一种基于BERT和外部知识的生成式自动文摘方法
一种基于bert和外部知识的生成式自动文摘方法
技术领域
1.本发明属于自然语言处理领域,具体涉及一种基于bert和外部知识的生成式自动文摘方法。
背景技术:
2.随着科技的进步和移动互联网行业的蓬勃发展,每个网民甚至每个终端都成为了互联网信息的生产者。面对海量的信息,信息过载的现象日益严重,如何让人们高效的获取所需要的信息成为当今时代极大的挑战。为了更高效的获取到所需要的信息,自动文本摘要逐渐成为一门不可或缺的技术。
3.自动文本摘要可以分为抽取式自动文本摘要和生成式自动文本摘要。抽取式文摘通过从原始文档中选择一些相关句子来生成摘要,文摘的长度取决于压缩率,这是一种简单而有效的文本摘要方法。生成式文摘通过抽象概括生成摘要,其基本思路是在理解原文语义的基础上,凝练原始文档的思想与概念,以实现语义重构。mihalcea等人提出了textrank方法来进行文本摘要。erkan等人提出了lexrank方法来进行文本摘要,textrank通过句中词共现个数计算句子相似度,主要应用在单文档自动摘要生成中,而lexrank是基于统计词频tf-idf向量的余弦相似度,主要应用在多文档自动摘要生成方面。mehdad等人在基于图排序的生成式方法的基础上提出了基于图排序算法的最佳路径排名策略,将其应用于生成式文本摘要中。吴仁守等人在编码器端引入全局自匹配机制进行全局优化,并利用全局门控单元抽取出文本的核心内容,该模型能有效融合全局信息,挖掘出原文本的核心内容,在lcsts数据集上实验表明,该模型的性能有显著提高。li等人提出了一种用于文本摘要的双注意力指针网络,该方法引入了自我关注机制来获取源文本的关键信息,并且结合门控机制控制信息的选择。在现有覆盖机制的基础上,增加了截断参数,防止该机制干扰其他目标的生成。
4.以上技术都是基于原文档直接生成摘要,和人工撰写摘要相比,没有考虑外部先验知识,导致生成的摘要无法准确的表达文档主旨,而且难以保证生成摘要的连贯性和一致性。
技术实现要素:
5.为解决上述问题,本发明提供了一种基于bert和外部知识的生成式自动文摘方法,获取文档数据并进行预处理;将预处理后的文档数据输入到训练好的生成式自动文摘模型中生成文档对应的摘要;生成式自动文摘模型包括textrank模块、bert模块、外部知识模块和transformer模型;
6.生成式自动文摘模型的训练过程包括:
7.s1.获取原始文摘数据,对原始文摘数据进行预处理;
8.s2.将预处理后的原始文摘数据送入textrank模块获取关键词,同时将预处理后的原始文摘数据输入到bert模块中进行编码,得到编码数据;
9.s3.根据关键词从外部知识模块中检索相关的知识信息,将知识信息与编码数据通过门控机制进行融合;
10.s4.将融合后的数据输入到transformer模型进行解码,得到解码数据,将解码数据输入全连接层,将全连接层的输出结果输入softmax层生成摘要;设置迭代初始次数;
11.s5.采用交叉熵损失函数训练生成式自动文摘模型,采用adam算法优化生成式自动文摘模型,即调整bert模块和transformer模型的参数;判断交叉熵损失函数计算结果是否达到最小值,若是,则结束训练,否则进入步骤s6;
12.s6.判断迭代次数是否达到最大迭代次数,若达到,则完成生成式自动文摘模型的训练,否则返回步骤s5,且迭代次数加1。
13.进一步的,对原始文摘数据进行预处理的过程为:
14.s11.对原始文摘数据进行分词处理,并使用bert的词表将分词处理后的原始文摘数据转化为id文件;
15.s12.设定序列长度最大值,根据序列长度最大值对id文件进行填充padding。
16.进一步的,获取编码数据的过程包括:
17.s21.对预处理后的原始文摘数据进行标记,得到标记文档,标记文档表示为:
18.s=[cls],d
11
,
…
,d
1m
,[sep],
…dij
…
,[cls],d
n1
,
…
,d
nx
,[sep];
[0019]
s22.对标记文档进行embedding,获取标记文档的文档词嵌入,文档词嵌入表示为:
[0020]
h=bert.embedding(s);
[0021]
s23.将文档词嵌入输入到bert模型中获取编码数据,编码数据表示为:
[0022]
td=bert(h);
[0023]
其中,d表示预处理后的原始文摘数据,s表示标记文档,di表示预处理后的原始文摘数据中的第i句话,d
ij
表示预处理后的原始文摘数据中第i句话的第j个单词,[cls]和[sep]为每句话的分隔符;h表示文档词嵌入,bert.embedding(
·
)表示embedding操作;bert(
·
)表示bert模型,td=t
[cls]
,t
11
,
…
,t
1m
,t
[sep]
,
…
t
ij
…
,t
[cls]
,t
n1
,
…
,t
nx
,t
[sep]
表示编码数据,t
[sep]
和t
[cls]
表示编码数据中每句话的分隔符,t
ij
表示编码数据中第i句话的第j个单词。
[0024]
进一步的,bert模型中采用多头注意力机制,其表示为:
[0025][0026]
headi=attention(qw
iq
,kw
ik
,vw
iv
);
[0027]
multhead(q,k,v)=concat(head1,
…
,headh)wo;
[0028]
其中,attention(
·
)表示注意力机制;q表示查询向量,k表示键向量、v表示值向量;softmax(
·
)表示归一化函数,t为矩阵转置的标识,dk表示键向量的维度,headi为第h次投影得到的attention值,i为投影的次数,w
iq
为q向量训练权重矩阵,w
ik
为k向量训练权重矩阵,w
iv
为v向量训练权重矩阵,multhead(
·
)表示多头注意力机制的最终输出,wo为附加的权重矩阵,concat(
·
)为向量拼接。
[0029]
进一步的,步骤s3包括:
[0030]
s31.获取关键词对应的关键词词嵌入,根据关键词词嵌入在外部知识模块检索相
关的外部知识;
[0031]
s32.通过线性运算融合外部知识与关键词得到知识向量;
[0032]
s33.通过门控机制筛选知识向量得到知识信息,将知识信息与编码数据进行融合得到t
′d。
[0033]
进一步的,生成摘要的公式表示为:
[0034]
out=transformer(t
′d);
[0035]
p
vocab
=softmax(g[out]);
[0036]
其中,transformer(
·
)代表transformer解码器,t
′d代表融合数据,g(
·
)代表全连接层,out表示transformer解码器的输出结果,p
vocab
表示词表中的词汇成为摘要的概率。
[0037]
进一步的,交叉熵损失函数表示为:
[0038][0039]
其中,y
《t
={y1,y2,y3,
…
,y
t-2
,y
t-1
};y
t
代表摘要中的第t个单词;x代表输入的原始文摘数据中的文档信息;θ代表训练的模型参数;n代表输入的原始文摘数据中的第n篇文档,t代表摘要的长度,n代表原始文摘数据中的文档总数量。
[0040]
进一步的,采用adam算法计算生成式自动文摘模型的优化结果,其计算公式为:
[0041][0042]
其中,表示校正后的一阶矩估计,表示校正后的二阶矩估计;μ表示步长,δ是为了维持数值稳定而添加的常数,θ表示要更新的参数。
[0043]
本发明的有益效果:
[0044]
本发明采用bert模型对文档数据进行编码,捕获文档数据更多的上下文信息,提高了编码的质量,通过textrank获得文档数据对应的关键词,根据关键词在外部知识库中获取相关的知识信息,采用门控机制将知识信息与编码后的文档数据融合,丰富了生成文摘的语义,提高了文摘的质量,使用transformer模型,可以捕捉更多内部信息,使生成的摘要在完整性和流畅性上都有了一定的提升。
附图说明
[0045]
图1为本发明的模型训练过程图;
[0046]
图2为本发明的模型结构图。
具体实施方式
[0047]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0048]
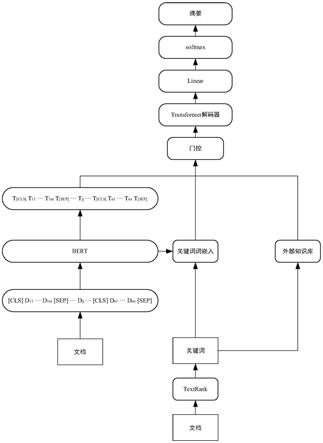
一种基于bert和外部知识的生成式自动文摘方法,如图2所示,构建生成式自动文
摘模型,生成式自动文摘模型包括textrank模块、bert模型、外部知识模块和transformer模型,该方法包括以下步骤:
[0049]
101、获取文档数据,并通过textrank模块获取文档数据对应的关键词;
[0050]
102、将文档数据输入到bert模型中进行编码,得到编码后的文档信息;
[0051]
103、通过关键词从外部知识模块检索外部知识,通过门控机制将外部知识与文档信息进行融合;
[0052]
104、将融合后的信息输入到transformer模型进行解码,生成摘要。
[0053]
在一实施例中,生成式自动文摘模型的训练过程如图1所示,包括:
[0054]
s1.获取原始数据集,将原始数据集进行划分,得到训练集、验证集和测试集,对训练集中的数据进行预处理;
[0055]
具体地,对验证集和测试集中的数据进行同样的预处理操作;
[0056]
s2.将训练集的预处理后的数据送入textrank模块获取关键词,同时将预处理后的数据送入bert模块进行编码,得到编码数据;
[0057]
s3.根据关键词在外部知识模块检索相关的知识信息,将知识信息与编码数据进行融合,得到融合数据;
[0058]
s4.将融合数据送入transformer模型进行解码,得到解码数据,将解码数据输入全连接层,将全连接层的输出结果输入softmax层生成摘要;
[0059]
s5.采用交叉熵损失函数训练生成式自动文摘模型,采用adam算法优化生成式自动文摘模型,即调整bert模块和transformer模型的参数;判断交叉熵损失函数计算结果是否达到最小值,若是,则结束训练,否则进入步骤s6;
[0060]
s6.判断迭代次数是否达到最大迭代次数,若达到,则完成生成式自动文摘模型的训练,否则返回步骤s5,且迭代次数加1。
[0061]
当训练完成后,采用测试集对训练完成的抽取式阅读理解模型进行性能评估。
[0062]
优选地,采用rouge评价指标中的rouge-1,rouge-2和rouge-l对模型性能进行评价。
[0063]
rouge是在2004年提出的一种自动文本摘要评价方法,是评估自动文本摘要的一组指标,核心是通过统计机器候选摘要句子和标准摘要句子重叠的单元n-gram,来评判摘要的质量。rouge主要是基于召回率(recall)进行评价,其基本思想是:由多个专家分别撰写人工摘要,构成标准摘要集。将系统生成的自动摘要与人工撰写的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过多专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为摘要评价技术的通用标准之一。其中rouge-n的计算方法如下所示:
[0064][0065]
其中,n代表n-gram的长度,count
match
(gramn)代表参考摘要和生成摘要共有的n-gram的个数,count(gramn)代表参考摘要中n-gram的个数。
[0066]
rouge-l的计算公式为:
[0067]
[0068][0069][0070]
其中,lcs(x,y)是x和y的最长公共子序列的长度,x是生成摘要,y是参考摘要,m,n分别代表参考摘要和生成摘要的长度(一般指所含词的个数),r
lcs
,p
lcs
分别表示召回率和准确率,最后的f
lcs
即是rouge-l。
[0071]
在一实施例中,原始数据集采用来自美国有线电视新闻网和英国《每日邮报》的cnn/daily mail数据集。该数据集包含了来自美国有线电视新闻网和英国《每日邮报》的约30万篇新闻语料,每篇源文本包含平均766个词和29.74个句子,对应的标准摘要包含平均53个词和3.72个句子。数据集划分为三个部分,训练集包含196961篇文档,验证集包含12148篇文档,测试集包含10397篇文档。
[0072]
对训练集中的数据进行预处理,其过程为:
[0073]
s11.对训练集中的数据进行分词处理,并使用bert的词表将分词处理后的数据转化为id文件;
[0074]
s12.按照bert模型的要求设定序列长度最大值,根据序列长度最大值对id文件进行填充padding;若id文件超过序列长度最大值,则将超出的数据截断,只输入前面的数据。
[0075]
将预处理后的数据送入textrank模块,采用textrank模块获取预处理后的数据中的每篇文档对应的关键词,其表示为:
[0076]
key1,
…
,keyi,
…
,keyn=textrank(d);
[0077]
其中,textrank(
·
)代表关键词提取算法,keyi代表从文档中提取的第i个关键词,同时使用[cls]、[sep]对每个关键词进行标记,从而实现对一个文档中的多个关键词进行分割。
[0078]
同时将预处理后的数据输入到bert模块中进行编码,得到编码数据,包括:
[0079]
s21.对预处理后的数据进行标记,得到标记文档,标记文档表示为:
[0080]
s=[cls],d
11
,
…
,d
1m
,[sep],
…dij
…
,[cls],d
n1
,
…
,d
nx
,[sep];
[0081]
其中,d表示预处理后的数据中的某一篇文档,s表示标记文档,di表示文档中的第i句话,d
ij
表示文档中第i句话的第j个单词,[cls]和[sep]为每句话的分隔符;
[0082]
s22.对标记文档进行embedding,获取标记文档的文档词嵌入,文档词嵌入表示为:
[0083]
h=bert.embedding(s);
[0084]
h表示文档词嵌入,bert.embedding(
·
)表示embedding操作;
[0085]
s23.将文档词嵌入输入到bert模型中获取编码文档,编码文档表示为:
[0086]
td=bert(h);
[0087]
td=t
[cls]
,t
11
,
…
,t
1m
,t
[sep]
,
…
t
ij
…
,t
[cls]
,t
n1
,
…
,t
nx
,t
[sep]
表示编码文档,bert(
·
)表示bert模型,t
[sep]
和t
[cls]
表示编码数据中每句话的分隔符,t
ij
表示编码数据中第i句话的第j个单词。
[0088]
bert可以获取高质量的编码主要是因为其使用的多头注意力机制,多头注意力机制的具体的公式如下:
[0089][0090]
headi=attention(qw
iq
,kw
ik
,vw
iv
);
[0091]
multhead(q,k,v)=concat(head1,
…
,headh)wo;
[0092]
其中,attention(
·
)表示注意力机制;q表示查询向量,k表示键向量、v表示值向量;softmax(
·
)表示归一化函数,t为矩阵转置的标识,dk表示键向量的维度,headi为第h次投影得到的attention值,i为投影的次数,w
iq
为q向量训练权重矩阵,w
ik
为k向量训练权重矩阵,w
iv
为v向量训练权重矩阵,multhead(
·
)表示多头注意力机制的最终输出,wo为附加的权重矩阵,concat(
·
)为向量拼接。
[0093]
在一实施例中,使用bert进行编码之后,为了丰富文档的语义,同时使用关键词去外部知识库检索对应的外部知识,并且将外部知识通过门控机制和编码文档进行拼接融合,得到语义更丰富的融合文档,具体过程如下所示:
[0094]
外部知识库中的知识信息是由一个个三元组组成并进行存储的,三元组的表示如下:
[0095]
(e;r;o)
[0096]
其中,e代表主体,r代表关系,o代表对象。
[0097]
对于通过textrank获取的文档中的每个关键词keyi,在文档词嵌入h中获取对应的关键词词嵌入hi,并从外部知识库里检索其对应的知识信息,具体检索过程:根据关键词获取外部知识库中的同义词或者通过字符串匹配主体获取外部知识库中与其相关的关系和对象作为外部知识。
[0098]
检索到外部知识之后,使用线性运算衡量融合外部知识和关键词得到知识向量,具体公式如下所示:
[0099][0100]
c=[c1;
···
;ci;
···
;cn];
[0101]
其中,f(
·
)代表线性函数,e表示主体实体向量,即关键词,o表示对象实体向量,即根据关键词获取的外部知识,r表示e和o的关系,mr表示关系的嵌入矩阵,n表示关键词的个数,[;]表示向量拼接操作,ci表示第i个知识向量,n为关键词总数。
[0102]
门控机制用于去除知识向量多余的信息,筛选出重要信息,本实施例中通过门控机制筛选知识向量得到知识信息,将知识信息与编码文档进行融合,具体融合过程如下所示:
[0103]
key=[h1;
···
;hi;
···
;hn]
[0104]c′
=c
⊙
σ(key)
[0105]
t
′d=[td;c
′
]
[0106]
其中,hi代表第i个关键词通过文档词嵌入获取的关键词词嵌入,n代表关键词的个数,σ(
·
)代表sigmoid函数,
⊙
代表矩阵的点乘,td为文档经过bert的编码,w是可训练的矩阵,t
′d是外部知识和文档信息融合后的输出,[;]表示向量拼接操作,c
′
表示通过门控机制筛选后得到的知识信息。
[0107]
将知识信息和编码文档融合后的数据输入到transformer解码器进行解码,将解
码器的输出输入到一个全连接层,再经过一个softmax层,生成摘要,具体的公式如下所示:
[0108]
out=transformer(t
′d);
[0109]
p
vocab
=softmax(g[out]);
[0110]
其中,transformer(
·
)代表transformer解码器,t
′d代表知识信息和编码文档融合后的输出,g(
·
)代表全连接层,out表示transformer解码器的输出结果,p
vocab
表示词表中的词汇,即知识信息和编码文档融合后文档中的词成为摘要的概率。
[0111]
得到最终生成的摘要后,将该摘要与参考摘要进行损失函数计算,来判断模型训练的好坏,损失函数计算公式为:
[0112][0113]
其中,y
《t
={y1,y2,y3,
…
,y
t-2
,y
t-1
};y
t
代表摘要中的第t个单词;x代表输入的文档信息;θ代表可训练的模型参数;n代表输入的第n篇文档,t代表摘要的长度,n代表文档的数量。
[0114]
根据损失函数的计算,需要对模型参数进行优化,采用adam优化算法。adam是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重,相对于常用的sgd算法,adam有着计算高效、内存占用少、快速调参等优势。adam能够通过计算梯度的一阶矩估计和二阶矩估计为不同的参数设计独立的自适应性学习率。主要计算公式如下:
[0115][0116]
其中,表示校正后的一阶矩估计,表示校正后的二阶矩估计;μ表示步长,δ是为了维持数值稳定而添加的常数,θ表示要更新的参数。
[0117]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1