系建立函数来确定标签身份数据。例如,标签身份数据描述指示医疗设备使用的计数器。
15、某一示例中,根据第一方面方法包括以下步骤:获取训练视觉元数据,该训练视觉元数据描述每个数字图像中医疗设备的使用状态。例如,通过将训练视觉元数据输入关系建立函数来确定标签身份数据。
16、根据第一方面方法的示例中,基于训练图像数据确定训练视觉元数据,其中训练转录和视觉标识符在时间上同步,并且训练转录与视觉标识符相关联,其中通过将训练视觉元数据输入关系建立函数来确定标签身份数据。
17、根据第一方面方法的示例中,获取医疗设备顺序数据,该医疗设备顺序数据描述多个医疗设备的预定使用顺序。然后,基于医疗设备顺序数据确定标签身份数据。因此,可以根据医疗设备在多个医疗设备使用中的使用顺序来标识该医疗设备。例如,标签身份数据则描述其他待用医疗设备的预测。设备身份数据则描述其他待用医疗设备。
18、第二方面,本发明涉及一种确定视觉标识符、音频标识符和标签之间关系的计算机实施方法,视觉标识符、音频标识符和标签标识医疗设备。上述方法包括在至少一台计算机(例如,至少一台计算机作为导航系统的一部分)的至少一个处理器上执行以下由至少一个处理器执行的示例性步骤。
19、(例如第一)示例性步骤中,获取音频数据,该音频数据描述音频标识符。
20、(例如第二)示例性步骤中,获取图像数据,该图像数据描述一系列时间上连续的数字图像,这些数字图像包括视觉标识符。
21、(例如第三)示例性步骤中,基于音频数据确定音频元数据,该音频元数据描述音频标识符的转录,其中转录和图像数据在时间上同步,并且音频标识符与视觉标识符相关联。
22、(例如第四)示例性步骤中,确定设备身份数据,该设备身份数据描述视觉标识符和音频标识符之间关系,其中通过将音频元数据输入关系建立函数来确定设备身份数据,该函数作为通过执行根据上述第一方面和下述第一至第十示例的方法训练过的学习算法的一部分。
23、如果根据第一方面方法包括通过将训练视觉元数据输入关系建立函数来训练学习算法,则根据第二方面方法例如包括以下步骤:基于图像数据确定视觉元数据,该视觉元数据描述每个数字图像中医疗设备的使用状态。然后,通过将视觉元数据输入关系建立函数来确定设备身份数据。
24、根据第一方面和第二方面方法的第一示例中,数字图像为静态图像或视频图像。
25、根据第一方面和第二方面方法的第二示例中,音频标识符包括或是语音信号,例如人声信号。
26、根据第一方面和第二方面方法的第三示例中,语音信号是人声信号,并且转录和/或训练转录是通过以下至少一步生成:语言翻译语音信号描述的词语,滤除语音信号描述的关键词,滤除语音信号描述的患者标识符,滤除语音信号描述的健康信息,消除语音信号中包括的噪声,确定语音信号描述关键词的预定组合。
27、根据第一方面和第二方面方法的第四示例中,视觉标识符是数字图像中医疗设备的图像呈现。因此,通过至少一个数字图像中医疗设备的外观来标识该医疗设备。
28、根据第一方面和第二方面方法的第五示例中,转录包括以下至少一种关于语音信号的信息,例如检测到语音信号的信息、语音信号、字符串变量、关于语音信号声源方向的信息、关于语音信号发声人的信息。
29、根据第一方面和第二方面方法的第六示例中,至少一个数字图像包括医疗设备和用于支撑医疗设备的设备支撑单元(例如手术台)的图像呈现,根据第一和第二方面方法然后包括基于将至少一个数字图像中医疗设备和设备支撑单元之间的相对位置与医疗设备和设备支撑单元之间的预定相对位置进行比较来确定图像标识符。
30、根据第一方面和第二方面方法的第七示例中,通过以下至少一项定义使用状态:
31、·医疗设备清洁状态;
32、·数字图像中呈现的用户手部的手部移动;
33、·至少一个数字图像中呈现的用户手部和至少一个数字图像中呈现的医疗设备之间的相对位置;
34、·至少一个数字图像中医疗设备的身份编码信息的呈现与至少一个数字图像中医疗设备的呈现之间的相对位置,其中身份编码信息例如是非解剖信息(例如qr码或条形码);
35、·医疗设备的几何形状,例如其预定维度上(如长度、直径或厚度)的大小。
36、根据第一方面和第二方面方法的第八示例中,进行检查来基于预定统计信息确定训练转录是否与视觉标识符描述相同的医疗设备。
37、根据第一方面和第二方面方法的第九示例中,学习算法包括机器学习算法或由机器学习算法组成,例如卷积神经网络。
38、根据第一方面和第二方面方法的第十示例中,模型参数定义学习算法的可学习参数,例如权重。
39、根据第二方面方法的示例中,获取音频确认数据,该音频确认数据描述指示医疗设备身份的人声信号。然后基于音频确认数据确定设备身份数据。这允许通过用户发出的语音信号进行音频确认,从而正确标识医疗设备。
40、根据第二方面方法的示例中,如果标签身份数据描述其他待用医疗设备的预测,则设备身份数据描述计数器的值。
41、第三方面,本发明涉及一种包括指令的计算机程序,当至少一台计算机执行程序时,这些指令使得至少一台计算机执行根据第一方面或第二方面的方法。替代地或附加地,本发明可涉及信号波(例如技术手段生成的物理信号波,例如电信号波),例如数字信号波,如携带代表程序(例如上述程序)的信息的电磁载波,所述程序例如包括适于执行根据第一方面或第二方面方法的任何或所有步骤的编码手段。某一示例中,信号波是携带上述计算机程序的数据载波信号。存储在盘上的计算机程序是数据文件,当读取并传输该文件时,该文件变成例如信号(例如技术手段生成的物理信号,例如电信号)形式的数据流。该信号可实施为信号波,例如本文描述的电磁载波。例如,信号(例如信号波)构建为经由计算机网络(例如lan、wlan、wan、移动网络,例如因特网)来传输。例如,信号(例如信号波)构建为通过光学或声学数据传输来传输。因此,根据第三方面,本发明可以替代地或附加地涉及代表上述程序的数据流,即包括程序。
42、第四方面,本发明涉及一种计算机可读存储介质,其上存储有根据第三方面的程序。上述程序存储介质例如为非瞬态程序存储介质。
43、第五方面,本发明涉及一种计算机可读存储介质,其上存储有定义通过执行根据第一方面方法训练过的学习算法的模型参数和架构的数据。上述程序存储介质例如为非瞬态程序存储介质。根据第五方面,本发明还涉及数据载波信号和/或数据流,该数据载波信号携带定义通过执行根据第一方面方法训练过的学习算法的模型参数和架构的数据,该数据流携带定义通过执行根据第一方面方法训练过的学习算法的模型参数和架构的数据。
44、第六方面,本发明涉及至少一台计算机(例如计算机),包括至少一个处理器(例如,处理器),其中由处理器执行根据第三方面的程序,或者至少一台计算机包括根据第四方面的计算机可读存储介质。
45、第七方面,本发明涉及一种用于确定视觉标识符、音频标识符和标签之间关系的系统,视觉标识符、音频标识符和标签标识医疗设备,该系统包括:
46、(a)根据第六方面的至少一台计算机;
47、(b)存储图像数据和音频数据的至少一个电子数据存储设备;以及
48、(c)根据第五方面的程序存储介质,
49、其中,至少一台计算机可操作性耦合到:
50、-至少一个电子数据存储设备,以从至少一个电子数据存储设备获取图像数据和音频数据,并向至少一个电子数据存储设备中存储至少设备身份数据;以及
51、-程序存储介质,以从程序存储介质中获取定义学习算法的模型参数和架构的数据。
52、第八方面,本发明涉及一种用于确定视觉标识符、音频标识符和标签之间关系的医疗系统,视觉标识符、音频标识符和标签标识医疗设备,该医疗系统包括:
53、(a)根据第六方面的至少一台计算机,其中计算机程序包括指令,当至少一台计算机执行程序时,这些指令使得至少一台计算机执行根据第二方面的方法;
54、(b)至少一个电子数据存储设备,其存储有至少定义通过执行根据第一方面方法训练过的学习算法的模型参数和架构的数据以及标签身份数据;以及
55、(c)用于生成图像数据的成像设备,
56、其中,至少一台计算机可操作性耦合到:
57、-至少一个电子数据存储设备,以从至少一个数据存储设备获取至少定义通过执行根据第一方面方法训练过的学习算法的模型参数和架构的数据以及标签身份数据;以及
58、-成像设备,以从成像设备接收图像数据。
59、根据第八方面系统的示例中,成像设备是数码相机,例如数码视频相机或数码静态图像相机。
60、本发明还涉及根据第七方面和第八方面系统用于确定视觉标识符、音频标识符和标签之间关系的用途,视觉标识符、音频标识符和标签标识医疗设备。
61、例如,本发明不涉及或尤其不包括或不包含侵入性步骤,该侵入性步骤代表对身体的实质性物理干扰,需要对身体采取专业医疗措施,而即使采取了必要的专业护理或措施,身体仍可能承受重大健康风险。
62、下文参照图1阐述了卷积神经网络作为与本公开发明结合使用的学习算法的示例。
63、卷积网络(又称为卷积神经网络或cnn)是用于处理公知网格状拓扑结构数据的神经网络的示例。此类示例包含时间序列数据(可视为以规则时间间隔采样的一维栅格)和图像数据(可视为像素的二维或三维栅格)。名称“卷积神经网络”指示该网络采用卷积的数学运算。卷积是线性运算。卷积网络是简单的神经网络,在其至少一层中使用卷积代替一般的矩阵乘法。卷积函数有多种变体,实践中广泛用于神经网络。一般而言,卷积神经网络中使用的运算与其他领域(例如工程学或纯数学)中使用的卷积定义并不精确对应。
64、卷积神经网络的主要组成是人工神经元。图6为描绘单神经元的示例。中间节点代表神经元,该神经元接受所有输入(x1,…,xn),并将输入乘以其特定权重(w1,…,wn)。输入的重要性取决于其权重值。这些计算值相加称为加权和,将插入到激活函数。加权和z定义为:
65、
66、偏置b为与输入无关的值,修改阈值边界。激活函数处理结果值,决定是否将输入传递到下一个神经元。
67、cnn通常取1阶或3阶张量作为其输入,例如,具有h行、w列和3通道(r、g、b色彩通道)的图像。然而,cnn可采取类似方式处理更高阶的张量输入。然后,输入继续经历一系列处理。一个处理步骤常称为一层,可以是卷积层、池化层、归一化层、完全连接层、损失层等。下面各节中描述了这些层的详细信息。
68、
69、上列等式5说明cnn在正向传递中逐层运行的方式。输入为x1,通常是图像(1阶或3阶张量)。将第一层处理中涉及的参数统称为张量wi。第一层的输出x2,也充当第二层处理的输入。此处理继续到完成cnn中所有层的处理为止,输出xl。但添加一层用于反向错误传播的附加层,这是一种在cnn中学习良好参数值的方法。假设当前问题是c类的图像分类问题。常用策略是将xl作为c维向量输出,其第i条目对预测进行编码(x1的后验概率来自于第i类)。为了使xl成为概率质量函数,可以将第(l-1)层中的处理设置为xl-1的softmax变换。其他应用中,输出xl可以具有其他形式和解释。最后一层是损失层。假设t是输入1的对应目标值(基本真值),则可用成本或损失函数来测量cnn预测xl与目标t之间的差异。应当指出,某些层可能没有任何参数,即,对于某些i,wi可能为空。
70、cnn示例中,relu用作卷积层的激活函数,而softmax激活函数提供信息以给出分类输出。下述部分将说明最重点层的意义。
71、将输入图像输入到包括卷积与relu的层的特征学习部分,随后是包括池化的层,随后是卷积与relu层以及池化层的进一步成对重复。将特征学习部分的输出输入到分类部分,其包括针对平坦化、完全连接和最大柔化的层。
72、卷积层中通常使用多个卷积内核。假设使用d个内核,每个内核的空间跨度为h×w,则将所有内核表示为f。f是中的4阶张量。类似地,使用索引变量0≤i<h、0≤j<w、0≤dl<dl和0≤d<d来确定内核中的具体元素。还应指出,内核集f与符号wl指代相同的对象。稍稍更改表示法来简化推导过程。同样清楚的是,即使使用了迷你批处理策略,内核也保持不变。
73、只要卷积核大于1×1,输出的空间幅度就小于输入的空间幅度。有时需要输入和输出图像具有相同的高度和宽度,可以使用简单的填充技巧。
74、对于每个输入通道,如果在第一行上方填充(即插入)行,在最后一行下方填充(即插入)行,在第一列左侧填充列,在最后一列右侧填充列,卷积输出的尺寸将为h1×w1×d,即与输入具有相同的空间幅度。是下限函数。填充的行和列的元素通常设置为0,但也可能是其他值。
75、步幅是卷积中的另一个重要概念。内核在每个可能的空间幅度与输入进行卷积,对应于步幅s=1。然而,如果s>1,内核的每次运动跳过s-1个像素位置(即,在水平和垂直方向上每s个像素执行一次卷积)。
76、本部分中,考虑步幅为1而不用填充的简单情况。因此,在中有y(或xl+1),其中hl+1=hl-h+1,wl+1=wl-w+1,dl+1=d。在精确数学中,卷积过程可表示为等式:
77、
78、对所有0≤d≤d=dl+1,,以及满足0≤il+1<h1-h+1=h1+1,0≤j1+1<w1-w+1=w1+1的任何空间位置(il+1,jl+1)重复等式15。在此等式中,是指由三元组(il+1+i,j1+1+j,d1)索引的x1元素。通常将偏项bd添加到为了清楚起见,该术语不再赘述。
79、池化函数将某一位置的网络输出替换为附近输出的汇总统计数据。例如,最大池化运算报告表格矩形邻域内的最大输出。其他常用的池化函数包含矩形邻域的平均值、矩形邻域的l2范数或者基于到中心像素距离的加权平均值。各种情形下,池化有助于使表示针对输入的小规模平移近似不变。平移不变性意味着若让输入少量平移,池化输出的值也不会改变。
80、由于池化汇总整个邻域的响应,可以通过报告汇总统计数据来汇总间隔k个像素而不是一个像素的区域,从而使用的池化单元与检测器单元相比更少。这会提高网络计算效率,因为下一层要处理的输入约少k倍。
81、假设已经学习cnn模型w1,…,wl-1的全部参数,则可使用该模型准备预测。预测仅涉及正向运行cnn模型,即,沿等式1中箭头方向运行。下面以图像分类问题为例。从输入x1开始,使其经过第一层处理(带有参数w1的框),并获得x2。依次将x2传递到第二层,依此类推。最后,接收到其估计x1的后验概率属于c类。可将cnn预测输出为:
82、
83、此时的问题在于:如何学习模型参数?
84、正如许多其他学习系统中,优化cnn模型的参数以最小化损失z,即,希望cnn模型的预测与基本真值标签相匹配。假设给出一个训练示例x1来训练此类参数。训练过程涉及在两个方向上运行cnn网络。首先在正向传递中运行网络来获得xl,使用当前cnn参数来达成预测。代替输出预测,需要将预测与对应于x1的目标t进行比较,即,继续运行正向传递,直到最后一个损失层为止。最终,获得损失z。损失z则是监督信号,指导应如何修正(更新)模型参数。
85、存在几种用于优化损失函数的算法,cnn不限于特定算法。一种示例算法称为随机梯度下降(sgd)。这种算法是指通过使用来自训练示例的(通常)小子集估算的梯度来更新参数。
86、
87、等式4中,←符号隐式指示(i层)参数wi从时间t更新到t+1。如果显式使用时间索引t,则该等式改写为:
88、
89、等式4中,偏导数衡量z相对于wi在不同维度变化的增长率。这种偏导数向量在数学优化中称为梯度。因此,在wi的当前值附近的小局部区域中,沿由梯度确定的方向移动wi将增加目标值z。为了最小化损失函数,应沿梯度的相反方向更新wi。此更新规则称为梯度下降。
90、然而,如果在负梯度方向上移动得太远,则损失函数可能会增加。因此,在每次更新中,仅通过负梯度(由η(学习率)控制)的一小部分更改参数。通常将η>0设置为较小的数字(例如η=0.001)。如果学习率不太高,则基于x1一次更新将使此特定训练示例的损失变小。然而,很有可能会使其他一些训练示例的损失变大。因此,需要使用所有训练示例来更新参数。当所有训练示例皆已用于更新参数时,称为已处理一个学习周期。通常一个学习周期将减少训练集平均损失,直到学习系统拟合训练数据为止。因此,可重复梯度下降更新学习周期,在某个点终止以获得cnn参数(例如,验证集平均损失增加时即可终止)。
91、最后一层的偏导数易于计算。xl在参数wl的控制下直连到z,因此很容易计算仅当wl不为空时才需要执行此步骤。同样,也很容易计算例如,如果使用平方l2损失,则为空,
92、实际上,对于每一层,计算两组梯度:相对于层参数wi的z的偏导数,以及该层的输入xi。如等式4所示,术语可用于更新当前(第i层)的参数。术语可用于反向更新参数,例如更新到第(i-1)层。直观解释是:xi为第(i-1)层的输出,而为应更改xi以减少损失函数的方式。因此,可以视为逐层将从z反向传播到当前层的“错误”监管信息的一部分。因此,可继续反向传播过程,使用将错误反向传播到第(i-1)层。这种逐层反向更新的过程能够大幅简化学习cnn。
93、以第i层为例,当更新第i层时,必须已经完成第(i+1)层的反向传播过程。即,已经计算出项和两者都存储在存储器中,可备使用。此时的任务是计算和使用链式规则,得出:
94、
95、
96、由于已经计算出并将其存储在存储器中,因此仅需矩阵整形操作(vec)和额外的转置操作即可获得这是两个等式右侧(rhs)中的第一项。只要可计算出和便能轻松获得期望值(两个等式的左侧)。
97、和要比直接计算和容易得多,因为xi通过带有参数wi的函数与xi+1直接相关。
98、在神经网络的背景下,激活充当神经元输入和输出之间的转移函数。它们定义了在何条件下激活节点,即,将输入值映射到输出,该输出在隐藏层中又用作后续神经元的输入之一。存在大量具有不同特性的不同激活函数。
99、损失函数量化算法对给定数据的建模效果。为了从数据中学习并更改网络权重,必须使损失函数最小化。通常,可在回归损失和分类损失之间进行区分。在分类中,尝试预测从一组有限的分类值(分类标签)中预测输出,另一方面,在预测连续值时处理回归。
100、在以下数学公式中,以下参数定义为:
101、·n为训练示例数;
102、·i为数据集中的第i个训练示例;
103、·yi为第i个训练示例的基本真值标签;
104、·为第i个训练示例的预测。
105、分类问题最常见的设置是交叉熵损失,它随着预测概率与实际标签的偏离增加,实际预测概率的对数乘以基本真值类别。其重点在于,交叉熵损失会严重惩罚有把握但有误的预测。数学等式可写为:
106、
107、回归损失的典型示例是均方误差或l2损失。顾名思义,均方误差是指预测值与实际观察值之间平方差的平均值,这仅涉及平均误差幅度,而与它们的方向无关。然而,由于平方,与偏差较小的预测相比,预测远离实际值会遭受严重的缺陷。另外,mse具有良好的数学特性,使其更轻松地计算梯度。其等式如下:
108、
109、有关卷积神经网络功能的信息请参阅下列文献:
110、i.goodfellow、y.bengio和a.courville所著《deep learning,chapterconvolutional networks》,2016年,请见http://www.deeplearningbook.org;
111、j.wu所著《introduction to convolutional neural networks》,请见https://pdfs.semanticscholar.org/450c/a19932fcef1ca6d0442cbf52fec38fb9d1e5.pdf。
112、《common loss functions in machine learning》,请见https://towardsdatascience.com/common-loss-functions-in-machine-learning-46af0ffc4d23,最近访问时间:2019-08-22。
113、alex krizhevsky、ilya sutskever和geoffrey e.hinton所著《imagenetclassification with deep convolutional neural networks》,请见http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf。
114、s.ren、k.he、r.girshick和j.sun所著《faster r-cnn:towards real-timeobject detection with region proposal networks》,请见https://arxiv.org/pdf/1506.01497.pdf。
115、s.-e.wei、v.ramakrishna、t.kanade和y.sheikh所著《convolutional posemachines》,请见https://arxiv.org/pdf/1602.00134.pdf。
116、jonathan long、evan shelhamer和trevor darrell所著《fully convolutionalnetworks for semantic segmentation》,请见https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/long_fully_convolutional_net works_2015_cvpr_paper.pdf。
117、学习算法例如使用随机森林分类器。参阅antonio criminisi、jamie shotton和ender konukoglu所著《decision forests:a unified framework for classification,regression,density estimation,manifold learning and semi-supervised learning(决策森林:分类、回归、密度估算、流形学习和半监督学习的统一框架)》,2011年,请见https://www.microsoft.com/zh-us/research/wp-content/uploads/2016/02/criminisiforests_foundtrends_2011.pdf,随机森林的解释如下:
118、“随机森林”是一种用于分类或回归的集成学习方法,该方法通过在训练时间构建多种决策树并输出类别而运行,类别为单独树的类别(分类)的模式或平均预测(回归)。
119、随机森林的基本构建块是单决策树。决策树是一组以分层方式组织的问题,以图形方式表示为树。决策树通过询问有关其已知属性(所谓“特征”)的连续问题来估计对象的未知属性(“标签”)。接下来要考虑的问题取决于上一个问题的答案,这种关系以图形方式表示为对象遵循的穿过树的路径。然后,基于路径上的终端节点(所谓“叶节点”)做出决策。每个问题对应于树的内部节点(所谓“分割节点”)。
120、每个分割节点都有与之相关的所谓测试函数。将分割节点j处的测试函数用公式表示为具有二进制输出的函数:
121、
122、其中0和1可分别解释为“假”和“真”,表示第j个分割节点处测试函数的参数。
123、v则是由向量表示的当前对象(“数据点”),其中分量xi表示数据点的某些属性(特征),所有这些属性都形成特征空间。
124、在最简单的形式中,测试函数是线性模型,其在特征空间中选择一个特征轴,并根据各自特征的值是低于可学习阈值还是高于可学习阈值来对每个数据点进行分类。对于其他更复杂的形式,可能有非线性测试功能。
125、为了训练决策树,使用一组训练数据点,对于这一组训练数据点来说,特征和所述标签皆为已知。训练的目的是在所有分割节点上自动学习合适的测试函数,最适于从数据点的特征中确定标签。稍后,可以再通过经由基于其特征训练过的树发送数据点来针对带有未知标签的新数据点评估这种训练过的决策树。
126、为了理解训练过程,有益的是,将训练点的子集表示为与不同的树枝相关联。举例而言,s1表示到达节点1的训练点的子集(节点从0开始以广度优先的顺序对根f进行编号),而表示去往节点1的左侧子级和右侧子级的子集。
127、训练负责通过优化在可用训练集上定义的所选目标函数来选择与每个分割节点(由j索引)相关联的测试函数h(v,θj)的类型和参数。
128、分割函数的优化采取贪婪方式。在每个节点j上,根据引入训练集v的子集,学习将sj“最佳”分割为和的函数。这个问题用公式表示为该节点处目标函数的最大化:
129、
130、其中
131、
132、
133、
134、如前所述,符号表示分割前后的训练点集。目标函数在此呈抽象形式,其精确定义和“最佳”含义取决于将至的任务(例如,是否有监督,连续或离散输出)。例如,对于二进制分类,术语“最佳”可定义为分割训练子集sj,以使所得的子节点尽可能最纯,即,仅包含单类训练点。在此情况下,目标函数例如可定义为信息增益。
135、在训练期间,还需要优化树的结构(形状)。训练从根节点j=0开始,在该节点找到最优分割参数,如前所述。因此,构建两个子节点,每个子节点接收训练集的不同不相交子集。然后,将此过程应用于所有新构建的节点,训练阶段继续。树的结构取决于如何以及何时决定停止生长树的各个分支。可应用不同的停止标准。例如,当已到达最大数量的级别d时,通常会停止树。替代地,可施加最大值的最小值,换言之,当在叶节点内寻找训练点的属性彼此相似时停止。当节点包含的训练点太少时,树的生长也可能会停止。已经证明避免使整棵树生长在一般化方面具有积极影响。
136、在训练期间,将随机性注入到树中:当在第j个节点处进行训练时,不是在测试函数的整个参数空间上进行优化,而是仅使参数值的小随机子集可用。因此,在随机性模型下,通过优化每个分割节点j来完成训练树:
137、
138、由于这种随机设置,稍后可以并行对多个决策树进行训练,每个决策树利用来自数据点的不同的属性集。
139、在训练阶段的最后,获得:(i)与每个节点相关联的(贪婪)最优弱学习器;(ii)学习过的树结构;以及(iii)每片叶上的不同训练点集。
140、训练后,每个叶节点仍与(标记)训练数据的子集关联。在测试过程中,先前不可见的点穿过树直至到达叶。由于分割节点作用于特征,输入测试点可能最终位于与其自身相似的训练点相关联的叶中。因此,可以合理假设相关标签也必须与该叶中训练点的标签相似。这证明了使用该叶中收集的标签统计数据来预测与输入测试点相关联的标签的合理性。
141、在最泛化意义上,可使用后验分布来采集叶统计数据:
142、p(c|v)与p(y|v),
143、其中c和y分别表示离散标签或连续标签。v是在树中测试的数据点,条件作用表示分布取决于测试点到达的特定叶节点。可使用不同的叶预示变量。例如,在离散情况下,可以获得最大后验(map)估计为c*=arg maxcp(c|v)。
144、基于上述决策树的构造原理,现在可进入决策森林,又称为随机森林:
145、随机决策森林是一组随机训练的决策树。森林模型的关键在于其组成树彼此之间随机不同的事实。这导致个体树预测之间去相关,进而导致改进泛化性和鲁棒性。
146、在有t棵树的森林中,使用变量来索引每个组成树。独立训练(可能并行训练)所有树。在测试过程中,同时推进每个测试点通过所有树(从根处开始)直至到达相应的叶为止。树测试通常也可并行进行,因此在现代并行cpu或gpu硬件上实现高计算效率。可以通过简单的平均运算将所有树预测合并到单个森林预测中。例如,在分类中:
147、
148、pt(c|v)表示通过第t棵树获得的后验分布。替代地,也可将树输出一起相乘(尽管树在统计上并不独立):
149、
150、用分区函数z确保概率归一化。
151、定义
152、本部分提供了本公开所用具体术语的定义,它们也构成本公开的一部分。
153、本发明方法例如是一种计算机实施方法。例如,本发明方法的全部步骤或仅一些步骤(即,少于步骤总数)可以由计算机(例如,至少一台计算机)执行。计算机实施方法的实施例是计算机执行数据处理方法的用途。计算机实施方法的实施例是涉及计算机操作的方法,使得计算机操作为执行该方法的一个、多个或全部步骤。
154、计算机包括例如至少一个处理器和例如至少一个存储器,以便(技术上)处理数据,例如采取电子和/或光学方式处理数据。处理器例如由半导体的物质或组合物制成,例如至少部分n型和/或p型掺杂半导体,例如ii型、iii型、iv型、v型、vi型半导体材料中的至少一种,例如(掺杂)砷化硅和/或砷化镓。所述计算步骤或确定步骤例如由计算机执行。确定步骤或计算步骤例如是在技术方法框架内(例如程序框架内)确定数据的步骤。计算机例如是任何类型的数据处理装置,例如电子数据处理装置。计算机可以是通常视为计算机的装置,例如台式个人电脑、笔记本电脑、上网本等,但也可以是任何可编程设备,例如移动电话或嵌入式处理器。计算机可以例如包括“子计算机”系统(网络),其中每个子计算机代表其本身的计算机。术语“计算机”包括云计算机,例如云服务器。术语“计算机”包括服务器资源。术语“云计算机”包括云计算机系统,例如包括至少一个云计算机的系统,例如包括多个可操作性互连的云计算机,诸如服务器群。这种云计算机优选地连接到诸如万维网(www)等广域网,位于全部连接到万维网的所谓计算机云中。这种基础设施用于“云计算”,描述了不要求终端用户知道提供特定服务的计算机的物理位置和/或配置的那些计算、软件、数据访问和存储服务。例如,术语“云”就此用来隐喻因特网(万维网)。例如,云提供作为服务(iaas)的计算基础设施。云计算机可以充当用于执行本发明方法的操作系统和/或数据处理应用的虚拟主机。云计算机例如是由亚马逊网络服务(amazon web servicestm)提供的弹性计算云(ec2)。计算机例如包括接口,以便接收或输出数据和/或执行模数转换。该数据例如是表示物理属性和/或从技术信号生成的数据。技术信号例如通过(技术)检测装置(例如用于检测标记器的装置)和/或(技术)分析装置(例如用于执行(医学)成像方法的装置)来生成,其中技术信号是例如电信号或光信号。技术信号例如表示由计算机接收或输出的数据。计算机优选地可操作性耦合到显示装置,该显示装置允许将由计算机输出的信息显示给例如用户。显示装置的一个示例是虚拟现实装置或增强现实装置(又称为虚拟现实眼镜或增强现实眼镜),其可以充当用于导航的“护目镜”。这种增强现实眼镜的具体示例是谷歌眼镜(google glass,google,inc.旗下的商标品牌)。增强现实装置或虚拟现实装置既可用于通过用户交互将信息输入计算机中,又可用于显示由计算机输出的信息。显示装置的另一示例是例如包括液晶显示器的标准计算机监视器,该液晶显示器可操作性连接到用于从用于生成信号的计算机接收显示控制数据的计算机,该信号用于在显示装置上显示图像信息内容。这种计算机监视器的具体实施例是数字灯箱。这种数字灯箱的示例是brainlab ag的产品监视器也可以是例如手持式的便携式装置,诸如智能电话或个人数字助理或数字媒体播放器。
155、本发明还涉及一种包括指令的计算机程序,当由计算机执行该程序时,这些指令促使计算机执行本文所述的一种或多种方法,例如一种或多种方法的步骤;和/或一种存储有上述程序的计算机可读存储介质(例如非瞬态计算机可读存储介质);和/或一种包括上述程序存储介质的计算机;和/或一种携带表示程序(例如上述程序)的信息的(例如以技术手段生成的物理性、例如电)信号波,例如数字信号波,诸如电磁载波,该程序例如包括适于执行本文所述的任意或全部方法步骤的代码机构。某一示例中,信号波是携带上述计算机程序的数据载波信号。本发明还涉及一种计算机,该计算机包括至少一个处理器和/或上述计算机可读存储介质以及例如存储器,其中,该程序由处理器执行。
156、本发明框架内,计算机程序单元可以体现为硬件和/或软件(这包括固件、驻留软件、微代码等)。本发明框架内,计算机程序单元可以采取计算机程序产品的形式,该计算机程序产品可以体现为计算机可用、例如计算机可读的数据存储介质,该数据存储介质包括计算机可用、例如计算机可读的程序指令,所述数据存储介质中体现的“代码”或“计算机程序”使用于指令执行系统上或与指令执行系统结合使用。这种系统可以是计算机;计算机可以是包括用于执行本发明计算机程序单元和/或程序的机构的数据处理装置,例如包括执行计算机程序单元的数字处理器(中央处理单元或cpu)的数据处理装置,以及可选地包括用于存储用于执行计算机程序单元和/或通过执行计算机程序单元生成的数据的易失性存储器(例如随机存取存储器或ram)的数据处理装置。本发明框架内,计算机可用、例如计算机可读的数据存储介质可以是任何数据存储介质,其可以包含、存储、通信、传播或传输那些指令执行系统、设备或装置上使用或与之结合使用的程序。计算机可用、例如计算机可读的数据存储介质例如可以是但不限于电子、磁、光、电磁、红外或半导体系统、设备或装置,或者是诸如因特网的传播介质。计算机可用或计算机可读的数据存储介质甚至可以是例如可打印所述程序的纸张或其他合适介质,因为程序可以通过电子方式捕获,例如通过光学扫描该纸张或其他合适介质,然后再编译、解码或以适当方式另行处理。数据存储介质优选为非易失性数据存储介质。本文所述的计算机程序产品和任何软件和/或硬件形成用于在示例实施例中执行本发明功能的各种机构。计算机和/或数据处理装置可以例如包括指导信息装置,该指导信息装置包括用于输出指导信息的机构。指导信息可以例如在视觉上通过视觉指示机构(例如,监视器和/或灯)和/或在听觉上通过听觉指示机构(例如,扬声器和/或数字语音输出装置)和/或在触觉上通过触觉指示机构(例如,振动元件或并入器械中的振动元件)输出给用户。出于本文目的,计算机是技术计算机,例如包括诸如有形组件、例如机械组件和/或电子组件的技术组件。本文提及的任何装置都是技术装置并例如是有形装置。
157、表述“获取数据”例如包含(在所述计算机实施方法的框架内)由计算机实施方法或程序确定数据的场景。确定数据例如包含测量物理量并将所测得的值变换成数据,例如数字数据,和/或借助于计算机并例如在本发明方法的框架内计算(例如输出)该数据。如本文所述的“确定”步骤例如包括发出执行本文所述的确定的命令或由其组成。例如,该步骤包括发出促使计算机(例如远程计算机、例如远程服务器、例如云中)执行确定的命令或由其组成。替选地或附加地,本文所述的“确定”步骤例如包括以下步骤或由其组成:接收由本文所述的确定的结果数据,例如从远程计算机(例如从促使其执行确定的远程计算机)接收结果数据。“获取数据”的含义还例如包含以下场景:通过(例如输入)由计算机实施方法或程序例如从另一程序、先前的方法步骤或数据存储介质接收或检索数据,例如用于通过由计算机实施方法或程序进行进一步处理。生成待获取数据可以但不必是本发明方法的一部分。因此,表述“获取数据”还可以例如表示等待接收数据和/或接收数据。所接收的数据可以例如经由接口来输入。表述“获取数据”还可以表示由计算机实施方法或程序执行一些步骤以便(主动地)从譬如数据存储介质(例如rom、ram、数据库、硬盘驱动器等)的数据源或经由接口(譬如从其他计算机或网络)接收或检索数据。分别通过本公开方法或装置获取的数据可从位于数据存储装置中的数据库获取,该数据存储装置可操作性连接到计算机以便进行数据库与计算机之间的数据传输,例如从数据库到计算机的数据传输。计算机获取数据以用作“确定数据”步骤的输入。所确定的数据可以再输出到相同的或其他数据库以便存储以供后续使用。该数据库或用于实施本公开方法的数据库可以位于网络数据存储装置或网络服务器(例如,云数据存储装置或云服务器)或本地数据存储装置(例如可操作性连接到至少一个执行本公开方法的计算机的大容量存储装置)。数据可以通过在获取步骤之前执行附加步骤的方式来实现“就绪”状态。根据这个附加步骤,生成数据以供获取。例如,检测或捕获数据(例如,通过分析装置)。替选地或附加地,根据附加步骤,譬如经由接口,输入数据。例如可以输入所生成的数据(譬如,输入计算机中)。根据附加步骤(其在获取步骤之前进行),也可以通过执行将数据存储于数据存储介质(例如rom、ram、cd和/或硬盘驱动器)的附加步骤来提供数据,从而在本发明方法或程序的框架内,使数据就绪。因此,“获取数据”的步骤还可涉及命令装置获取和/或提供待获取的数据。特别地,获取步骤不涉及侵入性步骤,该侵入性步骤代表对身体的实质性物理干扰,要求采取专业医疗措施,即使执行时采取了所要求的专业护理和措施,身体也可能承受重大健康风险。特别地,获取数据的步骤,例如确定数据,不涉及外科手术步骤,特别是不涉及利用外科手术或疗法来治疗人体或动物躯体的步骤。为了区分本公开方法使用的不同数据,将数据表示为(即称为)“xy数据”等,并根据它们描述的信息来定义,然后优选地将其称为“xy信息”等。
158、当空间内的实际对象(例如,手术室中的身体部位)的每个点的空间位置均分配有存储在导航系统中的图像(ct、mr等)的图像数据点时,配准身体的n维图像。
- 还没有人留言评论。精彩留言会获得点赞!