一种基于改进YOLOv5网络的带钢表面缺陷检测方法
一种基于改进yolov5网络的带钢表面缺陷检测方法
技术领域
1.本发明属于工业缺陷检测技术领域,具体涉及一种基于空间通道注意力模 块的yolov5网络的带钢表面缺陷检测方法。
背景技术:
2.带钢是钢铁的重要原材料之一,广泛应用于机械制造、航空航天和交通运 输中,在各类生产生活中占有重要地位,但是带钢的生产过程中,由于工业技 术的限制和生产工艺的影响,可能造成带钢表面存在表面油斑、杏仁状缺陷、 白点和划痕等多种缺陷。这些缺陷在很大程度上会影响带钢的抗腐蚀性和使用 寿命。现有的缺陷检测手段使用人工裸眼检测为主,工人检测效率低,劳动强 度大,生产成本高,已经不能满足带钢表面缺陷检测的需求。
3.深度学习通过卷积神经网络进行缺陷特征的自动提取并进行学习,无需进 行人工特征因子设计,因此深度神经网络具有学习能力强和鲁棒性高的特点, 已逐渐成为带钢表面缺陷检测的主流方法。翁玉尚等人(翁玉尚,肖金球,夏禹. 改进mask r-cnn算法的带钢表面缺陷检测[j/ol].计算机工程与应 用:1-12[2021-06-24].)提出改进的掩码区域卷积神经网络(mask r-cnn)算法, 使用k-means ii聚类算法改进区域建议网络(rpn)锚框生成方法。李维刚等 人(李维刚,叶欣,赵云涛,王文波.基于改进yolov3算法的带钢表面缺陷检测[j]. 电子学报,2020)提出了一种融合浅层特征与深层特征的的yolov3算法框架, 改进后的yolov3算法在东北大学带钢数据集上平均精度均值达到了80%。但 是,面对微弱微小的带钢缺陷时,由于背景和前景耦合程度强、缺陷区域小, 深度学习模型不能很好的提取特征,导致模型检测效果较差。
技术实现要素:
[0004]
针对现有技术的不足,本发明拟解决的技术问题是,提供一种基于改进 yolov5网络的带钢表面缺陷检测方法,能对常见不同类型的带钢表面缺陷进 行实时检测并进行缺陷定位,提高不同种类以及相似结构缺陷识别的准确率, 能满足实际带钢工业生产的实时性和准确性要求。
[0005]
本发明解决上述技术问题采用的技术方案是:设计一种基于改进yolov5 网络的带钢表面缺陷检测方法,其特征在于,该方法包括以下步骤:
[0006]
第一步:图像数据集获取
[0007]
1.1利用工业相机采集带钢表面图像,筛选出包含缺陷的图片;当筛选出 的缺陷图像中的缺陷类型涵盖已知的带钢表面缺陷的类型时,形成缺陷图片集;
[0008]
1.2将缺陷图片集进行尺寸归一化操作,然后使用labelimg软件对缺陷图 片集中的图片进行手动标注,使每一张缺陷图片上具有缺陷种类和缺陷位置坐 标的标签;
[0009]
1.3随机将完成标注的缺陷图片集的不少于60%部分划分为训练集,余下 部分为验证集;
[0010]
第二步:构造改进yolov5网络模型
[0011]
改进yolov5网络模型为在yolov5网络模型的基础上,在pan的三个 csp23_模块与网络模型的分类与定位部分的三个conv模块之间均串连接入一 个csa模块;
[0012]
csa模块包括一个通道注意力模块和一个空间注意力模块,两个模块串 联,通道注意力模块的输出为空间注意力模块的输入;
[0013]
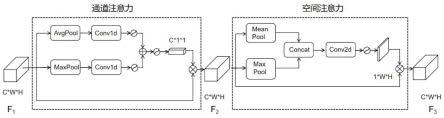
csp23_模块输出的特征图f1输入到csa模块中,首先经过通道注意力模 块处理,通道注意力模块首先将输入的特征f1分别经过基于深度和宽度的全局 最大池化和全局平均池化,得到两个1
×1×
c的特征图;接着,将得到的两个 1
×1×
c的特征图分别经过一个卷积核大小为k的快速一维卷积处理,然后将 两个快速一维卷积得到的结果相加后再经过激活函数sigmoid处理,得到通道 注意力;将通道注意力乘以原始特征f1进行特征的重新加权,得到加权后的特 征f2;
[0014]
通道注意力模块输出的特征f2输入到空间注意力模块,空间注意力模块对 特征f2分别进行全局最大池化和全局平均池化处理,得到两个h
×w×
1的特 征图;然后将这两个h
×w×
1的特征图基于通道做通道拼接操作,然后将拼 接操作得到的结果经过一个卷积核为7
×
7大小的卷积操作,降维为一个一维向 量,即h
×w×
1,再经过激活函数sigmoid生成空间注意力权重;最后将空间 注意力权重与输入特征f2相乘,得到空间注意力模块的输出特征f3;特征f3即为csa模块的输出,也为网络模型的分类与定位部分的conv模块的输入;
[0015]
第三步:训练改进yolov5网络模型
[0016]
3.1图像数据集预处理
[0017]
将训练集采用mosaic数据增强的方式进行预处理;
[0018]
3.2参数设置
[0019]
初始化所有权重值、偏置值、批量归一化尺度因子值,设置网络的初始学 习率、batch_size,并将初始化的参数数据输入网络中;根据训练损失的变化来 动态调整学习率与迭代次数,以更新整个网络的参数;训练分为两个阶段,第 一阶段是训练开始的前100个周期,初始学习率固定为0.001,以加快收敛;第 二阶段是指100个周期之后的训练周期,初始学习率设置为0.0001;
[0020]
3.3网络模型训练
[0021]
将经过预处理的训练集输入到第二步中的初始化参数设定好后的改进 yolov5网络模型中进行特征提取,利用k-means聚类方法对训练集图像自动生 成锚框,以锚框的尺寸作为先验框,通过边框回归预测得到边界框;然后使用 logistic分类器对边界框进行分类,获得每个边界框对应的缺陷类别分类概率; 再通过非极大值抑制法对所有边界框的缺陷类别分类概率进行排序,确定每个 边界框对应的缺陷类别,得到预测值;预测值包括缺陷类别和缺陷位置信息, 非极大抑制阈值为0.5;然后通过损失函数giou计算预测值和真实值之间的loss 值;根据训练损失值进行反向传播,更新骨干网络和分类回归网络的参数,直 至loss值符合预设,网络模型参数的训练完成;
[0022]
3.4网络模型测试
[0023]
将验证集输入到步骤3.3中完成参数训练的网络模型中,得到验证集的张 量预测值;将其张量预测值与标注信息对比,测试该网络模型的可靠性;采用 ap对网络模型进行评价,当ap不小于85%时,则该网络模型测试为可靠;
[0024]
第四步:带钢表面缺陷检测
[0025]
将待检测的带钢表面图像经过如第一步的步骤1.2中相同的尺寸归一化操 作,然后输入到第三步中测试为可靠的网络模型中,得到待检测的带钢表面图 像的缺陷张量信息,包括缺陷位置、缺陷类别和置信度。
[0026]
与现有技术相比,本发明的有益效果是:本发明检测方法以yolov5网络 模型为基础,加入了自行设计的通道空间注意力模块;通道空间注意力模块通 过先将浅层特征与深层特征融合在一起再进行注意力运算,这样由于深层包含 有更多的高级语义信息与更少的背景信息,浅层特征与深层特征融合之后的目 标信息得到强化,在做注意力运算时可以让网络更多的关注目标缺陷,抑制背 景信息,从而可以更好地引导多尺度融合,提高检测精度,解决了在复杂场景 及背景下的特征提取难题。本发明检测方法充分发挥了深度学习方法提取特征 的优势,能够不依赖人工的特征工程,从大量数据集中先学习简单的浅层特征, 再逐渐学习到更为复杂抽象的深层特征,性能更好,缺陷种类识别精度更高, 且锂电池的缺陷的精确率、召回率高,识别速度快。
附图说明
[0027]
图1为本发明检测方法一种实施例的csa模块的结构与原理示意图。
[0028]
图2为本发明检测方法一种实施例的改进yolov5网络模型的结构与原理 示意图。
具体实施方式
[0029]
下面将结合附图对本技术的技术方案进行清楚、完整地描述,显然,所描 述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中 的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其 他实施例,都属于本技术保护的范围。
[0030]
本发明提供一种基于改进yolov5网络的带钢表面缺陷检测方法(简称检 测方法,参见图1-2),该检测方法包括以下步骤:
[0031]
第一步:图像数据集获取
[0032]
1.1利用工业相机采集带钢表面图像,筛选出包含缺陷的图片;当筛选出 的缺陷图像中的缺陷类型涵盖已知的带钢表面缺陷的类型时,形成缺陷图片集;
[0033]
1.2将缺陷图片集进行尺寸归一化操作(本实施例为缩放至608*608像素), 然后使用labelimg软件对缺陷图片集中的图片进行手动标注,使每一张缺陷图 片上具有缺陷种类和缺陷位置坐标的标签;
[0034]
1.3随机将完成标注的缺陷图片集的不少于60%部分划分为训练集,余下 部分为验证集;本实施为4:1,即训练集为80%,余下20%为验证集。
[0035]
第二步:构造改进yolov5网络模型
[0036]
改进yolov5网络模型为在yolov5网络模型的基础上,在pan(像素 聚合网络)的三个csp23_(跨阶段局部网络,分别为csp23_5、csp23_4、 csp23_3)模块与网络模型的分类与定位部分的三个conv(卷积)模块之间均 串连接入一个csa(通道空间注意力)模块。
[0037]
csa模块包括一个通道注意力(channelattention)模块和一个空间注意力 (spatialattention)模块,两个模块串联,通道注意力模块的输出为空间注意 力模块的输
入。
[0038]
csp23_模块输出的特征图f1(c
×w×
h)输入到csa模块中,首先经过 通道注意力模块处理,通道注意力模块首先将输入的特征f1(c
×w×
h)分别 经过基于深度和宽度的全局最大池化(maxpool)和全局平均池化(avgpool), 得到两个c
×1×
1的特征图。接着,将得到的两个c
×1×
1的特征图分别经过 一个卷积核大小为k的快速一维卷积(conv1d)处理,然后将两个快速一维卷 积得到的结果相加后再经过激活函数sigmoid处理,得到通道注意力;将通道 注意力乘以原始特征f1进行特征的重新加权,得到加权后的特征f2。
[0039]
快速一维卷积的卷积核大小k代表本地跨通道交互的覆盖范围,即有多少 个相近邻参与一维通道的注意力预测。其中交互作用的覆盖范围(即内核大小k)与通道维成比例,具体计算公式为:
[0040][0041]
其中,c表示特征通道数量,β=2和b=1表示两个超参数。
[0042]
通道注意力模块输出的特征f2输入到空间注意力模块,空间注意力模块对 特征f2分别进行全局最大池化(max pool)和全局平均池化(mean pool)处 理,得到两个1
×w×
h的特征图;然后将这两个1
×w×
h的特征图基于通道 做通道拼接(concat)操作,然后将拼接操作得到的结果经过一个卷积核为7
ꢀ×
7大小的卷积操作,降维为一个一维向量,即1
×w×
h,再经过激活函数 sigmoid生成空间注意力权重。最后将空间注意力权重与输入特征f2相乘,得 到空间注意力模块的输出特征f3。特征f3即为csa模块的输出,也为网络模 型的分类与定位部分的conv模块的输入。
[0043]
第三步:训练改进yolov5网络模型
[0044]
3.1图像数据集预处理
[0045]
将训练集采用mosaic数据增强的方式进行预处理;
[0046]
3.2参数设置
[0047]
初始化所有权重值、偏置值、批量归一化尺度因子值,设置网络的初始学 习率、batch_size,并将初始化的参数数据输入网络中;根据训练损失的变化来 动态调整学习率与迭代次数,以更新整个网络的参数;训练分为两个阶段,第 一阶段是训练开始的前100个周期,初始学习率固定为0.001,以加快收敛;第 二阶段是指100个周期之后的训练周期,初始学习率设置为0.0001。
[0048]
3.3网络模型训练
[0049]
将经过预处理的训练集输入到第二步中的初始化参数设定好后的改进 yolov5网络模型中进行特征提取,利用k-means聚类方法对训练集图像自动生 成锚框,以锚框的尺寸(锚框尺寸会根据图像缩放尺寸等比缩放)作为先验框, 通过边框回归预测得到边界框;然后使用logistic分类器对边界框进行分类,获 得每个边界框对应的缺陷类别分类概率;再通过非极大值抑制法(nms)对所 有边界框的缺陷类别分类概率进行排序,确定每个边界框对应的缺陷类别,得 到预测值;预测值包括缺陷类别和缺陷位置信息,非极大抑制阈值为0.5;然后 通过损失函数giou计算预测值和真实值之间的loss值;根据训练损失值进行反 向传播,更新骨干网络和分类回归网络的参数,直至loss值符合预设,网络模 型参数的训练完成;
[0050]
3.4网络模型测试
[0051]
将验证集输入到步骤3.3中完成参数训练的网络模型中,得到验证集的张 量预测值;将其张量预测值与标注信息对比,测试该网络模型的可靠性;采用 ap对网络模型进行评价,当ap不小于85%时,则该网络模型测试为可靠。
[0052]
第四步:带钢表面缺陷检测
[0053]
将待检测的带钢表面图像经过如第一步的步骤1.2中相同的尺寸归一化操 作,然后输入到第三步中测试为可靠的网络模型中,得到待检测的带钢表面图 像的缺陷张量信息,包括缺陷位置、缺陷类别和置信度(缺陷类别分类概率最 大值)。
[0054]
yolov5模型对输入端的图像采用mosaic数据增强的方式,丰富图像内 容,提升对烟雾较浅或者烟雾区域较小的检测效果。
[0055]
mosaic数据增强具有如下特征:
[0056]
首先从训练样本集中取出一批(批是指batch,批次是指batch size,是模 型的超参数,本实施例中批次等于32)图像;其次从这批图像中随机挑选4张 图像,随机通过色域变化、缩小、反转和/或裁剪方式操作这四张图像,每张图 像至少进行一种操作;然后将这4张图像按照左上、左下、右上、右下四个方 向位置排列后拼接得到一张新的图像,新图像大小与未进行操作的原图大小相 同,为608
×
608
×
3;重复上述操作,设置循环次数等于batch size。
[0057]
focus模块连接三组cbl(卷积层convolution-批标准化batchnormalization-激活函数leaky relu,cbl)卷积结构和跨阶段局部网络csp1_x 模块组成的结构,之后再连接一个池化网络spp模块,构成特征提取网络;通 过使用focus模块对图像进行切片操作,经过focus模块后送入由cbl卷积结 构和csp1_x模块组成的结构,再通过spp模块将低层特征和高层特征相融合。
[0058]
focus模块具有如下特征:
[0059]
首先将大小为608
×
608
×
3的原图像用1、2、3、4四个数字做标记,其次 将相同数字的像素组合成大小为304
×
304
×
3的4个部分,然后将这4个部分 按照数字大小在深度方向拼接为304
×
304
×
12的特征图,再连接一个cbl卷 积结构。
[0060]
focus模块包含的cbl卷积结构的特征是:卷积层(convolution,conv)的卷 积核个数为64,大小为3
×
3,步距为1。
[0061]
csp1_x模块具有如下特征:
[0062]
x代表残差结构的个数,除残差结构个数不同外的其他结构相同。
[0063]
以csp1_3模块为例,该csp1_3模块首先对输入的特征图进行cbl卷积 操作;然后送入3个残差结构中,接着对经过残差结构的特征图进行卷积,并 与输入的特征图直接卷积后得到的新特征图进行深度方向拼接concat;最后通 过批标准化、激活函数leakyrelu和一层cbl卷积结构输入到下个模块中。
[0064]
csp1_x模块中直接对输入特征图进行卷积的cbl卷积结构的卷积层conv 和csp1_x模块中位于最后的cbl卷积结构中的卷积层conv相同,卷积层conv 相关尺寸为:卷积核大小为1
×
1,步距为1。
[0065]
特征再处理网络设计:采用特征金字塔fpn和像素聚合网络pan的结构, 其中fpn结构是由两组csp2_3模块、cbl卷积结构和上采样up sample结构 串联组成的;pan包括两
个cbl卷积结构,对数据进行下采样。
[0066]
将fpn中的每个上采样结构的输出和特征提取网络中的csp1_9-1、 csp1_9-2模块的输出特征图进行深度方向张量拼接concat,同时将fpn中的 每个cbl卷积结构的输出和pan中的cbl卷积结构对应大小的特征图进行深 度方向张量拼接concat,pan结构每次经过cbl卷积结构后分别增加一个 csp2_3模块和spp模块,pan结构的第一个cbl卷积结构之前也增加一个 csp2_3模块和spp模块;csp2_3和spp模块都不改变特征图大小,neck中 csp2_3-3模块的输出是76
×
76,之后连接到cbl卷积结构,把图像大小变成 38
×
38,csp2_3-4模块的输出连接到cbl卷积结构的输入,把图像变成19
×ꢀ
19。
[0067]
fpn包括了两个cbl卷积结构,但是这里的cbl都是步距为1的卷积, 对特征图的大小没有影响,是fpn中的上采样up sample改变的特征图大小, 学习多尺度目标信息。
[0068]
跨阶段局部网络csp2_3模块具有的特征是:
[0069]
该模块结构与csp1_3模块每个残差结构中的将add融合过程删除后的结 构相同。csp2_3模块包括一个初始的cbl卷积结构和一个末尾的cbl卷积结 构、多个重复单元,大小为1
×
1的卷积层经批标准化和激活函数leaky relu连 接3
×
3卷积层,该3
×
3卷积层再连接批标准化和激活函数leaky relu构成重 复单元,重复单元的数量为三个,第一个重复单元的输入连接初始的cbl卷积 结构的输出,三个重复单元依次串联后的输出连接一层卷积层,该卷积层的输 出与原始输入经一层卷积层后进行拼接,拼接后再经批标准化和激活函数 leaky relu连接末尾的cbl卷积结构。
[0070]
fpn中的cbl卷积结构具有的特征是:卷积核大小都为1
×
1,步距都为 1。
[0071]
pan中的cbl卷积结构具有的特征是:卷积核大小都为3
×
3,步距都为 2。
[0072]
spp模块由最大池化核大小分别为1
×
1、5
×
5、9
×
9、13
×
13的四个并行 池化层组成,spp模块自身包含了两层cbl卷积结构,在开始和结束部分。
[0073]
yolov5模型的输出继承了yolov3的思想,采用3个尺度特征图进行检 测,特征图大小分别19
×
19、38
×
38、76
×
76。并为增加的每个spp模块后的 每个尺度分配相应个数的anchor box,特征图中的每个像素生成9个anchorbox,通过加权非极大值抑制筛选出最优框,并将giou作为损失函数返回到 网络中,训练参数。
[0074]
本实施例在centos7.9.2的平台下完成,使用python编程实现,测试网络模 型和训练网络模型的计算机性能是:tesla v100、interl xeon(r)gold 6271c cpu @2.6ghz;使用的框架是pytorch深度学习框架。yolov5模型的学习率选为 λ=0.01,训练步数为500次。
[0075]
本实施例采用ap(average precision,平均精度)和map(mean averageprecision,平均准确率)进行评价。在目标检测中,每个类别都对应一个准确 率和召回率。近几年常见的评价指标是ap和map,ap为准确率(precision)
‑ꢀ
召回率(recall)曲线下的面积,p-r曲线是以precision为y轴,recall为x轴绘制。 评判模型的优劣主要是通过曲线下的面积大小来决定。map则是多个类别的ap 均值。
[0076][0077][0078]
其中,tp是正例正确分为正例的数量,fp是正例错误分为负例的数量,fn 是负例分为正例的数量。
[0079]
ap的计算方法为:
[0080][0081]
其中,p表示准确率(precision),r表示召回率(recall)。
[0082]
在实际的统计情况中,准确率和召回率不是连续的曲线,独立的有限个数 值。因此,计算过程中将其离散统计:
[0083][0084]
其中,n表示待测数据集的图像总数,p(k)表示在模型对k个图像识别出的 准确率,δr(k)代表当模型在识别出k个图像到k-1个图像时的召回率变化情况。
[0085]
在目标检测中,通常利用预测出的标记框与目标的真实标记框的重叠度多 少来判断模型是否正确检测出来目标,该重叠度也被称为iou(intersection overunion),一般会设定iou的阈值为0.5,如果,模型经过计算得到的iou大于0.5, 那么则判定正确检测出目标,iou示意图如图所示。
[0086]
计算公式为:
[0087][0088]
其中,a∩b表示预测框与目标框重叠的面积,a∪b表示预测框与目标框的并集 面积。
[0089]
本实施例对带钢表面块状缺陷、划痕、油斑和白点一共4种缺陷图像进行了 实验,其中对白点的识别准确率在87%左右,其余所有缺陷识别率均达到90% 以上,对于块状缺陷和油斑这两个具有相似结构的缺陷的识别率较高,说明本 发明检测方法对于这两类相似缺陷区别度高,检测精度高。
[0090]
本发明未述及之处适用于现有技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1