三维地理场景融合表达效果评价方法及系统
1.本发明属于可视化融合技术领域,具体涉及一种三维地理场景融合表达效果评价方法及系统。
背景技术:
2.城市中安装了大量用于安防、建设等领域的监控摄像头。监控人员每天都需要查看拍摄某些区域多路摄像头视频内容,以判断是否有异常行为。由于每个摄像头都有各自的位置和视域,监控人员通常需要面对多路视频图像组成的井字形视频墙进行查看。这种多路视频表达方式给监控人员增加了巨大的检索分析压力。而视频-地理场景融合表达则将大量不同位置的摄像头与视频图像拍摄区域关联,能够有效帮助监控人员结合地理空间信息理解视频内容,提高视频查看分析效率。
3.目前已有多种视频-地理场景融合表达应用到视频监控领域,但在不同的时空约束与信息表达需求下,视频-场景融合表达的可视化效果一直未能得到系统、有效的分析,不同信息表达模式与表达策略的优劣缺乏定量比较。针对上述问题,我们认为可以运用眼动的方法对视频-地理场景融合信息表达进行分析,构建视频-地理场景融合表达模式参数模型,从用户体验的角度对不同视频-地理场景融合表达模式进行评价。基于上述分析,本发明提出一种基于眼动的视频-三维地理场景融合表达效果评价系统及方法的技术方案。基于上述分析,本发明提出一种三维地理场景融合表达效果评价方法及系统的技术方案。
技术实现要素:
4.本发明的目的是为评价三维场景与视频融合表达效果,为不同应用场景的视频-地理场景融合表达模式选择和性能分析提供支持,而提供一种三维地理场景融合表达效果评价方法及系统。
5.为实现上述目的,本发明所采用的技术方案是:
6.根据本发明实施例的第一方面,一种基于眼动的视频-三维地理场景融合表达效果评价方法,包括以下步骤:
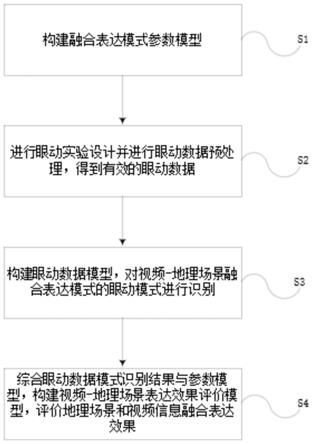
7.s1:构建融合表达模式参数模型;
8.s2:进行眼动实验设计并进行眼动数据预处理,得到有效的眼动数据;
9.s3:构建眼动数据模型,对视频-地理场景融合表达模式的眼动模式进行识别;
10.s4:综合眼动数据模式识别结果与参数模型,构建视频-地理场景表达效果评价模型,评价地理场景和视频信息融合表达效果;
11.进一步地,步骤s1所述的融合表达参数模型通过构建视频-地理场景融合表达参数模型,将影响视频-地理场景融合表达的影响因素进行全盘考虑,分类说明;通过构建眼动实验中用户参数模型,分析用户的性别、年龄等个体差异对视频-地理场景融合表达效果的影响;通过构建眼动实验中任务模型,将眼动实验中影响任务完成的因素进行了分类分析。
12.进一步地,视频-地理场景融合表达参数模型如下:
13.fva={a1,a2,a3,
……
,a
10
}
14.其中a1,a2,a3,
……
,a
10
表示影响视频-地理场景融合表达的参数。具体参数内容为a1(地理场景)={二维,三维}、a2(视频显示速率)={正常速度播放,加快速度播放,减慢速度播放}、a3(显示亮度)={视频/视频对象显示亮度}、a4(显示视频路数)={只显示一路视频信息,显示多路视频信息}、a5(显示对象)={视频图像显示,视频目标显示}、a6(融合模式)={嵌入式,相关式,投影式}、a7(嵌入方式)={视频图像总是正面面对用户,根据相机位置和角度将视频嵌入地理场景,动态图像(将对象映射到多边形上)}、a8(视频目标个数)={只显示一个视频目标,显示多个视频目标}、a9(视频目标投影式融合方式)={前后景独立投影(视频背景贴于地理场景中,目标投影到对应时空位置),前景投影式(将目标投影到三维场景的相应位置),前景抽象式投影(简化表示,用虚拟物体代替目标放置在相应位置上)}、a
10
(显示尺寸)={视频/视频对象显示尺寸大小}。
15.进一步地,根据参与的受试者与实验相关的个体差异,构建的用户参数模型,如下:
16.fvb={b1,b2,b3,
……
,b6}
17.其中,b1,b2,b3,
……
,b6是在相同条件下影响融合表达评价效果的用户特征参数。b1参数为(年龄)、b2(性别)、b3(职业)、b4(学历)、b5(是否实际使用过监控视频)、b6(裸眼或矫正视力是否正常)。
18.进一步地,由于影响眼动实验结果的因素还包括任务的差异,因此通过对不同任务类型进行总体说明,构建了眼动实验中任务模型。根据任务特征进行建模分类,可以表示为以下几个方面:
19.fvc={c1,c2,c3,
……
c7}
20.其中,c1,c2,c3,
……
c7是进行眼动实验时需要考虑到的任务类型。参数为c1(任务目标)、c2(任务前预观看)、c3(任务中反复观看)、c4(任务终止条件/找到几个目标)、c5(特定对象)、c6(被试者主观评价)、c7(被试者主观评价方法)。本文中涉及的参数变量为c5(特定对象)、c6(被试者主观评价)、c7(被试者主观评价方法)。
21.进一步地,s2所述的眼动实验依据视频-三维地理场景融合表达参数模型、用户参数模型以及任务模型设计眼动实验。
22.进一步地,s3所述构建眼动数据模型为结合视频-地理场景融合表达模式的眼动数据的时空轨迹特征,对眼动数据进行聚类分析,并将眼动数据与实验任务结合分析任务准确度和aoi占比率。同时,对眼动数据进行显著性分析,为后续判断影响因素对视频-地理场景融合表达效果是否有显著影响做依据。
23.进一步地,s4所述评价地理场景和视频信息融合表达效果从影响因素的角度进行评价。其中,客观因素可对应为视频-地理场景融合表达参数模型,受试者主观因素可对应用户参数模型,任务因素可对应任务模型。通过分别从以上三个角度中各选取一种或几种影响因素(参数)进行组合分析,并设置有针对性眼动实验,从而根据眼动实验数据分析结果对这几种影响因素进行系统评价。
24.根据本发明实施例的第二方面,一种基于眼动的视频-三维地理场景融合表达效果评价系统,其特别之处在于:包括视频-三维地理场景融合模块、数据获取模块、眼动数据
处理分析模块以及表达效果评价模块;
25.所述视频-三维地理场景融合模块即构建视频-地理场景融合表达模式参数模型,明确影响视频-地理场景融合表达的影响因素。
26.所述数据获取模块包括设计眼动实验,采集眼动实验过程中受试者的眼动数据,并对采集的眼动数据进行清洗、漏检、误检等预处理操作,生成有效的的眼动数据。
27.所述眼动数据处理分析模块通过对眼动数据时空轨迹进行聚类分析,并在聚类分析的基础上构建匹配模型,对视频-地理场景融合表达模式的眼动模式进行识别。基于逐相机检索,通过分析检索条件与相机视域的空间关系,选出与检索条件匹配的相机,实现检索条件与每个相机中的视频轨迹匹配查询;
28.所述表达效果评价模块根据视频-地理场景融合表达模式参数模型和眼动数据模式识别结果构建视频-地理场景融合表达效果评价模型,依据构建的评价模型对视频-地理场景融合表达效果进行评价。
29.进一步地,所述视频-地理场景融合表达参数模型通过将影响视频-地理场景融合表达的影响因素进行全盘考虑,分类说明;通过构建眼动实验中用户参数模型,分析用户的性别、年龄等个体差异对视频-地理场景融合表达效果的影响;通过构建眼动实验中任务模型,将眼动实验中影响任务完成的因素进行了分类分析。
30.进一步地,所述视频-地理场景融合表达效果评价模型中评价的内容包括对感兴趣区域的分析和时序分析的局限性和区别,受试者对三维场景和视频信息融合的三维场景的整体感觉,以及通过分析这些因素之后找出研究所设计的实验的缺点和不足,以便在今后的改进中有所依据。最后对三维场景和视频信息融合的表达效果作出评价。
31.本发明具有如下优点:以往的视频数据眼动分析都是直接在二维视频上进行的,只考虑了用户对视频内容本身的理解,缺乏对视频拍摄的地理场景的感知。本发明的眼动数据不仅分析了用户对视频信息的认知效果,还将用户对视频场景的认知一并加入考察分析。以往的视频数据眼动分析都是直接在二维视频上进行的,只考虑了用户对视频内容本身的理解,缺乏对视频拍摄的地理场景的感知。本发明的眼动数据不仅分析了用户对视频信息的认知效果,还将用户对视频场景的认知一并加入考察分析。
附图说明
32.图1为本发明实施例中提供的基于眼动的视频-三维地理场景融合表达效果评价的方法流程图;
33.图2为本发明实施例中提供的的构建视频-地理场景信息融合模式的参数模型图;
34.图3为本发明实施例中提供的数据获取流程图;
35.图4为本发明实施例中提供的眼动数据处理和分析流程图;
36.图5为本发明实施例中提供的视频-地理场景融合表达评价流程图;
37.图6为本发明实施例中提供的一种视频-三维地理场景融合的实验场景图;
38.图7为本发明实施例中提供的基于眼动的视频-三维地理场景融合表达效果评价系统的架构图。
具体实施方式
39.以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
40.参见图1,提供一种三维地理场景融合表达效果评价的方法,包括以下步骤:
41.s1、构建融合表达模式参数模型;
42.s2、进行眼动实验设计并进行眼动数据预处理,得到有效的眼动数据;
43.s3、通过构建眼动数据模型,对视频-地理场景融合表达模式的眼动模式进行识别;
44.s4、综合眼动数据模式识别结果与参数模型,构建视频-地理场景表达效果评价模型,评价地理场景和视频信息融合表达效果;
45.进一步地,步骤s1所述的融合表达参数模型通过构建视频-地理场景融合表达参数模型,将影响视频-地理场景融合表达的影响因素进行全盘考虑,分类说明;通过构建眼动实验中用户参数模型,分析用户的性别、年龄等个体差异对视频-地理场景融合表达效果的影响;通过构建眼动实验中任务模型,将眼动实验中影响任务完成的因素进行了分类分析。
46.进一步地,视频-地理场景融合表达参数模型如下:
47.fva={a1,a2,a3,
……
,a
10
}
48.其中a1,a2,a3,
……
,a
10
表示影响视频-地理场景融合表达的参数。具体参数内容为a1(地理场景)={二维,三维}、a2(视频显示速率)={正常速度播放,加快速度播放,减慢速度播放}、a3(显示亮度)={视频/视频对象显示亮度}、a4(显示视频路数)={只显示一路视频信息,显示多路视频信息}、a5(显示对象)={视频图像显示,视频目标显示}、a6(融合模式)={嵌入式,相关式,投影式}、a7(嵌入方式)={视频图像总是正面面对用户,根据相机位置和角度将视频嵌入地理场景,动态图像(将对象映射到多边形上)}、a8(视频目标个数)={只显示一个视频目标,显示多个视频目标}、a9(视频目标投影式融合方式)={前后景独立投影(视频背景贴于地理场景中,目标投影到对应时空位置),前景投影式(将目标投影到三维场景的相应位置),前景抽象式投影(简化表示,用虚拟物体代替目标放置在相应位置上)}、a
10
(显示尺寸)={视频/视频对象显示尺寸大小}。
49.进一步地,根据参与的受试者与实验相关的个体差异,构建的用户参数模型,如下:
50.fvb={b1,b2,b3,
……
,b6}
51.其中,b1,b2,b3,
……
,b6是在相同条件下影响融合表达评价效果的用户特征参数。b1参数为(年龄)、b2(性别)、b3(职业)、b4(学历)、b5(是否实际使用过监控视频)、b6(裸眼或矫正视力是否正常)。
52.进一步地,由于影响眼动实验结果的因素还包括任务的差异,因此通过对不同任务类型进行总体说明,构建了眼动实验中任务模型。根据任务特征进行建模分类,可以表示为以下几个方面:
53.fvc={c1,c2,c3,
……
c7}
54.其中,c1,c2,c3,
……
c7是进行眼动实验时需要考虑到的任务类型。参数为c1(任务目标)、c2(任务前预观看)、c3(任务中反复观看)、c4(任务终止条件/找到几个目标)、c5(特定对象)、c6(被试者主观评价)、c7(被试者主观评价方法)。本文中涉及的参数变量为c5(特定对象)、c6(被试者主观评价)、c7(被试者主观评价方法)。
55.进一步地,s2所述的眼动实验依据视频-三维地理场景融合表达参数模型、用户参数模型以及任务模型设计眼动实验。
56.眼动实验及其数据处理的具体步骤如下:
57.(1)召集实验志愿者进行眼动实验,并收集眼动数据:两组受试者需要完整观看地理场景中的视频数据,在观看完成之后对视频内容进行大体描述;
58.(2)对收集的眼动数据进行清洗,即进行误检、漏检处理;
59.(3)数据处理完成之后生成有效的眼动数据;
60.(4)眼动实验结束之后对受试者的个人体验信息进行收集总结。
61.进一步地,s3所述构建眼动数据模型为结合视频-地理场景融合表达模式的眼动数据的时空轨迹特征,对眼动数据进行聚类分析,并将眼动数据与实验任务结合分析任务准确度和aoi占比率。同时,对眼动数据进行显著性分析,为后续判断影响因素对视频-地理场景融合表达效果是否有显著影响做依据。
62.其中,实验中的aoi指的是视频区域。在准确度评价方面,首先是对被试者完成实验任务的准确度r
t
进行评价(是否正确描述出目标人物的运动方向),r
t
是根据被试者填写的目标人物的运动方向所得出的完成实验任务的准确度。在aoi占比率方面,对aoi占比率ra的评价:ra定义为在指定的aoi中分布的固定点数量占固定点总数的百分比。
[0063][0064]
其中,na表示在指定aoi中分布的注视点数量,n
t
表示注视点总数。
[0065]
进一步地,s4所述评价地理场景和视频信息融合表达效果从影响因素的角度进行评价。其中,客观因素可对应为视频-地理场景融合表达参数模型,受试者主观因素可对应用户参数模型,任务因素可对应任务模型。通过分别从以上三个角度中各选取一种或几种影响因素(参数)进行组合分析,并设置有针对性眼动实验,从而根据眼动实验数据分析结果对这几种影响因素进行系统评价。
[0066]
参见图7,本发明还提供一种基于眼动的视频-三维地理场景融合表达效果评价系统,该评价系统包括:
[0067]
视频-三维地理场景融合模块:构建视频-地理场景融合表达模式参数模型,明确影响视频-地理场景融合表达的影响因素。
[0068]
数据获取模块:设计眼动实验,采集眼动实验过程中受试者的眼动数据,并对采集的眼动数据进行清洗、漏检、误检等预处理操作,生成有效的的眼动数据。
[0069]
眼动数据处理分析模块:通过对眼动数据时空轨迹进行聚类分析,并在聚类分析的基础上构建匹配模型,对视频-地理场景融合表达模式的眼动模式进行识别。基于逐相机检索,通过分析检索条件与相机视域的空间关系,选出与检索条件匹配的相机,实现检索条件与每个相机中的视频轨迹匹配查询;
[0070]
表达效果评价模块:根据视频-地理场景融合表达模式参数模型和眼动数据模式
识别结果构建视频-地理场景融合表达效果评价模型,依据构建的评价模型对视频-地理场景融合表达效果进行评价。
[0071]
需要说明的是,上述基于眼动的视频-地理场景融合表达效果评价系统各模块/单元之间的信息交互、执行过程等内容,由于与本技术实施例中的方法实施例基于同一构思,其带来的技术效果与本技术方法实施例相同,具体内容可参见本技术前述所示的方法实施例中的叙述。
[0072]
所属技术领域的技术人员能够理解,本发明的各个方面可以实现为系统、方法或程序产品。因此,本发明的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“模块”或“平台”。
[0073]
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1