一种基于示功图融合相似度的抽油工况融合推理识别方法与流程
1.本发明涉及油井采油、抽油领域,具体涉及一种基于示功图融合相似度的抽油工况融合推理识别方法。
背景技术:
2.抽油示功图,是了解抽油机井下的管、杆、泵工作状况的主要手段。分析和解释示功图,就是直接了解深井泵工作状况好坏的一个主要手段,深井泵工作中的一切异常现象可以在示功图上比较直观的反映出来。
3.抽油机是石油开采环节中的核心设备,单纯人力来判断抽油机的工作状况以及操作抽油机的运行,效率低、不能满足行业发展需要。
4.在当前人工智能潮流的大背景下,特别是利用深度学习技术挖掘示功图所表达的信息,提高抽油机工况或故障识别准确率及效率,保证抽油机稳定、可靠工作有着重大意义。目前传统抽油井识别方法有力学模型分析、有杆泵井故障诊断专家系统等,但是由于各地地质差异以及机器老化问题,如果使用传统的示功图识别方法识别结果会存在较大差异。而且这些主流方法大多只能识别出一种抽油工况,这与实际工况偏差大,抽油过程中广泛存在同时出现多种工况问题。
5.在对反映抽油工况特征的待测示功图与样本图进行相似性进行度量时,采用基于皮尔逊相关系数算法的相似度,与其他如传统余弦距离计算方法相比,具有平移不变性和尺度不变性,可以克服受图片平移及图像缩放的影响。非常适合抽油机由于长时间使用造成的载荷整体增加或者位移量整体向某一方向偏移,进而导致示功图整体偏移的状况,可以一定程度量避免由于机器老化造成的识别率下降。对两图整体相似度评价的稳定性好,但易受光线亮度、对比度及颜色影响,图片旋转也会对结果产生重大影响。
6.若仅采用基于局部哈希算法的相似度计算相似度,由于其基于类似空间域转换思想,图片放大或缩小,改变纵横比,或增加减少亮度、对比度、颜色,对hash值的影响很小。局部敏感哈希算法可以有效的忽略示功图中平移、缩放、纵横比变化、旋转以及光线所带来的问题。但是局部敏感哈希算法对由于局部分析能力强,对图片内容非常敏感,较小的内容干扰,很容易引起图片的哈希值较大变化,从而导致相似度整体评价的稳定性不足。
7.将基于皮尔逊相关系数算法和局部哈希算法求取的相似度按一定步骤进行融合,充分发挥两者优势,以获取待测图与样本图更加合理的相似度,最终有效提高识别率的作用,这种方法未见公开报道。
技术实现要素:
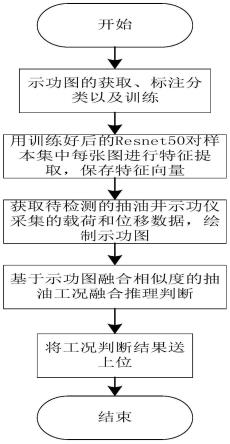
8.本发明公开了一种基于示功图融合相似度的抽油工况融合推理识别方法,从工程适用性出发,基于cbir技术、匹配算法,以示功图待测图与样本图间融合相似度为基础,进行融合推理,获得准确的抽油工况。本发明所述方法具体步骤如下:
9.一种基于示功图融合相似度的抽油工况融合推理识别方法,它包括以下流程:
10.(1)示功图获取、标注分类以及训练。
11.(2)用训练好后的resnet50对样本集中每张图进行特征提取,保存特征向量。(使用训练好的resnet50网络对标注好的训练集进行特征提取,并保存所有avgpool层的特征结果。)
12.(3)获取待检测的抽油井示功仪采集的载荷和位移数据,绘制示功图。(获取待检测的抽油井示功仪采集的载荷和位移数据,使用opencv将载荷和位移数据绘制成待识别的示功图。)
13.(4)基于示功图融合相似度的抽油工况融合推理判断。
14.(5)将工况判断结果送上位展示。优选的,所述示功图获取、标注分类以及训练步骤包括对示功图的获取、对现有示功图数据集标注分类,以及使用标注好的示功图数据集对resnet50训练,并保存训练权值;其具体步骤为:
15.(1-1)获取抽油井示功仪采集的载荷量和位移量数据,以位移为横坐标x,载荷量为横坐标y,使用opencv中的多边形绘图函数工具包将数据绘制成示功图;
16.(1-2)业务专家对示功图进行预处理,剔除有明显错误示功图,形成示功图数据集;
17.(1-3)业务专家对示功图数据集中示功图进行标注分类将标注分类好的数据集按7:3比例分为训练集和测试集;
18.(1-4)将训练集放入resnet50神经网络中进行训练。其中激活函数为relu,池化方法输入层使用max pooling,最后输出层使用avg pooling,优化代价函数为cross-entropy交叉熵,batch_size为16;
19.(1-5)在训练完成后,将训练完的resnet50权值保存。
20.优选的,所述基于示功图融合相似度的抽油工况融合推理判断步骤具体包括:
21.(4-1)使用resnet50提取待检测示功图特征
22.将传入的待检测示功图放入训练好的resnet50中,提取待测图在avgpool层的特征向量t=[t1,t2,...,t
2048
];
[0023]
(4-2)调取样本集中第i张图的特征向量si=[si1,si2,...si
2048
],0《i≤n,其中n为样本集中样本图的个数;
[0024]
(4-3)分别基于皮尔逊相关系数算法和局部敏感哈希算法计算待检测图与样本集中第i张图的相似度;
[0025]
(4-4)基于两种算法分别计算待测示功图与样本集中第i张图相似度mpi及mhi大小后,对两种相似度进行融合,获得待测图与标记为x工况的第i张匹配图的融合相似度pi(x),x=a1,a2...ak,ak为样本集中的全部工况之一;具体融合方法如下:
[0026]
pi(x)=mpi×
mhi+mpi(1-mhi)+mhi(1-mpi)
[0027]
其中mpi是基于皮尔逊算法的相似度值;mhi是基于敏感哈希算法的相似度值;
[0028]
(4-5)pi(x)与预先设置的相似度阈值ps比对,
[0029]
(4-5-1)如果pi(x)》ps,将该图存入初步推荐图库,进入下一步骤;
[0030]
(4-5-2)如果pi(x)≤ps,跳过这个匹配的图片,进入下一步骤;
[0031]
(4-6)判断数据库中所有样本图是否均比较过
[0032]
(4-6-1)没有全部计算完则取下张样本图与待测图比较,然后返回到步骤(4-2),
重复循环;
[0033]
(4-6-2)全部计算完进入下一个环节;
[0034]
(4-7)判断是否有相似的匹配照片
[0035]
(4-7-1)如果有推荐的匹配照片,那么列出所有推荐的匹配图片,转入下一步;
[0036]
(4-7-2)如果没有推荐的匹配照片,系统提示没有匹配照片,只能凭借工艺专家来判断分类,并进行标注后放入训练集,供下一轮的训练更新resnet神经网络。
[0037]
(4-8)基于推荐的所有匹配图,进行工况融合推理判断。
[0038]
(4-9)输出当前工况状态判断结果。
[0039]
优选的,已知待检测图与样本集中第i张图的特征向量分别为:t=[t1,t2,...,t
2048
],si=[si1,si2,...si
2048
],计算待检测图与样本集中第i张图的相似度的具体步骤为:
[0040]
基于皮尔逊相关系数算法计算待检测图与样本集中第i张图的特征向量间相似度mpi为:
[0041][0042]
其中cov为协方差,为向量平均值。
[0043]
基于局部敏感哈希算法计算待检测图与样本集中第i张图的特征向量间相似度mhi具体步骤为:
[0044]
1)首先分别计算出特征提取后特征向量t、si中的平均数avg,avg舍去小数;
[0045]
2)将特征向量t、si通过与平均数avg比较,小于avg的0,否则取1;从更新完的特征向量中从右往左取数书写为二进制形式,再转化为十进制作为哈希值;从而获得特征向量t、si对应的哈希值h
x
,hy;
[0046]
3)计算基于局部敏感哈希算法的相似度大小mhi[0047][0048]
其中:distance=bin(h
x
^hy).count('1')为汉明距离公式,其中,h
x
^hy表示将两个哈希值进行异或位运算,bin(h
x
^hy)将h
x
^hy变为二进制,bin(h
x
^hy).count('1')统计bin(h
x
^hy)中数字1的个数;max()表示取最大值,len()表示取数字长度,bin()表示转化成二进制,count('1')表示计算1的个数。
[0049]
优选的,基于推荐的所有匹配图,进行工况融合推理判断步骤,具体包括:
[0050]
(4-8-1)形成匹配图库
[0051]
在推荐的所有匹配图中,取匹配图中每个工况的最高融合相似度,列出排名前三的所有的图片;从而形成匹配图库,图库中有n张图片,其中图片有标注工况与待检测图片融合相似度的信息;
[0052]
(4-8-2)提取n张匹配图证据
[0053]
提取上一步骤中匹配图库中的n张匹配图的证据,第i张匹配图证据基本概率分配(bpa)表示为:
[0054][0055]
其中:
[0056]
mi(a1)为第i张匹配图证明待测图为a1工况时的bpa值,
[0057]
mi(a2)为第i张匹配图证明待测图为a2工况时的bpa值,
[0058]
mi(a3)为第i张匹配图证明待测图为a3工况时的bpa值,
[0059]
mi(θ)为第i张匹配图证明待测图工况为“未知”时的bpa值;
[0060]
pi(a1)为待测图与标记为a1工况的第i张匹配图的融合相似度,
[0061]
pi(a2)为待测图与标记为a2工况的第i张匹配图的融合相似度,
[0062]
pi(a3)为待测图与标记为a3工况的第i张匹配图的融合相似度;
[0063]
每一张的工况图片的相似度作为此张图片对此工况的概率赋值,由于图片工况已标定,那么这张图片其余工况概率赋值必然为0;
[0064]
(4-8-3)对n个证据融合
[0065]
对n张图的基本概率分配(bpa)进行证据融合,得到融合后每种工况的综合概率分配值m(a
x
),计算完毕后汇总成一个集合q;
[0066]
(4-8-4)融合结果综合判断。
[0067]
优选的,集合q的融合计算方法为:
[0068][0069]
其中aj,j=1,2,3表示a1、a2、a3工况;xi代表a1、a2、a3和θ对应三种工况和一种“未知”四种情况之一,i=1,2,...,n;mi(xi)为第i张图对xi情况的bpa值;其中:
[0070][0071]
∩xi=x1∩x2∩...∩xn[0072][0073]
集合q为q={m(a1),m(a2),m(a3)}。
[0074]
优选的,融合结果综合判断包括:
[0075]
(4-8-4-1)统计q中概率分配值大于等于0.32的概率分配值及对应工况;将这一种或多种工况列为当前工况并按其概率分配值排列。
[0076]
(4-8-4-2)统计q中概率分配值大于0.28,小于0.32的概率分配值及对应工况;将这一种或多种工况列为当前可能工况并按其概率分配值排列。
[0077]
有益效果:
[0078]
1.整个系统使用cbir技术、匹配算法和融合推理手段,打破传统识别方法的局限,从工程实际出发,在确实只具有一种工况的时候可以精确识别一种工况,同时也可综合判断同时发生的最多三个故障,更具有实际应用价值。
[0079]
2.提出一种融合相似度计算方法。将基于皮尔逊相关系数算法和局部哈希算法求
取的相似度按一定步骤进行融合,充分发挥两者优势,以获取待测图与样本图更加合理的相似度,最终有效提高识别率的作用。
[0080]
基于皮尔逊相关系数算法的相似度,与其他如传统余弦距离计算方法相比,具有平移不变性和尺度不变性,可以克服受图片平移及图像缩放的影响。非常适合抽油机由于长时间使用造成的载荷整体增加或者位移量整体向某一方向偏移,进而导致示功图整体偏移的状况,可以一定程度量避免由于机器老化造成的识别率下降。该方法对两图整体相似度评价的稳定性好,但易受光线亮度、对比度及颜色影响,图片旋转也会对结果产生重大影响。基于局部哈希算法的相似度,基于类似空间域转换思想,图片放大或缩小,改变纵横比,或增加减少亮度、对比度、颜色,对hash值的影响很小。局部敏感哈希算法可以有效的忽略示功图中平移、缩放、纵横比变化、旋转以及光线所带来的问题。但是局部敏感哈希算法对由于局部分析能力强,对图片内容非常敏感,较小的内容干扰,很容易引起图片的哈希值较大变化,从而导致相似度整体评价的稳定性不足。
[0081]
3.提出一种工况融合方法。可以将多个具有工况信息的相似图片经过工况融合方法融合,将几个工况信息证据融合,实现综合判断同时发生的最多三个故障的功能。并且这种方法通过一定技术方法同时兼备传统识别方法功能,在待检测示功图确实只具有一种工况信息的时候,也可以识别出一种工况。
[0082]
4.整个系统具有动态学习功能,在每一次识别后会将判断结果送上位,会将多种工况的图放入匹配图库中,升级迭代匹配图库。在以后工况融合的时候,逐渐提高识别准确率,对多种工况发生的时候识别也更敏感。
附图说明
[0083]
图1为本发明的方法整体流程图
[0084]
图2为本发明的一张表示凡尔漏失的示功图
[0085]
图3为本发明的凡尔漏失示功图在avgpool层的特征图
[0086]
图4为本发明的活塞下行碰泵标准示功图
[0087]
图5为本发明的活塞下行碰泵标准示意图在avgpool层的特征图
[0088]
图6为本发明的示功图获取、标注分类以及训练图
[0089]
图7为本发明的基于示功图融合相似度的抽油工况融合推理判断图
[0090]
图8为本发明的待检测的示功图
[0091]
图9为本发明的待检测的示功图在avgpool层的特征图
[0092]
图10为本发明的样本图与待测图图片的比较图
[0093]
图11为本发明的工况融合推理判断流程图
具体实施方式
[0094]
一种基于示功图融合相似度的抽油工况融合推理识别方法,结合图1,包括以下流程:
[0095]
(1)示功图获取、标注分类以及训练。
[0096]
(2)用训练好后的resnet50对样本集中每张图进行特征提取,保存特征向量。
[0097]
使用训练好的resnet50网络对标注好的训练集进行特征提取,并保存所有
avgpool层的特征结果,特征提取的过程举例如下:
[0098]
(2-1)取一张表示凡尔漏失的示功图,如图2。
[0099]
这张示功图转化为维数为256
×
256
×
3的数组。
[0100]
在进行一系列特征提取后,保存avgpool层数据,将其可视化如图3。
[0101]
此时在avgpool层这张示功图变为了维数为1
×
2048的数组,将原始的256
×
256
×
3=196608个特征简化为2048个特征,将这组特征向量进行保存。
[0102]
(2-2)又如取一张表示活塞下行碰泵的示功图,如图4。
[0103]
这张示功图转化为维数为256
×
256
×
3的数组。
[0104]
在进行一系列特征提取后,保存avgpool层数据,将其可视化如图5。
[0105]
此时在avgpool层这张示功图变为了维数为1
×
2048的数组,将原始的256
×
256
×
3=196608个特征简化为2048个特征,将这组特征向量进行保存。
[0106]
(3)获取待检测的抽油井示功仪采集的载荷和位移数据,绘制示功图。
[0107]
获取待检测的抽油井示功仪采集的载荷和位移数据,使用opencv将载荷和位移数据绘制成待识别的示功图。(绘制示功图方法为以位移为横坐标x,载荷量为横坐标y,使用opencv中的多边形绘图函数将数据绘制成示功图形式。)
[0108]
(4)基于示功图融合相似度的抽油工况融合推理判断。
[0109]
(5)将工况判断结果送上位显示。
[0110]
整体流程中示功图获取、标注分类以及训练主要包括对示功图的获取、对现有示功图数据集标注分类,以及使用标注好的示功图数据集对resnet50训练,并保存训练权值。结合图6,具体步骤为:
[0111]
(1-1)获取抽油井示功仪采集的载荷量和位移量数据,以位移为横坐标x,载荷量为横坐标y,使用opencv中的多边形绘图函数工具包将数据绘制成示功图。
[0112]
(1-2)业务专家对示功图进行预处理,剔除有明显错误示功图,形成示功图数据集;
[0113]
(1-3)业务专家对示功图数据集中示功图进行标注分类将标注分类好的数据集按7:3比例分为训练集和测试集;
[0114]
(1-4)将训练集放入resnet50神经网络中进行训练。其中激活函数为relu,池化方法输入层使用max pooling,最后输出层使用avg pooling,优化代价函数为cross-entropy交叉熵,batch_size为16。
[0115]
(1-5)在训练完成后,将训练完的resnet50权值保存。
[0116]
结合图7,整体流程中所述基于示功图融合相似度的抽油工况融合推理判断具体包括:
[0117]
(4-1)使用resnet50提取待检测示功图特征
[0118]
将传入的待检测示功图(如图8所示)放入训练好的resnet50中,提取待测图在avgpool层的特征向量t=[t1,t2,...,t
2048
](如图9所示)。
[0119]
(4-2)调取样本集中第i张图的特征向量si=[si1,si2,...si
2048
],0《i≤n,其中n为样本集中样本图的个数。
[0120]
(4-3)待检测图与样本图的比较如图10所示,分别基于皮尔逊相关系数算法和局部敏感哈希算法,计算待检测图与样本集中第i张图的相似度。已知待检测图与样本集中第
i张图的特征向量分别为:t=[t1,t2,...,t
2048
],si=[si1,si2,...si
2048
]。
[0121]
(4-3-1)皮尔逊相关系数算法(pearson)
[0122]
基于皮尔逊相关系数算法计算待检测图与样本集中第i张图的特征向量间相似度mpi为:
[0123][0124]
其中cov为协方差,为向量平均值。
[0125]
通常情况下皮尔逊相关系数算法通过以下取值范围判断变量的相关强度:
[0126]
表1皮尔逊相关系数算法相关系数与之对应的相关关系
[0127][0128][0129]
使用图4活塞下行碰泵标准示意图和图8待检测图的两张图为例,图4特征向量为s1=[0.14989834,0.25044987,0.01442009,...,0.04498396,0....0.13138881],图8特征向量t=[0.14860852,0.35052535,0.04173719...0.03383199,0....0.14634456]。
[0130]
使用皮尔逊相关系数算法的相关系数:
[0131][0132][0133][0134][0135][0136]
皮尔逊相关系数mpi为0.9595958626455949。
[0137]
(4-3-2)局部哈希值算法(locality-sensitive hashing,lsh)
[0138]
局部哈希值算法过程为将两个图片的特征向量转化为哈希值,然后使用汉明距离判别相似度大小。具体处理步骤如下:
[0139]
1)首先分别计算出特征提取后特征向量t、si中的平均数avg,avg舍去小数;
[0140]
2)将特征向量t、si通过与平均数avg比较,小于avg的0,否则取1;从更新完的特征向量中从右往左取数书写为二进制形式,再转化为十进制作为哈希值;从而获得特征向量t、si对应的哈希值h
x
,hy;
[0141]
计算哈希值的举例:
[0142]
①
以一个1x9的特征向量举例,特征向量为:
[0143]
[247,251,249,246,250,248,254,255,255]
[0144]
②
求这个特征向量的平均值avg:
[0145]
avg=(247+251+249+246+250+248+254+255+255)/9=250(舍去小数)
[0146]
③
如果特征向量中的数字小于平均值取0,否则取1,特征向量更新为
[0147]
[0,1,0,0,1,0,1,1,1]
[0148]
④
把特征向量从右向左输写为二进制111010010,求二进制111010010的十进制是450
[0149]
⑤
哈希值为450
[0150]
3)计算基于局部敏感哈希算法的相似度大小mhi[0151][0152]
其中:distance=bin(h
x
^hy).count('1')为汉明距离公式。其中,h
x
^hy表示将两个哈希值进行异或位运算,bin(h
x
^hy)将h
x
^hy变为二进制,bin(h
x
^hy).count('1')统计bin(h
x
^hy)中数字1的个数。max()表示取最大值,len()表示取数字长度,bin()表示转化成二进制,count('1')表示计算1的个数。
[0153]
继续使用图4活塞下行碰泵标准示意图和图8待检测图两张图为例。
[0154]
相似度计算如下:
[0155]
图4的局部哈希值为
[0156]
134907394872231459307921595053165966727638211850364403603817576411392320731173461515081931003824103848610395831696351907040851782228041860994642167480938160500881936760088328367755998578385056681263307472397144928353884295331378643730737444091359742116256489605880085183816832815426175848776508902642861101099718331667626993756088571910678548165049562655531040347315192365147004731519463191348029938325536398024923807910995856106628030724706982857657002928153864864676392486921999246267706746163086495545981910815108924723659871375564789477016296800409881711195186298617086596686860594133790662039913834971001258192
[0157]
图8的局部哈希值为
[0158]
134909336164677193315098704209033677690447002363625012226134058236907706682825938415330440596553877599573069588765898273219928634772258857712335020535886748323100840672670136928410227415944070798320660373464007207826192880682399295486352378417213368941249609392065322087900294454823171257989969080404957097945954668382504147265751628834405361978471569048472747634698092774719229568280672280314028714700120426807933140494888691468045948960439442940733676982095422331829668218501885620193652448187157640888011104851164295253464255310988804922158495010276988600247673701019379376880658833265386067561510743278490222832
[0159]
两图使用局部哈希计算后的相似度mhi为0.9084679393049437。
[0160]
(4-4)基于两种算法分别计算待测示功图与样本集中第i张图相似度mpi及mhi大小后,对两种相似度进行融合,获得待测图与标记为x工况的第i张匹配图的融合相似度pi(x),x=a1,a2...ak,ak为样本集中的全部工况之一),具体融合方法如下:
[0161]
pi(x)=mpi×
mhi+mpi(1-mhi)+mhi(1-mpi)
[0162]
其中mpi是基于皮尔逊算法的相似度值;mhi是基于敏感哈希算法的相似度值。
[0163]
举例:使用(4-3-1)和(4-3-2)的mpi和mhi继续举例说明,如表2:
[0164]
表2 mpi和mhi的表格形式
[0165]
mpimhi0.960.91
[0166]
根据表中数据可求解:
[0167]
pi(x)=0.96*0.91+0.96*0.09+0.91*0.04=0.9964
[0168]
所以对两种相似度融合获得融合相似度pi(x)为0.9964
[0169]
(4-5)pi(x)与预先设置的相似度阈值ps比对,
[0170]
(4-5-1)如果pi(x)》ps,将该图存入初步推荐图库,进入下一步骤;
[0171]
(4-5-2)如果pi(x)》ps,跳过这个匹配的图片,进入下一步骤;
[0172]
(4-6)判断数据库中所有样本图是否均比较过
[0173]
(4-6-1)没有全部计算完则取下张样本图与待测图比较,然后返回到第2步,重复循环;
[0174]
(4-6-2)全部计算完进入下一个环节;
[0175]
(4-7)判断是否有相似的匹配照片
[0176]
(4-7-1)如果有推荐的匹配照片,那么列出所有推荐的匹配图片,转入下一步;
[0177]
(4-7-2)如果没有推荐的匹配照片,系统提示没有匹配照片,只能凭借工艺专家来判断分类,并进行标注后放入训练集,供下一轮的训练更新resnet神经网络
[0178]
(4-8)基于推荐的所有匹配图,进行工况融合推理判断。
[0179]
(4-9)输出当前工况状态判断结果。
[0180]
结合图11,基于初步推荐图库中所有图片,进行工况融合推理判断的具体流程如下:
[0181]
(4-8-1)形成匹配图库
[0182]
在初步推荐图库中的所有匹配图中,取匹配图中每个工况的最高融合相似度,列出排名前三的所有的图片。从而形成匹配图库,图库中有n张图片,其中图片有标注工况与待检测图片融合相似度的信息。
[0183]
(4-8-2)提取n张匹配图证据
[0184]
提取上一步骤中匹配图库中的n张匹配图的证据。第i张匹配图证据基本概率分配(bpa)表示为:
[0185][0186]
其中:
[0187]
mi(a1)为第i张匹配图证明待测图为a1工况时的bpa值,
[0188]
mi(a2)为第i张匹配图证明待测图为a2工况时的bpa值,
[0189]
mi(a3)为第i张匹配图证明待测图为a3工况时的bpa值,
[0190]
mi(θ)为第i张匹配图证明待测图工况为“未知”时的bpa值。
[0191]
pi(a1)为待测图与标记为a1工况的第i张匹配图的融合相似度,
[0192]
pi(a2)为待测图与标记为a2工况的第i张匹配图的融合相似度,
[0193]
pi(a3)为待测图与标记为a3工况的第i张匹配图的融合相似度。
[0194]
每一张的工况图片的相似度作为此张图片对此工况的概率赋值,由于图片工况已标定,那么这张图片其余工况概率赋值必然为0。
[0195]
举例说明:
[0196]
例1:现第一张图片为工况a1,待测疑难图与第一张图片的融合相似度为p1(a1),那么第i张匹配图证据基本概率分配(bpa)表示为第一张图片对工况a1的概率赋值m1(a1)为p1(a1),对其他工况的概率赋值为0,记为表格形式如表3。
[0197]
表3表格形式
[0198][0199]
例2:二次筛选后有五张图片,第一张图片与工况a1的相似度为p1(a1),第二张图片与工况a2的相似度为p2(a2),第三张图片与工况a1的相似度为p3(a1),第四张图片与工况a2的相似度为p4(a2),第五张图片与工况a3的相似度为p5(a3)。则这五张匹配图证据基本概率分配(bpa)分别表示为
[0200][0201][0202]
表格形式如表4。
[0203]
表4的表格形式
[0204][0205]
(4-8-3)对n个证据融合
[0206]
对n张图的基本概率分配(bpa)进行证据融合,得到融合后每种工况的综合概率分配值m(aj),计算完毕后汇总成一个集合q。具体融合计算方法为:
[0207][0208]
其中aj,j=1,2,3表示a1、a2、a3工况;xi代表a1、a2、a3和θ对应三种工况和一种“未知”四种情况之一,i=1,2,...,n;mi(xi)为第i张图对xi情况的bpa值;其中:
[0209][0210]
∩xi=x1∩x2∩...∩xn[0211][0212]
对表4举例赋值后如表5所示:
[0213]
表5赋值后表格形式
[0214][0215]
1).表5中的工况a1,工况a2,工况a3融合后的概率分配值为:
[0216]
①
工况a1,油管漏失的综合概率分配值为:
[0217][0218]
m(a1)=[m1(a1)*m2(θ)*m3(a1)*m4(θ)*m5(θ)+m1(a1)*m2(θ)*m3(θ)*m4(θ)*m5(θ)+m1(θ)*m2(θ)*m3(a1)*m4(θ)*m5(θ)]/k=0.0329/0.06005=0.5478
[0219]
②
工况a2,抽油管断脱的综合概率分配值为:
[0220][0221]
m(a2)=[m1(θ)*m2(a2)*m3(θ)*m4(a2)*m5(θ)+m1(θ)*m2(a2)*m3(θ)*m4(θ)*m5(θ)+m1(θ)*m2(θ)*m3(θ)*m4(a2)*m5(θ)]/k=0.0219/0.06005=0.3647
[0222]
③
工况a3,稠油的综合概率分配值为:
[0223][0224]
m(a3)=m1(θ)*m2(θ)*m3(θ)*m4(θ)*m5(a3)/k=0.0525
[0225]
2).其中表5中的系数k为:
[0226][0227]
k=m1(a1)*m2(θ)*m3(a1)*m4(θ)*m5(θ)+m1(a1)*m2(θ)*m3(θ)*m4(θ)*m5(θ)+m1(θ)*m2(a2)*m3(θ)*m4(a2)*m5(θ)+m1(θ)*m2(a2)*m3(θ)*m4(θ)*m5(θ)+m1(θ)*m2(θ)*m3(a1)*m4(θ)*m5(θ)+m1(θ)*m2(θ)*m3(θ)*m4(a2)*m5(θ)+m1(θ)*m2(θ)*m3(θ)*m4(θ)*m5(a3)+m1(θ)*
m2
(θ)*m3(θ)*m4(θ)*m5(θ)=0.06005
[0228]
3).集合q为q={m(a1),m(a2),m(a3)}={0.5478,0.3647,0.0525}
[0229]
(4-8-4)融合结果综合判断
[0230]
(4-8-4-1)统计q中概率分配值大于等于0.32的概率分配值及对应工况;将这一种或多种工况列为当前工况并按其概率分配值排列。
[0231]
(4-8-4-2)统计q中概率分配值大于0.28,小于0.32的概率分配值及对应工况;将这一种或多种工况列为当前可能工况并按其概率分配值排列。
[0232]
例如根据(4-8-3)步骤中,综合概率分配值的集合为q={0.5478,0.3647,0.0525}。
[0233]
1)经过统计大于等于0.32的概率分配值,有0.5478,0.3647,这两个概率分配值对应的工况为油管漏失、抽油管断脱,所以综合工况是油管漏失、抽油管断脱。
[0234]
2)经过统计大于0.28,小于0.32的概率分配值,集合中没有满足此步骤的数据,那么没有其他可能的工况。
[0235]
例如根据(4-8-4)步骤的融合结果处理后,综合工况是油管漏失、抽油管断脱,没有其他可能的工况。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1