一种舆情监测方法和舆情监测系统
1.本发明涉及舆情监测技术领域,具体涉及一种舆情监测方法和舆情监测系统。
背景技术:
2.进入信息时代,互联网已经成为了当今社会进行信息传递的重要渠道和载体,基于互联网技术而生的社交媒体在社会生活中得到了广泛应用,人们早已将信息搜集的重心放到了网络社交平台上。但在大数据的时代背景下,网络媒体中的数据规模持续增长,数据形式越发多样,信息传播速度不断提高,这些改变为期待能够监控准确,响应迅速的舆情监控工作带来了不小挑战。已有的舆情监控系统存在以下问题:
3.1.采集数据的来源较少,信息不全面。大多网络舆情监控系统都只针对单一网站进行数据采集并分析,但如今各社交平台,网络媒体百花齐放,不同平台有不同平台的用户特点,各自的舆情数据也就有了不同的价值。多渠道采集舆情数据,才能更全面,准确的反应网络舆情的状况。
4.2.舆情检索不准确。大数据背景下,网络舆情数据规模庞大,信息繁杂。一些舆情监控系统直接使用用户提供的关键词进行信息采集,然而由于词汇多有近义词,不同时期可能有不同的网络流行词表达,并且词句可能有歧义等问题,直接使用初始关键词进行检索采集到的大多是寻常意义上的信息,无法获取到最全面的舆情数据以及用户关注的敏感舆情。
5.3.单文本情感分析的方法对反讽,语句歧义等问题解决效果较差。当下的情感分析方法大多是针对文本的情感分析,这类方法往往无法很好的识别反讽语句,因为这类语句抛弃上下文环境和正常语句相差甚微。而在如今的网络环境中,图片例如emoji,表情包等已经成为了人们表达情绪的重要补充,值得引起情感分析领域的关注。
技术实现要素:
6.本发明的目的在于提供一种舆情监测方法和舆情监测系统,以能够有效提高舆情数据的全面性以及准确性。
7.本发明解决上述技术问题的技术方案如下:
8.本发明提供一种舆情监测方法,所述舆情监测方法包括:
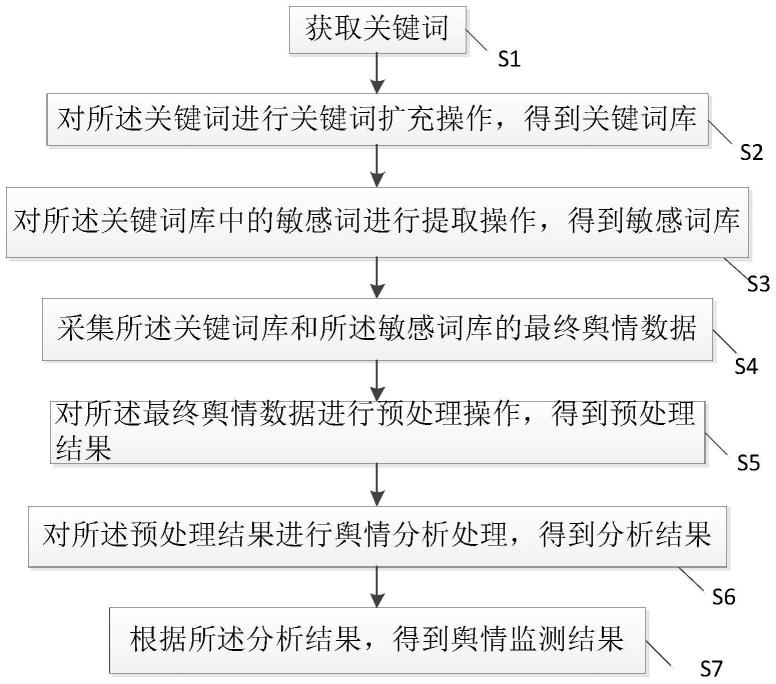
9.s1:获取用户输入的关键词;
10.s2:对所述关键词进行关键词扩充操作,得到关键词库;
11.s3:对所述关键词库中的敏感词进行提取操作,得到敏感词库;
12.s4:采集所述关键词库和所述敏感词库的最终舆情数据;
13.s5:对所述最终舆情数据进行预处理操作,得到预处理结果;
14.s6:对所述预处理结果进行舆情分析处理,得到分析结果;
15.s7:根据所述分析结果,得到舆情监测结果。
16.可选择地,所述步骤s2包括:
17.利用所述关键词在相关数据源中进行搜索,得到与所述关键词相匹配的多条数据信息;
18.根据所有所述数据信息,得到所述关键词库。
19.可选择地,所述步骤s3包括:
20.利用分词工具包对所述关键词库中所有数据进行分词操作,得到分词数据库;
21.将所有所述分词数据信息转换为词向量信息;
22.根据所述词向量信息,利用bilstm模型提取所述分词数据库中的负面词;
23.将所述负面词作为敏感词,得到所述敏感词库。
24.可选择地,所述步骤s4包括:
25.s41:配置数据采集表达式,并将所述关键词库和所述敏感词库合并为组合词库;
26.s42:利用所述组合词库检索相关舆情新闻列表;
27.s43:将所述相关舆情新闻列表的当前新闻页的网页地址加入待采集列表;
28.s44:从待采集列表中提取所述网页地址,访问所述当前新闻页的相关信息以形成初始舆情数据;
29.s45:若所述初始舆情数据同时满足完整性和唯一性,进入步骤s46,否则,进入步骤s47;
30.s46:将所述初始舆情数据作为所述最终舆情数据输出;
31.s47:判断所述当前新闻页是否为所述相关舆情新闻列表的最后一页,若是,返回步骤s46,否则,返回步骤s43。
32.可选择地,所述步骤s5包括:
33.对所述最终舆情数据进行分批处理,得到多批舆情数据;
34.利用正则表达式对每批所述舆情数据进行特殊字符和无用字符剔除处理,得到处理后的最终舆情数据;
35.对所述处理后的最终舆情数据进行数据特征提取操作,得到特征提取结果;
36.将所述特征提取结果作为所述预处理结果输出。
37.可选择地,所述舆情分析操作包括:一般统计性分析、关键词提取、热度计算和多模态情感分析。
38.可选择地,所述热度计算包括单个所述数据源的热度指数计算和多个所述数据源的热度指数计算,多个所述数据源的热度指数计算公式为:
[0039][0040]
其中,h为热度值,hi为第i个相关数据源的所有最终舆情数据的热度指数综合,wi为该相关数据源的热度权重;
[0041]
单个所述相关数据源的热度指数x的计算公式为:
[0042][0043]
其中,e为各相关数据源的用户关注指数,ts反映了相关舆情新闻的新鲜程度且ts=a-b,a为发布时间,b为采集时间,t代表的是3天一个热度周期内的总秒数且t=259200。
[0044]
可选择地,所述多模态情感分析包括:
[0045]
获取所述预处理结果中的图片特征和文字特征;
[0046]
根据所述图片特征和所述文本特征,训练图片文本对齐网络,得到训练好的图片文本对齐网络;
[0047]
根据所述图片特征和所述文本特征,利用所述训练好的图片文本对齐网络,得到融合特征;
[0048]
将所述融合特征作为分类器的输入,得到多模态情感分析结果;
[0049]
所述多模态情感分析模型的损失函数为:
[0050]
l=l
ca-l
da
[0051]
其中,l
ca
为交叉重建损失且m为样本数量,xj代表j模态的原始特征,dj表示j模态的编码器,ei代表i模态的编码器,xi代表i模态的原始特征,l
da
是分布对齐损失且w
ij
为模态i与j之间的2-wasserstein距离且其中,μ与均为编码器生成的隐藏层特征向量。
[0052]
可选择地,所述图片文本对齐网络包括:图片特征编码器、文本特征编码器、共享特征层和多个共享特征解码器,所述图片特征编码器和所述文本特征编码器同时连接所述共享特征层的输入端,多个所述共享特征编码器连接所述共享特征层的输出端,所述共享特征层还连接有分类器;
[0053]
所述图片特征编码器用于对所述图片特征进行编码;
[0054]
所述文本特征编码器用于对所述文本特征进行编码;
[0055]
多个所述共享特征解码器用于对所述共享特征进行解码,以输出重构图片特征和重构文本特征;
[0056]
所述分类器用于对所述共享特征进行分类,以对所述图片文本对齐网络进行训练。
[0057]
本发明还提供一种基于上述的舆情监测方法的舆情监测系统,所述舆情监测系统包括:
[0058]
关键词获取模块,所述关键词获取模块用于获取关键词;
[0059]
关键词扩充模块,所述关键词扩充模块用于对所述关键词进行扩充;
[0060]
敏感词提取模块,所述敏感词提取模块用于对关键词库中的敏感词进行提取;
[0061]
舆情数据采集模块,所述舆情数据采集模块用于采集所述关键词库和所述敏感词库的最终舆情数据;
[0062]
数据预处理模块,所述数据预处理模块用于对所述最终舆情数据进行预处理操作;
[0063]
舆情分析模块,所述舆情分析模块用于对预处理结果进行分析;
[0064]
舆情报告模块,所述舆情报告模块用于将舆情监测结果展示给用户。
[0065]
本发明具有以下有益效果:
[0066]
1、本发明能够提高舆情情感分析准确率;
[0067]
2、关键词扩展、敏感词提取的方法组合形成新的检索词,可以有效,全面的检索出用户关注的敏感舆情;
[0068]
3、基于多个相关数据源进行信息采集,并提供可扩展数据采集接口,能够解决当经舆情监测系统采集数据的来源少,信息不全面的问题。
附图说明
[0069]
图1为本发明所提供的舆情监测方法的流程图;
[0070]
图2为图1中步骤s4的分步骤流程图;
[0071]
图3为本发明所提供的多模态情感分析模型的结构示意图。
具体实施方式
[0072]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
[0073]
实施例
[0074]
本发明提供一种舆情监测方法,参考图1所示,所述舆情监测方法包括:
[0075]
s1:获取用户输入的关键词;
[0076]
这里的关键词一般为用户输入关键词。
[0077]
s2:对所述关键词进行关键词扩充操作,得到关键词库;
[0078]
所述步骤s2包括:
[0079]
利用所述关键词在相关数据源中进行搜索,得到与所述关键词相匹配的多条数据信息;
[0080]
这里,相关数据源包括但不限于微博、今日头条、网易新闻、腾讯新闻等数据源;搜索方式包括使用tf-idf算法和textrank算法找出搜索文章中的关键词。
[0081]
tf-idf是一种用于信息检索与文本挖掘的常用加权技术,是一种统计方法,用以评估一个字词对于一个文件集或一个语料库的其中一份文件的重要程度。tf表示词条在文本中出现的频率,公式为表示词i在文档j中的词频,n
i,j
表示词i在文档j中出现的次数,表示j文档中所有词出现的次数总和。idf是逆向文件频率,|d|是语料库中的文件总数,分母|j:ti∈dj|表示包含词语ti的文件数目。某个词i对某个类别描述文本j的tf-idf值计算如下:tf-idf
i,j
=tf
i,j
*idfi[0082]
若某词某一特定文件内的高词语频率,以及该词语在整个文件集合中有低文件频率,则能够产生出高权重的tf-df,因此可以过滤掉常见的词语保留重要的词语,做到关键词的提取。
[0083]
textrank是基于pagerank的思想改进而来,它是一种基于图的用于关键词抽取和文档摘要的排序算法,利用一篇文档内部的词语间的贡献信息便可以抽取关键词,它能够从一个给定的文本中抽取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法抽
取出该文本的关键词。textrank的基本思想是将文档看做一个词的网络,该网络中的链接表示词与词之间的语义关系。公式如下:
[0084][0085]
其中ws(vi)表示句子i的权重,右侧的求和表示每个相邻句子对本句子的贡献程度,在单文档中,我们可以粗略的认为所有句子都是相邻的,不需要像多文档一样进行多个窗口的生成和抽取,仅需单一文档窗口即可,w
ij
表示两个句子的相似度,ws(vj)代表上次迭代出的句子j的权重。d是阻尼系数,一般为0.85。
[0086]
从上文可以很明显的看出tf-idf适合于提取一篇文章中的稀有词,意在找出文章中出现的频率高,但是在语料库中出现频率较低的词,适合于找出一些特征词出来,而textrank算法是单纯的通过图算法提取出一篇文章的关键词,抛开了语料库,适合于寻找常规的关键词。我们将这两种方法同时使用,找出对应领域的常规关键词以及特异词来进行关键词库的扩充。
[0087]
根据所有所述数据信息,得到所述关键词库。
[0088]
s3:对所述关键词库中的敏感词进行提取操作,得到敏感词库;
[0089]
可选择地,所述步骤s3包括:
[0090]
利用分词工具包对所述关键词库中所有数据进行分词操作,得到分词数据库;本发明中采用的分词工具包为jieba分词工具包。
[0091]
将所有所述分词数据信息转换为词向量信息;
[0092]
由于机器无法识别分词,因此将分词数据信息转化为词向量信息,以便于机器识别。
[0093]
根据所述词向量信息,利用bilstm模型提取所述分词数据库中的负面词;本发明通过情感分析模型bilstm对分词结果进行情感分析,模型对每个词会计算得出一个在[-1,1]间的情感分值,约接近-1代表该词为负面词的可能性越大,越接近1则代表该词为正面词的可能性越大。接着按照情感极性分数进行递增排序取出前m个负面词加入到敏感词库。
[0094]
将所述负面词作为敏感词,得到所述敏感词库。
[0095]
s4:采集所述关键词库和所述敏感词库的最终舆情数据;
[0096]
最终舆情数据包括文章主题,发布时间,内容全文,转发数,评论数,点赞数,发布用户认证信息,等级,地域等信息(若存在)。
[0097]
具体地,参考图2所示,所述步骤s4包括:
[0098]
s41:配置数据采集表达式,并将所述关键词库和所述敏感词库合并为组合词库;这里,数据采集表达式主要为css表达式或xpath表达式。
[0099]
s42:利用所述组合词库检索相关舆情新闻列表;
[0100]
s43:将所述相关舆情新闻列表的当前新闻页的网页地址加入待采集列表;
[0101]
s44:从待采集列表中提取所述网页地址,访问所述当前新闻页的相关信息以形成初始舆情数据;
[0102]
这里,相关信息包括提取文章标题,发布时间,文章正文等信息。
[0103]
s45:若所述初始舆情数据同时满足完整性和唯一性,进入步骤s46,否则,进入步骤s47;
[0104]
完整性和唯一性即为:例如若提取的为新闻文章,那么若文章标题缺失或文章内容缺失将被视为不完整数据丢弃,若提取到的数据已经在数据库中(数据重复)那么数据也不再存入。
[0105]
s46:将所述初始舆情数据作为所述最终舆情数据输出;
[0106]
s47:判断所述当前新闻页是否为所述相关舆情新闻列表的最后一页,若是,返回步骤s46,否则,返回步骤s43。
[0107]
s5:对所述最终舆情数据进行预处理操作,得到预处理结果;
[0108]
可选择地,所述步骤s5包括:
[0109]
对所述最终舆情数据进行分批处理,得到多批舆情数据;
[0110]
利用正则表达式对每批所述舆情数据进行特殊字符和无用字符剔除处理,得到处理后的最终舆情数据;
[0111]
对所述处理后的最终舆情数据进行数据特征提取操作,得到特征提取结果;文本数据采用已开源的albert中文预训练模型提取768维的语义向量。图片数据采用已开源的resnet101预训练模型提取2048维的图片特征向量。
[0112]
将所述特征提取结果作为所述预处理结果输出。
[0113]
s6:对所述预处理结果进行舆情分析处理,得到分析结果;
[0114]
可选择地,所述舆情分析操作包括:一般统计性分析、关键词提取、热度计算和多模态情感分析。
[0115]
一般统计性分析包含,关键词及相似关键词相关的舆情数据总数,各网站舆情数据占比,舆情数据量分时段统计信息,舆情数据发布的地域分布信息;
[0116]
关键词提取包括:一个关键词搜索可能得到多个相关舆情事件,而一个舆情事件包含多条舆情数据。对每个独立事件的分析也对舆情分析至关重要。本发明采用tf-idf算法和textrank算法提取相关事件中的舆情关键词,用于舆情报告模块中形成舆情关键词云以及舆情分关键词的热度计算。
[0117]
热度计算包括:将舆情数据按检索词分类/所属事件分类/所属事件中的关键词分类可分别计算这几个维度的舆情热度。舆情的热度计算本发明以传统的社会化媒体算法reddit作为基础,分别针对社交媒体舆情数据(微博),网络媒体舆情数据(今日头条,腾讯新闻,网易新闻)设计了不同的热度计算方法计算不同平台的舆情热度指数,然后为不同平台的舆情热度赋予权重将所有平台的相关舆情数据的热度指数乘以权重再相加得到关键词相关的舆情的多源舆情热度指数。
[0118]
可选择地,所述热度计算包括单个所述数据源的热度指数计算和多个所述数据源的热度指数计算:
[0119]
单个所述相关数据源的热度指数x的计算公式为:
[0120][0121]
其中,e为各相关数据源的用户关注指数,ts反映了相关舆情新闻的新鲜程度且ts=a-b,a为发布时间,b为采集时间,t代表的是3天一个热度周期内的总秒数且t=259200。
[0122]
对于单个相关数据源为微博时,e=用户类型(6
×
转发数+3
×
评论数+1
×
赞数),且用户类型及其对应权重为:"普通用户":1,"微博女郎":1.5,"达人":2,"蓝v":4,"黄v":
4,"金v":10;log10的使用也可以使得早期的转评赞获得更大的权重。
[0123]
在各新闻网络媒体中没有同微博一样的用户类型明细划分,但热度指数计算的原理相似,因此除e计算与微博热度指数计算不同外,其他计算步骤相同。
[0124]
根据分析数据特点,得到网络媒体热度计算公式中的e计算为:e=8
×
转发数+5
×
评论数+2
×
赞数
[0125]
多个所述数据源的热度指数计算公式为:
[0126][0127]
其中,h为热度值,hi为第i个相关数据源的所有最终舆情数据的热度指数综合,wi为该相关数据源的热度权重。
[0128]
多模态情感分析包括:由于不同模态(图片,文本)间的数据存在领域差异,融合多个模态间的特征也是一大难题。本软件的情感分析模块,分别为图,文数据构造了一个编码器和解码器,采用vae思想对齐图文特征,并将其特征融合到一个单独的隐藏层中形成共享特征表示层,采用共享特征表示层生成的融合特征来训练舆情数据的情感分类器,最终得到多模态舆情数据的情感倾向分数。
[0129]
所述多模态情感分析模型的损失函数为:
[0130]
l=l
ca-l
da
[0131]
其中,l
ca
为交叉重建损失且m为样本数量,xj代表j模态的原始特征,dj表示j模态的编码器,ei代表i模态的编码器,xi代表i模态的原始特征,l
da
是分布对齐损失且w
ij
为模态i与j之间的2-wasserstein距离且其中,μ与均为编码器生成的隐藏层特征向量。
[0132]
可选择地,所述多模态情感分析包括:
[0133]
获取所述预处理结果中的图片特征和文字特征;
[0134]
根据所述图片特征和所述文本特征,训练图片文本对齐网络,得到训练好的图片文本对齐网络;
[0135]
这里,训练好的图片文本对齐网络即为能够较好融合图片与文本对应语义信息的图片文本对齐网络。
[0136]
根据所述图片特征和所述文本特征,利用所述训练好的图片文本对齐网络,得到融合特征;
[0137]
将所述融合特征作为分类器的输入,得到多模态情感分析结果。
[0138]
s7:根据所述分析结果,得到舆情监测结果。
[0139]
可选择地,参考图3所示,所述图片文本对齐网络包括:图片特征编码器、文本特征编码器、共享特征层和多个共享特征解码器,所述图片特征编码器和所述文本特征编码器同时连接所述共享特征层的输入端,多个所述共享特征编码器连接所述共享特征层的输出
端,所述共享特征层还连接有分类器;
[0140]
所述图片特征编码器用于对所述图片特征进行编码;
[0141]
所述文本特征编码器用于对所述文本特征进行编码;
[0142]
多个所述共享特征解码器用于对所述共享特征进行解码,以输出重构图片特征和重构文本特征;
[0143]
所述分类器用于对所述共享特征进行分类,以对所述图片文本对齐网络进行训练。
[0144]
本发明还提供一种基于上述的舆情监测方法的舆情监测系统,所述舆情监测系统包括:
[0145]
关键词获取模块,所述关键词获取模块用于获取关键词;
[0146]
关键词扩充模块,所述关键词扩充模块用于对所述关键词进行扩充;
[0147]
敏感词提取模块,所述敏感词提取模块用于对关键词库中的敏感词进行提取;
[0148]
舆情数据采集模块,所述舆情数据采集模块用于采集所述关键词库和所述敏感词库的最终舆情数据;
[0149]
数据预处理模块,所述数据预处理模块用于对所述最终舆情数据进行预处理操作;
[0150]
舆情分析模块,所述舆情分析模块用于对预处理结果进行分析;
[0151]
舆情报告模块,所述舆情报告模块用于将舆情监测结果展示给用户。
[0152]
本发明具有以下有益效果:
[0153]
1、本发明能够提高舆情情感分析准确率;
[0154]
2、关键词扩展、敏感词提取的方法组合形成新的检索词,可以有效,全面的检索出用户关注的敏感舆情;
[0155]
3、基于多个相关数据源进行信息采集,并提供可扩展数据采集接口,能够解决当经舆情监测系统采集数据的来源少,信息不全面的问题。
[0156]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1