视频浓缩中背景图像的生成方法与流程
1.本发明属于计算机视觉、路况监控技术领域,具体涉及一种视频浓缩中背景图像的生成方法。
背景技术:
2.视频浓缩video synopsis,是对视频内容的一个简单概括,以自动或半自动的方式,通过对视频中的运动目标进行算法分析,提取运动目标,然后对各个目标的运动轨迹进行分析,将不同的目标拼接到一个共同的背景场景中,并将其以某种方式进行组合,生成新的浓缩后视频的一种技术。
3.因此,在视频浓缩时,生成背景图像是关键基础步骤。现有的背景图像生成方法是:采用背景建模技术判断视频中是否存在静止图像帧,如果存在,则将静止图像帧序列中的第一个静止图像帧,作为背景图像;否则,对背景建模得到的候选背景图像进行一定的处理,从而得到背景图像。
4.以上方法过于依赖背景建模技术,而背景建模只能获取到每个图像帧中的运动物体作为前景目标,而且精度不高,因此存在问题如下:1.该方法遗漏前景目标的概率较高,导致生成的背景图像中残留前景目标的可能性较大;2.该方法只能针对运动物体作为前景目标进行前景目标检测,不能针对特定类型的非运动目标,可能遗漏短暂静止的前景目标,导致生成的背景图像中残留前景目标;3.如果存在多张静止图像帧,该方法只采用第一张作为背景图像,没有利用多张静止图像帧的信息,生成的背景图像中残留前景目标的可能性较高。
技术实现要素:
5.针对现有技术存在的缺陷,本发明提供一种视频浓缩中背景图像的生成方法,可有效解决上述问题。
6.本发明采用的技术方案如下:
7.本发明提供一种视频浓缩中背景图像的生成方法,包括以下步骤:
8.步骤1,视频包括p张图像帧,按序依次表示为:图像帧s1,图像帧s2,...,图像帧s
p
;
9.步骤2,对于每张图像帧su,u=1,2,...,p,均执行步骤2.1-步骤2.5,得到图像帧su的目标框集合h
su
={目标框h
su
(1),目标框h
su
(2),...,目标框h
su
(z(u))};其中,z(u)代表图像帧su包括的目标框的数量;
10.步骤2.1,利用目标检测模型,对图像帧su进行特定目标检测,得到目标框集合h1;
11.其中,如果图像帧su中未检测到特定目标,则目标框集合h1为空;如果在图像帧su中检测到存在n1个特定目标,每个特定目标对应一个目标框,由此检测到n1个目标框,因此,目标框集合h1中包括n1个目标框;
12.步骤2.2,利用目标跟踪模型,对图像帧su进行特定目标跟踪,得到目标框集合h2;
13.其中,如果图像帧su中未跟踪到特定目标,则目标框集合h2为空;如果在图像帧su中跟踪到存在n2个特定目标,每个特定目标对应一个目标框,由此跟踪到n2个目标框,因此,目标框集合h2中包括n2个目标框;
14.步骤2.3,利用背景建模技术,对图像帧su进行运动物体目标检测,得到目标框集合h3;
15.其中,如果图像帧su中未检测到存在运动物体目标,则目标框集合h3为空;如果在图像帧su中检测到存在n3个运动物体目标,每个运动物体目标对应一个目标框,由此检测到n3个目标框,因此,目标框集合h3中包括n3个目标框;
16.其中,对于目标框集合h1、目标框集合h2和目标框集合h3中的每个目标框,均具有以下属性:(x0,y0,w0,h0),(x0,y0)代表目标框的中心点在图像帧su中的坐标;w0和h0分别代表目标框的宽度和高度;
17.步骤2.4,对目标框集合h1和目标框集合h2进行合并操作,得到合并目标框集合h
12
:
18.步骤2.4.1,合并目标框集合h
12
初始为空;
19.步骤2.4.2,将目标框集合h1中的所有目标框,以及目标框集合h2中的所有目标框,均加入到合并目标框集合h
12
中,由此得到合并目标框集合h
12
;
20.步骤2.4.3,对步骤2.4.2得到的合并目标框集合h
12
进行去冗余操作,得到最终的合并目标框集合h
12
:
21.去冗余操作为:
22.对于目标框集合h2中的每个目标框,表示为:目标框h2,计算其与目标框集合h1中的各个目标框的重叠度iou,如果存在重叠度iou》ε的情况,则将目标框h2作为冗余目标框,从步骤2.4.2得到的合并目标框集合h
12
中,删除该目标框h2;否则,保留该目标框h2;
23.步骤2.5,对合并目标框集合h
12
和目标框集合h3进行合并操作,得到最终的目标框集合h
su
:
24.步骤2.5.1,目标框集合h
su
初始为空;
25.步骤2.5.2,将合并目标框集合h
12
中的所有目标框,以及目标框集合h3中的所有目标框,均加入到目标框集合h
su
,由此得到目标框集合h
su
;
26.步骤2.5.3,对步骤2.5.2得到的目标框集合h
su
进行去冗余操作,得到最终的目标框集合h
su
:
27.去冗余操作为:
28.对于合并目标框集合h
12
中的每个目标框,表示为目标框h
12
,判断其是否被目标框集合h3中的某个目标框完全包含,如果是,则从目标框集合h
su
中删除该目标框h
12
;否则,保留该目标框h
12
;
29.对于目标框集合h3中的每个目标框h3,判断其是否被合并目标框集合h
12
中的某个目标框完全包含,如果是,则从目标框集合h
su
中删除该目标框h3;否则,保留该目标框h3;
30.步骤3,背景候选图的生成:
31.对于图像帧s1,得到的目标框集合h
s1
包括z(1)个目标框;
32.对于图像帧s2,得到的目标框集合h
s2
包括z(2)个目标框;
33.依此类推
34.对于图像帧s
p
,得到的目标框集合h
sp
包括z(p)个目标框;
35.在z(1),z(2),...,z(p)中,选择最小值,表示为:z(min),一共包括z(min)个目标框的图像帧依次为:图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
,其中,n1为具有z(min)个目标框的图像帧的数量;
36.如果z(min)=0,表明图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
中均不具有目标框,将图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
作为背景候选图,然后执行步骤4;
37.如果z(min)≠0,在z(1),z(2),...,z(p)中,选择次小值,表示为:z(mid),一共包括z(mid)个目标框的图像帧依次为:图像帧s
1mid
,图像帧s
2mid
,...,图像帧s
n2mid
,其中,n2为具有z(mid)个目标框的图像帧的数量;
38.将n1+n2个图像帧,即图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
,图像帧s
1mid
,图像帧s
2mid
,...,图像帧s
n2mid
作为背景候选图,然后执行步骤5;
39.步骤4,如果n1《3,将图像帧s
1min
作为背景图,结束流程;
40.如果n1≥3,则从图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
中,挑选与其他各图像帧的相似度的和最大的图像帧,作为背景图,结束流程;
41.步骤5,以图像帧s
1min
为基础,图像帧s
1min
包括z(min)个目标框,分别表示为:目标框h(1),目标框h(2),...,目标框h(z(min));
42.对于每个目标框h(a),a=1,2,...,z(min),其属性为:(xa,ya,wa,ha),(xa,ya)代表目标框h(a)的中心点在图像帧s
1min
中的坐标;wa和ha分别代表目标框的宽度和高度,均执行以下步骤:
43.按序依次遍历图像帧s
2min
,...,图像帧s
n1min
,图像帧s
1mid
,图像帧s
2mid
,...,图像帧s
n2mid
,当首次遍历到某个图像帧sb,b=2min,...,n1min,1mid,2mid,...,n2mid,满足以下条件:
44.在图像帧sb中,以(xa,ya)为中心点,wa和ha为宽度和高度,绘制目标框h(b),所绘制的目标框h(b),与图像帧sb中原来存在的目标框不存在任何重叠;
45.则停止遍历,从图像帧sb中剪切出来绘制的目标框h(b)的区域,作为子图,替换图像帧s
1min
中目标框h(a)的区域;
46.当对图像帧s
1min
的z(min)个目标框均执行完成替换操作时,由此得到的图像帧,作为背景图,结束流程。
47.优选的,步骤4中,n1≥3时,从图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
中,挑选与其他各图像帧的相似度的和最大的图像帧,作为背景图,具体为:
48.步骤4.1,对于图像帧s
1min
,分别计算其与其他n1-1个图像帧的相似度,再对得到的n1-1个相似度求和,得到图像帧s
1min
的相似度量值f
1min
;
49.对于图像帧s
2min
,分别计算其与其他n1-1个图像帧的相似度,再对得到的n1-1个相似度求和,得到图像帧s
2min
的相似度量值f
2min
;
50.依此类推
51.对于图像帧s
n1min
,分别计算其与其他n1-1个图像帧的相似度,再对得到的n1-1个相似度求和,得到图像帧s
n1min
的相似度量值f
n1min
;
52.步骤4.2,在相似度量值f
1min
,f
2min
,...,f
n1min
中,选择最大值,表示为:f
(max)
;相似度量值f
(max)
对应的图像帧,作为背景图。
53.优选的,图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
中,任意两个图像帧表示为:
54.图像帧si和图像帧sj,采用以下方法,计算相似度:
55.图像帧si和图像帧sj的尺寸相同,均划分为c1*c2个结构块block;其中,c1为结构块的行数,c2为结构块的列数;
56.采用下式,计算图像帧si和图像帧sj的相似度block_ssim
(i,j)
:
[0057][0058]
其中:
[0059]
对图像帧si的c1*c2个结构块按从左向右,从上向下的顺序,从1开始依次编号,代表图像帧si中编号为l的结构块;
[0060]
对图像帧sj的c1*c2个结构块按从左向右,从上向下的顺序,从1开始依次编号,代表图像帧sj中编号为l的结构块;
[0061]
代表结构块和结构块的相似度;
[0062]
floor()函数表示向下取整;
[0063]
的含义为:对结构块和结构块的相似度,以0.8为阈值进行二值化,即:如果相似度大于等于0.8,则结果为1;否则,结果为0。
[0064]
本发明提供的视频浓缩中背景图像的生成方法具有以下优点:
[0065]
(1)该方法结合深度学习(目标检测、目标跟踪)和非深度学习(背景建模)的方法,对图像帧中前景目标的检测更加准确,提高图像帧中前景目标检出率,漏检明显减少,从而保证生成准确的背景图像;
[0066]
(2)该方法可以针对特定目标(比如行人、机动车、非机动车等)加强其检出的能力,可以适应不同场景不同目标的检出需要。
[0067]
(3)该方法可以有效解决背景建模漏检短暂静止的前景目标的弊端。
[0068]
(4)该方法生成背景候选图的效率高,遍历一次每帧的目标框数量,即可选出背景候选图,计算量小,耗时短。
[0069]
(5)该方法提出块结构相似度计算方法,在多帧目标框数量为0的情况下,有效利用了多帧信息,计算出与所有帧图像相似度最高的一帧图像,生成背景图像,前景目标的漏检残留现象被进一步消除,生成的背景图像质量明显提升。
附图说明
[0070]
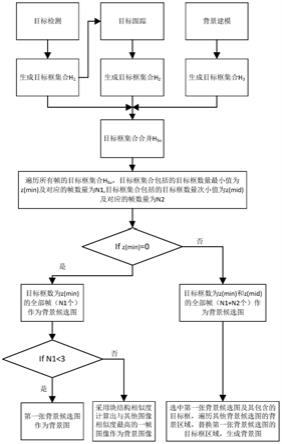
图1为本发明提供的视频浓缩中背景图像的生成方法的流程示意图。
具体实施方式
[0071]
为了使本发明所解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0072]
本发明提供一种视频浓缩中背景图像的生成方法,结合目标检测、目标跟踪、背景建模、图像的结构相似度等计算方法,实现浓缩视频中背景图像生成,本发明可有效减小生
成的背景图像中残留前景目标的可能性,从而提高生成的背景图像的准确度和精度。
[0073]
参考图1,本发明提供一种视频浓缩中背景图像的生成方法,包括以下步骤:
[0074]
步骤1,视频包括p张图像帧,按序依次表示为:图像帧s1,图像帧s2,...,图像帧s
p
;
[0075]
步骤2,对于每张图像帧su,u=1,2,...,p,均执行步骤2.1-步骤2.5,得到图像帧su的目标框集合h
su
={目标框h
su
(1),目标框h
su
(2),...,目标框h
su
(z(u))};其中,z(u)代表图像帧su包括的目标框的数量;
[0076]
步骤2.1,利用目标检测模型,对图像帧su进行特定目标检测,得到目标框集合h1;
[0077]
其中,如果图像帧su中未检测到特定目标,则目标框集合h1为空;如果在图像帧su中检测到存在n1个特定目标,每个特定目标对应一个目标框,由此检测到n1个目标框,因此,目标框集合h1中包括n1个目标框;
[0078]
作为一种具体实现方式,可以采用yolov5目标检测模型,对图像帧su进行特定目标检测,比如特定目标为行人、非机动车、机动车等,每一个检测到的目标生成一个目标框,由此得到目标框集合h1。例如,以行人为特定目标,检测到某个图像帧su共包括10个行人,则生成10个行人目标框,形成目标框集合h1。
[0079]
步骤2.2,利用目标跟踪模型,对图像帧su进行特定目标跟踪,得到目标框集合h2;
[0080]
其中,如果图像帧su中未跟踪到特定目标,则目标框集合h2为空;如果在图像帧su中跟踪到存在n2个特定目标,每个特定目标对应一个目标框,由此跟踪到n2个目标框,因此,目标框集合h2中包括n2个目标框;
[0081]
作为一种具体实现方式,可以采用deepsort-resnet18目标跟踪模型,对图像帧su进行特定目标跟踪。例如,特定目标为行人,在某个图像帧su中共追踪到10个行人,则生成10个行人目标框,形成目标框集合h2。
[0082]
步骤2.3,利用背景建模技术,对图像帧su进行运动物体目标检测,得到目标框集合h3;
[0083]
其中,如果图像帧su中未检测到存在运动物体目标,则目标框集合h3为空;如果在图像帧su中检测到存在n3个运动物体目标,每个运动物体目标对应一个目标框,由此检测到n3个目标框,因此,目标框集合h3中包括n3个目标框;
[0084]
具体的,利用背景建模技术,对图像帧su进行运动物体目标检测,例如,检测到图像帧su中存在两个运动物体,分别为树叶和车辆,则生成2个目标框,形成目标框集合h3。
[0085]
其中,对于目标框集合h1、目标框集合h2和目标框集合h3中的每个目标框,均具有以下属性:(x0,y0,w0,h0),(x0,y0)代表目标框的中心点在图像帧su中的坐标;w0和h0分别代表目标框的宽度和高度。另外,本发明中,各个图像帧的尺寸均相等。
[0086]
在一条运动轨迹形成的图像帧序列中,通过目标检测模型,检测到部分图像帧具有目标框,部分图像帧由于目标检测模型的检测效率和物体遮挡产生漏检,导致不具有目标框。此时出现遗漏前景目标的现象。
[0087]
因此,本发明中,通过目标跟踪模型对图像帧进行检测,将跟踪到的目标框与目标检测模型在同一个图像帧中检测到的目标框进行合并,实现目标跟踪模型对目标检测模型的补充作用。具体合并方法见步骤2.4。
[0088]
由于背景建模技术只对各个图像帧su中的运动物体进行检测,可能遗漏短暂静止的前景目标,进而误判。而目标检测模型和目标跟踪模型虽然具有较高的检测性能,但依然
具有遗漏前景目标的可能性。所以,将背景建模技术检测到的目标框,与目标检测模型和目标跟踪模型检测到的目标框进一步进行合并,实现背景建模技术对目标检测模型和目标跟踪模型的补充,进一步减少漏检前景目标的可能性,具体合并方法见步骤2.5。
[0089]
因此,将目标检测模型、目标跟踪模型和背景建模技术检测到的目标框进行合并,相互补充,三类目标框基本涵盖了视频中每帧的前景目标,使漏检的概率控制在较低的范围。
[0090]
具体见步骤2.4和步骤2.5。
[0091]
步骤2.4,对目标框集合h1和目标框集合h2进行合并操作,得到合并目标框集合h
12
:
[0092]
步骤2.4.1,合并目标框集合h
12
初始为空;
[0093]
步骤2.4.2,将目标框集合h1中的所有目标框,以及目标框集合h2中的所有目标框,均加入到合并目标框集合h
12
中,由此得到合并目标框集合h
12
;
[0094]
步骤2.4.3,对步骤2.4.2得到的合并目标框集合h
12
进行去冗余操作,得到最终的合并目标框集合h
12
:
[0095]
去冗余操作为:
[0096]
对于目标框集合h2中的每个目标框,表示为:目标框h2,计算其与目标框集合h1中的各个目标框的重叠度iou,如果存在重叠度iou》ε的情况,例如,ε为0.8,则将目标框h2作为冗余目标框,从步骤2.4.2得到的合并目标框集合h
12
中,删除该目标框h2;否则,保留该目标框h2;
[0097]
本步骤合并目标检测模型得到的目标框集合h1和目标跟踪模型得到的目标框集合h2,目标框集合h2可以补充目标框集合h1漏检的情况。目标框集合h1的目标框准确率较高,可以校准目标框集合h2跟踪不准的情况。但两者合并会产生重叠度较高的冗余目标框。去除冗余目标框的机制:如果h1中的某个目标框和h2中的某个目标框的重叠度iou》0.8,则将h2中的这个目标框作为冗余目标框,进行删除。
[0098]
因此,本发明中,由于目标检测模型得到的目标框准确率较高,可以校准目标跟踪模型跟踪不准的情况,因此优先保留目标检测模型得到的目标框,对目标跟踪模型检测到的冗余目标框进行删除。
[0099]
步骤2.5,对合并目标框集合h
12
和目标框集合h3进行合并操作,得到最终的目标框集合h
su
:
[0100]
步骤2.5.1,目标框集合h
su
初始为空;
[0101]
步骤2.5.2,将合并目标框集合h
12
中的所有目标框,以及目标框集合h3中的所有目标框,均加入到目标框集合h
su
,由此得到目标框集合h
su
;
[0102]
步骤2.5.3,对步骤2.5.2得到的目标框集合h
su
进行去冗余操作,得到最终的目标框集合h
su
:
[0103]
去冗余操作为:
[0104]
对于合并目标框集合h
12
中的每个目标框,表示为目标框h
12
,判断其是否被目标框集合h3中的某个目标框完全包含,如果是,则从目标框集合h
su
中删除该目标框h
12
;否则,保留该目标框h
12
;
[0105]
对于目标框集合h3中的每个目标框h3,判断其是否被合并目标框集合h
12
中的某个
目标框完全包含,如果是,则从目标框集合h
su
中删除该目标框h3;否则,保留该目标框h3;
[0106]
具体的,合并目标框集合h3和目标框集合h
12
,目标框集合h3可以补充目标检测模型和目标跟踪模型得到的合并后的目标框的信息,但两者合并同样会产生重叠度较高的冗余目标框。
[0107]
此时去除冗余目标框的机制:如果目标框集合h
12
中的目标框完全包含目标框集合h3中的某个目标框,那么删除目标框集合h3中的这个目标框;反之如果目标框集合h3中目标框完全包含了目标框集合h
12
中的某个目标框,那么删除目标框集合h
12
中的这个目标框。
[0108]
步骤3,背景候选图的生成:
[0109]
对于图像帧s1,得到的目标框集合h
s1
包括z(1)个目标框;
[0110]
对于图像帧s2,得到的目标框集合h
s2
包括z(2)个目标框;
[0111]
依此类推
[0112]
对于图像帧s
p
,得到的目标框集合h
sp
包括z(p)个目标框;
[0113]
在z(1),z(2),...,z(p)中,选择最小值,表示为:z(min),一共包括z(min)个目标框的图像帧依次为:图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
,其中,n1为具有z(min)个目标框的图像帧的数量;
[0114]
例如,图像帧序列共包括100个图像帧,分别为:图像帧s1,图像帧s2,
…
,图像帧s
100
,在这100个图像帧中,一共有5个图像帧,分别为:s2,s
10
,s
15
,s
51
,s
60
,均具有0个目标框。其他图像帧具有1个以上的目标框。则z(min)=0,n1=5。
[0115]
再例如,图像帧序列共包括100个图像帧,分别为:图像帧s1,图像帧s2,
…
,图像帧s
100
,在这100个图像帧中,一共有10个图像帧,均具有1个目标框,而其他90个图像帧均具有2个以上目标框。则z(min)=1,n1=10。
[0116]
如果z(min)=0,表明图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
中均不具有目标框,代表这些图像帧均为背景,因此,直接将图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
作为背景候选图,然后执行步骤4;
[0117]
如果z(min)≠0,在z(1),z(2),...,z(p)中,选择次小值,表示为:z(mid),一共包括z(mid)个目标框的图像帧依次为:图像帧s
1mid
,图像帧s
2mid
,...,图像帧s
n2mid
,其中,n2为具有z(mid)个目标框的图像帧的数量;
[0118]
将n1+n2个图像帧,即图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
,图像帧s
1mid
,图像帧s
2mid
,...,图像帧s
n2mid
作为背景候选图,然后执行步骤5;
[0119]
也就是说,当z(min)≠0,代表所有的图像帧均不属于完全背景图像,为提高检测精度和算法的有效性,选取目标框数为z(min)和z(mid)的所有图像帧,作为背景候选图。
[0120]
步骤4,如果n1《3,将图像帧s
1min
作为背景图,结束流程;
[0121]
如果n1≥3,则从图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
中,挑选与其他各图像帧的相似度的和最大的图像帧,作为背景图,结束流程;
[0122]
本步骤具体为:
[0123]
步骤4.1,对于图像帧s
1min
,分别计算其与其他n1-1个图像帧的相似度,再对得到的n1-1个相似度求和,得到图像帧s
1min
的相似度量值f
1min
;
[0124]
例如,假设n1=4,则分别计算s
1min
和s
2min
的相似度f1,s
1min
和s
3min
的相似度f2,s
1min
和s
4min
的相似度f3,再对f1、f2和f3求和,得到相似度量值f
1min
。
[0125]
对于图像帧s
2min
,分别计算其与其他n1-1个图像帧的相似度,再对得到的n1-1个相似度求和,得到图像帧s
2min
的相似度量值f
2min
;
[0126]
依此类推
[0127]
对于图像帧s
n1min
,分别计算其与其他n1-1个图像帧的相似度,再对得到的n1-1个相似度求和,得到图像帧s
n1min
的相似度量值f
n1min
;
[0128]
其中,图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
中,任意两个图像帧表示为:图像帧si和图像帧sj,采用以下方法,计算相似度:
[0129]
图像帧si和图像帧sj的尺寸相同,均划分为c1*c2个结构块block;其中,c1为结构块的行数,c2为结构块的列数;
[0130]
采用下式,计算图像帧si和图像帧sj的相似度block_ssim
(i,j)
:
[0131][0132]
其中:
[0133]
对图像帧si的c1*c2个结构块按从左向右,从上向下的顺序,从1开始依次编号,代表图像帧si中编号为l的结构块;
[0134]
对图像帧sj的c1*c2个结构块按从左向右,从上向下的顺序,从1开始依次编号,代表图像帧sj中编号为l的结构块;
[0135]
代表结构块和结构块的相似度;
[0136]
floor()函数表示向下取整;
[0137]
的含义为:对结构块和结构块的相似度,以0.8为阈值进行二值化,即:如果相似度大于等于0.8,则结果为1;否则,结果为0。
[0138]
步骤4.2,在相似度量值f
1min
,f
2min
,...,f
n1min
中,选择最大值,表示为:f
(max)
;相似度量值f
(max)
对应的图像帧,作为背景图。
[0139]
下面列举一个实施例:
[0140]
具有n1张图像帧,图像帧s
1min
,图像帧s
2min
,...,图像帧s
n1min
,从n1张图像帧中,采用以下方法,挑选一张图像帧作为背景图:
[0141]
n1张图像帧的尺寸resize均为(500,500),每个结构块block的边长blocksize=10,因此,每个图像帧划分为50*50个结构块block;
[0142]
采用公式计算图像帧si和图像帧sj的相似度block_ssim
(i,j)
:
[0143][0144]
其中:函数表示结构块和结构块的相似度,取值范围在[0,1],floor()函数表示向下取整,因此,表示两个结构块的结构相似度以0.8为阈值进行二值化。
[0145]
计算每张图与其他各张图的块结构相似度之和:
[0146]
求使f(x)最大的x取值:m=argmax(f(x))
[0147]
根据计算结果,第m张背景候选图作为背景图。
[0148]
步骤5,以图像帧s
1min
为基础,图像帧s
1min
包括z(min)个目标框,分别表示为:目标框h(1),目标框h(2),...,目标框h(z(min));
[0149]
对于每个目标框h(a),a=1,2,...,z(min),其属性为:(xa,ya,wa,ha),(xa,ya)代表目标框h(a)的中心点在图像帧s
1min
中的坐标;wa和ha分别代表目标框的宽度和高度,均执行以下步骤:
[0150]
按序依次遍历图像帧s
2min
,...,图像帧s
n1min
,图像帧s
1mid
,图像帧s
2mid
,...,图像帧s
n2mid
,当首次遍历到某个图像帧sb,b=2min,...,n1min,1mid,2mid,...,n2mid,满足以下条件:
[0151]
在图像帧sb中,以(xa,ya)为中心点,wa和ha为宽度和高度,绘制目标框h(b),所绘制的目标框h(b),与图像帧sb中原来存在的目标框不存在任何重叠;
[0152]
则停止遍历,从图像帧sb中剪切出来绘制的目标框h(b)的区域,作为子图,替换图像帧s
1min
中目标框h(a)的区域;
[0153]
当对图像帧s
1min
的z(min)个目标框均执行完成替换操作时,由此得到的图像帧,作为背景图,结束流程。
[0154]
下面列举一个实施例:
[0155]
本发明浓缩视频中背景图像生成的方法,包含4个步骤:目标框生成、目标框合并、背景候选图生成、背景图生成。如图1所示。
[0156]
步骤一:目标框生成:
[0157]
对于每个图像帧,本发明选择三种方法生成目标框。
[0158]
(1)利用目标检测模型yolov5对每个图像帧的特定目标进行检测,比如特定目标为行人、非机动车、机动车,检测这三类目标,得到该图像帧的检测目标框集合h1;
[0159]
(2)利用目标跟踪模型deepsort-resnet18对该图像帧的特定目标进行跟踪,得到该图像帧的跟踪目标框集合h2;
[0160]
(3)利用背景建模,对该图像帧中的运动物体进行检测,得到该图像帧的目标mask,经过连通域分析确定其外接矩形作为背景建模目标框集合h3。
[0161]
步骤二:目标框集合合并
[0162]
对于同一个图像帧,通过将目标检测模型、目标跟踪模型和背景建模得到的各个目标框进行合并,使三类目标框相互补充,三类目标框基本涵盖了视频中每帧的前景目标,使漏检的概率控制在较低的范围。
[0163]
合并方法:
[0164]
首先合并h1和h2,h2的信息可以补充h1漏检的情况,h1中的目标框准确率较高可以校准h2跟踪不准的情况,但两者合并会产生重叠度较高的冗余目标框。去除冗余目标框的机制:
[0165]
如果h1和h2中的某个目标框iou》0.8,那么删除h2中的这个目标框为冗余目标框。由于h1中的目标框准确率较高可以校准h2跟踪不准的情况,因此优先保留h1,对h2中的冗余
目标框进行删除之后,h1和h2进行合并。合并过程如下:
[0166][0167]
上述iou(a,b)函数表示计算a和b的交并比,delete(h2,k)函数表示删除h2中的第k个元素。hm就是h1和h2合并的结果。
[0168]
再次合并hm和s3,s3可以补充s1和s2的合并结果s3的信息,但两者合并同样会产生重叠度较高的冗余目标框。去除冗余目标框的机制:如果hm中目标框完全包含了s3中的某个目标框,那么删除s3中的这个目标框;反之如果s3中目标框完全包含了hm中的某个目标框,那么删除hm中的这个目标框。合并过程如下:
[0169][0170]
上述iosa(a,b)函数表示(a∩b)/a,iosb(a,b)函数表示(a∩b)/b.hm就是h1、h2和h3的合并结果。
[0171]
步骤三:背景候选图生成
[0172]
每个图像帧均形成一个目标框集合,目标框集合具有一定数量的目标框。对各个图像帧的目标框数量进行遍历,目标框数量最小值为m1及对应的帧数量为n1,目标框数量次小值为m2及对应的帧数量为n2。
[0173]
如果m1=0,选目标框数为m1的全部帧(n1个)作为背景候选图。
[0174]
否则,选目标框数为m1和m2的全部帧(n1+n2个)作为背景候选图。
[0175]
步骤四:背景图生成
[0176]
(1)针对m1=0的情况,如果背景候选图数量n1《3,则第一张背景候选图作为背景图。如果背景候选图数量n1》=3,n1张背景候选图全部参与计算。采用块结构相似度计算出与其他图像相似度最高的一帧图像作为背景图像。
[0177]
(2)针对m1》0的情况,选中第一张背景候选图及其对应的目标框集合sm,遍历其他背景候选图的背景区域,替换第一张背景候选图的目标框区域,具体过程如下:
[0178][0179]
执行完成,生成一张背景图像。
[0180]
本发明具有以下创新:
[0181]
1.本发明方法流程:多类目标框生成、目标框合并、候选背景图像生成、背景图像生成。
[0182]
2.本发明方法中多类目标框的合并机制,有效利用各类方法生成目标框,提升了目标检出率,并且合理的消除了目标框重合的冗余信息。
[0183]
3.本发明方法中生成背景候选图机制,遍历一次每帧的目标框数量,即可选出背景候选图,效率高、计算量小、耗时短。
[0184]
4.本发明方法中提出块结构相似度计算方法,有效利用了多帧的图像信息,前景目标的漏检残留现象被进一步消除,生成的背景图像质量明显提升。
[0185]
与现有技术相比,本发明有益效果是:
[0186]
(1)该方法结合深度学习(目标检测、目标跟踪)和非深度学习(背景建模)的方法,对图像帧中前景目标的检测更加准确,提高图像帧中前景目标检出率,漏检明显减少,从而保证生成准确的背景图像;
[0187]
(2)该方法可以针对特定目标(比如行人、机动车、非机动车等)加强其检出的能力,可以适应不同场景不同目标的检出需要。
[0188]
(3)该方法可以有效解决背景建模漏检短暂静止的前景目标的弊端。
[0189]
(4)该方法生成背景候选图的效率高,遍历一次每帧的目标框数量,即可选出背景候选图,计算量小,耗时短。
[0190]
(5)该方法提出块结构相似度计算方法,在多帧目标框数量为0的情况下,有效利用了多帧信息,计算出与所有帧图像相似度最高的一帧图像,生成背景图像,前景目标的漏检残留现象被进一步消除,生成的背景图像质量明显提升。
[0191]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1