一种提高超标量处理器缓存命中率的方法及装置与流程
1.本公开涉及计算机技术领域,尤其涉及一种提高超标量处理器缓存命中率的方法及装置。
背景技术:
2.超标量处理器作为当代数字化和智能化工业中的核心,已深入我们生活的方方面面。在过去,cpu访问主存速度不高一直是限制处理器提高性能的瓶颈问题,于是便有了高速缓存cache系统的出现。cache的引入提高了处理器的整体性能,然而现代超标处理器处理速度和处理数据类型都发生了翻天覆地的变化,如何进一步挖掘超标量处理器的潜在性能,提高cache的命中率已经成为提升超标量处理器性能的重要途径之一。
3.cache的命中率与cache的映射方式和替换算法息息相关。在先有的超标量处理器中,通常采用的映射方式有直接映射、组相连和全相连,全相连最灵活但是实现比较复杂,直接映射比较容易实现,但是可能产生快速抖动,组相连则是前两者的一个折衷。常用的替换策略有近期最少使用法(lru)、随机替换法和先入先出法(fifo)等,lru顾名思义是替换掉近期最少使用的某个块,但是随着cache相关度的增加,相比于lru替换来说会产生更多的cache miss,但随着容量的增大这个差距会越来越小,fifo替换的原则是如果某一个数据最先进入缓存中,那它应该被最早替换掉,这种方式实现起来比较容易,但是可能会把一些经常使用的程序块替换掉,导致cache miss增多。
4.由于cache的容量是有限的,主存中的内容不可能全部映射到cache中,因此现有的解决方案都是利用了时间局部性和空间局部性原理,在空间局部性中,如果某项数据被访问,那么与它相邻的数据很可能很快被访问;在时间局部性中,如果某个数据被访问,那么在不久的将来很可能再次被访问。然而,所有基于这个局部性原理的技术都会导致cache miss,如随机替换法没有固定的规律可循,高命中率难以保证;先入先出算法不能突出存储器数据的局部性,即使使用频率很高的数据也会被替换掉,命中率也不会很高;最近最少使用法最能突出局部性,然而在复杂的超标量处理器中实现成本非常高。
技术实现要素:
5.本公开的目的是要提供一种提高超标量处理器缓存命中率的方法及装置,可以解决上述现有技术问题中的一个或者多个。
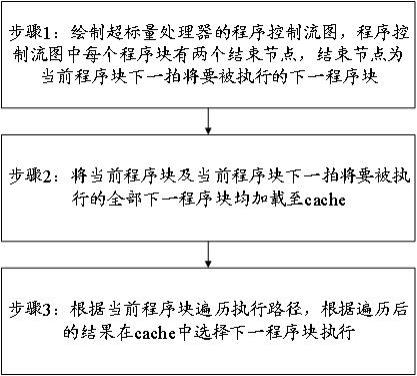
6.根据本公开的一个方面,提供了一种提高超标量处理器缓存命中率的方法,包括以下步骤:步骤1:绘制超标量处理器的程序控制流图,程序控制流图中每个程序块有两个结束节点,结束节点为当前程序块下一拍将要被执行的下一程序块;步骤2:将当前程序块及当前程序块下一拍将要被执行的全部下一程序块均加载至cache;步骤3:根据当前程序块遍历执行路径,根据遍历后的结果在cache中选择下一程
序块执行。
7.在可能的实施方式中,在步骤1中,绘制超标量处理器的程序控制流图包括:步骤1.1:获取超标量处理器源码;步骤1.2:将超标量处理器源码转化成抽象语法树;步骤1.3:将程序划分为有一个开始节点和两个结束节点的程序块,完成程序控制流图的绘制。
8.在可能的实施方式中,在步骤2中,将当前程序块及当前程序块下一拍将要被执行的全部下一程序块均加载至cache包括,步骤2.1:将程序控制流图中的程序块以链表数据结构存储在程序控制流图存储器内,链表数据结构由当前程序块bc、左子树中的下一程序块bl和右子树中的下一程序块br构成,其中,左子树中的下一程序块bl为与当前程序块相连的下一程序块,右子树中的下一程序块br为与当前程序块不相连的下一程序块;步骤2.2:加载和替换单元从程序控制流图存储器加载一定数量的程序块,并将当前要执行的程序块和将要被执行的程序块同时加载到cache中。
9.在可能的实施方式中,在步骤3中,根据当前程序块遍历执行路径,根据遍历后的结果在cache中选择下一程序块执行包括,步骤3.1:cpu进入第一个程序块;步骤3.2:cache判断下一拍执行的程序块是否是当前程序块相连的程序块,若不是,则执行步骤3.3,若是,则执行步骤3.4;步骤3.3:丢弃左子树中的下一程序块bl,并从加载和替换单元中根据程序控制流图向下加载一级右子树程序集;步骤3.4:丢弃右子树中的下一程序块br,并从加载和替换单元中根据程序控制流图向下加载一级左子树程序集;步骤3.5:cpu进入未丢弃的下一程序块,并判断程序块是否结束,若程序块未结束,返回执行步骤3.2;若程序块已结束,则当前程序结束。
10.根据本公开的另一个方面,提供了一种提高超标量处理器缓存命中率的装置,用于实现上述任一一种提高超标量处理器缓存命中率的方法,包括:程序控制流图绘制单元,用于绘制超标量处理器的程序控制流图,程序控制流图中每个程序块有两个结束节点,结束节点为当前程序块下一拍将要被执行的下一程序块;加载和替换单元,用于将当前程序块及当前程序块下一拍将要被执行的全部下一程序块均加载至cache;执行路径遍历单元,用于根据当前程序块遍历执行路径,根据遍历后的结果在cache中选择下一程序块执行。
11.在可能的实施方式中,在程序控制流图绘制单元中包括:源码获取子单元,用于获取超标量处理器源码;抽象语法树转化子单元,用于将超标量处理器源码转化成抽象语法树;程序块划分子单元,用于将程序划分为有一个开始节点和两个结束节点的程序块,完成程序控制流图的绘制。
12.在可能的实施方式中,一种提高超标量处理器缓存命中率的装置还包括程序控制
流图存储器,用于将程序控制流图中的程序块以链表数据结构存储,链表数据结构由当前程序块bc、左子树中的下一程序块bl和右子树中的下一程序块br构成,其中,左子树中的下一程序块bl为与当前程序块相连的下一程序块,右子树中的下一程序块br为与当前程序块不相连的下一程序块;加载和替换单元从程序控制流图存储器加载一定数量的程序块,并将当前要执行的程序块和将要被执行的程序块同时加载到cache中。
13.在可能的实施方式中,执行路径遍历单元包括:程序块判断子单元,用于当cpu进入当前程序块时,判断下一拍执行的程序块是否是当前程序块相连的程序块;下一程序块选择子单元,用于根据程序判断子单元的判断结果,选择将要被执行的下一程序块,同时将不会被执行的下一程序块丢弃;程序集加载子单元,用于根据程序控制流图,在将要被执行的下一程序块所在的子树,向下加载一级程序集;程序块结束判断子单元,用于判断程序块是否结束,若程序块结束,则程序结束。
14.本公开提供的一种提高超标量处理器缓存命中率的方法及装置,通过绘制超标量处理器的程序控制流图,将当前执行的程序块及下一个要执行的程序块提前放入cache中,使得cache中总会有一个程序块可以处在执行中,极大提高了缓存的命中率。
15.另外,在本公开技术方案中,凡未作特别说明的,均可通过采用本领域中的常规手段来实现本技术方案。
附图说明
16.为了更清楚地说明本公开实施例的技术方案,下面将对实施例描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
17.图1为本公开实施例提供的一种提高超标量处理器缓存命中率的方法的流程图。
18.图2为本公开实施例提供的一种提高超标量处理器缓存命中率的方法中一个程序控制流图的简单示意图。
19.图3为本公开实施例提供的一种提高超标量处理器缓存命中率的装置的结构示意图。
具体实施方式
20.本公开说明书和权利要求书中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如包含了一系列的步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、系统、产品或设备固有的其他步骤或单元。
21.为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是
本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
22.实施例1:在本实施例中,参考说明书附图1,提供了一种提高超标量处理器缓存命中率的方法,包括以下步骤:步骤1:绘制超标量处理器的程序控制流图,程序控制流图中每个程序块有两个结束节点,结束节点为当前程序块下一拍将要被执行的下一程序块;步骤2:将当前程序块及当前程序块下一拍将要被执行的全部下一程序块均加载至cache;步骤3:根据当前程序块遍历执行路径,根据遍历后的结果在cache中选择下一程序块执行。
23.在可选的实施例中,在步骤1中,绘制超标量处理器的程序控制流图包括:步骤1.1:获取超标量处理器源码;步骤1.2:将超标量处理器源码转化成抽象语法树;步骤1.3:根据抽象语法树将程序划分为有一个开始节点和两个结束节点的程序块,完成程序控制流图的绘制。
24.具体的,在本实施例中,选用基本程序块作为程序化分的最小粒度,同时将程序控制流图抽象为由节点和有向边构成的网络图。参考说明书附图2,示出了一个程序控制流图的简单示意图,图中每个节点表示一个程序块,即cache中一个cache line中的数据,有向边表示程序块之间的执行路径。
25.具体的,两个结束节点分别用于进入下一个程序块和跳转到另一个程序块,即结束节点为当前程序块下一拍将要被执行的下一程序块。
26.在可选的实施例中,在步骤2中,将当前程序块及当前程序块下一拍将要被执行的全部下一程序块均加载至cache包括,步骤2.1:将程序控制流图中的程序块以链表数据结构存储在程序控制流图存储器内,链表数据结构由当前程序块bc、左子树中的下一程序块bl和右子树中的下一程序块br构成,其中,左子树中的下一程序块bl为与当前程序块相连的下一程序块,右子树中的下一程序块br为与当前程序块不相连的下一程序块;步骤2.2:加载和替换单元从程序控制流图存储器加载一定数量的程序块,并将当前要执行的程序块和将要被执行的程序块同时加载到cache中。
27.由此,通过设置程序控制流图存储器专供程序控制流图使用,能够高速进行超标量处理器程序控制流图需要执行的操作,例如程序块的更新;同时通过设置专用的程序控制流图存储器,使程序控制流图和超标量处理器的互不干预,提高了程序运行稳定性,提高处理器性能。
28.具体的,由于程序块相当于固定数量的cache line的集合,因此左子树中的下一程序块bl表示继续执行cache中下一个cache line,即左子树中的下一程序块与当前程序块相连;右子树中的下一程序块br表示跳转执行cache中与当前程序块不相连的cache line,即右子树中的下一程序块与当前程序块不相连。应当理解的是,此处左右子树表示的含义仅为示意性举例,在可能的实施例中,左子树中的下一程序块bl可以表示跳转执行
cache中与当前程序块不相连的cache line,右子树中的下一程序块br也可以表示继续执行cache中下一个cache line。
29.具体的,加载和替换单元可以将程序块的地址信息发送至cache以加载程序块。
30.在可选的实施例中,若当前程序块bc只有一个下一程序块,则左子树中的下一程序块bl和右子树中的下一程序块br地址的优先级是一样的。
31.在可选的实施例中,可以使用数字电路构建一个加载和替换单元,用于从程序控制流图存储器加载一定数量的程序块,并将当前要执行的程序块和将要被执行的程序块传递到cache中。
32.通过将当前要执行的程序块和将要被执行的程序块同时加载到cache中,使得若当前执行的程序块需要进入到下一程序块,无需通过预测进入,可以直接从cache中获取将要被执行的程序块,而从cache中加载数据通常只需几个周期,由此,避免了传统超标量处理器中未命中时需要重新从内存中导入数据的长达几十到几百周期的过程,提高了处理器的处理效率。
33.在可选的实施例中,在步骤3中,根据当前程序块遍历执行路径,根据遍历后的结果在cache中选择下一程序块执行包括,步骤3.1:cpu进入第一个程序块;步骤3.2:cache判断下一拍执行的程序块是否是当前程序块相连的程序块,若不是,则执行步骤3.3,若是,则执行步骤3.4;步骤3.3:cache丢弃左子树中的下一程序块bl,并从加载和替换单元中根据程序控制流图向下加载一级右子树程序集;步骤3.4:cache丢弃右子树中的下一程序块br,并从加载和替换单元中根据程序控制流图向下加载一级左子树程序集;步骤3.5:cpu进入未丢弃的下一程序块,并判断程序块是否结束,若程序块未结束,返回执行步骤3.2;若程序块已结束,则当前程序结束。
34.当前程序块被cpu进入并执行时,当前程序块的两个下一程序块也已经被加载进入cache中,因此,无论将要执行的下一程序块是左子树中的还是右子树中的,都不会产生cache未命中。当cpu进入某一子树的下一程序块,另一子树都会从cache中丢弃,并且新的子树会提前加载至当前子树的叶子上,由此,根据程序控制流图动态变化的子树使得所有所需程序块都可以在cache中获得。
35.在可选的实施例中,当第一个程序块被加载时,由于cache还没有使用过该程序块,因此会出现强制未命中。由此,实现了除程序执行初期的强制未命中外,不存在其他的cache未命中,极大提升了缓存的命中率。
36.在可选的实施例中,在cache中预先定义特定深度的子树,由此,超标量处理器可实现直接从cache中进入程序块执行,而无需从主存中进入,提高处理效率,提升处理器性能。
37.本公开提供的一种提高超标量处理器缓存命中率的方法,通过绘制超标量处理器的程序控制流图,将当前执行的程序块及下一个要执行的程序块提前放入cache中,避免了基于局部性原理预测带来的不确定性,使得cache中总会有一个程序块可以处在执行中,极大提高了缓存的命中率,有效提高超标量处理器的性能。
38.实施例2:在本实施例中,参考说明书附图3,提供了一种提高超标量处理器缓存命中率的装置,用于实现上述方法实施例中任一一种提高超标量处理器缓存命中率的方法,一种提高超标量处理器缓存命中率的装置至少包括:程序控制流图绘制单元11,用于绘制超标量处理器的程序控制流图,程序控制流图中每个程序块有两个结束节点,结束节点为当前程序块下一拍将要被执行的下一程序块;加载和替换单元12,用于将当前程序块及当前程序块下一拍将要被执行的全部下一程序块均加载至cache;执行路径遍历单元13,用于根据当前程序块遍历执行路径,根据遍历后的结果在cache中选择下一程序块执行。
39.在可选的实施例中,在程序控制流图绘制单元中包括:源码获取子单元,用于获取超标量处理器源码;抽象语法树转化子单元,用于将超标量处理器源码转化成抽象语法树;程序块划分子单元,用于将程序划分为有一个开始节点和两个结束节点的程序块,完成程序控制流图的绘制。
40.在可选的实施例中,一种提高超标量处理器缓存命中率的装置还包括程序控制流图存储器,用于将程序控制流图中的程序块以链表数据结构存储,链表数据结构由当前程序块bc、左子树中的下一程序块bl和右子树中的下一程序块br构成,其中,左子树中的下一程序块bl为与当前程序块相连的下一程序块,右子树中的下一程序块br为与当前程序块不相连的下一程序块;加载和替换单元从程序控制流图存储器加载一定数量的程序块,并将当前要执行的程序块和将要被执行的程序块同时加载到cache中。
41.在可选的实施例中,执行路径遍历单元包括:程序块判断子单元,用于当cpu进入当前程序块时,判断下一拍执行的程序块是否是当前程序块相连的程序块;下一程序块选择子单元,用于根据程序判断子单元的判断结果,选择将要被执行的下一程序块,同时将不会被执行的下一程序块丢弃;程序集加载子单元,用于根据程序控制流图,在将要被执行的下一程序块所在的子树,向下加载一级程序集;程序块结束判断子单元,用于判断程序块是否结束,若程序块结束,则程序结束。
42.本公开提供的一种提高超标量处理器缓存命中率的装置,通过绘制超标量处理器的程序控制流图,将当前执行的程序块及下一个要执行的程序块提前放入cache中,避免了基于局部性原理预测带来的不确定性,使得cache中总会有一个程序块可以处在执行中,极大提高了缓存的命中率,有效提高超标量处理器的性能。
43.上述本说明书实施例先后顺序仅仅为了描述,不代表实施例的优劣。且上述对说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实
现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
44.本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
45.本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
46.以上仅为本公开的较佳实施例,并不用以限制本公开,凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1