基于特征加权支持向量回归的股指预测方法、装置及介质与流程
1.本发明涉及一种数据预测技术,尤其是涉及一种基于特征加权支持向量回归的股指预测方法、装置及介质。
背景技术:
2.关于股指时间序列的预测问题一直是目前的难题,造成这种现状,本质上是因为股票市场是一个非线性的动态系统,加之受诸如政策、心理等不确定因素的影响,使得相关研究存在精度不高、鲁棒性不强的缺陷。
3.传统的时间序列arima、garch模型通常适用于处理低维度时间序列数据,且预测精度不高,无法对复杂特征影响下的多维非线性时间序列数据进行准确预测。相比而言,机器学习中的支持向量机在处理这类复杂数据时更加行之有效。然而,业内多数研究采用支持向量机时仅等权处理每个特征,但是其中的核函数却是对特征高度敏感的,导致最终的预测结构的精确性和鲁棒性不高。
技术实现要素:
4.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于特征加权支持向量回归的股指预测方法、装置及介质,精度高,鲁棒性高,自动化,节约人力资源。
5.本发明的目的可以通过以下技术方案来实现:
6.一种基于特征加权支持向量回归的股指预测方法,包括:
7.利用训练好的支持向量机模型对股票指数进行动态预测;
8.所述的支持向量机模型的训练过程包括以下步骤:
9.1)采集某一交易日的股票指数以及该交易日前的若干个交易日的技术指标数据集,构成训练集,所述的技术指标数据集包括若干项技术指标数据;
10.2)对训练集进行归一化处理;
11.3)通过因子模型筛选算法从若干项技术指标数据中筛选出若干项参考技术指标数据,并构建表征各项参考技术指标数据的权重的特征权重矩阵;
12.4)利用特征权重矩阵对支持向量机模型的核函数映射过程进行加权。
13.进一步地,通过滑动窗口截取训练集,动态训练支持向量机模型。
14.进一步地,所述的因子模型筛选步骤包括:
15.对每项参考技术指标数据进行数据分箱操作,计算每个分箱的iv值,将各分箱的iv值相加,得到该项参考技术指标数据的iv值总和;
16.根据iv值总和由小到大的顺序对若干项参考技术指标数据进行排序,选择iv值总和最大的n项参考技术指标数据,作为参考技术指标数据,并构特征权重矩阵p。
17.进一步地,所述的特征权重矩阵的表达式为:
[0018][0019]
其中,iv(x1)是特征x1的iv值总和,iv(xn)是特征xn的iv值总和。
[0020]
进一步地,所述的核函数采用高斯核函数,表达式为:
[0021][0022]
其中,k(xi,xj)为样本xi与xj在特征空间中的内积,σ为高斯核的带宽。
[0023]
进一步地,对核函数映射过程进行加权后获得的加权高斯核函数表达式为:
[0024][0025]
其中,p为特征权重矩阵。
[0026]
进一步地,所述的归一化处理过程包括:
[0027]
采用z-score均值归一化处理。
[0028]
进一步地,所述的技术指标数据集包括ema、macd、kdj、boll、rsi、dpo、cci和bbi中的一种或多种。
[0029]
一种股指预测装置,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器调用所述程序指令能够执行所述的股指预测方法。
[0030]
一种计算机可读存储介质,包括计算机程序,所述计算机程序能够被处理器执行以实现所述的股指预测方法。
[0031]
与现有技术相比,本发明具有以如下有益效果:
[0032]
(1)本发明获取技术指标数据集并对其进行处理,计算各项技术指标iv值,根据iv值筛选技术指标,并进行重要性排序并构建权重矩阵,对svr核函数映射过程进行特征加权,再利用svr核函数预测股指数据,自动筛选特征,并有着较强的泛化能力,鲁棒性高,大大提高了股指预测精度,保证了人工做出经济决策的效率;
[0033]
(2)本发明通过滑动窗口截取训练集,动态训练支持向量机模型,根据滚动的数据构建一个实时的信息反馈机制,实现了对海量经济数据的自动挖掘,节约了大量的人力资源。
附图说明
[0034]
图1为本发明的方法流程图。
具体实施方式
[0035]
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
[0036]
实施例1
[0037]
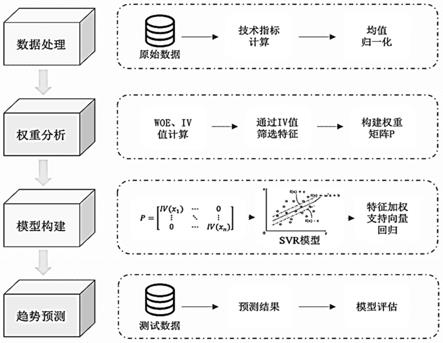
一种基于特征加权支持向量回归的股指预测方法,如图1,包括:
[0038]
1)数据处理:
[0039]
首先从数据库获取股票每日的k线数据,选择最常用的8大技术指标,如表1所示:
[0040]
表1技术指标
[0041]
[0042][0043]
根据上述公式,计算股指前20个交易日的八大技术指标数据,并与股指下一日的收盘价一同构建训练数据,得到原始数据后,由于各数据量纲不一致,因而对其进行均值归一化处理,从而提高最终预测精度;
[0044]
2)权重分析:
[0045]
通常特征筛选都是依据人为经验积累而做的判别,而股市每段时间的数据都极具特色,并且各个特征的有效周期可能会发生变化,特征的有效性也不是一成不变的,因而,首先需要对特征因子进行统计学方法筛选;
[0046]
对因子进行iv值计算,iv是一种主流的因子模型筛选方法,它不仅可以保障因子筛选的质量,还能减轻计算机运行负荷;
[0047]
首先对每个指标进行数据分箱操作,计算每个分箱的woe以及iv值,最终将各分箱iv值相加,得到该因子iv值总和,完成上述步骤后,将所有因子通过iv值由小到大排序,按
需选择iv值最大的n个因子,并构建特征权重矩阵p,特征权重矩阵p采用对角阵的形式,表达式为:
[0048][0049]
其中,iv(x1)是特征x1的iv值总和,iv(xn)是特征xn的iv值总和;
[0050]
3)模型构建:
[0051]
在svr算法的基础上,对核函数映射过程进行动态加权,特征通过iv值的计算来获取不同权值,不仅保留了原svr算法的处理非线性数据的能力,同时对核函数的映射过程做了优化,使得最终模型预测更加精确;
[0052]
4)趋势预测:
[0053]
采用滑动窗口预测模型,利用前20个交易日的数据对下一交易日的收盘价进行预测,动态训练,动态测试,依照最新数据实时更新模型,提高最终模型准确性。
[0054]
本实施例提出的股指预测方法用到了以下三种技术:
[0055]
(1)特征重要性分析
[0056]
在数据处理时,通常需要对特征变量进行筛选,选择变量时,往往要考虑很多因素,如预测能力,可解释性等,本实施例利用iv(information value)值来衡量特征重要性,在进行特征筛选时,iv值可以较好的反映特征的预测能力,通常iv值越大,特征对预测结果的贡献就越大;
[0057]
(2)支持向量回归模型
[0058]
支持向量机(svm)是一种高效的机器学习算法,近年来,它在许多工程领域都是一种非常受欢迎的算法,比如模式识别、图像识别、文本分类和生物医学工程等领域。其中,svr支持向量回归是svm在回归问题中的应用,它是建立在基础统计学习理论和结构风险最小化原则的基础上的应用算法,svr属于机器学习的范畴,区别于传统的统计学模型。该方法在本研究中可以较好的解决股指预测问题,有着较高的精度,同时它的泛化能力也很强。
[0059]
(3)核函数特征加权
[0060]
核函数目的是解决多维数据在低维度空间中不可分问题,映射到高维空间中,原始数据便处于线性可分状态,svr采用了核函数技巧,正是这种方法,使得有的难度很大的预测问题得以解决,不仅增加了精度,也提高了泛化能力。
[0061]
本实施例的核函数采用高斯核函数,表达式为:
[0062][0063]
其中,k(xi,xj)为样本xi与xj在特征空间中的内积,σ为高斯核的带宽。
[0064]
对核函数映射过程进行加权后获得的加权高斯核函数表达式为:
[0065][0066]
实施例2
[0067]
一种股指预测装置,包括存储器和处理器,所述存储器存储有计算机程序,所述处
理器调用所述程序指令能够执行实施例1所述的股指预测方法。
[0068]
实施例3
[0069]
一种计算机可读存储介质,包括计算机程序,所述计算机程序能够被处理器执行以实现实施例1所述的股指预测方法。
[0070]
实施例1、实施例2和实施例3提出了一种基于特征加权支持向量回归的股指预测方法、装置及介质,通过获取的每日k线数据,计算相应技术指标数据,并对其进行处理,计算各个技术指标iv值,并构建权重矩阵,对svr核函数映射过程进行特征加权,通过不断更新的模型来预测下一日收盘价数据,实时更新模型,自动筛选特征,并有着较强的泛化能力,大大提高了股指预测精度,同时也保证了人工做出经济决策的效率,实现了对海量经济数据的自动挖掘,设计了一套完整的预测模型,节约了大量的人力资源。
[0071]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1