一种基于云计算的人工智能训练方法及系统与流程
1.本发明涉及计算机人工智能训练技术领域,特别是涉及一种基于云计算的人工智能训练方法及系统。
背景技术:
2.随着信息技术发展到海量数据的阶段,人工智能技术也得到迅速的发展。特别是,深度学习的逐渐成熟,更多的数据特征由人工智能算法自行挖掘,并产生极大的价值。然而,目前的深度学习对于图形、声音等非结构性数据处理能发挥优异的特性,能实现准确率的智能识别,但对于推送信息、用户画像和用户决策等结构化数据,人工智能算法预测的结果,则往往难以解释,也难以展现出稳定的关联性。
3.目前,人工智能在推送信息和用户决策上的应用是文字、声音、图像和操纵等的识别,而人工智能在用户画像的应用则在海量用户信息中提取特征,由众多特征的确定用户手机使用习惯,并进行标签。对于识别之后的数据应用采用的处理方式,一般则是人工分析后的模型,进行的内容标签和用户标签之间的匹配而得出决策。同时,随着互联网的高速发展,用户个人信息被泄露的事件增加,相关保护用户隐私的法规也会越来越严格。因此,基于人工智能应用,在隐私数据得到保护决策具有可解释性的前提下,如何实现提高用户对内容推送的体验成为需要解决的问题。
技术实现要素:
4.为解决现有技术存在的缺陷,本发明的主要目的在于提供一种基于云计算的人工智能训练方法及系统,可实现利用人工智能进行决策的预测,
5.为了实现上述目的,本发明采用如下的技术方案:
6.在第一方面,本发明是一种基于云计算的人工智能训练方法,包括:在终端中,设置有分类模型和第一预测模型,其中,所述分类模型已训练,并通过在分类模型中输入分类参数以此生成分类结果,再将分类结果发送至云计算端,所述终端借助本地获取的输入预测参数与输出决策参数对第一预测模型进行训练;
7.在云计算端中,至少针对分类结果为相同某类的所述终端设置有第二预测模型,获取众多的输入预测参数和输出决策参数作为训练数据,第二预测模型将训练数据按照特征进行划分,按照特征分布设置梯度适应,按照梯度适应计算出第二预测模型的权重;将云计算端的所述第二预测模型的权重共享于输出决策参数相同的终端的所述第一预测模型,所述第一预测模型借助共享的权重进行模型训练。
8.上述方法可选有,在终端中,所述输入预测参数包含但不仅包含分类参数,所述云计算端根据分类结果生成分类参数的模拟参量;所述第二预测模型借助包含所述模拟参量的输入预测参数作为输入进行模型训练,所述第一预测模型借助包含分类参数的所述输入预测参数作为输入进行模型训练。
9.上述方法进一步有,所述分类参数包含隐私数据,所述终端仅发送不包含隐私数
据部分的输入预测参数。
10.上述方法可选有,还包括:在第一预测模型训练进行阶段,运营端按照第二预测模型的决策信息推送内容信息,在第一预测模型训练完成阶段,运营端按照第一预测模型预测的输出决策参数推送内容信息。
11.上述方法进一步有,在第一预测模型训练进行阶段,按照该终端相邻两次获取内容信息的时间为界限采集输入预测参数,当输入预测参数满足第一预测模型的输入要求进行一次训练并迭代,直至第一预测模型的损失参数满足预设要求时将第一预测模型设置为训练完成阶段。
12.上述方法进一步有,所述的第一预测模型的损失参数满足预设要求包括: 所述第一预测模型的损失参数相比于与其对应的第二预测模型的损失参数的差异在设定范围内。
13.上述方法可选有,述第一预测模型和第二预测模型的输入数据架构相同的决策树模型,所述分类模型为类聚模型。
14.在第二方面,本发明是一种基于云计算的人工智能训练系统,包括设置有分类模型和第一预测模型的终端,以及设置有第二预测模型的云计算端;所述分类模型包括:参数采集单元,用于获取分类参数;分类单元,用于根据分类参数生成分类结果;参数输出单元,用于将分类结果发送到云计算端;所述第一预测模型包括:第一预测采集单元,用于获取终端本地的输入预测参数和输出决策参数;第一预测单元,用于借助本地的输入预测参数和输出决策参数进行训练;所述第二预测模型包括:第二预测采集单元,用于获取众多的分类结果为相同某类的所述终端的输入预测参数和输出决策参数;第二预测单元,用于将输入预测参数和输出决策参数按照特征进行划分,按照特征分布设置梯度适应,按照梯度适应计算出第二预测模型的权重;共享单元,用于按照第二预测单元的权重更新分类结果相同的所述终端的第一预测单元的权重。
15.上述系统可选有,所述第一预测采集单元获取包含但不仅包含分类参数的输入预测参数,所述第二预测采集单元获取的输入预测参数不包含分类参数部分;所述第二预测模型还包括:参量生成单元,用于按照分类结果生成分类参数的模拟参量;所述第二预测单元借助包含所述模拟参量的输入预测参数作为输入进行模型训练。
16.上述系统可选有,还包括运营端,所述运营端包括推送模块;所述推送模块,用于在第一预测模型训练进行阶段按照第二预测模型的输出决策参数推送内容信息,在第一预测模型训练完成阶段按照第一预测模型预测的输出决策参数推送内容信息。
17.与现有技术相比,本发明有益效果如下:
18.(1)本发明通过在终端中分别设置用于分类模型和第一预测模型,并且在云计算端为分类结果为某类且相同的终端设置第二预测模型,第二预测模型采用大数据进行训练,能采用神经网络等复杂模型结果进行特征的深度挖掘;而设在终端本地的模型虽然数据量较小,但能参考第二预测模型的共享权值为起点进行训练,并且更为贴合本地的数据,做出反应更为灵敏的决策;同时,第二预测模型是采用分类结果类别相同的情况作为训练输入的,使第一预测模型和第二预测模型之间的特征关联度高,使第一预测模型的训练更为快速、拟合度高和数据损失少;再者,云计算端和终端仅传输分类结果、输入预测参数和输出决策参数,可免去分类参数的上传,以保护隐私数据。
19.(2)本发明进一步的有益效果有:终端将隐私数据作为分类模型的输入,但仅上传
分类结果,而不上传分类参数。当部分参数需要作为第二预测模型的输入时,利用分类结果估算出模拟参量用作第二预测模型的输入。
20.(3)本发明进一步的有益效果有:利用运营端生成推送内容影响在训练进行阶段的第一预测模型,使的在终端中形成帮助第一预测模型训练的数据,由于第二预测模型在大量数据下做出的决策结果能提高准确度的预测,因此第一预测模型能在推送内容信息下产生足够多的数据量用于终端的训练。
21.下面结合附图对本发明作进一步的说明。
附图说明
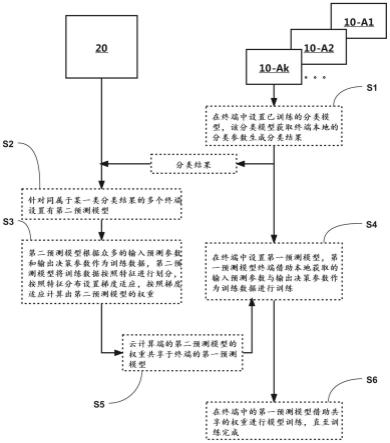
22.图1为本发明实施例的基于云计算的人工智能训练方法的流程示例图。
23.图2为本发明实施例的基于云计算的人工智能训练方法的数据通讯架构图。
24.图3为本发明实施例的基于云计算的人工智能训练方法的数据关系图。
25.图4为本发明实施例的基于云计算的人工智能训练方法的局部流程示意图。
具体实施方式
26.为更好的说明本发明的目的、技术方案和优点,下面结合附图和实施例对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不作为限制本发明的范围。
27.如图1所示,根据本发明第一方面的实施例,是一种基于云计算的人工智能训练方法。该方法包括:
28.s1、在终端10中设置已训练的分类模型,该分类模型获取终端10本地的分类参数生成分类结果;并将分类结果发送至云计算端20;
29.s2、在云计算端20中,获取众多终端10的分类结果,针对同属于某一类分类结果的多个终端10设置有第二预测模型;若分类模型由n类的分类结果,则设置有n个独立的第二预测模型;
30.s3、第二预测模型根据众多的输入预测参数和输出决策参数作为训练数据,第二预测模型将训练数据按照特征进行划分,按照特征分布设置梯度适应,按照梯度适应计算出第二预测模型的权重。其中,一独立的第二预测模型所获取的训练数据来自与同一类分类结果的终端10。
31.s4、在终端10中设置第一预测模型,第一预测模型终端10借助本地获取的输入预测参数与输出决策参数作为训练数据进行训练。其中,第一预测模型和第二预测模型的输入数据架构相同的模型。
32.s5、云计算端20的第二预测模型的权重共享于终端10的第一预测模型;其中,第二预测模型所对应的分类结果与该终端10所输出的分类结果相一致。
33.s6、在终端10中的第一预测模型借助共享的权重进行模型训练,直至训练完成。
34.值得说明的是,本实施例在终端10中的分类模型对本地分类参数进行特征划分,使得按照分类结果对众多的终端10分别进行差异化的数据处理,同一类别的终端10具有行为和决策的相似性,使得后决策的预测模型较强的拟合性能;本实施例在云计算端20设置了第二预测模型,由于获取的数据量大,可基于神经网络进行特征的深度挖掘和划分,得出
分类结果相同的多个终端 10都能拟合且损失较小的决策结果,分类结果信息与第二预测模型做出的决策和挖掘的特征之间具有关联性和可解释性;本实施例在终端10中设置第一预测模型,第一预测模型共享第一预测模型的权重,在此基础上进行迭代,具有快速的特性。特别地是,云计算端20和终端10之间仅传输部分数据,而最终决策的预测在终端10完成,可实现隐私数据保护。
35.如图2所示,本实施例中的人工智能训练方法具体地,在各终端10中的分类模型可以计作y*=f(x*)的分类函数,其中,y*表示分类结果,y*是有限的标签集合{a、b、
…
},x*表示分类的参数,x*是输入到分类函数的分类参量。分类模型的分类函数包含但不限于采用朴素贝叶斯、svm支持向量机、k临近算法或随机森林,通过分类函数的构建形成类聚模型。为了获取分类参量x*,还可以采用文字、图片和语音等的前置的识别模型。云计算端20可获取各终端10的分类结果y*。其中,针对y*=a的终端10,设置标记为a的第二预测模型,该第二预测模型获取所述分类结果为标签a的终端10的输入预测参数 [x
1a
、x
2a
、
…
、x
ka
]和输出决策参数[y
1a
、y
2a
、
…
、y
ka
],以ya=l(xa)的预测模型进行训练和预测。其中,针对y*=b的终端10,设置标记为b的第二预测模型,该第二预测模型获取所述分类结果为标签b的终端10的输入预测参数[x
1b
、x
2b
、
…
、x
kb
]和输出决策参数[y
1b
、y
2b
、
…
、y
kb
],以yb=l(xb)的预测模型进行训练和预测。当分类结果为其他,则依次类推。第二预测模型的预测函数包含但不限于softmax函数、贝叶斯分类函数和感知机等构建深度神经网络进行数据特征的提取,并根据数据特征形成决策树模型。第一预测模型采用本地的数据,对于标记为k的终端10,该第一预测模型采用xk作为输入预测参量,采用yk作为输入决策参量。第一预测模型具有与第二预测模型相同输入数据架构,并且,标记为a的第二预测模型将其权重[ωa]将共享到所有y*=a的终端10 对应的第一预测模型的权重。
[0036]
值得说明的是,常见的用户画像需要获取大量用户的隐私数据信息进行分类训练,但实际上这些模型已经具有较为准确的提取信息,并具备智能分类的能力。而本实施例采用终端10本地的分类参量进行智能分类,仅需要上传分类的结果即可,分类结果已经经过高度的抽象化,后续无法反向推导,同时分类结果也具有专用型,同时不具备追溯可能性,从而提高信息的安全性。
[0037]
如图3所示,本实施例的众多终端10和云计算端20的数据架构示意图。在第k个终端10中,分类模型获取分类参数xk*并生成分类结果yk*,第一预测模型获取输入预测参数xk和输出决策参数yk用作训练数据。同时在云计算端20中获取第k个终端10的数据。具体地,分类参数xk*包含有隐私数据,输入预测参数xk包含有部分的分类参数xk*,同时包含分类参数xk*中的部分隐私数据xs*。第k个终端10在给云计算端20发送数据时仅发送不包含xs*的部分xk数据,记作(x
k-xs*)。第k个终端10还发送分类结果yk*,云计算端20 根据yk*估算出与xs*有近似关联的模拟参量xs。第二预测模型借助(x
k-xs*) 数据和xs数据作为输入预测参数进行训练。
[0038]
值得说明的是,该数据架构通过估算xs*,使第二预测模型在训练过程中具有裕度跟高的数据,同时避免获取终端10中的隐私数据。在估算xs*的过程中还可以采取在满足yk不变的基础上,生成随机参量作为模拟参量xs,从而达到提高数据结构离散型的目的。
[0039]
如图4所示,本实施例的人工智能训练方法还借助运营端30进行训练。
[0040]
该方法还包括:
[0041]
s71、在第一预测模型训练完成阶段有,在云计算端20中,已经训练的第二预测模型获取各终端10的输入预测参数生成决策结果,并将决策结果发送到运营端30。具体地,针对y*=a,第二预测模型生成决策结果,如内容信息的标签匹配于a类型的用户。已经训练的第二预测模型可将损失参数控制在有价值的范围内,由于共享参数的存在,第一预测模型可以在此基础上较为合理的损失参数。同时,第一预测模型对本地终端10的数据十分贴合,可得出响应速度更快的决策结果。
[0042]
s72、在第一预测模型训练完成阶段有,按照第二预测模型的决策结果信息选择相匹配的内容信息,将该内容信息推送给终端10。具体地,a类型的终端10关注推送内容信息获取前后包括用户操作内容等信息作为输入预测参量,并且获取用户是否对推送内容信息进行决策作为输出决策参量。借此,第一预测模型利用共享的权重,对输入预测参量和输出决策参量之间的拟合程度进行计算,获取损失参数。对第一预测模型以梯度下降为目的地进行多次迭代。其中,第一预测模型可以在获取推送内容的时间维度上选取输入预测参量,以增加数据量级,并提高数据与决策之间的关联。当终端10中第一预测模型的损失参数相比于与其对应的第二预测模型的损失参数的差异在设定范围内,则可以确定第一预测模型具有运行的价值,完成该终端10的人工智能训练。
[0043]
s81、在第一预测模型训练完成阶段有,第一预测模型对本地的输入预测测量进行预测,生成决策结果并发送给运营端30。具体地,由于第一预测模型已经训练,当在终端10中用户产生某种特征的行为,并通过输入预测参量被第一训练模型所获取,可得出决策结果。
[0044]
s82、在第一预测模型训练完成阶段有,按照第二预测模型的决策结果信息选择相匹配的内容信息,将该内容信息推送给终端10。可以理解的是,决策结果是终端10产生的,贴合终端10中用户的行为操作,具有高效性。同时,针对y*=a的多个终端10,其产生的决策结果可以有偏差,形成更为个性化的决策结果。
[0045]
根据本发明第二方面的实施例,是一种基于云计算的人工智能训练系统,包括设置有分类模型和第一预测模型的终端10,设置有第二预测模型的云计算端20,以及可形成推送内容信息的运营端30。
[0046]
分类模型由参数采集单元11、分类单元12和参数输出单元13组成。其中,参数采集单元11用于获取分类参数,分类单元12用于根据分类参数生成分类结果,参数输出单元13用于将分类结果发送到云计算端20。
[0047]
第一预测模型由第一预测采集单元101和第一预测单元102组成。其中,第一预测采集单元101用于获取终端10本地的输入预测参数和输出决策参数,第一预测单元102用于借助本地的输入预测参数和输出决策参数进行训练。
[0048]
第二预测模型由第二预测采集单元21、第二预测单元22和共享单元23 组成。其中,第二预测采集单元21用于获取众多的分类结果为相同某类的终端10的输入预测参数和输出决策参数,第二预测单元22用于将输入预测参数和输出决策参数按照特征进行划分,按照特征分布设置梯度适应,按照梯度适应计算出第二预测模型的权重,共享单元23用于按照第二预测单元22的权重更新分类结果相同的终端10的第一预测单元102的权重。运营端30由推送模块31组成;推送模块31用于在第一预测模型训练进行阶段按照第二预测模型的输出决策参数推送内容信息,在第一预测模型训练完成阶段按照第一预测模型预测的输
出决策参数推送内容信息。
[0049]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本发明所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom (eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink) dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0050]
在一个实施例中,上述的云计算端20和运营端30可以是服务器。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端10通过网络连接通信。该计算机程序被处理器执行时以实现一种联邦模型训练方法。
[0051]
在一个实施例中,上述的终端10可以是手机,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述实施例中联邦模型训练方法。
[0052]
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
[0053]
以上实施例主要描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1