一种用于深度学习目标检测的动态训练方法
1.本发明涉及深度学习技术领域,特别地,涉及一种用于深度学习目标检测的动态训练方法。
背景技术:
2.根据对学习的监督程度,深度学习分为有监督学习、弱监督学习和无监督学习三种。近年来随着人工智能领域硬件和软件的不断提升,有监督深度学习技术得到了飞速发展。深度学习技术已运用在各个领域,比如计算机视觉、自然语言处理、音频分析等。基于图像的目标检测技术属于深度学习在计算机视觉领域的一个应用。有监督深度学习目标检测需要大量训练样本驱动,训练样本的难度和质量在很大程度上已决定了学习速度和质量。训练样本包括正训练样本和负训练样本,通常在一幅图像里,恰好覆盖检测目标的候选区域(或者称为感兴趣区域,简记为roi)属于正样本,而与目标区域(ground truth)完全不重叠的所有区域都属于负样本。而实际情况往往并非如此,roi与ground truth可能相交,但不完全重叠。因此,研究者们提出用交并比(iou)及其阈值来判定正、负样本。iou是指roi与ground truth的交集面积和并集面积之比。iou大于某个阈值的roi定义为正样本,而小于某个阈值的roi判定为负样本。定义了正、负样本后,采用哪些样本来训练目标检测模型,即抽样训练样本,对训练效率和质量也至关重要。
3.例如任少卿等人在faster-rcnn的第二阶段网络训练中采取了以下训练方法:与所有ground truth的iou的最大值(iou
max
)不小于0.5的roi定义为正样本,iou
max
∈(0,0.5)的roi定义为负样本,而iou
max
=0的roi(即纯背景)定义为中性样本;如果样本充足,随机抽样出训练样本,同时保证正、负训练样本均衡;如果正样本不足时,可重复抽样,对于负样本也是如此;如果没有正样本,则终止训练。而ross girshick在fast-rcnn的训练中采取了以下训练方法:iou
max
不小于0.5的roi定义为正样本;而iou
max
∈[0.1,0.5)的roi定义为负样本,iou
max
∈[0,0.1)的定义为中性样本,不参与训练;如果训练样本充足,随机采样训练样本,同时保证正、负训练样本均衡;如果正样本不足时,可重复抽样,对于负样本也是如此;如果没有正样本,则终止训练。
[0004]
但上述两种训练方法并非最优的。首先,这两种训练方法对正、负样本的定义的阈值没有间隔,也就是没有明确分离正、负样本,iou
max
在0.5附近的正样本和负样本容易混淆,不利于网络学习;其次,它们采样时过分强调正、负样本平衡,而不能充分利用已有的目标区域;第三,它们不能充分利用背景图像(即无目标区域的图像)训练模型,缩小了模型视野,如此会带来较多的误报;第四,它们产生的训练样本难度大,难以训练基于深度学习的目标检测模型。
技术实现要素:
[0005]
本发明的目的在于提供一种用于深度学习目标检测的动态训练方法,以解决背景技术中提出的问题。
[0006]
为实现上述目的,本发明提供了一种用于深度学习目标检测的动态训练方法,包括以下步骤:
[0007]
s1、提取图像中的目标区域和忽略区域;
[0008]
s2、分别计算候选区域与每个目标区域的交并比iou,并分别计算候选区域与每个忽略区域的相交面积在候选区域中的占比a;
[0009]
s3、根据所有的正样本iou、负样本iou、占比a及正样本iou的阈值t
p
、负样本iou的阈值tn、占比a的阈值ta定义候补负样本、负样本、正样本、候补正样本和中性样本:最大交并比(iou
max
)小于0.05,且最大a(a
max
)小于ta的候选区域定义为候补负样本;iou
max
∈[0.05,tn),且a
max
小于ta的候选区域定义为负样本;iou
max
∈(tn,t
p
),且a
max
小于ta的候选区域定义为与之匹配的目标区域对应类别的候补正样本;iou
max
∈[t
p
,1]的候选区域定义为与之匹配的目标区域对应类别的正样本;其余候选区域定义为中性样本;
[0010]
s4、统计候补负样本、负样本、正样本和候补正样本的数量,分别表示为n
cn
、nn、n
p
、n
cp
,并计算每个非中性样本的难度系数cd和质量系数cq;其中,非中性样本是指候补负样本、负样本、正样本和候补正样本;
[0011]
s5、采样高质量训练样本:根据非中性样本的质量系数由高到低,按正样本、负样本、候补正样本的优先级顺序选取一小批量nb个训练样本;如果以上样本量不足nb个,则再随机选出部分候补负样本作为负训练样本,以补足nb个训练样本;
[0012]
s6、根据训练损失收敛情况,逐步改变tn和t
p
的设置,以改变正样本与负样本之间的差距,从而动态产生不同难度和质量的训练样本,用于训练基于深度学习的目标检测模型。
[0013]
进一步的,所述步骤s1中:忽略区域是指目标区域以外的其它注释区域,它们与目标具有相似性,可能干扰训练。
[0014]
进一步的,所述步骤s3中:为避免干扰,中性样本不参与训练;所述占比a的阈值ta=0.5;所述正样本iou的阈值t
p
∈[0.5,0.7];所述负样本iou的阈值tn∈[0.25,0.5]。
[0015]
进一步的,所述步骤s4中的非中性样本的难度系数cd和质量系数cq计算公式为:
[0016][0017]cq
=1-2|c
d-0.25|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)。
[0018]
进一步的,所述步骤s6中逐步改变tn和t
p
的设置的具体方法为:s6.1、tn取最小值,而t
p
取最大值,以最大的正、负样本间隔产生难度最小的训练样本,快速训练模型至总损失连续5个回合都不下降;s6.2、继续训练模型,如果负训练样本的训练损失增幅连续3个回合都小于5%,则以0.01的微量增大tn,反之则以0.01的微量减小tn;如果正训练样本的训练损失增幅连续3个回合都小于5%,则以0.01的微量减小t
p
,反之则以0.01的微量增大tn。本发明的动态训练方法以先易后难、保证质量为指导思想,分阶段动态产生不同难度和质量的训练样本,充分利用数据集中的注释和背景图像,使模型训练高效、低损和强泛化。
[0019]
相比于现有技术,本发明具有以下有益效果:充分利用现有的数据,先难后易、保证质量,加快训练速度,降低训练损失,提升模型泛化能力,最终降低目标检测的漏检率和误报率。
[0020]
本发明的用于深度学习目标检测的动态训练方法,明确提出了候补样本概念。按非中性样本的质量高低,先后从正样本和负样本中分别挑选出正、负训练样本,提高训练样本质量;当训练样本总量不足小批量数nb时,再按质量高低从候补正样本中挑选出质量较差的正训练样本,兼顾正、负训练样本平衡;当训练样本总量还是不足时,则从候补负样本中随机选取部分作为负训练样本,补足训练样本;当无正样本可用时,允许仅使用候补负样本来继续训练,以开阔模型视野,减少误报。在训练过程中,以先易后难、保证质量为指导思想,逐步改变正样本iou、负样本iou的阈值tn和t
p
的设置,从而改变正、负训练样本之间的差距,进而动态产生不同难度和质量的训练样本,充分利用数据集中的注释区域和背景图像,使模型训练高效、低损和强泛化,最终降低目标检测的漏检率和误报率。
[0021]
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
[0022]
构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0023]
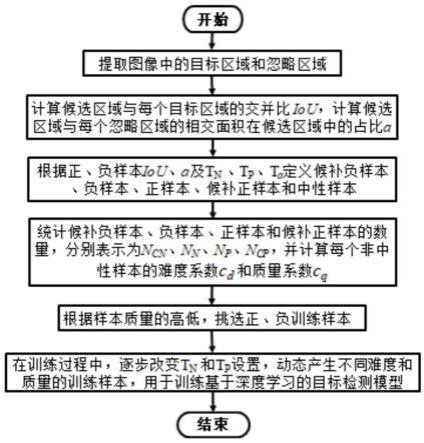
图1是本发明一种用于深度学习目标检测的动态训练方法的总流程示意图;
[0024]
图2是本发明一种用于深度学习目标检测的动态训练方法的步骤s3细化流程示意图;
[0025]
图3是本发明一种用于深度学习目标检测的动态训练方法的步骤s5细化流程示意图。
具体实施方式
[0026]
以下结合附图对本发明的实施例进行详细说明,但是本发明可以根据权利要求限定和覆盖的多种不同方式实施。
[0027]
请参见图1、图2和图3,本实施例提供一种用于深度学习目标检测的动态训练方法。因在训练过程中分阶段产生不同难度和质量的训练样本实现动态训练,故称之为动态训练方法,该方法包括以下步骤:
[0028]
s1、提取图像中的目标区域和忽略区域;其中,忽略区域是指目标区域以外的其它注释区域,它们与目标具有相似性,用于产生中性样本,避免干扰训练。
[0029]
s2、分别计算候选区域与每个目标区域的交并比iou,并分别计算候选区域与每个忽略区域的相交面积在候选区域中的占比a。
[0030]
s3、根据步骤s2中计算出的所有的正样本iou、负样本iou、占比a以及正样本iou的阈值t
p
、负样本iou的阈值tn、占比a的阈值ta来定义候补负样本、负样本、正样本、候补正样本和中性样本:最大交并比(iou
max
)小于0.05,且最大a(a
max
)小于ta的候选区域定义为候补负样本;iou
max
∈[0.05,tn),且a
max
小于ta的候选区域定义为负样本;iou
max
∈(tn,t
p
),且a
max
小于ta的候选区域定义为与该候选区域交并比最大的目标区域对应类别的候补正样本;iou
max
∈[t
p
,1]的候选区域定义为与该候选区域交并比最大的目标区域对应类别的正样本;其余候选区域定义为中性样本。优选的,ta为a的阈值,通常取ta=0.5,t
p
为正样本iou阈值,取t
p
∈[0.5,0.7];tn为负样本iou阈值,取tn∈[0.25,0.5]。
[0031]
s4、统计候补负样本、负样本、正样本和候补正样本的数量,分别表示为n
cn
、nn、n
p
、n
cp
,并计算每个非中性样本的难度系数cd和质量系数cq。优选的,样本难度系数cd和质量系数cq计算公式为:
[0032][0033]cq
=1-2|c
d-0.25|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)。
[0034]
s5、采样高质量训练样本:根据非中性样本质量系数的高低,按正样本、负样本、候补正样本的优先级顺序选取一小批量nb个训练样本;具体可以细分为几种情况:
[0035]
(1)、若正样本数量n
p
大于等于训练样本数量nb,则选取nb个质量排名靠前的正样本作为正训练样本;
[0036]
(2)、若正样本数量n
p
小于训练样本数量nb,且训练样本数量nb与正样本数量n
p
之差大于负样本数量nn,则先选取所有正样本作为正训练样本,再选取(n
b-n
p
)个质量排名靠前的负样本作为负训练样本;
[0037]
(3)、若正样本数量n
p
与负样本数量nn之和小于训练样本数量nb,且训练样本数量nb与正样本数量n
p
以及负样本数量nn之差大于候补正样本数量n
cp
,则先选取所有正样本作为正训练样本,再选取所有负样本作为负训练样本,最后再选取(n
b-n
p-nn)个质量排名靠前的候补正样本作为正训练样本;
[0038]
(4)、若正样本数量n
p
、负样本数量nn以及候补正样本数量n
cp
三者之和小于训练样本数量nb,也即正样本、负样本和候补正样本的总数量不足nb个,则在全选上述三种样本后,再随机选出部分候补负样本作为负训练样本,以补足nb个训练样本。小批量训练样本包括正训练样本和负训练样本,在一种具体的实施方式中,其总数量nb取32个。
[0039]
s6、根据训练损失收敛情况,逐步改变tn和t
p
的设置,改变正、负样本之间的差距,动态产生不同难度和质量的训练样本,用于训练基于深度学习的目标检测模型。优选的,动态训练过程中的逐步改变tn和t
p
(即正样本iou的阈值和负样本iou的阈值)设置方法为:(1)、tn取最小值,而t
p
取最大值,以最大的正、负样本间隔产生难度最小的训练样本,快速训练模型至总损失连续5个回合都不下降;(2)、继续训练模型,如果负训练样本的训练损失增幅连续3个回合都小于5%,则以0.01的微量增大tn,反之则以0.01的微量减小tn;如果正训练样本的训练损失增幅连续3个回合都小于5%,则以0.01的微量减小t
p
,反之则以0.01的微量增大tn。本发明的动态训练方法以先易后难、保证质量为指导思想,分阶段动态产生不同难度和质量的训练样本,充分利用数据集中的注释和背景图像,使模型训练高效、低损和强泛化。
[0040]
如表1所示,对比了本发明方法与现有技术的fast-rcnn训练方法以及faster-rcnn训练方法在目前最大的夜间行人数据集nightowls的验证集上的训练速度和训练损失,及nightowls的验证集上的mr-2
漏检率。其中,mr-2
漏检率指标是9个fppi(每张图像的平均误报量)处的漏检率(mr)均值,这9个fppi以对数空间均匀分布在[10-2
,100]范围内。mr-2
是目前最受欢迎的单目标检测评估性能指标,因为它综合考虑了代表安全的漏检率和代表效率的误报率,mr-2
取值越低越好。三种方法都为faster-rcnn的第二阶段提供训练样本和方法。这三种训练方法均采用带动量的小批量随机梯度下降算法从零开始训练模型,其动
量系数和衰减因子分别为0.9和0.0005;学习率(η)初始值设为0.01,并采用以下策略更新η:如果训练损失在连续5个回合内均不下降,则将η缩小10倍;如果η降至1e-10,则终止训练。
[0041]
表1不同训练样本的训练速度、训练损失和mr-2
漏检率对比
[0042][0043]
由表1中的数据可知,本发明方法在训练速度、训练损失和模型泛化能力(即mr-2
漏检率更低)方面都明显优于faster-rcnn和fast-rcnn的训练方法。
[0044]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1