一种基于聚类的管网分区及跨区水量调配的方法与流程
1.本发明涉及供水技术领域,具体涉及一种基于聚类的管网分区及跨区水量调配的方法。
背景技术:
2.随着我国经济水平的快速发展,尤其是城市化进程的不断推进,城镇人口规模和占地面积的大幅增长,供水管网也逐渐变得大型化而且更加复杂;原本靠人工经验的管网调度受不确定性因素影响很大、无法快速应对短期水量调配的需要,因此亟需针对大型管网的、更科学的管网调度技术。
3.目前采用较多的是分级分区技术,一般在一级层面考虑水量平衡或行政管理分区,在二级层面基于压力、流量管理分区,而三级则考虑到更精细的管控需要,如漏损控制等。大尺度的一级分区是多级调度的基础,但现有的方法主要依赖人工经验,属于工程试错,因此缺乏较为科学的规划且无法自动划分;而已有的聚类算法在分区上的应用直接考虑小尺度的管理需求,不适宜较大尺度的一级分区且没有考虑多水源造成的分区水量不平衡影响,由此较难制定行之有效的管网调度计划。
技术实现要素:
4.本发明的目的是设计一种基于聚类的管网分区及跨区水量调配的方法,能够对供水管网进行大尺度的科学分区并满足其水量调配需求,实现基于水量平衡的管网调度,提供决策依据。
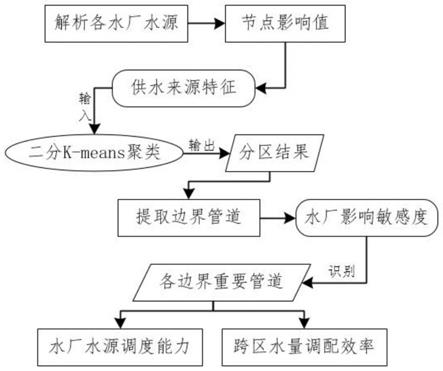
5.为实现上述目的,本发明提供如下技术方案:一种基于聚类的管网分区及跨区水量调配的方法,首先通过水厂供水范围的解析,生成节点的供水来源特征,然后利用聚类算法划分合理的分区、确定合理的分区数和分区范围,之后根据敏感性分析对跨区的重要管道进行识别,接着分析各个水厂的调配能力,最终得到当前分区方案下区域间的调水效率,具体包括以下步骤:
6.步骤一:利用管网模拟软件对供水管网中的水厂水源进行延时水力模拟,所述管网模拟软件为epanet,计算节点的受影响流量值;粒子追踪作为一种进行物质追踪的方法,将输出点的浓度描述为输入源强度的线性函数,所述函数见公式(1):
[0007][0008]
其中,c0为输出点浓度;n为输入输出之间的行程路径数;t0为输出时间;cj为水质源输入强度;tj为行程路径j的延时;γj为行程路径j的影响系数;水质源输入强度cj和影响系数γj的单位取决于所使用的源模型。
[0009]
根据上述公式(1),将水厂水源作为输入源增加流量,将各个节点作为输出点计算流量增加值,作为节点影响度的衡量。
[0010]
步骤二:根据步骤一得到的节点影响值,构建全部节点的供水来源特征;即将水厂
水源对各个节点的影响值按节点id进行聚合,得到每一个节点对应的水厂影响值,然后再将节点的水厂影响值转化为节点的受水厂影响占比,进而构建了所有节点的供水来源特征;需要说明的是,当某些节点id不受某个水厂影响时,影响值缺省为“0”。
[0011]
步骤三:将步骤二得到的供水来源特征作为模型输入,基于二分k-means聚类得到分区结果;即将所有节点的供水来源结构特征作为训练集,输入至二分k-means聚类模型中,训练后输出各种不同簇类的节点集合,从而得到各种不同k值的分区方案。
[0012]
利用k-sse曲线的降速变缓点作为评估依据,结合具体的管网情况,确定最终的k类分区方案;即对比管网的水厂分布位置,判断当前分区能否保证各水厂较为均匀地分配至各区,考虑分区内包含多个水厂的情况;比较各分区边界是否清晰,是否存在局部节点散乱、分界线不明显;如果分区边界清晰、局部节点不散落、分界线明显,则当前分区效果较好,可以直接完成分区或考虑增加聚类分区的数目;如果边界不清晰、局部节点散乱、分界线不明显,则说明当前的分区效果比较差,分区需要合并,减少聚类分区的数目。
[0013]
需要说明的是,二分k-means模型是基于二分法(binary split)对k-means进行的改进;k是聚类算法中预先设定的,代表聚类簇数;sse(sum ofsquares error)是误差平方和,衡量聚类的效果。
[0014]
步骤四:从步骤三中的分区结果中提取边界管道,计算管道对水厂影响的敏感度;即具体的节点分区转化为节点信息表(节点id、分区编号id),结合管道信息表(管道id、头节点id、尾节点id)匹配每个管道头、尾节点对应的分区编号。
[0015]
再利用异或运算判断是否管道头尾是属于不同区的节点,从而判断是否为分区边界的管道,进而自动提取边界的管道信息。
[0016]
最后利用敏感性分析(sensitivityanalysis)、结合供水管网中的水厂水源进行延时水力模拟,依次改变各水厂水源的出水压力或出水流量,按分区边界汇总、统计提取的边界管道的响应流量,作为各边界管道对水厂影响的敏感度。
[0017]
步骤五:根据步骤四得到的管道对水厂影响的敏感度,识别边界的重要管道;具体是利用最优切分算法对跨区重要管道进行识别,应用步骤为:
①
将边界管道按流量变化值的降序排列;
②
对于n根管道,确定n-1个切分点,将管道分为两组,遍历切分点的位置;
③
基于某个目标函数确定最优的切分策略,通常基于平方误差的最小化,如公式(2)所示:
[0018][0019]
其中,y为最终的优化目标,使其最小化;s为切分点,r1(s)与r2(s)分别代表被切分后的两组数据,c1与c2分别代表两组数据的平均值。
[0020]
在进行具体划分时,同时融合两个策略,其一利用最优切分算法寻找所谓的最优的切分点,其二判断当前切分的管道流量占比是否占原流量的85%,若无则移至下一个切分点,直至达到原流量的85%;需要说明的是,通过约束跨区重要管道的流量占比85%以上,避免因管道流量的极端分布导致过多的数据被筛除。
[0021]
根据最优切分算法和当前切分的管道流量占比确定的最优切分点,即可得到各边界的重要管道集合。
[0022]
步骤六:计算水厂水源的调度能力与跨区水量调配效率,即根据各边界重要管道
集合,分别测试受各水厂影响的响应流量,从而得到水厂水源的调度能力与跨区水量调配效率。具体而言,应用步骤为:针对各个水厂分别增加1000方/小时的出水流量;统计与该水厂所在分区相邻的分区其边界上重要管道的供水总流量,得到水厂水源在该边界的流量调度能力,汇总各边界的流量占比,即得到流量的传递效率;针对各个水厂分别绘制边界供水效率图。
[0023]
与现有技术相比,本发明的有益效果:使用本发明基于聚类的管网分区及跨区水量调配的方法,先分析水厂供水范围再利用聚类算法划分分区,分区后对重要管道进行识别、分析各水厂的调配能力,可以得到当前分区方案下区域间的调水效率,如此能够对供水管网进行大尺度的科学分区并满足其水量调配需求,实现基于水量平衡的管网调度,提供决策依据。
附图说明
[0024]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0025]
图1为本发明的步骤流程图;
[0026]
图2为本发明的二分k-means聚类分区方案输入输出图;
[0027]
图3为本发明的重要管道识别的计算流程图;
具体实施方式
[0028]
下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0029]
实施例:请参考图1,一种基于聚类的管网分区及跨区水量调配的方法,首先通过水厂供水范围的解析,生成节点的供水来源特征,然后利用聚类算法划分合理的分区、确定合理的分区数和分区范围,之后根据敏感性分析对跨区的重要管道进行识别,接着分析各个水厂的调配能力,最终得到当前分区方案下区域间的调水效率,具体包括以下步骤:
[0030]
步骤一:利用管网模拟软件对供水管网中的水厂水源进行延时水力模拟,所述管网模拟软件为epanet,计算节点的受影响流量值;粒子追踪作为一种进行物质追踪的方法,将输出点的浓度描述为输入源强度的线性函数,所述函数见公式(1):
[0031][0032]
其中,c0为输出点浓度;n为输入输出之间的行程路径数;t0为输出时间;cj为水质源输入强度;tj为行程路径j的延时;γj为行程路径j的影响系数;水质源输入强度cj和影响系数γj的单位取决于所使用的源模型。
[0033]
根据上述公式(1),将水厂水源作为输入源增加流量,将各个节点作为输出点计算流量增加值,作为节点影响度的衡量。
[0034]
步骤二:根据步骤一得到的节点影响值,构建全部节点的供水来源特征;即将水厂水源对各个节点的影响值按节点id进行聚合,得到每一个节点对应的水厂影响值,然后再将节点的水厂影响值转化为节点的受水厂影响占比,进而构建了所有节点的供水来源特征;需要说明的是,当某些节点id不受某个水厂影响时,影响值缺省为“0”。
[0035]
步骤三:将步骤二得到的供水来源特征作为模型输入,基于二分k-means聚类得到分区结果,所涉及的基于二分k-means聚类的分区方案请参考图2;即将所有节点的供水来源结构特征作为训练集,输入至二分k-means聚类模型中,训练后输出各种不同簇类的节点集合,具体实施中,具体实施时,可以使用pam算法优化聚类的过程,提升分区效果。另外,需要根据“k-sse曲线”的降速变缓点、管网实际情况选定k值,得到最合适的分区方案,即对比管网的水厂分布位置,判断当前分区能否保证各水厂较为均匀地分配至各区,考虑分区内包含多个水厂的情况;比较各分区边界是否清晰,是否存在局部节点散乱、分界线不明显;如果分区边界清晰、局部节点不散落、分界线明显,则当前分区效果较好,可以直接完成分区或考虑增加聚类分区的数目;如果边界不清晰、局部节点散乱、分界线不明显,则说明当前的分区效果比较差,分区需要合并,减少聚类分区的数目。
[0036]
需要说明的是,二分k-means模型是基于二分法(binary split)对k-means进行的改进;k是聚类算法中预先设定的,代表聚类簇数;sse(sum ofsquares error)是误差平方和,衡量聚类的效果。
[0037]
步骤四:从步骤三中的分区结果中提取边界管道,计算管道对水厂影响的敏感度;即具体的节点分区转化为节点信息表(节点id、分区编号id),结合管道信息表(管道id、头节点id、尾节点id)匹配每个管道头、尾节点对应的分区编号。
[0038]
再利用异或运算判断是否管道头尾是属于不同区的节点,从而判断是否为分区边界的管道,进而自动提取边界的管道信息。
[0039]
最后利用敏感性分析(sensitivityanalysis)、结合管网水力模拟,依次改变各水厂水源的出水压力或出水流量,按分区边界汇总、统计提取的边界管道的响应流量,作为各边界管道对水厂的影响敏感度。
[0040]
步骤五:根据步骤四得到的各边界管道对水厂的敏感度,识别边界的重要管道,所涉及的跨区重要管道识别的计算流程如图3所示;具体是利用最优切分算法对跨区重要管道进行识别,应用步骤为:
①
将边界管道按流量变化值的降序排列;
②
对于n根管道,确定n-1个切分点,将管道分为两组,遍历切分点的位置;
③
基于某个目标函数确定最优的切分策略,通常基于平方误差的最小化,如公式(2)所示:
[0041][0042]
其中,y为最终的优化目标,使其最小化;s为切分点,r1(s)与r2(s)分别代表被切分后的两组数据,c1与c2分别代表两组数据的平均值。
[0043]
在进行具体划分时,同时融合两个策略,其一利用最优切分算法寻找所谓的最优的切分点,其二判断当前切分的管道流量占比是否占原流量的85%,若无则移至下一个切分点,直至达到原流量的85%;需要说明的是,通过约束跨区重要管道的流量占比85%以上,避免因管道流量的极端分布导致过多的数据被筛除。
[0044]
根据最优切分算法和当前切分的管道流量占比确定的最优切分点,即可得到各边界的重要管道集合。
[0045]
步骤六:计算水厂水源的调度能力与跨区水量调配效率,即根据各边界重要管道集合,分别测试受各水厂影响的响应流量,从而得到水厂水源的调度能力与跨区水量调配效率。具体而言,应用步骤为:针对各个水厂分别增加1000方/小时的出水流量;统计与该水厂所在分区相邻的分区其边界上重要管道的供水总流量,得到水厂水源在该边界的流量调度能力,汇总各边界的流量占比,即得到流量的传递效率;针对各个水厂分别绘制边界供水效率图。
[0046]
使用本发明基于聚类的管网分区及跨区水量调配的方法,先分析水厂供水范围再利用聚类算法划分分区,分区后对重要管道进行识别、分析各水厂的调配能力,可以得到当前分区方案下区域间的调水效率,如此能够对供水管网进行大尺度的科学分区并满足其水量调配需求,实现基于水量平衡的管网调度,提供决策依据;此决策依据这主要指的两个方面,一方面是帮助管网管理者进行合适的供水分区;另外一方面是为调度人员提供可靠信息,当某些地区缺水,有邻区调水需求时,可以根据管道的调度能力判断应该启停哪个位置的管道阀门;
[0047]
聚类方法原理简单、计算逻辑清晰,涉及的参数意义明确,水务人员收集节点的水源流量数据集后,能够直接运用该方法进行分区。
[0048]
基于聚类的大型管网分区方法贴合水量平衡的需要,综合利用聚类算法及模拟技术,可以有效地提升水务信息化程度。
[0049]
涉及到的跨区重要管道识别方法计算公式非常简单,实用性很强,便于后续水量调度计划的管理。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1