基于物品簇级多目标优化的物品推荐方法及装置和设备
1.本技术涉及物品推荐技术领域。尤其是涉及一种基于物品簇级多目标优化的物品推荐方法及装置和设备。
背景技术:
2.随着移动互联网的快速发展,推荐系统(recommender systems)成为在线内容服务平台中解决信息过载问题的关键技术。基于协同过滤的推荐系统采用用户-物品历史交互记录进行训练,目标是在给定当前用户状态的情况下提供他/她最有可能感兴趣的物品,实现个性化推荐。然而,在推荐系统的训练过程中存在一个自循环:系统的曝光和推荐机制实际影响了历史交互记录的收集(推荐给用户的物品会大概率被用户所点击,然后作为正样本再次进入系统进行训练)。这种自循环会导致训练过程中出现严重的流行度偏差(popularity bias)。因此,实验证明训练数据中的物品出现频率分布实际是一个极端的幂律分布:一小部分流行(头部)物品的交互样本几乎占据了整个训练数据集的大部分,基于这种存在偏见的训练数据进行推荐模型的学习会导致头部物品获得更高的预估得分,从而被推向更高的排名位置;与之相反,长尾物品则会收到模型忽视。结果导致,热门物品被重复推荐给用户,这进一步加剧了流行度偏见和出现“强者愈强”问题的马太效应。
3.尽管如此,长尾物品集合中的推荐效果往往在提高系统性能方面起着重要作用:从用户的角度来说,他/她很容易对重复的热门推荐和流量物品感到厌烦;在长尾物品集合中,实际存在着更符合用户真实兴趣偏好的潜在物品。对于互联网内容服务提供平台来说,与头部流量物品相比,推荐并出售更多的长尾商品可带来更多的边际利润。一般来说,推荐任务是一个典型的开发-探索(exploration and exploitation)问题,长尾物品集合部分的精准推荐将有利于内容平台更好地探索用户兴趣,最终转化为更高的在长期利润。
4.现有的专注于长尾物品推荐的方法通常基于在训练目标中添加推荐多样性和新颖性等指标;然而,第一,基于添加此类指标进行训练的推荐算法(作为约束项或作为多目标优化问题)可能会导致准确性的巨大牺牲;第二,此类指标无法直接量化并进行优化,推荐结果的多样性和新颖性仍然是一个开放的研究问题,没有标准或公认的计算公式。
技术实现要素:
5.鉴于以上所述现有技术的缺点,本技术的目的在于提供一种基于物品簇级多目标优化的物品推荐方法及装置和设备,用于解决现有技术中推荐系统的流行度偏差问题。
6.为实现上述目的及其他相关目的,本技术提供一种基于物品簇级多目标优化的物品推荐方法,所述方法包括:获取用户个人兴趣特征与物品特征;采用因果学习将全局流行度特征从用户个人兴趣特征中进行分离;通过物品特征与全局流行度特征的相关性将物品进行动态聚类分簇,以供得到物品簇;利用帕累托最优求解器求解每个物品簇目标的最优梯度权重,从而获得全局最优的梯度更新;采用二元交叉熵作为用户-物品样本的主损失函数进行训练,并在损失函数中引入收缩损失作为约束项,以供对用户推荐商品。
7.于本技术的一实施例中,所述采用因果学习将全局流行度特征从用户个人兴趣特征中进行分离,包括:其中,fb(
·
)表示个人兴趣部分函数;f
p
(
·
)表示全局流行度部分模型;λ
p
表示控制全局流行度影响比例的权重超参数,θb和θ
p
分别是fb(
·
)和f
p
(
·
)的参数;vu为用户个人兴趣特征向量;u表示用户;v
′
为全局流行度特征向量;vi为物品特征向量;i表示物品。
8.于本技术的一实施例中,所述通过物品特征与全局流行度特征的相关性将物品进行动态聚类分簇,包括:其中,表示聚类特征向量,用于强调物品特征向量vi与全局流行度特征向量v
′
在方向上的关系与相似性;
⊙
表示阿达玛乘积;||
·
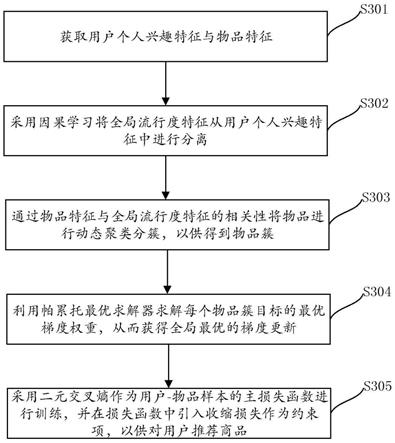
||表示求解一阶范数。
9.于本技术的一实施例中,所述物品特征向量与全局流行度特征向量相似的物品,与物品特征向量与全局流行度特征向量相远的物品在全局训练过程中处于同等地位。
10.于本技术的一实施例中,所述利用帕累托最优求解器求解每个物品簇目标的最优梯度权重,从而获得全局最优的梯度更新,包括:给定在一个训练集中的损失函数采用karush-kuhn-tucker条件方程组来描述最优梯度权重ωk的性质:1)ω1,
…
,ωk≥0并且2)对共享参数集合求解最优梯度权重ωk的计算公式如下:其中,k表示预设目标个数;||
·
||2表示求解二阶范数;表示第k个任务的损失函数;表示对于共享参数集合θ
sh
的偏导数。
11.于本技术的一实施例中,所述在损失函数中引入收缩损失作为约束项,包括:其中,表示收缩损失函数;||
·
||2表示求解二阶范数,代表用户个人兴趣特征向量vu对于物品特征向量vi的偏导数,代表物品特征向量vi对于全局流行度特征向量v
′
的偏导数;u表示用户;i表示物品。
12.于本技术的一实施例中,所述主损失函数的计算公式包括:的计算公式包括:其中,y
ui
是用户-物品样本对(u,i)的真实标签;其中,若用户u和物品i之间存在点击交互,则y
ui
=1,否则y
ui
=0;σ(
·
)是sigmoid函数;是推荐模型的预估logits。
13.于本技术的一实施例中,所述方法还包括:基于收缩损失函数,关于共享参数集合θ
sh
的最终训练函数计算公式如下其中,表示共享损失函数;是正样本集合部分的损失函数;是单个用户-物品样本对(u,i)的损失函数;;是负样本集合部分的损失函数;表示用户-物品样本对(u,i)属于负样本集合r-;λc和λr分别是收缩损失函数和共享参数集合θ
sh
的相
关超参系数。
14.为实现上述目的及其他相关目的,本技术提供一种基于物品簇级多目标优化的物品推荐装置,所述装置包括:获取模块,用于获取用户个人兴趣特征与物品特征;处理模块,用于采用因果学习将全局流行度特征从用户个人兴趣特征中进行分离;通过物品特征与全局流行度特征的相关性将物品进行动态聚类分簇,以供得到物品簇;利用帕累托最优求解器求解每个物品簇目标的最优梯度权重,从而获得全局最优的梯度更新;采用二元交叉熵作为用户-物品样本的主损失函数进行训练,并在损失函数中引入收缩损失作为约束项,以供对用户推荐商品。
15.为实现上述目的及其他相关目的,本技术提供一种计算机设备,所述设备包括:存储器、处理器、及通信器;所述存储器存储有数据传输程序,所述处理器执行所述数据传输程序实现如上所述的方法;所述通信器分别通信连接用于对数据集存储与预处理的数据库、用于web内容推荐的客户端。
16.如上所述,本技术的一种基于物品簇级多目标优化的物品推荐方法及装置和设备,通过获取用户个人兴趣特征与物品特征;采用因果学习将全局流行度特征从用户个人兴趣特征中进行分离;通过物品特征与全局流行度特征的相关性将物品进行动态聚类分簇,以供得到物品簇;利用帕累托最优求解器求解每个物品簇目标的最优梯度权重,从而获得全局最优的梯度更新;采用二元交叉熵作为用户-物品样本的主损失函数进行训练,并在损失函数中引入收缩损失作为约束项,以供对用户推荐商品。
17.具有以下有益效果:
18.本技术有效对现有推荐系统中流行度偏差问题进行缓解与消除的同时获得了推荐准确率的提升。同时本算法框架的额外时间复杂度和空间复杂度均在可接受范围内,在商用内容服务平台中的应用具有巨大潜力。
附图说明
19.图1显示为本技术于一实施例中不同物品对模型总梯度的二阶范数的示意图。
20.图2显示为本技术于一实施例中物品在降维空间内的梯度关系的示意图。
21.图3显示为本技术于一实施例中基于物品簇级多目标优化的物品推荐方法的流程示意图。
22.图4显示为本技术于一实施例中物品簇级多目标优化算法框架icmt的示意图。
23.图5显示为本技术于一实施例中基于物品簇级多目标优化的物品推荐装置的模块示意图。
24.图6显示为本技术于一实施例中的计算机设备的结构示意图。
具体实施方式
25.以下通过特定的具体实例说明本技术的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本技术的其他优点与功效。本技术还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本技术的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
26.需要说明的是,以下实施例中所提供的图示仅以示意方式说明本技术的基本构想,遂图式中仅显示与本技术中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
27.为解决上述问题,本技术从优化的角度分析了现有推荐系统中的流行度偏差问题。首先,对gowalla数据集进行了实证研究,在此数据集上采用最先进的图神经网络推荐模型lightgcn进行训练,如图1所示,可视化了不同物品对模型总梯度的二阶范数;如图2所示,展示了数据集中编号1706的头部流行物品和编号分别为8698和13155的两个长尾物品在降维空间内的梯度关系,从中可得以下观察结论:
28.(1)头部热门物品的梯度范数比长尾物品在量级上大很多,说明整体的梯度方向实际是由头部热门物品主导的。
29.(2)来自头部热门物品和长尾物品的梯度之间存在潜在冲突,也就间接导致,基于以头部热门物品梯度为主的模型参数更新可能会破坏模型在长尾物品集合中的学习与拟合。
30.基于上述观察,本技术提出用于推荐系统的物品簇级多目标优化算法框架(item cluster-wise multi-objective training,icmt)以消除流行度偏差。
31.需要说明的是,icmt是一个通用的(模型无关的)算法框架,可使用不同的特定模型进行实例化,例如概率矩阵分解模型(probabilistic matrix factorization,pmf)、神经网络协同过滤模型(neural matrix factorization,neumf)、轻量级图卷积网络模型(lightgcn)等。
32.在一或多个实施例中,基于本技术所述推荐方法在实际应用中,首先可通过最先进的推荐模型(例如lightgcn)实例化icmt算法框架;接下来在服务端进行模型训练和模型部署;在web客户端为用户提供个性化内容推荐服务。
33.在模型训练环节中,首先进行数据集中训练集、验证集和测试集的划分,如比例分配为8:1:1;接下来进行模型的离线训练。在落地应用时,模型训练是在单台服务器中进行的,其硬件配置为:20核cpu(intel(r)core(tm)i9-7900x cpu@3.30ghz),4张gpu(geforce gtx 1080ti 11g gddr5x),内存64g;本应用全部采用tensorflow作为深度学习框架,其版本为1.15.0;训练和框架实现细节如下介绍。
34.如图3所示,展示本技术于一实施例中的基于物品簇级多目标优化的物品推荐方法的流程示意图。如图所述,所述方法包括:
35.步骤s301:获取用户个人兴趣特征与物品特征。
36.简单来说,本技术将用用户交互行为分为个人兴趣和全局流行度两个维度展开。可参考图4所示的,物品簇级多目标优化算法框架icmt的示意图。如图所示,可基于传统推荐模型获来获取用户个人兴趣特征和物品特征。
37.优先地,所述传统推荐模型包括但不下于:概率矩阵分解模型(probabilistic matrix factorization,pmf)、神经网络协同过滤模型(neural matrix factorization,neumf)、轻量级图卷积网络模型(lightgcn)等。
38.步骤s302:采用因果学习将全局流行度特征从用户个人兴趣特征中进行分分解,并在推理阶段进行分离。
39.于本技术一实施例中,在传统推荐模型fb(
·
)的基础上,本技术icmt框架细化并分解了用户表征的粒度,为每个用户分配一个独特的用户个人兴趣特征向量vu来表示个人内在兴趣的同时维护了全局流行度特征向量建模流行度影响。后者在物理意义上表示整体流行度趋势,参与到每个正向点击交互样本的训练过程中,这部分表示为函数f
p
(
·
)。通过聚合,icmt的预测函数计算公式如下:
[0040][0041]
其中,fb(
·
)表示个人兴趣部分函数;f
p
(
·
)表示全局流行度部分模型;λ
p
表示控制全局流行度影响比例的权重超参数,θb和θ
p
分别是fb(
·
)和f
p
(
·
)的参数;vu为用户个人兴趣特征向量;v
′
为全局流行度特征向量;vi为物品特征向量。
[0042]
在推理阶段,只有个人兴趣部分函数fb(
·
)用于最终点击率预估,框架将全局流行度的影响部分进行了显示消除。不失一般性,在icmt中使用内积(inner product)作为f
p
(
·
)的实现方式。
[0043]
步骤s303:通过物品特征与全局流行度特征的相关性将物品进行动态聚类分簇,以供得到物品簇。
[0044]
简单来说,将模型在每个物品簇上的拟合视为优化子目标,从而,对整个训练数据的拟合可视为对多个物品簇目标的多目标优化问题。
[0045]
于本技术中,本技术icmt框架通过以下观测对物品进行聚类,即物品特征向量与全局流行度特征向量相似的物品,与物品特征向量与全局流行度特征向量相远的物品在全局训练过程中处于同等地位,从而以此观测生成不同的物品簇。本框架通过v
′
与所有vi的阿达玛乘积(hadamard product)操作来计算相似度。最终进行聚类的物品特征向量定义如下:
[0046][0047]
其中,表示聚类特征向量,用于强调物品特征向量vi与全局流行度特征向量v
′
在方向上的关系与相似性;
⊙
表示阿达玛乘积;||
·
||表示求解一阶范数。
[0048]
优选地,最终聚类特征向量为该乘积除以特征向量间的内积,以归一化向量尺度因素影响。聚类特征向量强调物品特征向量与流行度特征向量在方向上的关系与相似性。然后,本框架在所构成的潜在空间中执行ae-kmeans聚类算法进行物品集合中的分簇。
[0049]
步骤s304:利用帕累托最优求解器求解每个物品簇目标的最优梯度权重,从而获得全局最优的梯度更新。
[0050]
对多个物品簇目标的多目标优化的步骤中,本技术icmt框架利用帕累最优求解器(pareto-efficiency solver)来自适应地分配每个目标的梯度权重,从而获得全局最优的梯度更新。其中,模型对头部物品集合的拟合不会损害到对长尾物品集合的拟合。
[0051]
于一些示例中,在获得了物品簇之后,下一步将求解每个簇目标所对应的帕累托最优权重ωk。值得一提的是,帕累托最优的有效解并不是唯一的,所有有效解的集合命名为帕累托前沿(pareto frontier)。本框架的目标是找到一组权重集合ωk以便使由多个物
品簇目标整体达到帕累托最优状态,该方法又名物品簇级帕累托最优(item cluster-wise pareto-efficiency)。
[0052]
根据帕累托最优的定义,给定在一个训练batch中的损失函数本技术采用karush-kuhn-tucker(kkt)条件方程组来描述ωk的性质:
[0053]
(1)ω1,
…
,ωk≥0并且
[0054]
(2)对模型共享参数集合
[0055]
因此,求解ωk的计算公式如下:
[0056][0057][0058]
其中,k表示预设目标个数;||
·
||2表示求解二阶范数;表示第k个任务的损失函数;表示对于共享参数集合θ
sh
的偏导数。
[0059]
上式中定义的最优化问题相当于在输入点集(即ωk的参数空间)的凸包中找到一个最小范数点,本技术优选采用frank-wolfe算法来解决该凸优化问题。
[0060]
步骤s305:采用二元交叉熵作为用户-物品样本的主损失函数进行训练,并在损失函数中引入收缩损失作为约束项,以供对用户推荐商品。
[0061]
在损失函数中,icmt引入了关注模型鲁棒性的收缩损失(contractive loss)作为约束项,以进一步抑制模型对长尾物品集合的忽视。
[0062]
于本技术一实施例中,随着头部热门物品主导了推荐系统梯度更新过程,模型参数容易被头部热门物品的微小波动和变化而大幅影响。本框架提出了一个有效的约束项,以提升模型鲁棒性并进一步消除流行度偏差的副作用。
[0063]
其中,对于稳健的模型,当物品特有参数vi发生微小波动时,用户特征向量vu应保持较小幅度的变化。同时,为尽量消除流行度偏差,物品特征向量也应较少受到全局流行度特征向量v
′
的影响。因此,本框架将收缩约束项定义为vu关于vi的雅可比矩阵(jacobian matrix)的平方和以及vi相对于v
′
的偏导数之和:
[0064][0065]
其中,表示收缩损失函数;||
·
||2表示求解二阶范数,代表用户个人兴趣特征向量vu对于物品特征向量vi的偏导数,代表物品特征向量vi对于全局流行度特征向量v
′
的偏导数;u表示用户;i表示物品。
[0066]
于本技术一实施例中,本技术采用二元交叉熵作为主损失函数来训练推荐模型。准确来说,用户-物品样本对(u,i)的主损失具体计算公式如下:
[0067]
[0068]
其中,y
ui
是(u,i)用户-物品样本对的真实标签(即如果用户u和物品i之间存在点击交互,则y
ui
=1,否则y
ui
=0);σ(
·
)是sigmoid函数,是推荐模型的预估logits。
[0069]
此外,考虑到关注模型鲁棒性的收缩约束项,本框架关于共享参数θ
sh
的最终训练函数计算公式如下:
[0070][0071]
其中,表示共享损失函数;是正样本集合部分的损失函数;是单个用户-物品样本对(u,i)的损失函数;;是负样本集合部分的损失函数;表示用户-物品样本对(u,i)属于负样本集合r-;λc和λr分别是收缩损失函数和共享参数集合θ
sh
的相关超参系数。
[0072]
在一或多个可实现的示例汇总,本技术所实现的推荐系统可包括数据模块,推荐服务模块(tensorflow框架进行模型训练和部署)和web内容推荐客户端三大部分。数据模块进行数据集的存储、预处理和数据流的生成,主要使用sqlite数据库进行实现;推荐服务模块进行本技术推荐模型和算法框架的执行,本技术可使用tensorflow serving将训练完毕的模型转化为在线的个推荐服务;web内容推荐客户端的功能包括用户登录,推荐结果的展示和用户行为的日志记录。本推荐系统应用在公网进行了部署,在目前较为普遍的百兆无线网络带宽条件和100-300的并发数下,模型平均推理延时在30-50ms,页面平均刷新延时在80-100ms,具有良好的应用体验。
[0073]
综上所述,本技术提出的一种从因果学习和物品簇级多目标优化的角度消除推荐系统中流行度偏差问题的算法框架icmt,并在三个主流推荐模型上建立了采用此框架的推荐系统。在广泛使用的三个大规模电商数据集上,系统实现了多场景下的个性化推荐。
[0074]
实验结果证明,在包含全局流行度影响因素分解,物品簇级帕累托最优梯度求解和提升模型鲁棒性的收缩约束项三个创新模块的作用下,推荐系统的流行度偏差问题得到了有效缓解,在长尾物品集合上的推荐性能得到了大幅提升,同时,模型整体的推荐准确率也获得了提升。综合pmf,neumf和lightgcn三种推荐模型和last.fm,gowalla和yelp2018三个数据集,icmt框架在长尾性能评估指标长尾召回率(recall-tail@20)/长尾归一化折扣累积增益(ndcg-tail@20)/物品集合覆盖率(coverage@20)/长尾物品比例(apt@20)上平均获得了42.45%/30.11%/15.45%/33.23%的提升;在整体准确率评估指标召回率(recall@20)/归一化折扣累积增益(ndcg@20)上平均获得了4.03%/2.98%的提升。
[0075]
同时,本定位可广泛进行了消融学习,超参数学习和样例学习,从而对模型各组件的功效以及参数敏感性等特性进行详细分析;通过消融学习证明了三个创新组件的有效性,其中全局流行度影响因素分解和物品簇级帕累托最优梯度求解对模型的总体准确率和长尾物品集合上的性能带来了显著提升,收缩约束项则有效提升了模型的推荐集合覆盖率和抗恶意攻击性;超参数学习部分根据数据集选择了最有的参数组合,样例学习则验证了icmt框架对长尾物品集合的重视效果(获得更高且具有理论含义的样本权重)。
[0076]
本动物将因果学习与物品簇级多目标优化相结合,提出了一种解决推荐系统中流行度偏差问题的新方法,有效对该问题进行缓解与消除的同时获得了推荐准确率的提升。同时,本算法框架的额外时间复杂度和空间复杂度均在可接受范围内,在商用内容服务平
台中的应用具有巨大潜力。
[0077]
如图5所示,展示本技术于一实施例中的基于物品簇级多目标优化的物品推荐装置的模块示意图,如图所示,所述基于物品簇级多目标优化的物品推荐装置500包括:
[0078]
获取模块501,用于获取用户个人兴趣特征与物品特征;
[0079]
处理模块502,用于采用因果学习将全局流行度特征从用户个人兴趣特征中进行分离;通过物品特征与全局流行度特征的相关性将物品进行动态聚类分簇,以供得到物品簇;利用帕累托最优求解器求解每个物品簇目标的最优梯度权重,从而获得全局最优的梯度更新;采用二元交叉熵作为用户-物品样本的主损失函数进行训练,并在损失函数中引入收缩损失作为约束项,以供对用户推荐商品。
[0080]
可以理解的是,所述基于物品簇级多目标优化的物品推荐装置500通过各模块的运行,能够实现如图3所述的基于物品簇级多目标优化的物品推荐方法。
[0081]
需要说明的是,应理解以上装置的各个模块的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个物理实体上,也可以物理上分开。且这些模块可以全部以软件通过处理元件调用的形式实现;也可以全部以硬件的形式实现;还可以部分模块通过处理元件调用软件的形式实现,部分模块通过硬件的形式实现。例如,处理模块502可以为单独设立的处理元件,也可以集成在上述装置的某一个芯片中实现,此外,也可以以程序代码的形式存储于上述装置的存储器中,由上述装置的某一个处理元件调用并执行以上处理模块502的功能。其它模块的实现与之类似。此外这些模块全部或部分可以集成在一起,也可以独立实现。这里所述的处理元件可以是一种集成电路,具有信号的处理能力。在实现过程中,上述方法的各步骤或以上各个模块可以通过处理器元件中的硬件的集成逻辑电路或者软件形式的指令完成。
[0082]
例如,以上这些模块可以是被配置成实施以上方法的一个或多个集成电路,例如:一个或多个特定集成电路(application specific integrated circuit,简称asic),或,一个或多个微处理器(digital signal processor,简称dsp),或,一个或者多个现场可编程门阵列(field programmable gate array,简称fpga)等。再如,当以上某个模块通过处理元件调度程序代码的形式实现时,该处理元件可以是通用处理器,例如中央处理器(central processing unit,简称cpu)或其它可以调用程序代码的处理器。再如,这些模块可以集成在一起,以片上系统(system-on-a-chip,简称soc)的形式实现。
[0083]
如图6所示,展示本技术于一实施例中的计算机设备的结构示意图,如图所示,所述计算机设备600包括:存储器601、处理器602、及通信器603。所述存储器601存储有数据传输程序,所述处理器602执行所述数据传输程序实现如图3所述的基于物品簇级多目标优化的物品推荐方法;所述通信器603通信分别通信连接用于对数据集存储与预处理的数据库、用于web内容推荐的客户端。
[0084]
例如,数据库主要进行数据集的存储、预处理和数据流的生成,可采用sqlite数据库进行实现;web内容推荐客户端的功能包括用户登录,推荐结果的展示和用户行为的日志记录。本设备600主要进行推荐模型和算法框架的执行,可应用在公网进行了部署,在目前较为普遍的百兆无线网络带宽条件和100-300的并发数下,平均推理延时在30-50ms,页面平均刷新延时在80-100ms,具有良好的应用体验。
[0085]
所述存储器601可能包含随机存取存储器(random access memory,简称ram),也
可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
[0086]
所述处理器602可以是通用处理器,包括中央处理器(central processing unit,简称cpu)、网络处理器(network processor,简称np)等;还可以是数字信号处理器(digital signal processing,简称dsp)、专用集成电路(application specific integrated circuit,简称asic)、现场可编程门阵列(field-programmable gate array,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
[0087]
所述通信器603用于实现其他设备(例如客户端、控制器、读写库和只读库)之间的通信连接。其可包含一组或多组不同通信方式的模块。所述通信连接可以是一个或多个有线/无线通讯方式及其组合。通信方式包括:互联网、can、内联网、广域网(wan)、局域网(lan)、无线网络、数字用户线(dsl)网络、帧中继网络、异步传输模式(atm)网络、虚拟专用网络(vpn)和/或任何其它合适的通信网络中的任何一个或多个。例如:wifi、蓝牙、nfc、gprs、gsm、及以太网中任意一种及多种组合。
[0088]
于本技术的一实施例中,一种计算机可读存储介质,其上存储有数据传输程序,该数据传输程序被处理器执行时实现如图3所述的基于物品簇级多目标优化的物品推荐方法。
[0089]
综上所述,本技术提供一种基于物品簇级多目标优化的物品推荐方法及装置和设备,有效克服了现有技术中的种种缺点而具高度产业利用价值。
[0090]
上述实施例仅例示性说明本技术的原理及其功效,而非用于限制本技术。任何熟悉此技术的人士皆可在不违背本技术的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本技术所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本技术的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1