一种神经机器翻译系统的性能提升方法与流程
1.本发明涉及一种神经机器翻译技术,具体为一种神经机器翻译系统的性能提升方法。
背景技术:
2.机器翻译(machine translation,简称mt)是一门使用计算机进行自然语言之间相互翻译的学科。它是自然语言处理研究方向的一个支系,也是人工智能的最终目标之一。机器翻译相比于人工翻译,即使翻译质量有着一定差距,但是机器翻译的高效率以及低成本所带来的收益是极为可观的,并且对于促进人类文化交流有着重要意义。
3.早期的机器翻译研究都是以基于规则的方法为主,特别是在上世纪70年代,以基于规则方法为代表的专家系统是人工智能中最具代表性的研究领域。它的主要思想是以词典和人工书写的规则库作为翻译知识,用一系列规则的组合完成翻译。该方法的缺陷在于需要大量语言学专家构造规则,并且制定的规则难以统一,甚至人工定义的规则之间会出现冲突,造成基于规则的翻译系统的可扩展性和可维护性较差。
4.直到上世纪90年代,统计机器翻译逐渐兴起。它利用统计模型从单语或双语语料中自动学习翻译知识。统计机器翻译使用单语语料学习语言模型,使用双语平行语料学习翻译模型,并使用这些统计模型完成对翻译过程的建模。整个过程不需要人工编写规则,也不需要从实例中构建翻译模板。无论是词还是短语,甚至是句法结构,统计机器翻译系统都可以自动学习。但统计机器翻译需要对大量的双语平行语料进行统计分析,从而构造统计翻译模型来完成翻译。至2005年开始,统计机器翻译进入了十年黄金时期。在这一时期,各种基于统计机器翻译模型层出不穷,经典的基于短语的模型和基于句法的模型也先后被提出。
5.自2014年开始,随着机器学习技术的发展,基于深度学习的神经机器翻译逐渐兴起。它在短短几年内已经在大部分任务上取得了明显的优势。在神经机器翻译中,词串被表示成实数向量。翻译过程并不是在离散化的单词和短语上进行,而是在实数向量空间上计算,因此它对词序列表示的方式产生了本质的改变。在神经机器翻译中,序列到序列的转化过程可以由编码器-解码器框架实现。编码器将输入的源语经过编码形成一个稠密的语义向量,之后解码器结合语义向量进行自回归解码,生成最终关于目标语的翻译结果。这种方法不需要额外的人工特征工程,直接使用神经网络进行建模,同样也需要大量的双语语料进行训练。
6.目前,神经机器翻译系统已经取得较好的效果,如果神经机器翻译模型经过较优的参数训练达到足够强的表示能力,那么与传统的基于规则的机器翻译方法和基于统计的机器翻译方法相比,在翻译速度与质量方面都有着较大的优势。但与专业的人工翻译相比较,依旧存在不小差距,因此对神经机器翻译性能的进一步优化更是成为一个待解决的难题。
7.神经机器翻译系统在实际生活中已经得到了广泛应用,但依旧存在捕获位置信息
能力较差、鲁棒性较差等难题。随着国际化交流越来越普及,尽管神经机器翻译具有优秀的性能。但是在重要场景下,神经机器翻译系统依旧只能起到辅助作用。所以提升神经机器翻译系统性能便成了机器翻译技术应用的关键问题。在传统的神经网络系统性能方法中,需要在系统上进行一系列复杂的操作才能取得较好的性能提升效果,耗时长且难以复现,大大限制了机器翻译技术的实际应用。
技术实现要素:
8.针对现有的神经机器翻译技术中依旧存在捕获位置信息能力不足导致神经机器翻译系统对输入语言语序不敏感、鲁棒性较差等问题,本发明要解决的技术问题是提供一种绝对位置编码生成规则,能够在不增加神经机器翻译系统的参数量和计算量的基础上,提升神经机器翻译系统性能。
9.为解决上述技术问题,本发明采用的技术方案是:
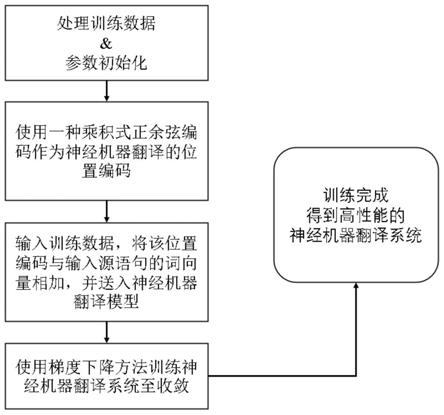
10.本发明提供一种神经机器翻译系统的性能提升方法,包括以下步骤:
11.1)处理训练数据并初始化神经机器翻译系统的参数,其参数初始化规则遵从xavier参数初始化规则;
12.2)将神经机器翻译系统中的绝对位置编码生成规则调整为一种乘积式正余弦编码生成规则;
13.3)输入训练数据,并将步骤2)中生成的绝对位置编码读入神经机器翻译系统,与输入源语句的词向量相加,得到与位置信息融合的词向量,并送入神经机器翻译模型;
14.4)使用梯度下降方法训练神经机器翻译系统至收敛,训练过程与现有神经机器翻译系统的训练过程保持一致;
15.5)在解码过程中,对于神经机器翻译系统中的绝对位置编码生成规则,应与步骤2)中乘积式正余弦编码生成规则保持一致。
16.步骤1)中,处理训练数据并初始化神经机器翻译系统的参数,其参数初始化规则遵从xavier参数初始化规则,具体为:
17.101)选择需要训练的参数,包括词表中的每个词向量、编码器和解码器中每层的参数以及解码器输出层的参数;
18.102)使用xavier参数初始化规则对101)步骤中的参数进行初始化,具体公式如下:
[0019][0020]
其中w表示需要训练的参数,u表示均匀分布,n
in
与n
out
分别代表该需要训练的参数的输入和输出维度。
[0021]
步骤2)中,将神经机器翻译系统中的绝对位置编码生成规则调整为一种乘积式正余弦编码,具体为:
[0022]
[0023][0024]
其中pos代表位置编码的位置维度索引,2j代表位置编码的隐层维度索引,d代表位置编码的隐层维度大小。
[0025]
步骤4)中,训练神经机器翻译系统至收敛,训练过程与现有神经机器翻译系统的训练过程保持一致;
[0026]
401)将训练数据输入修改位置编码生成规则后的神经机器翻译系统,计算关于训练数据的目标函数l,计算公式如下:
[0027][0028]
其中(x,y)表示训练的输入和目标,w表示模型的可训练参数,l(
·
)表示神经机器翻译系统的损失函数;
[0029]
402)将损失的梯度反向传播,计算神经机器翻译模型中待训练参数的梯度,并更新该参数公式如下:
[0030][0031]
其中t表示更新的步数,α为学习率,表示更新步幅的大小,需要随着训练进程不断更新调整;
[0032]
403)利用步骤401)和步骤402)的公式不断更新模型的待训练参数,直到神经机器翻译模型对训练数据的损失收敛。
[0033]
本发明具有以下有益效果及优点:
[0034]
1.本发明方法在机器翻译上通过改进神经机器翻译系统的绝对位置编码生成规则,通过扩大不同位置间编码的差异性,最终通过提升神经机器翻译系统捕获位置信息能力达到神经机器翻译系统性能提升的目的。
[0035]
2.本发明提出的神经机器翻译系统性能提升方法,该算法在wmt14英德任务上取得0.5bleu值的性能提升效果,同时模型的参数量与计算量没有增长。
附图说明
[0036]
图1为本发明一种神经机器翻译系统的性能提升方法流程图;
[0037]
图2为本发明应用于现有的神经机器翻译系统示意图。
具体实施方式
[0038]
下面结合说明书附图对本发明作进一步阐述。
[0039]
如图1所示,本发明一种神经机器翻译系统的性能提升方法,包括以下步骤:
[0040]
1)初始化神经机器翻译系统的参数,其参数初始化规则遵从xavier参数初始化规则;
[0041]
2)将神经机器翻译系统中的绝对位置编码生成规则调整为一种乘积式正余弦编码,生成神经机器翻译系统的绝对位置编码;
[0042]
3)将调整之后的神经网络系统进行整合,并读入训练数据;
[0043]
4)使用梯度下降方法训练神经机器翻译系统至收敛,训练过程与现有神经机器翻译系统的训练过程保持一致;
[0044]
5)利用本发明训练得到的神经机器翻译系统进行机器翻译。如图2所示,在解码过程中,使用步骤2)的规则生成神经机器翻译系统的绝对位置编码,将句子送入神经机器翻译系统,通过自回归方式逐词解码,得到翻译结果。
[0045]
在步骤1)中,处理训练数据并初始化神经机器翻译系统的参数,其参数初始化规则遵从xavier参数初始化规则,具体为:
[0046]
101)选择需要训练的参数,包括词表中的每个词向量、编码器和解码器中每层的参数以及解码器输出层的参数;
[0047]
102)使用xavier参数初始化规则对101)步骤中的参数进行初始化,具体公式如下:
[0048][0049]
其中w表示101)中需要训练的参数,u表示均匀分布,n
in
与n
out
分别代表该需要训练的参数的输入和输出维度。
[0050]
本步骤以对齐的源语言和目标语言双语数据作为训练数据。
[0051]
步骤2)中,将神经机器翻译系统中的绝对位置编码生成规则调整为一种乘积式正余弦编码,具体为:
[0052][0053][0054]
其中pos代表位置编码的位置维度索引,2j代表位置编码的隐层维度索引,d代表位置编码的隐层维度大小。
[0055]
步骤4)中,训练神经机器翻译系统至收敛,训练过程与现有神经机器翻译系统的训练过程保持一致;
[0056]
401)将训练数据输入修改绝对位置编码生成规则后的神经机器翻译系统,计算关于训练数据的目标函数l,计算公式如下:
[0057][0058]
其中(x,y)表示训练的输入和目标,w表示模型的可训练参数,l(
·
)表示神经机器翻译系统的损失函数;
[0059]
402)将损失反向传播,计算神经机器翻译模型中待训练参数的梯度,并更新该参数公式如下:
[0060]
[0061]
其中t表示更新的步数,α为学习率,表示更新步幅的大小,需要随着训练进程不断更新调整;
[0062]
403)利用步骤401)和步骤402)的公式不断更新模型的待训练参数,直到神经机器翻译模型对训练数据的损失收敛。
[0063]
步骤5)中,在使用解码过程中,对于神经机器翻译系统中的绝对位置编码生成规则,应与步骤2)保持一致。
[0064]
该方法具体流程如图1所示。具体应用过程为:将待翻译的源语言文本进行分词处理后送入模型,在编码器进行参数计算,然后送进解码器中以自回归方式逐词解码,最终计算得到目标语的文本进行输出,如图2所示。
[0065]
应用效果以小牛翻译机为例,应用该神经机器翻译系统的性能提升方法,未增加任何参数量与计算量的前提下,在wmt14英语到德语的任务上基线系统提升了神经机器翻译系统的0.5bleu值;在wmt16英语到罗马尼亚语的任务上基线系统提升了神经机器翻译系统的0.4bleu值。本发明通过对神经机器翻译系统定义一个新的绝对位置编码生成规则:更改神经机器翻译系统的绝对位置编码规则为一种正余弦编码生成规则;在模型训练过程中,使用该规则生成绝对位置编码,达到提升神经机器翻译系统的位置信息捕获能力;最终训练得到一个对语序信息更加敏感且性能更加优越的神经翻译系统。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1