一种代码缺陷的自动定位与修复方法
1.本发明涉及人工智能技术领域,尤其涉及一种代码缺陷的自动定位与修复方法。
背景技术:
2.代码缺陷的自动定位与修复技术是自动化软件调试的两个重要研究方向,其中缺陷定位技术能够针对不同语法粒度(类、方法、语句等粒度),自动计算出程序元素的出错概率并按照概率排序生成定位文件;缺陷修复技术能够按照给定的语句顺序(一般来源于定位文件),逐步尝试生成正确的程序补丁,并完成补丁语义的正确性评估。两者都旨在帮助降低软件开发过程中寻找与修复缺陷所花费的人力与时间成本。
3.对于缺陷的自动定位任务,早期的技术大都基于对测试用例动态执行信息的统计分析,主要包含基于频谱的缺陷定位(spectrum-based fault localization)与基于变异测试的缺陷定位(mutation-based fault localization)技术。对于前者,通过运行人工编写的测试用例,工具能够自动获取程序语句的运行轨迹(即频谱)以及最终的测试结果,并统计不同语句被正确或错误的测试用例执行的次数,之后以此为特征设计公式来计算语句的出错概率;对于后者,方法使用预定义的变异算子对源代码语句进行修改,并在所有变异后的程序(变异体)上运行测试用例,得到变异体的频谱和测试结果,之后统计哪些语句的变异体能导致测试用例的运行信息发生变化,以此作为特征设计公式来计算语句的出错概率。近年来,基于机器学习(深度学习)的缺陷定位方法成为了研究热点,它将前述方法计算得到的语句出错概率作为输入特征,并与文本相似度、代码复杂度等其他维度的特征进行融合,通过监督学习的机制训练二分类器并预测语句的出错概率。
4.对于缺陷的自动修复任务,基于模板的修复方法(template-based program repair)与基于深度学习的修复方法(deep learning-based program repair)是两条主流的研究路线。对于前者,方法首先针对修复的目标,预先选择通用的或满足特定需求(如内存溢出)的修复模板,之后按照定位文件给出的顺序逐语句、逐模板地尝试生成修复补丁,最后对补丁进行正确性评估。对于后者,近年来的技术大多基于神经机器翻译(neural machine translation,nmt)框架,将代码语句的修复任务看作一个序列到序列的翻译过程。这个过程包含编码(encode)和解码(decode)两个部分:编码时,既可以将输入的源代码简单地拆分成单词序列,也可以通过解析语法树等方式保留其特有的语法结构信息;解码时,以编码得到的中间特征作为输入,逐步计算下一个单词的概率值并输出结果,以生成完整的代码补丁。
5.现有技术存在如下问题:
6.1.基于深度学习的定位方法相比基于频谱、基于变异测试的方法能够取得更好的效果,但是其输入特征中不包含能直接反映语句出错原因的深层语义特征,这阻碍了定位性能的进一步提升。
7.2.基于神经机器翻译的修复方法在训练时采用最大似然策略,因此更倾向于生成出现频率较高的单词,而忽略了出现频率较低的单词(往往是特定于项目的单词,例如变量
名、函数名等),而基于模板的修复方法是从同一个文件(或项目)中寻找语法适配的单词填充模板以生成完整的程序补丁,因此能较好地解决这个问题。然而对于后者,在选择修复模板时,现有的工作只能按照预先定义的固定顺序逐个选择模板进行尝试,并不能借助特定的知识针对不同程序语句的特点来动态生成修复模板的选择顺序,这会引起修复性能与修复效率的下降。
技术实现要素:
8.为此,本发明提出一种代码缺陷的自动定位与修复方法,包括缺陷语义知识学习、缺陷定位、缺陷自动修复三个模块:所述缺陷语义知识学习模块应用于在线训练阶段,所述缺陷定位与缺陷自动修复模块应用于离线应用阶段,需要以目标项目中的数据作为输入,方法在实际离线应用时,只需要两部分输入,其一是待修复的项目源代码,其二是待修复项目作者编写的人工测试用例;所述缺陷语义知识学习模块设计了基于双向lstm的二分类器和多分类器模型,并通过监督学习机制在构建的大规模数据集上学习与代码缺陷相关的语义知识;所述缺陷定位模块首先将所述缺陷语义知识学习模块中已训练好的二分类器模型应用于目标数据集上,针对每条输入的目标程序语句,预测得到面向11种缺陷类型的出错概率作为深度语义特征,之后设计了基于多层感知机的排序模型,融合深度语义特征、基于频谱的特征与基于变异测试的特征,为目标程序语句预测出错概率,并根据概率对目标项目中的全部语句进行排序,以生成定位文件;所述缺陷自动修复模块借助迁移学习,复用了所述缺陷语义知识学习模块中已训练好的多分类器模型,使用目标项目开发历史中的缺陷数据做二次训练,并用于预测输入的目标程序语句被各修复模板成功修复的概率,以确定修复模板的选择顺序;最终,所述缺陷定位模块输出一份更准确的定位文件,每一行使用“文件的绝对路径”与“目标语句在该文件中的位置”来唯一指定一条程序语句,将含有缺陷的语句排在定位文件中更靠前的位置,所述缺陷自动修复模块输出一个包含11个修复模板的有序列表,并根据定位文件与模板列表中的顺序逐语句、逐模板生成并输出标准格式的修复补丁。
9.所述11种常用的修复模板,包括空指针检查、添加缺失语句、修改条件表达式、修改数据类型、修改常量、修改变量、修改函数调用、修改操作符、修改返回语句、移动语句、删除语句。
10.所述大规模定位数据集包含11个子数据集,对应11种修复模板,每种修复模板唯一对应一种能够修复的缺陷类型,每个子数据集中包含两种标签的数据,一种是含有该类型缺陷的数据作为正样本,另一种是不含有该类型缺陷的数据作为负样本,每个样本由一条程序语句以及它所在的函数构成的,所述程序语句的开始和结束位置使用特殊符号《s》和《/s》进行标记,之后,借助长短时记忆网络构建基于双向lstm的二分类器模型,包含嵌入层、循环层、池化层和输出层,所述输出层为2维,针对每种缺陷类型,以该类型所包含的正负样本数据作为训练集,来训练一个二分类器,使其拥有判别输入语句是否含有该类别缺陷的能力。
11.所述大规模修复数据集含有11种标签的数据,对应11类修复模板,所述大规模修复数据集中只包含出错的样本,对应定位数据集每一个子数据集中的正样本,设计一个基于双向lstm的多分类器模型,包含嵌入层、循环层、池化层和输出层,所述输出层为11维,使
用构建的修复数据集来训练这个多分类器,使其拥有能判别输入语句更可能被哪个修复模板成功修复的能力。
12.所述缺陷定位模块设计一个基于多层感知机的二分类器模型来融合基于频谱的特征、基于变异测试的特征、基于深度语义的特征三种帮助缺陷定位的特征,并通过监督学习机制进行训练,使其能够获得判别输入语句是否含有缺陷的能力,用来预测结合三种特征之后的程序语句的出错概率,生成定位文件。
13.所述基于频谱的特征获取方式为:给定一个项目p以及与待修复缺陷相关的测试用例集合t={t1,t2,
…
,tn},通过在p上运行这些测试用例,可以分别得到程序语句的运行轨迹集合s={s1,s2,
…
,sn}以及测试结果集合r={r1,r2,
…
,rn},集合s中的每条运行轨迹sk包含数量不等的语句,把集合s中涉及到的全部语句整理为语句集合u={u1,u2,
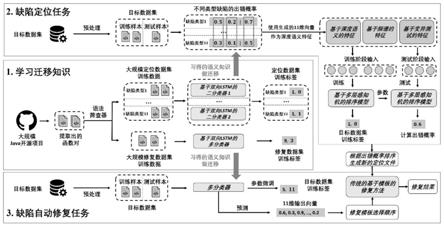
…
,um},这个集合中的语句是与待修复缺陷相关的语句,包含正确语句和错误语句两类,而缺陷定位的任务就是将其中的错误语句尽可能排在靠前的位置,采用ochiai、tarantula、dstar三种基于频谱的经典算法,为每条候选语句生成三个概率值作为基于频谱的特征。
14.所述基于变异测试的特征获取方式为:针对语句集合u中的任意语句uk,首先使用与pit变异测试工具中相同的16个变异算子对uk进行变异,得到uk的变异体集合并在全部的变异体中运行测试用例,收集全部测试结果,之后在四个不同的粒度上分别统计测试用例运行状态的变化情况,分别是“测试结果”、“测试结果+异常类型”、“测试结果+异常类型+异常信息”、“测试结果+异常类型+异常信息+函数调用轨迹”,选择适用于变异测试的ochiai定制算法来分别计算程序语句在四个粒度上的出错概率,并把它们统称为基于变异测试的特征。
15.所述深度语义特征的实现方式为:基于双向lstm的二分类器模型,分别以大规模定位数据集中的11种特定缺陷类型的训练数据作为输入,通过监督学习机制迭代优化并保存11种最优模型参数,把这些参数中蕴含的缺陷语义知识迁移到目标数据集上,即将目标数据集中的程序语句作为输入,借助已训练好的模型,预测生成11个面向特定缺陷类型的出错概率值,并把它们统称为深度语义特征。
16.所述基于多层感知机的二分类模型的实现方式为:输入层共包含3+4+11=18维输入特征,首先使用一个“语义信息融合层”将深度语义特征从11维降到4维,之后再使用一个“多输入信息融合层”融合三种不同的特征,最终通过输出层得到语句的出错概率,目标项目中的程序语句按照其预测的出错概率值从高到低进行排序,生成定位文件。
17.所述缺陷自动修复模块包含五个步骤,即选择待修复的语句,选择需要的修复模板,生成补丁,运行测试用例进行自动化测试,人工检查;一旦所述缺陷自动修复模块发现有补丁可以通过全部的测试用例,修复进程立刻结束运行;为了应对在一些情况下,当一个错误的模板被更早选择时,可能会有错误补丁生成,导致修复进程被提前终止,从而失去选择正确修复模板机会的问题,需要对模板的选择顺序做优化,使正确的修复模板能更早被选中,在为目标程序语句选择模板时,按照所述基于双向lstm的多分类器模型给出的概率值对修复模板进行排序,以完成修复模板的动态选择。
18.本发明所要实现的技术效果在于:
19.解决基于深度学习的缺陷定位技术中没有充分利用与缺陷检测相关的语义特征的问题,同时解决基于模板的缺陷自动修复技术中不能动态指定修复模板选择顺序的问
题。
附图说明
20.图1方法整体架构;
21.图2基于双向lstm的二分类器模型;
22.图3基于多层感知机的二分类器模型;
具体实施方式
23.以下是本发明的优选实施例,并结合附图对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。
24.本发明提出了一种代码缺陷的自动定位与修复方法。该方法的整体流程如图1所示。
25.首先选择11个常用的修复模板,并设计基于抽象语法树(abstract syntax tree,ast)的语法筛查器,筛选与这11类修复相关的开源代码提交(commit)信息。之后将这些提交版本所对应的修复前后的代码提取出来,保留出错语句及其函数级别的上下文内容,并对其出错语句进行位置标注,最终构建两个大规模数据集,分别用于之后的定位与修复工作。
26.设计基于双向lstm的二分类器模型用于学习与特定缺陷类型相关的深度语义知识,这个步骤通过使用大规模定位数据集训练来实现;另一方面,设计基于双向lstm的多分类器模型用于学习含有缺陷的语句更可能被哪个修复模板成功修复的知识,这个过程需要用到大规模修复数据集来进行训练。
27.将这两种知识迁移到目标项目中去实现最终的定位与修复任务,这又分为两个步骤:首先,收集目标项目开发历史中的缺陷数据,用于获取与缺陷相关的深度语义特征(针对定位任务)或微调已经训练过的模型参数(针对修复任务),以提高模型在目标项目数据上的预测性能;之后,对于目标项目中的待处理语句,使用定位任务中基于多层感知机的排序模型生成语句的出错概率来指导输出定位文件,使用基于双向lstm的多分类器模型生成不同修复模板的选择概率来指导输出模板的有序列表,以实现缺陷定位与自动修复的目标。
28.缺陷语义知识学习模块:
29.11个在之前的修复方法中常见的修复模板,包括空指针检查、添加缺失语句、修改条件表达式、修改数据类型、修改常量、修改变量、修改函数调用、修改操作符、修改返回语句、移动语句、删除语句,其中每一个模板对应修复一种常见的缺陷类型。借助神经网络学习与这些缺陷相关的语义知识,并应用到之后的定位和修复任务。为了实现这个目的,首先构建了两个大规模开源数据集,分别称为定位和修复数据集。
30.定位数据集包含11个子数据集,对应11种修复模板。每个子数据集中包含两种标签的数据,一种是含有该类型缺陷的数据(正样本),另一种是不含有该类型缺陷的数据(负样本)。每个样本是由一条程序语句以及它所在的函数构成的,为了区分该语句与函数内的其他语句,在它的开始和结束位置使用特殊符号《s》和《/s》进行标记。之后,借助长短时记忆网络(long short-term memory,lstm),构建了基于双向lstm的二分类器模型,结构如图
2所示,包含嵌入层、循环层、池化层和输出层。针对每种缺陷类型,以该类型所包含的正负样本数据作为训练集,来训练一个二分类器,使其拥有判别输入语句是否含有该类别缺陷的能力。训练后的模型蕴含了能够帮助进行缺陷定位任务的语义知识。
31.修复数据集含有11种标签的数据,对应11类修复模板。与定位数据集不同的是,修复数据集中只包含出错的样本(对应定位数据集每一个子数据集中的正样本),不包含未出错的样本(对应负样本),这是由于任务不同导致的。针对修复任务,我们的目标是为不同的程序语句动态生成修复模板的选择顺序,因此我们关心的是“假设输入语句已经出错的前提下,它更可能被哪个模板修复”这个问题。因此,设计一个基于双向lstm的多分类器模型,其结构与上述定位任务中的模型几乎一样,只是输出层从2维(含有缺陷/不含有缺陷的概率)变成了11维(含有特定缺陷类型的概率)。使用构建的修复数据集来训练这个多分类器,使其拥有能判别输入语句更可能被哪个修复模板成功修复的能力。训练后的模型蕴含了能够帮助进行修复模板选择的语义知识。
32.缺陷定位模块:
33.设计了一个基于多层感知机(multi-layer perceptron,mlp)的二分类器模型来融合三种能够帮助缺陷定位的特征,并通过监督学习机制进行训练,使其能够获得判别输入语句是否含有缺陷的能力。下面将分四部分来介绍三种类型的特征,以及融合这些特征进行缺陷定位任务的二分类器模型。
34.基于频谱的特征
35.给定一个项目p以及与待修复缺陷相关的测试用例集合t={t1,t2,
…
,tn},通过在p上运行这些测试用例,可以分别得到程序语句的运行轨迹集合s={s1,s2,
…
,sn}以及测试结果(通过或失败)集合r={r1,r2,
…
,rn}。集合s中的每条运行轨迹sk包含数量不等的语句,我们把集合s中涉及到的全部语句整理为语句集合u={u1,u2,
…
,um}。这个集合中的语句是与待修复缺陷相关的语句,包含正确语句和错误语句(即含有缺陷的语句)两类,而缺陷定位的任务就是将其中的错误语句尽可能排在靠前的位置,以帮助开发人员尽早发现缺陷。基于频谱的方法以“被更多失败测试用例执行经过的语句更可能出错”的假设作为出发点,设计了一系列公式来计算语句的出错概率,例如经典的ochiai算法的计算公式如下:
[0036][0037]
其中,e表示一条程序语句,t
p
(e)和tf(e)分别表示执行经过语句e的通过和失败测试用例的个数,t
p
和tf分别表示集合t中通过和失败测试用例的总数,sus(e)表示计算得到的语句e的出错概率。
[0038]
最终,我们选择了ochiai、tarantula、dstar三种基于频谱的经典算法,为每条候选语句生成了三个概率值,我们把它们统称为基于频谱的特征。
[0039]
基于变异测试的特征
[0040]
人工编写的测试用例是一种宝贵的软件制品,为了更充分地利用测试用例运行得到的信息,基于变异测试的方法应运而生。该方法需要的输入内容与基于频谱的方法相同,因此在下文中我们沿用上节中的符号定义。针对语句集合u中的任意语句uk,该方法首先使用预定义的变异算子(在本工作中使用了与pit变异测试工具中相同的16个变异算子)对uk进行变异,得到uk的变异体集合并在全部的变异体中运行测试用例,收集全部测试结果。基于变异测试的方法以“如果一个变异体能够使原始测试失败的测试用例变成通过状态,那它对应的原始语句更可能出错”的假设作为出发点,同样设计了一系列公式来计算语句的出错概率。其中,很多基于频谱的计算公式可以被继续使用,只不过公式中元素的含义与之前有所不同,还是以ochiai算法为例:
[0041][0042]
其中,m(e)表示程序语句e的变异体集合,表示在e上运行失败而在变异体m上运行成功的测试用例的个数,反之则是公式中的是一个更宏观的量,表示能够产生从失败到通过的运行状态转换的全部测试用例的数量。
[0043]
由于变异算子中定义的变更操作非常简单(例如变更中缀表达式的操作符),因此实际上极少能通过变异原始程序语句直接使测试用例的最终运行结果发生改变,这使得统计的变化信息不够明显,阻碍了基于变异测试方法性能上的进一步提升。因此,我们将“测试状态是否发生了改变”这个问题扩展到了四个不同的变更粒度上,分别是“测试结果”、“测试结果+异常类型”、“测试结果+异常类型+异常信息”、“测试结果+异常类型+异常信息+函数调用轨迹”。我们选择ochiai算法来分别计算程序语句在四个粒度上的出错概率,并把它们统称为基于变异测试的特征。
[0044]
基于深度语义的特征
[0045]
借助基于双向lstm的二分类器模型,分别以11种特定缺陷类型的训练数据作为输入,通过监督学习机制迭代优化并保存11种最优模型参数,其中蕴含了能够帮助预测程序语句是否包含某种特定类型缺陷的语义知识。而现在,把这些学到的知识迁移到目标数据集上,即将目标数据集中的语句作为输入,借助已训练好的模型,预测生成11个面向特定缺陷类型的出错概率值,我们把它们称为基于深度语义的特征。
[0046]
基于多层感知机的二分类器模型
[0047]
在得到以上三组不同的特征之后,我们设计了一个基于多层感知机的二分类器模型对特征进行融合,用来预测结合三种特征之后的程序语句的出错概率。其模型结构如图3所示。
[0048]
其中,输入层共包含18维输入特征(3+4+11),由于深度语义特征的维度比另外两种特征的维度要大,为了使模型能尽量均衡地从三类输入信息中提取特征,我们首先使用一个全连接层(即图中的语义信息融合层)将语义特征从11维降到4维,之后再使用另一个全连接层(即图中的多输入信息融合层)融合三种不同的特征,最终通过输出层得到语句的出错概率。当然,该模型的最优参数也需要通过训练得到,在实际使用时,可以收集目标项目开发历史中的缺陷用于训练,并保存最优模型参数以预测新的缺陷。最终,每条程序语句按照其预测得到的出错概率值从高到低进行排序,生成定位文件,以完成缺陷定位的任务。
[0049]
缺陷自动修复模块:
[0050]
基于模板的缺陷自动修复方法包含五个步骤,即选择待修复的语句,选择需要的
修复模板,生成补丁,运行测试用例进行自动化测试,人工检查。其中需要注意的是,在默认的运行设置中规定了,一旦第四步发现有补丁可以通过全部的测试用例,修复进程就会立刻结束运行。进程停止后,会对生成的补丁进行人工检查,我们把人工认定为正确/错误的补丁分别称为真补丁/假补丁。之前的方法往往致力于使用更多、更优质的修复模板来提高修复的上限,却忽视了对模板选择顺序的研究。我们发现在一些情况下,当一个错误的模板被更早选择时,可能会有假补丁生成,导致修复进程被提前终止,失去了选择正确修复模板的机会。
[0051]
修复方法的目标是对模板的选择顺序做优化,使正确的修复模板能被更早选中。在缺陷语义知识学习模块中,基于双向lstm设计了多分类器模型,并通过监督学习的机制训练该模型,使其拥有判别输入语句更可能被哪个模板成功修复的能力。为了能在目标项目上得到更好的效果,在实际使用时,同样借助迁移学习的思想,选取了该项目开发历史中的缺陷及其对应的修复模板类型作为数据和标签,应用于已经在大规模修复数据集上训练得到的模型做二次训练来微调参数,使其拥有更好的泛化性。对于待测试的目标程序语句,模型能够预测生成一个11维的概率向量,对应11个预定义的修复模板。因此,在为该程序语句选择模板时,我们按照模型给出的概率值对修复模板进行排序,以优化自动修复任务。
[0052]
缺陷自动修复任务所需要的离线定位文件可以通过我们提出的缺陷定位方法做进一步优化,因此,同时使用我们提出的缺陷定位方法与修复模板动态选择方法能够更好地提升缺陷自动修复的性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1