基于自注意力机制和最小二乘的条件对抗领域自适应方法
1.本发明涉及迁移学习技术领域,具体是基于自注意力机制和最小二乘的条件对抗领域自适应方法。
背景技术:
2.深度学习是人工智能研究领域中的重要研究方向之一,它通过模拟人的大脑,将每一层网络都看作为人脑的一组神经元,通过多层网络不断叠加从而使得机器能够完成和人脑一样的任务;虽然深度学习在各个领域内都有着很好的应用效果,但也存在着一定局限性;其对训练集和测试集要求方面必须满足相同的数据分布特性,同时满足数据具备标签的条件;然而在现实世界中,随着大数据时代的来临,数据虽然爆炸式增长,但并不是出现的数据都拥有其对应的标签,而且对每一个数据集中的数据都分别进行标注又是个极其耗费金钱和时间的工作,为了解决以上问题,人们提出了迁移学习。
3.条件对抗领域自适应相关算法依然存在以下问题:条件对抗领域自适应算法中的由于仅使用卷积网络提取特征导致无法捕捉远距离像素信息关系,进而使得算法的分类任务精度下降和使用交叉熵损失函数的使用所导致的模型训练不稳定、梯度消失、模式崩塌的问题;因此,针对上述问题提出基于自注意力机制和最小二乘的条件对抗领域自适应方法。
技术实现要素:
4.为了弥补现有技术的不足,解决条件对抗领域自适应算法中的由于仅使用卷积网络提取特征导致无法捕捉远距离像素信息关系,进而使得算法的分类任务精度下降和使用交叉熵损失函数的使用所导致的模型训练不稳定、梯度消失、模式崩塌的问题,本发明提出基于自注意力机制和最小二乘的条件对抗领域自适应方法。
5.本发明解决其技术问题所采用的技术方案是:本发明所述的基于自注意力机制和最小二乘的条件对抗领域自适应方法,该方法包括如下;通过自注意力机制的特征提取网络和最小二乘的条件形成对抗领域自适应损失函数。
6.优选的,所述自注意力机制引入到特征提取网络中,根据非局部神经网络的思想,定义自注意力机制层表示形式如式(1)所示:
[0007][0008]
式中,x表示resnet-50网络层的输入图像特征矩阵;xi表示特征矩阵中的第i个元素;xj表示特征矩阵中的第j个元素;n表示所有特征矩阵元素数量之和;
[0009]
通过式(1)看出γ
i,j
与xi、xj都有着直接关系,所以任何一对特征矩阵中的元素输入到自注意力机制层均会直接影响到该层的输出;γ
i,j
表示特征矩阵中元素xi和xj之间的关联性指标;由于自注意力模块是非局部嵌入高斯模型的一种特殊形式,则式(1)中f(xi,
xj)表示为:
[0010][0011]
其中θ(xi)和φ(xj)具体表达方式如式(3)和(4)所示:
[0012]
θ(xi)=w
θ
*xiꢀꢀꢀ
(3)
[0013][0014]
式中,w
θ
、均表示卷积操作,其中卷积核为1x1且信道尺寸为输入信道的1/8;θ(xi)、均表示卷积网络组成的特征空间,其作用是减少每个卷积核的通道数量和参数,进而降低算法运算复杂度;
[0015]
因此,根据式(2)—(4),将式(1)改写为:
[0016][0017]
由于γ
i,j
为特征矩阵中元素xi和xj之间的关联性指标,再根据式(5),则自注意力机制层的输出表达式为:
[0018][0019]
式中,h(xj)表示输入图片在j位置处的特征值,其具体表达方式如式(7)所示:
[0020]
h(xj)=whxjꢀꢀꢀ
(7)
[0021]
此外式(3)、(4)和(7)卷积操作中的w
θ
、wh都有着相同的卷积核大小和信道尺寸;
[0022]
最后将自注意力机制层的输出o和输入特征x组成线性网络,得到输出特征:
[0023]
yi=wooi+xiꢀꢀꢀ
(8)
[0024]
式中,wo表示卷积操作,卷积核为1
×
1,其信道尺寸为wh、w
θ
、的8倍,目的是为了能够还原原始图片信道数目。
[0025]
优选的,所述最小二乘的损失函数网络结构主要由三部分组成,每部分的具体表达形式如式(9)-(11)所示:
[0026][0027][0028][0029]
式中,a、b分别表示源域标签和目标域标签;h()表示标准熵;ω(x)表示熵感知权重,表达形式为ω(x)=1+e-x
;c表示先验参数,用于设定域判别器d认为提取特征来自源域的值;表示源域数据;表示源域数据的标签;g()表示类别分类器;表示特征提取器;
d()表示域判别器;表示利用特征提取器获取的源域数据特征;表示利用特征提取器获取的目标域特征;表示利用源域分类器获取的预测标签;表示利用类别分类器g()预测的目标域类别;ε(g)、γ(d)和分别表示用来衡量类别分类器、域判别器和特征提取器优劣程度的损失函数;
[0030]
根据式(9)—(11),应用到条件对抗领域自适应方法中的最小二乘损失函数表示为:
[0031][0032][0033]
式中λ的含义表示分类损失和迁移损失之间的权衡参数;工作时,进一步,为了证明本方法的可行性,接下来将从理论层面证明最小二乘损失函数能够避免出现梯度消失现象的原因。在条件对抗领域自适应方法中使用交叉熵损失函数,当出现梯度消失时,该损失函数无法收敛,导致模型训练失败,而交叉熵损失函数的收敛问题归根到底就是js散度收敛问题,根据js散度相关理论可知:
[0034][0035]
当源域分布和目标域分布相似时,js散度趋近于0,但由于js散度自身的不稳定性,模型训练过程中js散度很难趋于0,会提前梯度消失,进而使网络框架模型无法进一步优化参数;此时将使用最小二乘损失函数来解决上述问题。
[0036]
首先,对改进算法的域判别器d通过求导得到最优判别器d
*
,其具体表达形式为:
[0037][0038]
其次,将式(15)再带入到式(11)中,经推导可得:
[0039][0040]
最后,将a、b、c分别设定为-1、1、0,经化简式(16)可得:
[0041][0042]
根据式(17),计算最小二乘损失函数的收敛等同于使和的皮尔森散度χ2(pearsonχ2)收敛,而皮尔森散度在收敛过程中不会出现梯度消失的问题;因此,所提的最小二乘损失函数即可避免梯度消失现象,从而增强了模型训练过程的稳定性。
[0043]
本发明的有益之处在于:
[0044]
1.本发明通过在特征提取阶段,提出了将自注意力机制加入到残差网络中,解决了对条件对抗领域自适应方法中使用卷积网络提取特征,导致忽略图像上远距离特征关系、减弱模型提取共享特征能力、降低模型精度等一系列问题;并提出使用最小二乘损失函数代替条件对抗领域自适应方法中的交叉熵损失函数,解决算法模型出现模式崩塌、梯度消失以及训练过程不稳定等问题;基于自注意力机制和最小二乘的条件对抗领域自适应方法具有训练过程稳定,数据集分类任务精度高和收敛速度快等优点。
附图说明
[0045]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本
发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。
[0046]
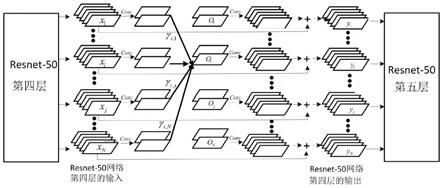
图1为的自注意力层的网络结图;
[0047]
图2为的最小二乘损失函数网络结构图。
具体实施方式
[0048]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0049]
请参阅图1-2所示,基于自注意力机制和最小二乘的条件对抗领域自适应方法,该方法包括如下;通过自注意力机制的特征提取网络和最小二乘的条件形成对抗领域自适应损失函数。
[0050]
所述自注意力机制引入到特征提取网络中,根据非局部神经网络的思想,定义自注意力机制层表示形式如式(1)所示:
[0051][0052]
式中,x表示resnet-50网络层的输入图像特征矩阵;xi表示特征矩阵中的第i个元素;xj表示特征矩阵中的第j个元素;n表示所有特征矩阵元素数量之和;
[0053]
通过式(1)看出γ
i,j
与xi、xj都有着直接关系,所以任何一对特征矩阵中的元素输入到自注意力机制层均会直接影响到该层的输出;γ
i,j
表示特征矩阵中元素xi和xj之间的关联性指标;由于自注意力模块是非局部嵌入高斯模型的一种特殊形式,则式(1)中f(xi,xj)表示为:
[0054][0055]
其中θ(xi)和φ(xj)具体表达方式如式(3)和(4)所示:
[0056]
θ(xi)=w
θ
*xiꢀꢀꢀ
(3)
[0057][0058]
式中,w
θ
、均表示卷积操作,其中卷积核为1x1且信道尺寸为输入信道的1/8;θ(xi)、均表示卷积网络组成的特征空间,其作用是减少每个卷积核的通道数量和参数,进而降低算法运算复杂度;
[0059]
因此,根据式(2)—(4),将式(1)改写为:
[0060][0061]
由于γ
i,j
为特征矩阵中元素xi和xj之间的关联性指标,再根据式(5),则自注意力机制层的输出表达式为:
[0062][0063]
式中,h(xj)表示输入图片在j位置处的特征值,其具体表达方式如式(7)所示:
[0064]
h(xj)=whxjꢀꢀꢀꢀ
(7)
[0065]
此外式(3)、(4)和(7)卷积操作中的w
θ
、wh都有着相同的卷积核大小和信道尺寸;
[0066]
最后将自注意力机制层的输出o和输入特征x组成线性网络,得到输出特征:
[0067]
yi=wooi+xiꢀꢀꢀ
(8)
[0068]
式中,wo表示卷积操作,卷积核为1
×
1,其信道尺寸为wh、w
θ
、的8倍,目的是为了能够还原原始图片信道数目;工作时,自注意力机制层相比于卷积网络层,其能够捕捉到图像中各个位置上的特征关系,从而增大特征关系间的捕捉范围;此外相比于线性网络层,其解决了线性网络层只能根据权重得到输入与输出的关系局限性问题,同时提升不同输入关系与输出结果间的关联性;相比于循环神经网络层,其增大了特征涵盖关系距离,克服了循环神经网络层只能捕捉到当前时刻和前一时刻输入数据关系的难题;根据上述自注意力机制层的理论推导,该自注意力机制层处于resnet-50网络的第四层和第五层之间,其输入为resnet-50网络第四层的输出特征,其输出为resnet-50网络第四层的输入特征,具体表达形式如式(8)所示;利用式(5)即可求得;在图1中第一次卷积操作主要是用于为了减少信道数量,进而降低计算复杂度;而最后一次卷积操作的作用主要是用于增加信道数量,还原图像的完整性,从而为与resnet-50网络后续层的连接提供便利条件。
[0069]
所述最小二乘的损失函数网络结构主要由三部分组成,每部分的具体表达形式如式(9)-(11)所示:
[0070][0071][0072][0073]
式中,a、b分别表示源域标签和目标域标签;h()表示标准熵;ω(x)表示熵感知权重,表达形式为ω(x)=1+e-x
;c表示先验参数,用于设定域判别器d认为提取特征来自源域的值;表示源域数据;表示源域数据的标签;g()表示类别分类器;表示特征提取器;d()表示域判别器;表示利用特征提取器获取的源域数据特征;表示利用特征提取器获取的目标域特征;表示利用源域分类器获取的预测标签;表示利用类别分类器g()预测的目标域类别;ε(g)、γ(d)和分别表示用来衡量类别分类器、域判别器和特征提取器优劣程度的损失函数;
[0074]
根据式(9)—(11),应用到条件对抗领域自适应方法中的最小二乘损失函数表示为:
[0075][0076][0077]
式中λ的含义表示分类损失和迁移损失之间的权衡参数;工作时,进一步,为了证明本方法的可行性,接下来将从理论层面证明最小二乘损失函数能够避免出现梯度消失现象的原因。在条件对抗领域自适应方法中使用交叉熵损失函数,当出现梯度消失时,该损失函数无法收敛,导致模型训练失败,而交叉熵损失函数的收敛问题归根到底就是js散度收敛问题,根据js散度相关理论可知:
[0078][0079]
当源域分布和目标域分布相似时,js散度趋近于0,但由于js散度自身的不稳定性,模型训练过程中js散度很难趋于0,会提前梯度消失,进而使网络框架模型无法进一步优化参数;此时将使用最小二乘损失函数来解决上述问题。
[0080]
首先,对改进算法的域判别器d通过求导得到最优判别器d
*
,其具体表达形式为:
[0081][0082]
其次,将式(15)再带入到式(11)中,经推导可得:
[0083][0084]
最后,将a、b、c分别设定为-1、1、0,经化简式(16)可得:
[0085][0086]
根据式(17),计算最小二乘损失函数的收敛等同于使和的皮尔森散度χ2(pearsonχ2)收敛,而皮尔森散度在收敛过程中不会出现梯度消失的问题;因此,所提的最小二乘损失函数即可避免梯度消失现象,从而增强了模型训练过程的稳定性;最小二乘损失函数有利于缩短源域特征和目标域特征间的距离,使所提取的数据特征更接近决策边界,从而增强获取域不变特征的能力。另外,由于最小二乘损失函数具有只在一点饱和的特点,从而有效解决梯度消失的现象。
[0087]
本发明的软件程序依据自动化、网络和计算机处理技术编制,是本领域技术人员所熟悉的技术。
[0088]
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0089]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1