视频处理方法、视频处理装置、终端及存储介质与流程
1.本技术涉及影像技术领域,更具体而言,涉及一种视频处理方法、视频处理装置、终端、及非易失性计算机可读存储介质。
背景技术:
2.视频画面稳定与否,极大程度上影响视频观感,视频防抖技术可通过对画面进行一定的旋转变形和裁切,获得具有稳定效果的视频。
3.不同于普通的视频防抖,在有人像的视频中,除去视频整体的防抖效果之外,人脸区域的变化过渡是否平滑自然则更为关键,因此需要对人脸区域进行特殊处理。在保证人脸区域防抖效果的同时,还需要避免由于防抖造成的人像扭曲变形。人像视频防抖方案一般只针对图像进行全局处理,无法兼顾人像和画面整体的防抖效果。由于防抖算法会通过图像的旋转变形对画面整体进行重新的渲染,所以在画面整体较好的防抖效果下,人脸区域会随着画面整体的变化而发生一定的变形,造成人像忽大忽小或扭曲形变的效果;而在保护人像变化自然、避免扭曲变形的条件下,则会损失画面整体的防抖效果,二者难以兼得。
技术实现要素:
4.本技术实施方式提供一种视频处理方法、视频处理装置、终端、及非易失性计算机可读存储介质,至少用于解决人像防抖效果和画面整体防抖效果难以兼得的问题。
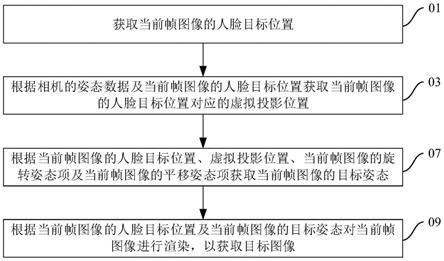
5.本技术实施方式的视频处理方法包括:获取所述当前帧图像的人脸目标位置。根据相机的姿态数据及所述当前帧图像的人脸目标位置获取所述当前帧图像的人脸目标位置对应的虚拟投影位置。根据所述当前帧图像的人脸目标位置、所述虚拟投影位置、所述当前帧图像的旋转姿态项及所述当前帧图像的平移姿态项获取所述当前帧图像的目标姿态。及根据所述当前帧图像的人脸目标位置及所述当前帧图像的目标姿态对所述当前帧图像进行渲染,以获取目标图像。
6.本技术实施方式的视频处理装置包括第一获取模块、第二获取模块、第三获取模块及渲染模块。所述第一获取模块用于获取所述当前帧图像的人脸目标位置。所述第二获取模块用于根据相机的姿态数据及所述当前帧图像的人脸目标位置获取所述当前帧图像的人脸目标位置对应的虚拟投影位置。所述第三获取模块用于根据所述当前帧图像的人脸目标位置、所述虚拟投影位置、所述当前帧图像的旋转姿态项及所述当前帧图像的平移姿态项获取所述当前帧图像的目标姿态。所述渲染模块用于根据所述当前帧图像的人脸目标位置及所述当前帧图像的目标姿态对所述当前帧图像进行渲染,以获取目标图像。
7.本技术实施方式的终端包括一个或多个处理器、存储器、及一个或多个程序。其中,一个或多个所述程序被存储在所述存储器中,并且被一个或多个所述处理器执行,所述程序包括用于执行本技术实施方式的视频处理方法的指令,所述视频处理方法包括:获取所述当前帧图像的人脸目标位置。根据相机的姿态数据及所述当前帧图像的人脸目标位置
获取所述当前帧图像的人脸目标位置对应的虚拟投影位置。根据所述当前帧图像的人脸目标位置、所述虚拟投影位置、所述当前帧图像的旋转姿态项及所述当前帧图像的平移姿态项获取所述当前帧图像的目标姿态。及根据所述当前帧图像的人脸目标位置及所述当前帧图像的目标姿态对所述当前帧图像进行渲染,以获取目标图像。
8.本技术实施方式的非易失性计算机可读存储介质存储有计算机程序,当所述计算机程序被一个或多个处理器执行时,所述处理器执行如下视频处理方法:获取所述当前帧图像的人脸目标位置。根据相机的姿态数据及所述当前帧图像的人脸目标位置获取所述当前帧图像的人脸目标位置对应的虚拟投影位置。根据所述当前帧图像的人脸目标位置、所述虚拟投影位置、所述当前帧图像的旋转姿态项及所述当前帧图像的平移姿态项获取所述当前帧图像的目标姿态。及根据所述当前帧图像的人脸目标位置及所述当前帧图像的目标姿态对所述当前帧图像进行渲染,以获取目标图像。
9.本技术的视频处理方法、视频处理装置、终端及非易失性计算机可读存储介质中,根据当前帧图像的人脸目标位置和相机的姿态数据获取当前帧图像的人脸目标位置对应的虚拟投影位置。然后,结合当前帧图像的人脸目标位置、虚拟投影位置和当前帧图像的旋转姿态项、当前帧图像的平移姿态项对当前帧图像的整体姿态进行计算,以获取当前帧图像的目标姿态。最终,根据当前帧图像的目标人脸位置和当前帧图像的目标姿态对当前帧图像进行渲染,得到目标图像。结合当前帧图像的目标姿态和当前帧图像的人脸目标位置获取目标图像,在保证人脸过渡自然、不产生形变的同时,增加画面整体的稳定性,提升了视频的防抖表现。
10.本技术的实施方式的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实施方式的实践了解到。
附图说明
11.本技术的上述和/或附加的方面和优点从结合下面附图对实施方式的描述中将变得明显和容易理解,其中:
12.图1是本技术某些实施方式的视频处理方法的流程图;
13.图2是本技术某些实施方式的视频处理装置的结构示意图;
14.图3是本技术某些实施方式的终端的结构示意图;
15.图4至图14是本技术某些实施方式的视频处理方法的流程图;
16.图15是本技术某些实施方式的非易失性计算机可读存储介质与处理器的连接示意图。
具体实施方式
17.下面详细描述本技术的实施方式,所述实施方式的示例在附图中示出,其中,相同或类似的标号自始至终表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,仅用于解释本技术的实施方式,而不能理解为对本技术的实施方式的限制。
18.请参阅图1,本技术提供一种视频处理方法,视频包括当前帧图像,视频处理方法包括:
19.01:获取当前帧图像的人脸目标位置;
20.03:根据相机的姿态数据及当前帧图像的人脸目标位置获取当前帧图像的人脸目标位置对应的虚拟投影位置;
21.07:根据当前帧图像的人脸目标位置、虚拟投影位置、当前帧图像的旋转姿态项及当前帧图像的平移姿态项获取当前帧图像的目标姿态;及
22.09:根据当前帧图像的人脸目标位置及当前帧图像的目标姿态对当前帧图像进行渲染,以获取目标图像。
23.请结合图2,本技术还提供一种视频处理装置10,视频处理装置10包括第一获取模块11、第二获取模块13、第三获取模块15及渲染模块17。第一获取模块11用于执行01中的方法,即,第一获取模块11用于获取当前帧图像的人脸目标位置。第二获取模块用于执行03中的方法,即,第二获取模块13用于根据相机的姿态数据及当前帧图像的人脸目标位置获取当前帧图像的人脸目标位置对应的虚拟投影位置。第三获取模块15用于执行07中的方法,即,第三获取模块15用于根据当前帧图像的人脸目标位置、虚拟投影位置、当前帧图像的旋转姿态项及当前帧图像的平移姿态项获取当前帧图像的目标姿态。渲染模块17用于执行09中的方法,即,渲染模块17用于根据当前帧图像的人脸目标位置及当前帧图像的目标姿态对当前帧图像进行渲染,以获取目标图像。
24.本技术还提供一种终端100,终端100包括一个或多个处理器30、存储器50、及一个或多个程序。其中,一个或多个程序被存储在存储器50中,并且被一个或多个处理器30执行,程序包括用于执行本技术实施方式的视频处理方法的指令。即,一个或多个处理器30执行程序时,处理器30可以实现01、03、07及09中的方法。即,一个或多个处理器30用于执行:获取当前帧图像的人脸目标位置;根据相机的姿态数据及当前帧图像的人脸目标位置获取当前帧图像的人脸目标位置对应的虚拟投影位置;根据当前帧图像的人脸目标位置、虚拟投影位置、当前帧图像的旋转姿态项及当前帧图像的平移姿态项获取当前帧图像的目标姿态;及根据当前帧图像的人脸目标位置及当前帧图像的目标姿态对当前帧图像进行渲染,以获取目标图像。
25.具体地,终端100可以包括但不限于手机、笔记本电脑、平板电脑、智能手表等终端设备。视频处理装置10可以是集成在终端100中的功能模块的集成。本技术仅以终端100是手机为例进行说明,终端100是其他类型的终端设备时的情形与手机类似,在此不详细展开说明。
26.不同于普通的视频防抖,在有人像的视频中,除去视频整体的防抖效果之外,人脸区域的变化过渡是否平滑自然则更为关键,因此需要对人脸区域进行特殊处理。在保证人脸区域的防抖效果的同时,还需要避免由于防抖造成的人像扭曲变形。人像视频防抖方案一般只针对图像进行全局处理,无法兼顾人像和画面整体的防抖效果。由于防抖算法会通过图像的旋转变形对画面整体进行重新的渲染,所以在画面整体较好的防抖效果下,人脸区域会随着画面整体的变化而发生一定的变形,造成人像忽大忽小或扭曲形变的效果;而在保护人像变化自然、避免扭曲变形的条件下,则会损失画面整体的防抖效果,二者难以兼得。
27.本技术的视频处理方法中,根据当前帧图像的人脸目标位置和相机的姿态数据获取当前帧图像的人脸目标位置对应的虚拟投影位置。然后,结合当前帧图像的人脸目标位
置、虚拟投影位置和当前帧图像的旋转姿态项、当前帧图像的平移姿态项对当前帧图像的整体姿态进行计算,以获取当前帧图像的目标姿态。最终,根据当前帧图像的目标人脸位置和当前帧图像的目标姿态对当前帧图像进行渲染,得到目标图像。结合当前帧图像的目标姿态和当前帧图像的人脸目标位置获取目标图像,在保证人脸过渡自然、不产生形变的同时,增加画面整体的稳定性,提升了视频的防抖表现。
28.方法01中,第一获取模块11或处理器30针对当前帧图像的人脸区域进行防抖处理,以获取当前帧图像的人脸目标位置,以对人脸区域进行特殊处理,保证人脸区域的防抖效果。
29.方法03中,结合相机的姿态数据和当前帧图像的人脸目标位置计算得到当前帧图像的人脸目标位置对应的虚拟投影位置。其中,第二获取模块13或处理器30通过利用相机的姿态数据,可以有效处理视频画面中不同的抖动程度,适用于多种运动场景下的人像视频防抖。同时,支持终端100的实时处理,可以及时获取人像防抖的视频结果。
30.方法07中,当前帧图像的旋转姿态项和当前帧图像的平移姿态项能够反映当前帧图像的虚拟姿态信息。第三获取模块15或处理器30结合当前帧图像的人脸目标位置、虚拟投影位置,当前帧图像的旋转姿态项和当前帧图像的平移姿态项对当前帧图像的整体画面进行计算,以获取当前帧图像的目标姿态,从而保证视频中的人脸过渡自然、不产生形变,同时,还可以增加视频的画面整体的稳定性,提升了视频的防抖效果
31.方法09中,结合当前帧图像的人脸目标位置和当前帧图像的目标姿态对当前帧图像进行渲染,以获取对应当前帧图像的目标图像。同样地,对于视频中的其他帧图像而言,均执行01、03、07及09中的方法,从而生成具有人像防抖效果的视频。
32.请参阅图4,在某些实施方式中,视频还包括前一帧图像,01:获取当前帧图像的人脸目标位置,包括:
33.011:获取当前帧图像的人脸区域的实际中心位置;及
34.013:根据预设的人像区域防抖的目标函数和实际中心位置获取当前帧图像的人脸目标位置,目标函数是关于当前帧图像的人脸目标位置、前一帧图像的人脸目标位置、以及实际中心位置的函数。
35.请结合图2,第一获取模块11还用于执行011及013中的方法。即,第一获取模块11还用于:获取当前帧图像的人脸区域的实际中心位置;及根据预设的人像区域防抖的目标函数和实际中心位置获取当前帧图像的人脸目标位置,目标函数是关于当前帧图像的人脸目标位置、前一帧图像的人脸目标位置、以及实际中心位置的函数。
36.请结合图3,处理器30还用于执行011及013中的方法。即,处理器30还用于:获取当前帧图像的人脸区域的实际中心位置;及根据预设的人像区域防抖的目标函数和实际中心位置获取当前帧图像的人脸目标位置,目标函数是关于当前帧图像的人脸目标位置、前一帧图像的人脸目标位置、以及实际中心位置的函数。
37.具体地,第一获取模块11或处理器30利用卷积神经网络(convolutional neural networks,cnn)人脸检测模型确定当前帧图像的人脸区域,并获取人脸区域中各像素点的位置计算得到当前帧图像的人脸区域的实际中心位置。再对预设的人像区域防抖的目标函数进行求解,以得到当前帧图像的目标人脸位置。其中,预设的人像区域防抖的目标函数是关于当前帧图像的人脸目标位置、前一帧图像的人脸目标位置、及当前帧图像的实际中心
位置的函数。前一帧图像的人脸目标位置和当前帧图像的实际中心位置均为已知数据。第一获取模块11或处理器30对预设的人像区域防抖的目标函数进行求解,即可获取得到当前帧图像的人脸目标位置。
38.请参阅图5,在某些实施方式中,011:获取当前帧图像的人脸区域的实际中心位置,包括:
39.0111:获取当前帧图像的人脸区域的多个关键点的实际位置;及
40.0113:对多个关键点的实际位置进行求平均以获取实际中心位置。
41.请结合图2,第一获取模块11还用于执行0111及0113中的方法。即,第一获取模块11还用于:获取当前帧图像的人脸区域的多个关键点的实际位置;及对多个关键点的实际位置进行求平均以获取实际中心位置。
42.请结合图3,处理器30还用于执行0111及0113中的方法。即,处理器30还用于:获取当前帧图像的人脸区域的多个关键点的实际位置;及对多个关键点的实际位置进行求平均以获取实际中心位置。
43.第一获取模块11或处理器30获取当前帧图像的实际中心位置时,利用二维人脸关键点检测算法确定当前帧图像的人脸区域的关键点。其中,人脸区域的关键点可选取人脸的鼻子、眼睛、嘴巴等位置处的一个或多个像素点作为关键点,使得根据关键点的实际位置确定的实际中心位置与当前帧图像的实际人脸区域的中心位置之间的差距较小。
44.在一个实施例中,第一获取模块11或处理器30获取的人脸区域的关键点为4个,将多个关键点分别记为li,关键点的总数记为n,其中,i的取值范围为[1,4],li的实际位置为(xi,yi),(xi,yi)的取值为第一获取模块11或处理器30获取得到的关键点li的实际位置的取值,则计算当前帧图像的人脸区域的实际中心位置时,对多个关键点的实际位置进行求平均以获取实际中心位置,实际中心位置记为c
t
,具体可通过公式(1)表示:
[0045]
公式(1):c
t
=1/n∑ili[0046]
例如,当4个关键点的实际位置分别为(0.00,1.00)、(0.00,8.00)、(6.00,4.00)、(8.00,6.00),则实际中心位置的为((0.00+0.00+6.00+8.00)/4,(1.00+8.00+4.00+6.00)/4),即,实际中心位置为(3.50,4.75)。
[0047]
请参阅图6,在某些实施方式中,人脸区域具有多个关键点,当前帧图像的人脸目标位置包括多个关键点的目标位置;013:根据预设的人像区域防抖的目标函数和实际中心位置获取当前帧图像的人脸目标位置,包括:
[0048]
0131:获取当前帧图像中每个关键点的目标位置与前一帧图像中对应的关键点的目标位置之间的差值的1范数以作为第一参数;
[0049]
0133:获取当前帧图像中每个关键点的目标位置与实际中心位置的差值的绝对值,并从多个绝对值中挑选出最大值以作为第二参数;及
[0050]
0135:将第一参数与第二参数以预设第一比例进行加权和计算,以得到第一加权和值,将使第一加权和值取最小值时,当前帧图像中所有关键点的目标位置的取值的集合,作为当前帧图像的人脸目标位置。
[0051]
请结合图2,第一获取模块11还用于执行0131、0133及0135中的方法。即,第一获取模块11还用于:获取当前帧图像中每个关键点的目标位置与前一帧图像中对应的关键点的目标位置之间的差值的1范数以作为第一参数;获取当前帧图像中每个关键点的目标位置
与实际中心位置的差值的绝对值,并从多个绝对值中挑选出最大值以作为第二参数;及将第一参数与第二参数以预设第一比例进行加权和计算,以得到第一加权和值,将使第一加权和值取最小值时,当前帧图像中所有关键点的目标位置的取值的集合,作为当前帧图像的人脸目标位置。
[0052]
请结合图3,处理器30还用于执行0131、0133及0135中的方法。即,处理器30还用于:获取当前帧图像中每个关键点的目标位置与前一帧图像中对应的关键点的目标位置之间的差值的1范数以作为第一参数;获取当前帧图像中每个关键点的目标位置与实际中心位置的差值的绝对值,并从多个绝对值中挑选出最大值以作为第二参数;及将第一参数与第二参数以预设第一比例进行加权和计算,以得到第一加权和值,将使第一加权和值取最小值时,当前帧图像中所有关键点的目标位置的取值的集合,作为当前帧图像的人脸目标位置。
[0053]
具体地,预设的人像区域防抖的目标函数与当前帧图像的实际中心位置c
t
、当前帧图像的人脸目标位置中的多个关键点以及前一帧图像的人脸目标位置的多个关键点相关,其中,当前帧图像的人脸目标位置的关键点的集合为未知数,记为h
t
,前一帧图像的人脸目标位置的关键点的集合记为h
t-1
,h
t-1
为已知量。预设的人像区域防抖的目标函数可用公式(1)表示:
[0054]
公式(1):argminh(w1||h
t-h
t-1
||+w2max(||h
t-c
t
||))
[0055]
其中,||h
t-h
t-1
||对应方法0131中的第一参数,即,第一获取模块11或处理器30获取h
t-h
t-1
的1范数。如,当前帧图像的人脸目标位置的多个关键点的集合h
t
中的多个关键点分别为l1、l2、l3、l4,前一帧图像的人脸目标位置的对应的多个关键点的集合h
t-1
中的多个关键点分别为l
1,-1
、l
2,-1
、l
3,-1
、l
4,-1
,则第一参数为|l
1-l
1,-1
|+|l
2-l
2,-1
|+|l
3-l
3,-1
|+|l
4-l
4,-1
|。max(||h
t-c
t
||)对应方法0133中的第二参数,即,第一获取模块11或处理器30计算当前帧图像(人脸区域)的多个关键点中距离(当前帧图像)的实际中心位置最远的一个关键点,分别计算每个关键点的目标位置与实际中心位置之间的差值的绝对值,并从多个绝对值中挑选出最大值以作为第二参数。如,第一个关键点与实际中心位置之间的差值的绝对值记为d1,第二个关键点与实际中心位置之间的差值的绝对值记为d2,第三个关键点与实际中心位置之间的差值的绝对值记为d3,第四个关键点与实际中心位置之间的差值的绝对值记为d4,其中,第三个关键点与实际中心位置之间的差值的绝对值为四个差值的绝对值中的最大值,则第二参数为d3。
[0056]
第一获取模块11或处理器30以预设第一比例对第一参数和第二参数进行加权和计算,预设第一比例为w1:w2,w1:w2的取值范围可包括但不限于[0,1]。其中,w1表示当前帧图像(整体)与前一帧图像(整体)之间的防抖强度,w1越大,表示当前帧图像与前一帧图像之间的差异越小,图像整体防抖效果越好;w2表示当前帧图像的人脸区域与前一帧图像的人脸区域之间的防抖强度,w2越大,表示当前帧图像的人脸区域与前一帧图像的人脸区域之间的差异越小,图像的人脸区域防抖效果越好。w1和w2的具体取值可根据实际的防抖效果需求进行设置。
[0057]
最终,第一获取模块11或处理器30利用argmin函数获取第一加权和值(w
1*
(|l
1-l1,-1
|+|l
2-l
2,-1
|+|l
3-l
3,-1
|+|l
4-l
4,-1
|)+w2*d3)取最小值时,l1、l2、l3、l4的取值,多个关键点l1、l2、l3、l4的取值的集合即为当前帧图像的人脸目标位置。
[0058]
综上,预设的人像区域防抖的目标函数可以保证前后连续两帧的目标人像位置距离较近,同时保证当前帧图像的人脸目标位置与当前帧图像的实际人脸位置差距不大,从而使得人脸区域的防抖效果过渡自然。
[0059]
请参阅图7,在某些实施方式中,当前帧图像的人脸区域具有多个关键点,当前帧图像的人脸目标位置包括多个关键点的目标位置。03:根据相机的姿态数据及当前帧图像的人脸目标位置获取当前帧图像的人脸目标位置对应的虚拟投影位置,包括:
[0060]
031:获取相机的实际姿态位置;
[0061]
033:获取相机的内参矩阵、虚拟旋转矩阵及实际旋转矩阵;
[0062]
035:根据实际姿态位置、内参矩阵、虚拟旋转矩阵及实际旋转矩阵获取单应性矩阵,单应性矩阵与相机的目标姿态位置、实际姿态位置相关;及
[0063]
037:根据多个关键点的目标位置及单应性矩阵获取多个关键点的虚拟投影位置。
[0064]
请结合图2,第二获取模块13还用于执行031、033、035及037中的方法。即,第二获取模块13还用于:获取相机的实际姿态位置;获取相机的内参矩阵、虚拟旋转矩阵及实际旋转矩阵;根据实际姿态位置、内参矩阵、虚拟旋转矩阵及实际旋转矩阵获取单应性矩阵,单应性矩阵与相机的目标姿态位置、实际姿态位置相关;及根据多个关键点的目标位置及单应性矩阵获取多个关键点的虚拟投影位置。
[0065]
请结合图3,处理器30还用于执行031、033、035及037中的方法。即,处理器30还用于:获取相机的实际姿态位置;获取相机的内参矩阵、虚拟旋转矩阵及实际旋转矩阵;根据实际姿态位置、内参矩阵、虚拟旋转矩阵及实际旋转矩阵获取单应性矩阵,单应性矩阵与相机的目标姿态位置、实际姿态位置相关;及根据多个关键点的目标位置及单应性矩阵获取多个关键点的虚拟投影位置。
[0066]
方法031和033中,第二获取模块13或处理器30根据陀螺仪输入的陀螺仪(gyroscope,gyro)数据进行计算,以获取相机的实际姿态位置,记为pr;第二获取模块13或处理器30根据gyro数据获取相机的内参矩阵、相机的虚拟旋转矩阵和相机的实际旋转矩阵,并将内参矩阵记为k,虚拟旋转矩阵记为rv,实际旋转矩阵记为rr。本技术中,终端100通过利用陀螺仪输入的gyro数据,使得第二获取模块13或处理器30可以有效处理视频画面中不同的抖动程度,使得视频处理方法可以适用于多种运动场景下的人像视频防抖。
[0067]
方法035中,第二获取模块13或处理器30将相机的目标姿态位置记为pv,结合实际姿态位置pr、内参矩阵k、虚拟旋转矩阵rv和实际旋转矩阵rr获取目标姿态位置pv与实际姿态位置pr之间的单应性矩阵q,单应性矩阵q能够反映相机的目标姿态位置和实际姿态位置之间的变换关系,便于计算当前帧图像的关键点的目标位置对应的虚拟投影位置。
[0068]
方法037中,由于当前帧图像的人脸目标位置已由第一获取模块11或处理器30获取得到,第二获取模块13或处理器30结合单应性矩阵q和关键点的目标位置获取各关键点对应的虚拟投影位置,方便后续结合人脸区域的人脸信息和图像的画面整体的姿态信息优化视频的防抖效果,保证人脸过渡自然、不产生变形的同时,实现视频防抖的效果,提升视频的防抖表现。
[0069]
请参阅图8,在某些实施方式中,035:根据实际姿态位置、内参矩阵、虚拟旋转矩阵及实际旋转矩阵获取单应性矩阵,包括:
[0070]
0351:获取内参矩阵与实际旋转矩阵的乘积的逆矩阵;及
[0071]
0353:根据虚拟旋转矩阵与逆矩阵的乘积、及实际姿态位置获取单应性矩阵。
[0072]
请结合图2,第二获取模块13还用于执行0351及0353中的方法。即,第二获取模块13还用于:获取内参矩阵与实际旋转矩阵的乘积的逆矩阵;及根据虚拟旋转矩阵与逆矩阵的乘积、及实际姿态位置获取单应性矩阵。
[0073]
请结合图3,处理器30还用于执行0351及0353中的方法。即,处理器30还用于:获取内参矩阵与实际旋转矩阵的乘积的逆矩阵;及根据虚拟旋转矩阵与逆矩阵的乘积、及实际姿态位置获取单应性矩阵。
[0074]
具体地,单应性矩阵q可采用公式(2)表示:
[0075]
公式(2):q(pv,pr)=rv*(krr)-1
[0076]
其中,单应性矩阵q表示为(pv,pr),pv为相机的目标姿态位置,pr为相机的实际姿态位置,目标姿态位置pv和实际姿态位置pr均为单应性矩阵q的列向量。rv为相机的虚拟旋转矩阵,(krr)-1
为内参矩阵k与实际旋转矩阵rr的乘积的逆矩阵。
[0077]
第二获取模块13或处理器30结合虚拟旋转矩阵rv和逆矩阵(krr)-1
的乘积rv*(krr)-1
及实际姿态位置pr获取单应性矩阵q,从而结合单应性矩阵q和预设的最优化目标函数获取目标姿态。
[0078]
若当前帧图像的人脸目标位置的包括四个关键点,四个关键点分别记为l1、l2、l3、l4,第二获取模块13或处理器30得到单应性矩阵q的表达式后,分别获取当前帧图像的人脸目标位置的多个关键点对应的虚拟投影位置,即,各关键点对应的虚拟投影位置可用公式(3)表示:
[0079]
公式(3):lv=q*l
[0080]
其中,lv表示关键点的虚拟投影位置,l表示当前帧图像的人脸目标位置的各关键点,l∈{l1,l2,l3,l4}。例如,与关键点l1对应的虚拟投影位置l
v1
=q*l1,与关键点l2对应的虚拟投影位置l
v2
=q*l2,与关键点l3对应的虚拟投影位置l
v3
=q*l3,与关键点l4对应的虚拟投影位置l
v4
=q*l4。
[0081]
请参阅图9,在某些实施方式中,视频包括前一帧图像和前两帧图像,视频处理方法还包括:
[0082]
04:根据当前帧图像的虚拟旋转姿态、前一帧图像的虚拟旋转姿态、前两帧图像的虚拟旋转姿态获取当前帧图像的旋转姿态项。
[0083]
请结合图2,视频处理装置10还包括第四获取模块14,第四获取模块14用于执行04中的方法。即,第四获取模块14用于:根据当前帧图像的虚拟旋转姿态、前一帧图像的虚拟旋转姿态、前两帧图像的虚拟旋转姿态获取当前帧图像的旋转姿态项。
[0084]
请结合图3,处理器30还用于执行04中的方法。即,处理器30还用于:根据当前帧图像的虚拟旋转姿态、前一帧图像的虚拟旋转姿态、前两帧图像的虚拟旋转姿态获取当前帧图像的旋转姿态项。
[0085]
当前帧图像的旋转姿态项与当前帧图像、前一帧图像、前两帧图像(前两帧图像为一张图像)的虚拟旋转姿态相关,综合前一帧图像和前两帧图像的虚拟旋转姿态,作为对当前帧图像的画面整体进行防抖处理的优化因素,使得当前帧图像与前面两帧图像之间的差别较小,保证视频中的画面整体过渡自然。同时,结合前一帧图像和前两帧图像(一共两帧图像)对当前帧图像的虚拟旋转姿态进行估算,有效减少第四获取模块14或处理器30的计
算量,提高运算效率。当然,也可以结合三帧或者三帧以上的图像的虚拟旋转姿态对当前帧图像的旋转姿态项进行估算,对此不作限制。
[0086]
请参阅图10,在某些实施方式中,04:根据当前帧图像的虚拟旋转姿态、前一帧图像的虚拟旋转姿态、前两帧图像的虚拟旋转姿态获取当前帧图像的旋转姿态项,包括:
[0087]
041:获取当前帧图像的虚拟旋转姿态与前一帧图像的虚拟旋转姿态的差值的2范数,以作为第一旋转系数;
[0088]
043:获取当前帧图像的虚拟旋转姿态与前一帧图像的虚拟旋转姿态的乘积、和前一帧图像的虚拟旋转姿态与前两帧图像的虚拟旋转姿态的乘积之间的差值的2范数,以作为第二旋转系数;及
[0089]
045:将第一旋转系数与第二旋转系数以预设平滑比例进行加权和计算,以获取当前帧图像的旋转姿态项。
[0090]
请结合图2,第四获取模块14还用于执行041、043、及045中的方法。即,第四获取模块14还用于:获取当前帧图像的虚拟旋转姿态与前一帧图像的虚拟旋转姿态的差值的2范数,以作为第一旋转系数;获取当前帧图像的虚拟旋转姿态与前一帧图像的虚拟旋转姿态的乘积、和前一帧图像的虚拟旋转姿态与前两帧图像的虚拟旋转姿态的乘积之间的差值的2范数,以作为第二旋转系数;及将第一旋转系数与第二旋转系数以预设平滑比例进行加权和计算,以获取当前帧图像的旋转姿态项。
[0091]
请结合图3,处理器30还用于执行041、043、及045中的方法。即,处理器30还用于:获取当前帧图像的虚拟旋转姿态与前一帧图像的虚拟旋转姿态的差值的2范数,以作为第一旋转系数;获取当前帧图像的虚拟旋转姿态与前一帧图像的虚拟旋转姿态的乘积、和前一帧图像的虚拟旋转姿态与前两帧图像的虚拟旋转姿态的乘积之间的差值的2范数,以作为第二旋转系数;及将第一旋转系数与第二旋转系数以预设平滑比例进行加权和计算,以获取当前帧图像的旋转姿态项。
[0092]
在本技术的实施例中,第四获取模块14或处理器30结合两帧图像(前一帧图像和前两帧图像)与当前帧图像获取当前帧图像的旋转姿态项。具体地,将当前帧图像的虚拟旋转姿态记为rv,前一帧图像的虚拟旋转姿态记为r
v,-1
,前两帧图像的虚拟旋转姿态记为r
v,-2
,当前帧图像的旋转姿态项记为er(rv)。
[0093]
第四获取模块14或处理器30获取得到当前帧图像的虚拟旋转姿态rv、前一帧图像的虚拟旋转姿态r
v,-1
以及前两帧图像的虚拟旋转姿态r
v,-2
后,获取当前帧图像的虚拟旋转姿态rv与前一帧图像的虚拟旋转姿态r
v,-1
之间的差值的2范数,作为第一旋转系数。第四获取模块14或处理器30获取当前帧图像的虚拟旋转姿态rv与前一帧图像的虚拟旋转姿态r
v,-1
的乘积r
vrv,-1
,获取前一帧图像的虚拟旋转姿态r
v,-1
与前两帧图像的虚拟旋转姿态r
v,-2
的乘积r
v,-1rv,-2
,将两个乘积r
vrv,-1
与乘积r
v,-1rv,-2
之间的差值的2范数作为第二旋转系数。最后,第四获取模块14或处理器30再将第一旋转系数和第二旋转系数以预设平滑比例进行加权和计算,以获取当前帧图像的旋转姿态项er(rv)。当前帧图像的旋转姿态项er(rv)可用公式(4)表示:
[0094]
公式(4):er(rv)=c0||r
v-r
v,-1
||2+c1||r
vrv,-1-r
v,-1rv,-2
||2[0095]
其中,c0和c1为预设平滑系数,c0/c1为预设平滑比例。||r
v-r
v,-1
||2为第一旋转系数,||r
vrv,-1-r
v,-1rv,-2
||2为第二旋转系数。当前帧图像的虚拟旋转姿态rv、前一帧图像的虚
拟旋转姿态r
v,-1
和前两帧图像的虚拟旋转姿态r
v,-2
均为已知量,计算得到的第一旋转系数和第二旋转系数为具体的数值。
[0096]
请参阅图9,在某些实施方式中,视频处理方法还可包括:
[0097]
05:根据当前帧图像的虚拟平移姿态、前一帧图像的虚拟平移姿态、前两帧图像的虚拟平移姿态获取当前帧图像的平移姿态项。
[0098]
请结合图2,视频处理装置10还可包括第五获取模块16,第五获取模块16用于执行05中的方法。即,第五获取模块16用于:根据当前帧图像的虚拟平移姿态、前一帧图像的虚拟平移姿态、前两帧图像的虚拟平移姿态获取当前帧图像的平移姿态项。
[0099]
请结合图3,处理器30还用于执行05中的方法。即,处理器30还用于:根据当前帧图像的虚拟平移姿态、前一帧图像的虚拟平移姿态、前两帧图像的虚拟平移姿态获取当前帧图像的平移姿态项。
[0100]
当前帧图像的平移姿态项与当前帧图像、前一帧图像、前两帧图像的虚拟平移量相关,综合前一帧图像和前两帧图像的虚拟平移量,作为对当前帧图像的画面整体进行防抖处理的优化因素,使得当前帧图像与前面两帧图像之间的差别较小,使得当前帧图像的画面整体过渡自然。同时,结合前一帧图像和前两帧图像对当前帧图像的虚拟平移量进行估算,有效减少第五获取模块16或处理器30的计算量,提高运算效率。当然,也可以结合三帧或者三帧以上的图像的虚拟平移量对当前帧图像的平移姿态项进行估算,对此不作限制。
[0101]
请参阅图11,在某些实施方式中,05:根据当前帧图像的虚拟平移姿态、前一帧图像的虚拟平移姿态、前两帧图像的虚拟平移姿态获取当前帧图像的平移姿态项,包括:
[0102]
051:获取当前帧图像的虚拟平移量与前一帧图像的虚拟平移量的差值的2范数,以作为第一平移系数;
[0103]
053:获取前一帧图像的虚拟平移量与当前帧图像的虚拟平移量的差值、前一帧图像的虚拟平移量与前两帧图像的虚拟平移量的差值之间的和值的2范数,以作为第二平移系数;及
[0104]
055:将第一平移系数与第二平移系数以预设平滑比例进行加权和计算,以获取当前帧图像的平移姿态项。
[0105]
请结合图2,第五获取模块16还用于执行051、053及055中的方法。即,第五获取模块16还用于:获取当前帧图像的虚拟平移量与前一帧图像的虚拟平移量的差值的2范数,以作为第一平移系数;获取前一帧图像的虚拟平移量与当前帧图像的虚拟平移量的差值、前一帧图像的虚拟平移量与前两帧图像的虚拟平移量的差值之间的和值的2范数,以作为第二平移系数;及将第一平移系数与第二平移系数以预设平滑比例进行加权和计算,以获取当前帧图像的平移姿态项。
[0106]
请结合图3,处理器30还用于执行051、053及055中的方法。即,处理器30还用于:获取当前帧图像的虚拟平移量与前一帧图像的虚拟平移量的差值的2范数,以作为第一平移系数;获取前一帧图像的虚拟平移量与当前帧图像的虚拟平移量的差值、前一帧图像的虚拟平移量与前两帧图像的虚拟平移量的差值之间的和值的2范数,以作为第二平移系数;及将第一平移系数与第二平移系数以预设平滑比例进行加权和计算,以获取当前帧图像的平移姿态项。
[0107]
在本技术的实施例中,第五获取模块16或处理器30结合两帧图像(前一帧图像和前两帧图像)与当前帧图像获取当前帧图像的平移姿态项。具体地,将当前帧图像的虚拟平移量记为t,前一帧图像的虚拟平移量记为t-1
,前两帧图像的虚拟平移量记为t-2
,当前帧图像的平移姿态项记为e
t
(t)。
[0108]
第五获取模块16或处理器30获取得到当前帧图像的虚拟平移量t、前一帧图像的虚拟平移量t-1
、前两帧图像的虚拟平移量t-2
后,获取当前帧图像的虚拟平移量t与前一帧图像的虚拟平移量t-1
之间的差值的2范数,作为第一平移系数。第五获取模块16或处理器30获取前一帧图像的虚拟平移量t-1
与当前帧图像的虚拟平移量t之间的差值t-1-t、获取前一帧图像的虚拟平移量t-1
与前两帧图像的虚拟平移量t-2
之间的差值t-1-t-2
,再去两个差值之间的和值的2范数,作为第二平移系数,即,第二平移系数为(t-1-t)+(t-1-t-2
)的2范数。最后,第五获取模块16或处理器30再将第一平移系数和第二平移系数以预设平滑系数进行加权和计算,以获取当前帧图像的平移姿态项e
t
(t)。当前帧图像的平移姿态项e
t
(t)可用公式(5)表示:
[0109]
公式(5):e
t
(t)=c0||t-t-1
||2+c1||2t-1-(t+t-2
)||2[0110]
其中,c0和c1为预设平滑系数,c0/c1为预设平滑比例,与当前帧图像的旋转姿态项的预设平滑系数相同。||t-t-1
||2为第一平移系数,||2t-1-(t+t-2
)||2为第二平移系数。当前帧图像的虚拟平移量记为t、前一帧图像的虚拟平移量记为t-1
、前两帧图像的虚拟平移量记为t-2
均为已知量,计算得到的第一平移系数和第二平移系数为具体的数值。
[0111]
请参阅图12,在某些实施方式中,07:根据当前帧图像的人脸目标位置、虚拟投影位置、当前帧图像的旋转姿态项及当前帧图像的平移姿态项获取当前帧图像的目标姿态,包括:
[0112]
071:获取当前帧图像的人脸目标位置的目标中心位置;
[0113]
073:获取每个虚拟投影位置与目标中心位置的差值的2范数以作为当前帧图像的人脸数据项,人脸数据项与当前帧图像的目标姿态相关;及
[0114]
075:根据预设的最优化目标函数和旋转姿态项、平移姿态项获取当前帧图像的目标姿态,最优化目标函数是关于目标中心位置、旋转姿态项及平移姿态项的函数。
[0115]
请结合图2,第三获取模块15还用于执行071、073及075中的方法。即,第三获取模块15还用于:获取当前帧图像的人脸目标位置的目标中心位置;获取每个虚拟投影位置与目标中心位置的差值的2范数以作为当前帧图像的人脸数据项,人脸数据项与当前帧图像的目标姿态相关;及根据预设的最优化目标函数和旋转姿态项、平移姿态项获取当前帧图像的目标姿态,最优化目标函数是关于目标中心位置、旋转姿态项及平移姿态项的函数。
[0116]
请结合图3,处理器30还用于执行071、073及075中的方法。即,处理器30还用于:获取当前帧图像的人脸目标位置的目标中心位置;获取每个虚拟投影位置与目标中心位置的差值的2范数以作为当前帧图像的人脸数据项,人脸数据项与当前帧图像的目标姿态相关;及根据预设的最优化目标函数和旋转姿态项、平移姿态项获取当前帧图像的目标姿态,最优化目标函数是关于目标中心位置、旋转姿态项及平移姿态项的函数。
[0117]
对于方法071,方法013中已根据预设的人像区域防抖的目标函数计算得到当前帧图像的人脸目标位置,第三获取模块15或处理器30可根据当前帧图像的人脸目标位置获取得到当前帧图像的目标中心位置。当前帧图像的目标中心位置可记为c2。
[0118]
对于方法073,将当前帧图像的人脸数据项记为ef(pv),方法037中已根据人脸区域的多个关键点的目标位置及单应性矩阵获取得到多个关键点的虚拟投影位置lv,第三获取模块15或处理器30可根据每个关键点的虚拟投影位置lv与目标中心位置c2之间的差值的2范数,获取当前帧图像的人脸数据项ef(pv)。当前帧图像的人脸数据项ef(pv)可用公式(6)表示:
[0119]
公式(6):ef(pv)=∑i||l
vi-c2||2[0120]
其中,i的取值范围为[0,n],i为整数,n为当前帧图像的人脸区域的关键点的总数。
[0121]
第三获取模块15或处理器30结合当前帧图像的人脸数据项、当前帧图像的旋转姿态项、当前帧图像的平移姿态项设计最优化目标函数,并对最优化目标函数进行求解,即可获取得到当前帧图像的目标姿态。
[0122]
请参阅图13,在某些实施方式中,071:获取当前帧图像的目标中心位置,包括:
[0123]
0711:获取当前帧图像的人脸目标位置的多个关键点的目标位置;及
[0124]
0713:对多个关键点的目标位置进行求平均以获取目标中心位置。
[0125]
请结合图2,第三获取模块15还用于执行0711及0713中的方法。即,第三获取模块15还用于:获取当前帧图像的人脸目标位置的多个关键点的目标位置;及对多个关键点的目标位置进行求平均以获取目标中心位置。
[0126]
请结合图3,处理器30还用于执行0711及0713中的方法。即,处理器30还用于:获取当前帧图像的人脸目标位置的多个关键点的目标位置;及对多个关键点的目标位置进行求平均以获取目标中心位置。
[0127]
具体地,第三获取模块15或处理器30获取当前帧图像的目标中心位置时,可结合当前帧图像的目标中心位置的多个关键点的目标位置进行求平均计算,以获取当前帧图像的目标中心位置。
[0128]
请参阅图14,在某些实施方式中,075:根据预设的最优化目标函数和旋转姿态项、平移姿态项获取当前帧图像的目标姿态,包括:
[0129]
0751:将人脸数据项、旋转姿态项与平移姿态项以预设第二比例进行加权和计算,以得到第二加权和值,将使第二加权和值取最小值时,人脸数据项的取值;及
[0130]
0753:根据人脸数据项的取值获取当前帧图像的目标姿态。
[0131]
请结合图2,第三获取模块15还用于执行0751及0753中的方法。即,第三获取模块15还用于:将人脸数据项、旋转姿态项与平移姿态项以预设第二比例进行加权和计算,以得到第二加权和值,将使第二加权和值取最小值时,人脸数据项的取值;及根据人脸数据项的取值获取当前帧图像的目标姿态。
[0132]
请结合图3,处理器30还用于执行0751及0753中的方法。即,处理器30还用于:将人脸数据项、旋转姿态项与平移姿态项以预设第二比例进行加权和计算,以得到第二加权和值,将使第二加权和值取最小值时,人脸数据项的取值;及根据人脸数据项的取值获取当前帧图像的目标姿态。
[0133]
具体地,预设的最优化目标函数用公式(7)表示:
[0134]
公式(7):argmin(wf*ef(pv)+wr*er(rv)+w
t
*e
t
(t))
[0135]
其中,预设第二比例为wf:wr:w
t
,wf:wr:w
t
的取值范围可包括但不限于[0,1]。其中,
wf的取值越大,则说明人脸数据项的防抖强度越大,则最终获得的当前帧图像的目标姿态pv与前一帧图像的目标姿态之间的差异越小,图像的画面整体过渡更加自然。wr的取值越大,则说明当前帧图像的旋转姿态项与前一帧图像的旋转姿态项之间的差异越小。w
t
的取值越大,则说明当前帧图像的平移姿态项与前一帧图像的平移姿态项之间的差异越小。wf、w
t
、wr的具体取值可根据实际的防抖效果需求进行设置。
[0136]
最终,第三获取模块15或处理器30利用argmim函数获取第二加权和值(wf*ef(pv)+wr*er(rv)+w
t
*e
t
(t))取得最小值时,人脸数据项的取值。由于人脸数据项与当前帧图像的目标姿态pv相关,根据人脸数据项的取值可计算得到当前帧图像的目标姿态的取值。
[0137]
综上,渲染模块17或处理器30获得当前帧图像的人脸目标位置和当前帧图像的目标姿态后,对当前帧图像进行重新渲染,从而生成具有人像防抖效果的目标图像。
[0138]
请参阅图15,本技术还提供一种包含计算机程序201的非易失性计算机可读存储介质200。当计算机程序201被一个或多个处理器30执行时,使得处理器30实现01、03、07、09、011、013、0111、0113、0131、0133、0135、031、033、035、037、0351、0353、04、041、043、045、05、051、053、055、071、073、075、0711、0713、0751、及0753中的方法。
[0139]
在本说明书的描述中,参考术语“某些实施方式”、“一个例子中”、“示例地”等的描述意指结合所述实施方式或示例描述的具体特征、结构、材料或者特点包含于本技术的至少一个实施方式或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施方式或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施方式或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0140]
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本技术的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本技术的实施例所属技术领域的技术人员所理解。
[0141]
尽管上面已经示出和描述了本技术的实施方式,可以理解的是,上述实施方式是示例性的,不能理解为对本技术的限制,本领域的普通技术人员在本技术的范围内可以对上述实施方式进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1