具有使用异构标签分布的新标签的分布式机器学习的制作方法
公开的是涉及分布式机器学习的实施例,并且特定地,公开的是涉及具有使用异构标签分布的新标签的分布式机器学习(诸如例如,联合学习)的实施例。
背景技术:
1、在过去几年中,机器学习已经在各个领域(诸如自然语言处理、计算机视觉、语音识别、和物联网(iot))中产生了重大突破,其中一些突破涉及自动化和数字化任务。这种成功大多数源于在合适的环境中收集和处理大数据。对于机器学习的一些应用来说,收集数据的这种过程可能难以置信地侵犯隐私。一个潜在用例是改进语音识别和语言翻译的结果,而另一个是预测在移动电话上键入的下一个单词,以提高打字者的速度和生产率。在两种情况下,将有益的是,直接在相同数据上训练而不是使用来自其它源的数据。这将允许在同样用于进行预测的相同数据分布(i.i.d.——独立同分布)上训练机器学习(ml)模型(本文也称为“模型”)。然而,由于隐私考虑,直接收集此类数据可能不总是可行的。用户可能不喜欢也没有兴趣将他们键入的所有内容发送到远程服务器/云。
2、解决这一点的一个最近的解决方案是引入联合学习,一种新的分布式机器学习方法,其中训练数据根本不离开用户的计算装置。代替直接共享它们的数据,客户端计算装置本身使用它们的本地可用数据来计算权重更新。这是一种在不直接检查服务器节点或计算装置上的客户端或用户的数据的情况下训练模型的方式。联合学习是机器学习的一种协作形式,其中训练过程被分布在许多用户中。服务器节点或计算装置具有在模型之间进行协调的角色,但是大部分工作不再由中央实体来执行,而是由用户或客户端的联盟(federation)来执行。
3、在每个用户或客户端计算装置中初始化模型之后,随机选择一定数量的装置来改进模型。每个被采样的用户或客户端计算装置从服务器节点或计算装置接收当前模型,并使用其本地可用数据来计算模型更新。所有这些更新都被发送回服务器节点或计算装置,在所述服务器节点或计算装置对它们进行平均,并根据客户端使用的训练示例的数量进行加权。然后,服务器节点或计算装置通常通过使用某种形式的梯度下降将该更新应用于模型。
4、当前的机器学习方法要求大型数据集的可用性,这些数据集通常通过从用户或客户端计算装置收集大量数据来创建。联合学习是一种更灵活的技术,其允许在不直接看到数据的情况下训练模型。虽然机器学习过程以分布式方式使用,但联合学习与常规机器学习在数据中心中使用的方式非常不同。联合学习中使用的本地数据可能不具有与传统机器学习过程中相同的关于数据分布的保证,并且通信在本地用户或客户端计算装置与服务器节点或计算装置之间经常是缓慢且不稳定的。为了能够高效地执行联合学习,需要在每个用户机器或计算装置内适配适当的优化过程。例如,不同的电信运营商将各自生成巨大的警报数据集和相关特征。在这种情况下,与真警报列表相比,可能存在好的假警报列表。对于这样的机器学习分类任务,典型地,预先将要求中央中枢/储存库中的所有运营商的数据集。这是要求的,因为不同的运营商将包含各种特征,并且结果模型将学习它们的特性。然而,这种场景在实时情况下是极其不切实际的,因为它要求多个规章和地理许可;并且此外,对于运营商来说,这极其侵犯隐私。运营商通常将不想在其场所之外共享其客户的数据。因此,诸如联合学习之类的分布式机器学习可以提供一种合适的备选方案,在这种情况下能利用该备选方案来获得更大的益处。
技术实现思路
1、分布式机器学习(诸如联合学习)的概念是基于分布在多个计算装置上的数据集来建立机器学习模型,同时防止数据泄漏。参见例如bonawitz、keith等人的“towardsfederated learning at scale:system design”arxiv预印本arxiv:1902.01046(2019)。最近的挑战和改进已聚焦于克服联合学习中的统计挑战。也有研究努力使联合学习更加个性化。上述工作都聚焦于装置上联合学习,其中涉及分布式移动用户交互,并且大规模分布中的通信成本、不平衡的数据分布、以及装置可靠性是优化的一些主要因素。
2、然而,提出的当前联合学习方法存在缺点。通常固有地假设用户或客户端计算装置(本文也称为客户端或用户)试图训练/更新相同的模型架构。在这种情况下,客户端或用户不能自由选择它们自己的架构和ml建模技术。这对于客户端或用户来说可能是个问题,因为其可能导致计算装置上的本地模型过拟合或欠拟合。在模型更新之后,这也可能导致全局服务器节点或计算装置(下文也称为全局用户)中不胜任的全局模型。因此,对于客户端或用户来说,可能优选的是,选择适合其便利性的其自己的架构/模型,并且中央资源可以用于以有效的方式组合这些(潜在不同的)模型。
3、当前方法的另一个缺点是实时客户端或用户可能不具有遵循i.i.d.分布的样本。例如,在迭代中,客户端或用户a能够具有100个正样本和50个负样本,而用户b能够具有50个正样本、30个中性样本和0个负样本。在这种情况下,具有这些样本的联合学习设置中的模型可能导致较差的全局模型。
4、此外,当前的联合学习方法只能处理每个本地模型跨所有客户端或用户具有相同标签的情形,并且不提供处理独特标签或仅可适用于客户端或用户子集的标签的灵活性。然而,在许多实际应用中,对于每个本地模型,由于其对特定区域、人口统计等的依赖性和约束,具有可能仅适用于客户端或用户子集的独特标签或者新的或重叠的未见到标签可能是重要且常见的场景。在这种情况下,跨特定于区域的所有数据点可能存在不同的标签。
5、最近,本主题申请的受让人开发了一种能够实现在联合学习的用户之间使用异构模型类型和架构的方法,并在pct/in2019/050736中公开。此外,本主题申请的受让人开发了一种能够处理联合学习设置中的异构标签和异构模型的方法,并在pct/in2020/050618中公开。然而,仍然存在对于一种能够处理分布式机器学习设置中的新的且未见到的异构标签的方法的需要。
6、本文所公开的实施例提供了能够处理分布式机器学习设置中的新的且未见到的异构标签的方法。本文所公开的实施例提供了这样一种方式,例如在联合学习中,针对给定的感兴趣问题(即图像分类、文本分类等),为所有用户处理具有异构标签分布的新的未见到标签。术语“标签”和“类别”在本文中可互换使用,并且本文所公开和要求保护的方法适用于并适配于处理新的且未见到的异构标签和类别两者,如这些术语在本文中所使用的那样,并且也如本领域普通技术人员通常理解的那样。如关于示例性实施例进一步详细描述的,类别可以是例如“猫”、“狗”、“大象”等,并且类似地,来自这些类的标签包括“猫”、“狗”、“大象”等的特定实例。
7、虽然实施例处理联合学习设置中的未见到异构标签,但是通常假设存在对所有本地客户端或用户以及全局用户可用的公共数据集。本地用户发送从公共数据集获得的softmax概率,而不是将本地模型更新发送给全局用户。本文所公开的实施例通过从类别相似性矩阵合成数据印象(data impression)而学习新的类别(标签),来提供具有零次学习机制(zero-shot learning mechanism)的框架。在一些实施例中,为了结合报告标签的本地客户端或用户的可信度,使用用于验证跨本地客户端或用户所新报告的类别(标签)的无监督聚类技术。
8、以这种方式,例如,新的类别(标签)被再次添加到公共数据集中,以用于下一次联合学习迭代。实施例的附加优点是本地客户端或用户能够在联合学习方法中拟合它们自己的模型(异构模型)。
9、实施例还能够有利地处理新的且未见到的异构标签,使得本地客户端或用户能够在联合学习期间跨本地装置具有不同的新的且未见到的类别(标签),处理跨用户的异构标签分布(这在大多数行业中是常见的),以及处理跨用户的不同数据分布和模型架构。
10、根据第一方面,提供了一种在中央计算装置用于分布式机器学习(ml)的方法。所述方法包括向包括第一本地计算装置和第二本地计算装置的多个本地计算装置提供包括第一标签集合的第一数据集。所述方法进一步包括从所述第一本地计算装置接收来自使用所述第一标签集合训练第一本地ml模型的第一ml模型概率值集合。所述方法进一步包括从所述第二本地计算装置接收来自使用所述第一标签集合和不同于所述第一标签集合中的任何标签的一个或多个标签训练第二本地ml模型的第二ml模型概率值集合。所述方法进一步包括使用所接收的第一ml模型概率值集合和所接收的第二ml模型概率值集合来生成权重矩阵。所述方法进一步包括通过使用所生成的权重矩阵进行采样来生成第三ml模型概率值集合。所述方法进一步包括使用所生成的第三ml模型概率值集合来生成第一数据印象集合,其中所述第一数据印象集合包括不同于所述第一标签集合中的任何标签的所述一个或多个标签中的每个标签的数据印象。所述方法进一步包括通过使用不同于所述第一标签集合中的任何标签的所述一个或多个标签中的每个标签的所生成的第一数据印象集合进行聚类来生成第二数据印象集合。所述方法进一步包括使用所生成的第二数据印象集合来训练全局ml模型。
11、在一些实施例中,所述方法进一步包括通过使用不同于所述第一标签集合中的任何标签的所述一个或多个标签和所述第一标签集合的每个标签的所述第二数据印象集合和所述第一数据印象集合进行平均来生成第四ml模型概率值集合。在一些实施例中,所述方法进一步包括向包括所述第一本地计算装置和所述第二本地计算装置的所述多个本地计算装置提供所生成的第四ml模型概率值集合,以用于训练本地ml模型。
12、在一些实施例中,所接收的第一ml模型概率值集合和所接收的第二ml模型概率值集合是以下之一:softmax值、sigmoid值和dirichlet值。在一些实施例中,使用所生成的权重矩阵进行采样是根据softmax值和dirichlet分布函数。在一些实施例中,所生成的权重矩阵是类别相似性矩阵。在一些实施例中,使用不同于所述第一标签集合中的任何标签的所述一个或多个标签中的每个标签的所生成的第一数据印象集合进行聚类是根据k-medoids聚类算法,并且使用elbow方法来确定聚类k的数量。
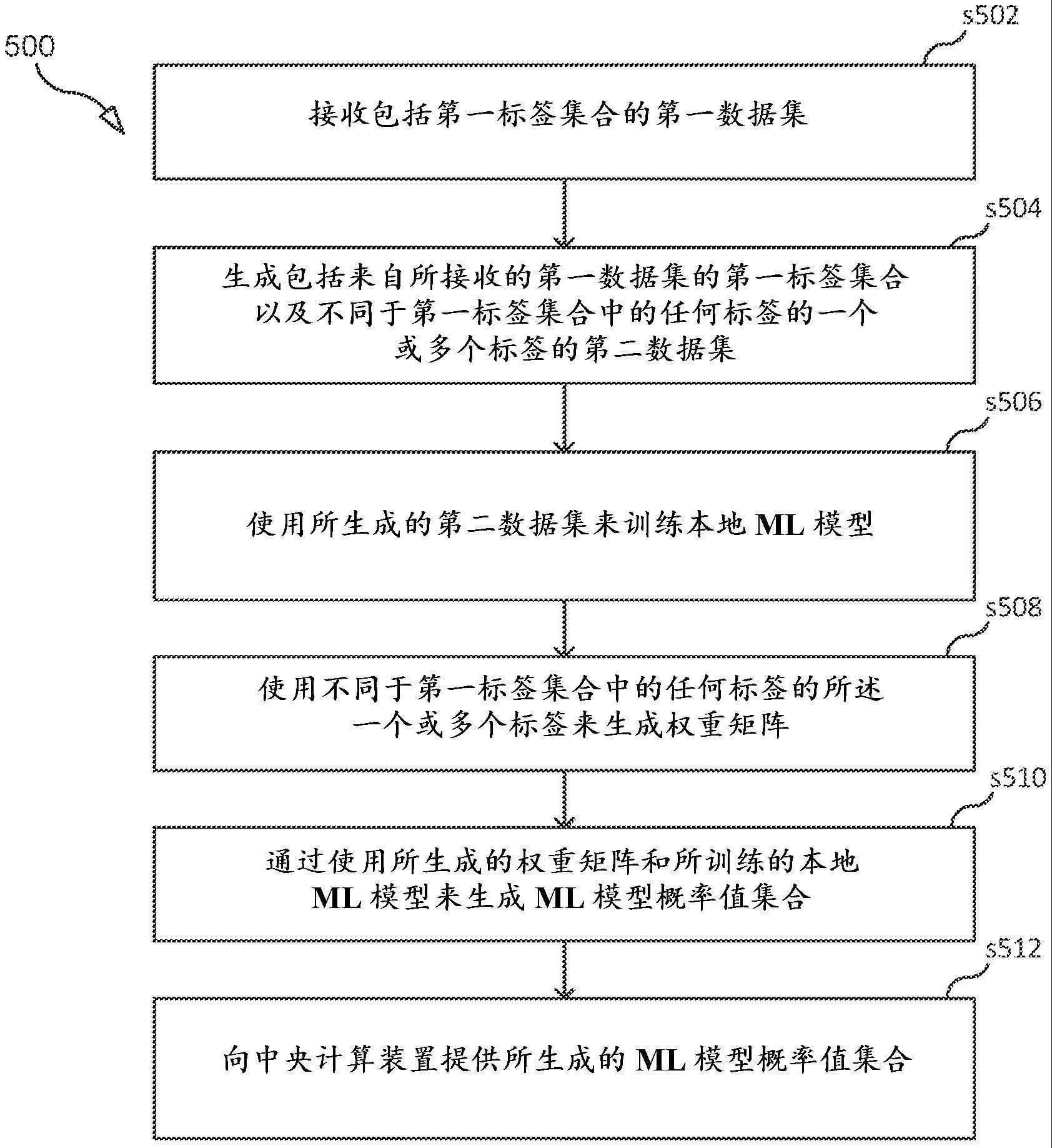
13、根据第二方面,提供了一种在本地计算装置用于分布式机器学习(ml)学习的方法。所述方法包括接收包括第一标签集合的第一数据集。所述方法进一步包括生成包括来自所接收的第一数据集的所述第一标签集合以及不同于所述第一标签集合中的任何标签的一个或多个标签的第二数据集。所述方法进一步包括使用所生成的第二数据集来训练本地ml模型。所述方法进一步包括使用不同于所述第一标签集合中的任何标签的所述一个或多个标签来生成权重矩阵。所述方法进一步包括通过使用所生成的权重矩阵和所训练的本地ml模型来生成ml模型概率值集合。所述方法进一步包括向中央计算装置提供所生成的ml模型概率值集合。
14、在一些实施例中,所接收的第一数据集是公共数据集,并且所生成的第二数据集是私有数据集。在一些实施例中,所述本地ml模型是以下之一:卷积神经网络(cnn)、人工神经网络(ann)和递归神经网络(rnn)。在一些实施例中,所述方法进一步包括从所述中央计算装置接收ml模型概率值集合,所述ml模型概率值集合表示使用不同于所述第一标签集合中的任何标签的所述一个或多个标签和所述第一标签集合的每个标签的第二数据印象集合和第一数据印象集合进行平均。在一些实施例中,所述方法进一步包括使用所接收的ml模型概率值集合来训练所述本地ml模型。
15、在一些实施例中,包括所述第一本地计算装置和所述第二本地计算装置的所述多个本地计算装置包括被配置成使用所训练的本地ml模型对警报类型进行分类的多个无线电网络节点。在一些实施例中,包括所述第一本地计算装置和所述第二本地计算装置的所述多个本地计算装置包括被配置成使用所训练的本地ml模型对警报类型进行分类的多个无线传感器装置。
16、根据第三方面,提供了一种中央计算装置。所述中央计算装置包括存储器以及耦合到所述存储器的处理器。所述处理器被配置成向包括第一本地计算装置和第二本地计算装置的多个本地计算装置提供包括第一标签集合的第一数据集。所述处理器进一步被配置成从所述第一本地计算装置接收来自使用所述第一标签集合训练第一本地ml模型的第一ml模型概率值集合。所述处理器进一步被配置成从所述第二本地计算装置接收来自使用所述第一标签集合和不同于所述第一标签集合中的任何标签的一个或多个标签训练第二本地ml模型的第二ml模型概率值集合。所述处理器进一步被配置成使用所接收的第一ml模型概率值集合和所接收的第二ml模型概率值集合来生成权重矩阵。所述处理器进一步被配置成通过使用所生成的权重矩阵进行采样来生成第三ml模型概率值集合。所述处理器进一步被配置成使用所生成的第三ml模型概率值集合来生成第一数据印象集合,其中所述第一数据印象集合包括不同于所述第一标签集合中的任何标签的所述一个或多个标签中的每个标签的数据印象。所述处理器进一步被配置成通过使用不同于所述第一标签集合中的任何标签的所述一个或多个标签中的每个标签的所生成的第一数据印象集合进行聚类来生成第二数据印象集合。所述处理器进一步被配置成使用所生成的第二数据印象集合来训练全局ml模型。
17、在一些实施例中,所述处理器进一步配置成通过使用不同于所述第一标签集合中的任何标签的所述一个或多个标签和所述第一标签集合的每个标签的所生成的第二数据印象集合和所生成的第一数据印象集合进行平均来生成第四ml模型概率值集合。在一些实施例中,所述处理器进一步配置成向包括所述第一本地计算装置和所述第二本地计算装置的多个本地计算装置提供所生成的第四ml模型概率值集合,以用于训练本地ml模型。
18、在一些实施例中,包括所述第一本地计算装置和所述第二本地计算装置的所述多个本地计算装置包括被配置成使用所训练的本地ml模型对警报类型进行分类的多个无线电网络节点。在一些实施例中,包括所述第一本地计算装置和所述第二本地计算装置的所述多个本地计算装置包括被配置成使用所训练的本地ml模型对警报类型进行分类的多个无线传感器装置。
19、根据第四方面,提供了一种本地计算装置。所述本地计算装置包括存储器和耦合到所述存储器的处理器。所述处理器被配置成接收包括第一标签集合的第一数据集。所述处理器进一步被配置成生成包括来自所接收的第一数据集的所述第一标签集合以及不同于所述第一标签集合中的任何标签的一个或多个标签的第二数据集。所述处理器进一步被配置成使用所生成的第二数据集来训练本地ml模型。所述处理器进一步被配置成使用不同于所述第一标签集合中的任何标签的所述一个或多个标签来生成权重矩阵。所述处理器进一步被配置成通过使用所生成的权重矩阵和所训练的本地ml模型来生成模型概率值集合。所述处理器进一步被配置成向中央计算装置提供所生成的模型概率值集合。
20、在一些实施例中,所接收的第一数据集是公共数据集,并且所生成的第二数据集是私有数据集。在一些实施例中,所述本地ml模型是以下之一:卷积神经网络(cnn)、人工神经网络(ann)和递归神经网络(rnn)。在一些实施例中,所述处理器进一步配置成从所述中央计算装置接收ml模型概率值集合,所述ml模型概率值集合表示使用不同于所述第一标签集合中的任何标签的所述一个或多个标签和所述第一标签集合的每个标签的第二数据印象集合和第一数据印象集合进行平均。在一些实施例中,所述处理器进一步配置成使用所接收的ml模型概率值集合来训练所述本地ml模型。
21、在一些实施例中,所述本地计算装置包括无线电网络节点,并且所述处理器进一步配置成使用所训练的本地ml模型对警报类型进行分类。在一些实施例中,所述本地计算装置包括无线传感器装置,并且所述处理器进一步配置成使用所训练的本地ml模型对警报类型进行分类。
22、根据第五方面,提供了一种包括指令的计算机程序,所述指令当由处理电路模块执行时,使得所述处理电路模块执行根据第一或第二方面的实施例中任一实施例所述的方法。
23、根据第六方面,提供了一种包含根据第五方面所述的计算机程序的载体,其中,所述载体是以下之一:电子信号、光信号、无线电信号、和计算机可读存储介质。
- 还没有人留言评论。精彩留言会获得点赞!