车辆及其控制方法与流程
1.本公开涉及一种车辆及其控制方法。
背景技术:
2.常规地,在车辆行驶时,车辆中的乘客可以看到车辆外部的风景,但是不能从听觉上感受自然环境。如果在行驶过程中提供与周围自然环境协调的适当声音,则车辆中的乘客可能会感觉更舒适和满意。
3.尽管已经开发了为用户提供提前存储的行驶声音的技术,然而,在行驶时,常规技术可能不能为乘客提供针对车辆的外部环境而定制的声音。
技术实现要素:
4.本公开的实施方式提供一种车辆及其控制方法,可以在行驶过程中为乘客提供最适合于外部环g境的诸如声音效果和/或音乐的声音。
5.将在下列说明书的第四部分设置本公开的附加实施例,其随后并且从说明书中部分显而易见、或可以通过本公开的实践而学习本公开。
6.根据本公开的实施例,提供一种车辆,包括:相机;扬声器;以及电连接至相机和扬声器的控制器;其中,控制器被配置为:通过相机获取车辆外部的第一外部图像;将第一外部图像输入至经过预训练的预训练第一神经网络;提取与第一外部图像相对应的第一特征;将第一特征与多个预存储特征进行比较,该多个预存储特征中的每个与多个声音样本中的一个相对应;并且控制扬声器输出多个声音样本当中的第一声音样本。
7.预训练的第一神经网络被配置为提取用于识别与所输入的第一外部图像相对应的地形信息的特征、或者用于识别被预设与地形信息相对应的情绪信息的特征。
8.控制器被配置为:使用机器学习模型在多个预存储特征当中识别与第一特征最为相似的第二特征,该多个预存储特征中的每个与多个声音样本中的一个相对应;并且选择与第二特征相对应的第一声音样本。
9.在将多个声音样本中的每个声音样本转换成时间和频率的频谱图像之后,基于输入有时间和频率的频谱图像的第二神经网络的学习,与多个声音样本中的一个相对应的多个预存储特征中的每个被提取并存储。
10.第二神经网络被配置为学习提取用于识别与所输入的频谱图像相对应的地形信息的特征、或者用于识别被预设与地形信息相对应的情绪信息的特征。
11.控制器进一步被配置为:响应于在获取第一外部图像之后过了预定时间而通过相机获取第二外部图像;将第二外部图像输入至第一神经网络;提取与第二外部图像相对应的第三特征;将第三特征与多个预存储特征进行比较,该多个预存储特征中的每个与多个声音样本中的一个相对应;并且在多个声音样本当中选择第一声音样本或与第一声音样本不同的第二声音样。
12.当从多个声音样本中选择第一声音样本并且第一声音样本包括第一声音效果时,
控制器被配置为将第一声音效果的重复回放的次数设置为小于预定的最大重复次数;并且当从多个声音样本中选择第二声音样本并且第二声音样本包括第二声音效果时,控制器被配置为将第二声音效果的重复回放次数设置成预定的最小重复次数。
13.当从多个声音样本中选择第一声音样本并且第一声音样本包括第一音乐时,控制器被配置为将第一音乐的回放时间设置成预定的最大回放时间;并且当从多个声音样本中选择第二声音样本并且第二声音样本包括第二音乐时,控制器被配置为将第二音乐的回放时间设置成预定的基本回放时间。
14.响应于从多个声音样本中正在选择第二声音样本并且第二声音样本包括第二音乐,控制器被配置为将用于淡出的滤波器应用于第一音乐的数据并且将用于淡入的滤波器应用于第二音乐的数据。
15.根据本公开的实施例,提供一种车辆的控制方法,控制方法包括:通过相机获取车辆外部的第一外部图像;将第一外部图像输入至预训练的第一神经网络;提取与第一外部图像相对应的第一特征;将第一特征与多个预存储特征进行比较,该多个预存储特征中的每个与多个声音样本中的一个相对应;并且基于比较的结果输出多个声音样本当中的第一声音样本。
16.预训练的第一神经网络提取用于识别与所输入的第一外部图像相对应的地形信息的特征、或者被用于识别被预设与地形信息相对应的情绪信息的特征。
17.控制方法还包括:通过机器学习模型在多个预存储特征当识别与第一特征最为相似的第二特征,该多个预存储特征中的每个与多个声音样本中的一个相对应;并且选择与第二特征相对应的第一声音样本。
18.在将多个声音样本中的每个声音样本转换成时间和频率的频谱图像之后,基于输入有时间和频率的频谱图像的第二神经网络的学习,与多个声音样本中的一个相对应的多个预存储特征中的每个被提取并存储。
19.第二神经网络学习提取用于识别与所输入的频谱图像相对应的地形信息的特征、或者用于识别被预设与地形信息相对应的情绪信息的特征。
20.控制方法还包括:响应于在获取第一外部图像之后过了预定时间而通过相机获取第二外部图像;将第二外部图像输入至第一神经网络;提取与第二外部图像相对应的第三特征;将第三特征与多个预存储特征进行比较,该多个预存储特征中的每个与多个声音样本中的一个相对应;并且基于比较的结果在多个声音样本当中选择第一声音样本或与第一声音样本不同的第二声音样本。
21.控制方法还包括:从多个声音样本中选择第一声音样本,其中,第一声音样本包括第一声音效果,并且将第一声音效果的重复回放的次数设置为小于预定的最大重复次数;或者从多个声音样本中选择第二声音样本,其中,第二声音样本包括第二声音效果,并且将第二声音效果的重复回放次数设置成预定的最小重复次数。
22.控制方法还包括:从多个声音样本中选择第一声音样本,其中,第一声音样本包括第一音乐,并且将第一音乐的回放时间设置成预定的最大回放时间;或者从多个声音样本中选择第二声音样本,其中,第二声音样本包括第二音乐,并且将第二音乐的回放时间设置成预定的基本回放时间。
23.控制方法还包括:响应于从多个声音样本中选择第二声音样本并且第二声音样本
包括第二音乐,应用用于淡出第一音乐的数据的滤波器并且应用用于淡入第二音乐的数据的滤波器。
附图说明
24.从结合所附附图的示例性实施例的下面的说明书中,本公开的这些和/或其他实施例将变得显而易见并且更易于理解,其中:
25.图1是示出包括根据实施例的车辆和服务器的系统的框图;
26.图2是示出根据实施例的车辆的操作的流程图;
27.图3是示出根据实施例的车辆的选择声音样本的操作的示图;
28.图4是示出根据实施例的第一卷积神经网络(cnn)的学习操作的流程图;
29.图5是示出根据实施例的第二cnn的学习操作的流程图;
30.图6是示出根据实施例的车辆的操作的流程图;
31.图7是示出根据实施例的车辆的操作的流程图;以及
32.图8a、图8b、图8c、以及图8d是示出根据实施例的车辆的行驶环境的每个图像的声景的实现方式的示图。
具体实施方式
33.贯穿本说明书,类似的参考标号表示类似元件。此外,本说明书并不描述根据本公开的实施例的全部元件,并且省去本公开涉及的技术领域中所熟知的描述或重叠部分。诸如“~零件”、“~设备”、“~模块”等的术语可以指用于处理至少一种功能或行为的单元。例如,术语可以指至少由至少一个硬件或软件处理的过程。根据实施例,多个“~零件”、“~设备”、或“~模块”可以示例为单一元件,或单一“~零件”、“~设备”、或可以包括多个元件的“~模块”。
34.应当理解的是,当将元件称为“连接”至另一元件时,该元件能够直接或间接地连接至另一元件,其中,间接连接包括经由无线通信网络的“连接”。
35.应当理解的是,当在本说明书中使用时,术语“包括”指存在所述特征、整体、步骤、操作、元件、和/或部件,但并不排除存在或添加一个或多个其他特征、整体、步骤、操作、元件、部件、和/或其组合。
36.应当理解的是,尽管此处可以使用术语第一、第二等来描述各个元件,然而,这些元件不应受这些术语限制。
37.应当理解的是,单数形式也旨在包括复数形式,除非上下文另有清晰指示。
38.方法步骤中所使用的参考标号仅用于说明方便,而非限制步骤的顺序。由此,除非上下文另有清晰指示,否则,可以另行实施编写顺序。
39.在下文中,将参考所附附图对操作原理和实施例进行详细描述。
40.图1是示出包括根据实施例的车辆100和服务器1000的系统1的框图。
41.参考图1,车辆100可以包括相机102、扬声器104、通信器106、存储器108、和/或控制器110。
42.相机102可以拍摄静止图像和/或视频。相机102可以包括图像传感器和透镜。此外,相机102可以基于控制器110的控制而获取(或拍摄)车辆100的内部和/或外部的图像。
43.可以提供单个相机102或多个相机102。相机102具有从车辆100的前面、后面、和/或侧面向外的视野、并且可以获取车辆100的外部图像。
44.例如,相机102可以包括分别定位在车辆100的前面和侧面的两个相机,并且基于控制器110的控制以预定的时间间隔获取图像,例如,每隔30秒。
45.扬声器104可以将电信号改变成声音并且输出该声音。
46.通信器106(也被称为通信设备或通信电路)可以在车辆100与外部设备(例如,服务器1000)之间建立无线和/或有线通信信道并且通过已建立的通信信道而支持通信。此外,通信器106可以包括通信电路。例如,服务器1000可以是云服务器。此外,例如,通信器106可以包括有线通信模块(例如,电力线通信模块)和/或无线通信模块(例如,全球定位系统(gps)模块、蜂窝通信模块、wi-fi通信模块、本地无线通信模块、和/或蓝牙通信模块)、并且可以使用上述通信模块当中的对应通信模块与外部设备进行通信。
47.通信器106可以包括通信电路(也被称为收发器)和控制电路,通信电路能够在车辆100的组成部件(也被称为设备)之间执行通信,例如,控制器局域网(can)和/或本地互连网络(lin)通信,而控制器电路通过用于车辆的通信网络控制通信电路的操作。
48.存储器108可以存储由车辆100的至少一个其他组成部件(相机102、扬声器104、通信器106、和/或控制器110)使用的各种数据。例如,存储器108可以存储软件程序以及关于有关于软件程序的命令的输入数据或输出数据。存储器108可以包括易失性存储器和/或非易失性存储器。
49.控制器110(也被称为控制电路或处理器)可以控制车辆100的至少一个其他组成部件(例如,诸如相机102、扬声器104、通信器106、和/或存储器108的硬件组成部件、或者诸如软件程序的软件组成部件)。此外,控制器110可以执行各种数据处理和数据操作。控制器110可以包括控制车辆100的电力系统的电子控制单元(ecu)。控制器110可以包括处理器和存储器。
50.控制器110可以被称为声景提供系统。
51.控制器110可以分析通过相机102实时获取的图像的特征。
52.控制器110可以通过车辆100的存储器108或服务器1000的预训练的第一神经网络算法分析图像的特征。
53.例如,第一神经网络算法可以包括第一卷积神经网络(cnn)算法(也被称为虚拟的cnn算法)。
54.第一cnn算法指用于通过cnn(也被称为第一cnn模型或第一基于cnn的深度学习模型)提取对应于图像的特征的算法,cnn通过输入图像进行学习。
55.例如,可以通过相对于图像生成地形的标记(例如,河边、海滩、公路、森林道路、和/或城市中心等)并且学习所标记的图像,第一cnn算法对图像进行分类。
56.作为另一示例,可以通过将图像分类成地形和情绪(例如,欢快、兴奋、悲伤、抑郁、孤独、和/或平和等)、相对于所分类的图像生成复杂形势的标记(例如,河边-欢快、海滩-兴奋等)、并且学习所标记的图像,第一cnn算法执行图像的精细分类。
57.控制器110可以基于与地形和/或情绪协调的基于声音样本的特征数据库而选择适合所获取图像的声音样本。在该示例中,基于声音样本的特征数据库可以存储在存储器108中或通过通信器106与服务器1000进行通信而被接收。
58.例如,服务器1000或存储器108可以通过第二神经网络算法学习各种声音样本来生成特征数据库。例如,第二神经网络算法可以包括第二cnn算法(也被称为音频cnn算法)。
59.第二cnn算法可以是这样一种算法,即,通过基于声音样本的短时间傅里叶变换(stft)生成时间和频率的频谱图像来提取特征,并且然后,学习输入有时间和频率的频谱图像的第二cnn(也被称为第二cnn模型或第二基于cnn的深度学习模型)。此外,可以对第二cnn算法应用其他算法。
60.控制器110可以包括第一cnn学习模型分析单元112、第二cnn学习模型分析单元114、基于机器学习的特征比较单元116、以及声音样本回放变量设置单元118。
61.第一cnn学习模型分析单元112可以在车辆100被驱动至第一cnn时输入通过相机102而获取的外部图像、并且通过第一cnn算法提取车辆100的实时行驶环境的特征。
62.第二cnn学习模型分析单元114可以将多个声音样本输入至第二cnn、通过第二cnn算法提取车辆100的行驶环境的特征、并且由此可以采集特征数据库。
63.多个声音样本中的每个声音样本可以包括声音效果和/或音乐。
64.例如,声音效果可以包括鸟声和/或波浪声。此外,音乐可以包括钢琴曲和/或长笛曲。
65.基于机器学习的特征比较单元116可以将对应于从第一cnn学习模型分析单元112输出的图像的特征与基于从第二cnn学习模型分析单元114输出的多个声音样本所采集的特征数据库进行比较,并且由此可以在特征数据库当中识别与从第一cnn学习模型分析单元112输出的图像相对应的特征最为相似的特征。此外,基于机器学习的特征比较单元116可以识别所识别特征的声音样本。
66.基于机器学习的特征比较单元116可以将图像的特征与声音的特征进行比较,并且由此可以通过选择与图像的特征最为相似的声音样本的机器学习模型来识别声音样本。
67.例如,可以通过相对熵(kullback-leibler,kl)散度方法等执行图像的特征与特征数据库之间的比较。在kl散度方法中,计算两个数据的概率分布之间的差,并且确定具有最小差的特征彼此相似并且可以通过使数据的交叉熵最小化而进行计算。
68.声音样本回放变量设置单元118可以识别通过基于机器学习的特征比较单元116所识别的声音样本是否包括声音效果和/或音乐。
69.当所识别的声音样本包括声音效果并且车辆100行驶的外部环境并未发生明显改变时,声音样本回放变量设置单元118可以将回放的声音效果设置在预定的最大回放次数,以使得声音效果的回放不会过度重复。
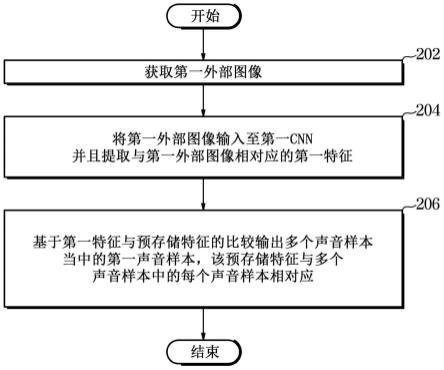
70.当所识别的声音样本包括音乐并且车辆100行驶的外部环境并未发生明显改变时,声音样本回放变量设置单元118可以将之前选择并且回放的音乐设置为延长,以使得之前选择的音乐不再从开始回放。
71.当需要根据新识别的声音样本来改变音乐时,声音样本回放变量设置单元118可以将用于淡入的滤波器(也被称为淡入滤波器)应用于包括在新识别的声音样本中的音乐数据并且将用于淡出的滤波器(也被称为淡出滤波器)应用于包括在之前声音样本中的音乐数据,以防止发生明显的改变。
72.当所识别的声音样本包括声音效果和音乐时,声音样本回放变量设置单元118可以将声音效果与音乐混合,并且由此可以通过扬声器104自然地输出混合的声音效果和音
乐。
73.上述所述第一cnn、第二cnn、和/或基于声音样本的特征数据库可以存储在作为外部设备的服务器1000中、可以基于通过通信器106与服务器1000的通信而被接收、或可以存储在存储器108中。
74.同时,车辆100可以包括音频设备(未示出),并且可以由扬声器104通过音频设备输出声音效果和/或音乐。
75.在下文中,参考图2至图6对控制器110的操作进行更为详细地描述。
76.图2是示出根据实施例的车辆100(或车辆100的控制器110)的操作的流程图。图3是示出选择根据实施例的车辆100(或车辆100的控制器110)的声音样本的操作的示图。
77.参考图2和图3,车辆100可以通过相机102获取车辆100的第一外部图像301(202)。
78.例如,第一外部图像301可以是图3中所示的沿海道路的图像。
79.车辆100可以将第一外部图像301输入至预训练的第一神经网络(例如,第一cnn 303)并且提取与第一外部图像301相对应的第一特征305(204)。
80.第一cnn 303可以进行预训练,以提取用于识别与所输入的第一外部图像301相对应的地形信息的特征、或者用于识别被预设与地形信息相对应的情绪信息的特征。后面将参考图4对第一cnn 303的学习的实施例进行描述。
81.第一特征305指与车辆100的行驶环境相对应的特征并且可以包括用于识别与第一外部图像301相对应的地形信息的特征。
82.车辆100可以基于第一特征305与对应于多个声音样本307中的每个声音样本的预存储特征313的比较,来控制扬声器104输出多个声音样本307当中的第一声音样本319(206)。
83.多个声音样本307可以被称为声音样本数据库。
84.在将多个声音样本307中的每个声音样本转换成时间和频率的频谱图像309之后,基于输入有时间和频率的频谱图像309的第二神经网络(例如,第二cnn 311)的学习,与多个声音样本307中的每个声音样本相对应的预存储特征313被提取并存储。
85.例如,第二cnn 311可以进行预训练,以提取与车辆100的行驶环境相对应的特征,车辆100的行驶环境与所输入的频谱图像309相对应。后面将参考图5对第二cnn 311的学习的实施例进行描述。
86.例如,与所输入的频谱图像309对应的车辆100的行驶环境相对应的特征可以包括用于识别地形信息的特征或被预设与地形信息相对应的情绪信息的特征。
87.与多个声音样本307中的每个声音样本相对应的预存储特征313可以被数据库化并且存储在基于声音样本的特征数据库315中。
88.通过机器学习模型317,车辆100可以在预存储的特征313当中识别与第一特征305最为相似的第二特征,并且可以选择该第二特征的第一声音样本319,该预存储特征313与多个声音样本307中的每个声音样本相对应。
89.第二特征指对应于所输入的频谱图像309的车辆100的行驶环境相对应的特征,并且可以包括用于识别与第一声音样本319相对应的地形信息的特征。
90.除上述所述实施例之外,响应于获取第一外部图像301之后过了预定时间,车辆100可以通过相机102获取第二外部图像。此外,车辆100可以将第二外部图像输入至第一
cnn 303并且提取于第二外部图像相对应的第三特征。车辆100可以基于第三特征与预存储特征313的比较来在多个声音样本307当中选择第一声音样本319或与第一声音样本319不同的第二声音样本,该预存储特征与多个声音样本307中的每个声音样本相对应。
91.根据上述所述操作,当从多个声音样本307中选择第一声音样本319并且所选择的第一声音样本319包括第一声音效果时,车辆100可以将第一声音效果的重复回放次数设置为小于预定的最大重复次数。
92.根据上述所述操作,当从多个声音样本307中选择第二声音样本并且第二声音样本包括第二声音效果时,车辆100可以将第二声音效果的重复回放次数设置成预定的最小重复次数。
93.根据上述所述操作,当从多个声音样本307中选择第一声音样本319并且第一声音样本319包括第一音乐时,车辆100可以将第一音乐的回放时间设置成预定的最大回放时间。
94.根据上述所述操作,当从多个声音样本307中选择第二声音样本并且第二声音样本包括第二音乐时,车辆100可以将第二音乐的回放时间设置成预定的基本回放时间。此外,当从多个声音样本307中选择第二声音样本并且第二声音样本包括第二音乐时,车辆100可以将用于淡出的滤波器应用于第一音乐的数据并且将用于淡入的滤波器应用于第二音乐的数据。
95.图4是示出根据实施例的第一cnn的学习操作的流程图。
96.可以由车辆100(和/或车辆100的控制器110)和/或诸如服务器1000(和/或服务器1000的控制器(未示出))的外部电子设备等执行第一cnn的学习操作。
97.车辆100和/或电子设备可以利用至少一个字标记用于学习行驶环境的多个图像中的每个图像(402)。
98.至少一个字可以包括与图像相对应的地形信息和/或被预设与地形信息相对应的情绪信息。
99.例如,地形信息可以是诸如河边、海滩、公路、森林道路、和/或城市中心等的各种地形。此外,被预设与地形信息相对应的情绪信息可以是诸如河边情况下的欢快和/或海滩情况下的兴奋等的各种情绪。
100.车辆100和/或电子设备可以通过第一cnn学习多个图像来配置第一cnn模型,以至少一个字标记每个图像(404)。
101.第一cnn模型可以进行训练,以提取与输入图像相对应的对应于车辆100的行驶环境的特征。
102.例如,与车辆100的行驶环境相对应的特征可以包括用于识别与输入图像相对应的地形信息的特征、或者用于识别被预设与地形信息相对应的情绪信息的特征。
103.图5是示出根据实施方式的第二cnn的学习操作的流程图。
104.可以由车辆100(和/或车辆100的控制器110)和/或诸如服务器1000(和/或服务器1000的控制器(未示出))等的外部电子设备执行第二cnn的学习操作。
105.车辆100和/或电子设备可以以至少一个字标记多个声音样本中的每个声音样本(502)。
106.至少一个字可以包括被预设与声音样本相对应的地形信息和/或被预设与地形信
息相对应的情绪信息。
107.例如,地形信息可以是诸如河边、海滩、公路、森林道路、和/或城市中心等的各种地形。此外,被预设对应于地形信息的情绪信息可以是诸如河边情况下的欢快和/或海滩情况下的兴奋等的各种情绪。
108.车辆100和/或电子设备可以通过第二cnn学习多个声音样本配置第二cnn模型,以至少一个字标记每个声音样本(504)。
109.在将多个声音样本中的每个声音样本转换成时间和频率的频谱图像之后,车辆100可以执行输入有时间和频率的频谱图像的第二cnn模型的学习。
110.第二cnn模型可以进行训练,以提取对应于所输入的声音样本的车辆100的行驶环境对应的特征。
111.例如,与车辆100的行驶环境相对应的特征可以包括用于识别与所输入的声音样本相对应的地形信息的特征、或者用于识别被预设与地形信息相对应的情绪信息的特征。
112.图6是示出根据实施例的车辆100(或车辆100的控制器110)的操作的路程图。
113.车辆100可以通过相机102获取图像(602)。
114.车辆100可以在行驶过程中以预定的时间间隔(例如,每隔30秒)通过相机102获取车辆100的外部图像。
115.车辆100可以将所获取的外部图像输入至预训练的第一cnn并且提取与车辆100的行驶环境相对应的特征(604)。
116.第一cnn可以是被训练为接收各种行驶环境的图像作为输入并且提取特征的第一cnn模型。
117.车辆100可以通过机器学习模型(也被称为机器学习技术)从基于声音样本的特征数据库中选择与对应于行驶环境的特征最为相似的基于声音样本的特征(606)。
118.车辆100可以将与行驶环境相对应的特征和基于声音样本的特征数据库中的基于声音样本的特征进行比较,并且由此可以通过kl散度方法在基于声音样本的特征数据库的基于声音样本的特征当中识别与对应于行驶环境的特征最为相似的基于声音样本的特征。
119.车辆100可以识别基于所选择的声音样本的特征的声音样本(608)。
120.声音样本可以包括声音效果和/或音乐。
121.根据上面参考图6所述的实施例,当假设以预定的时间间隔(时间周期)(例如,每隔30秒)选择声音样本时,车辆100可以根据车辆100的行驶环境通过扬声器104自然地输出声音。例如,车辆100可以根据车辆100的行驶环境并且根据所选择的声音样本的类型在不中断或无波动的情况下在适当的时间通过扬声器104输出声音。参考图7对车辆100输出声音的实施例进行详细描述。
122.图7是示出根据实施例的车辆100(或车辆100的控制器110)的操作的流程图。
123.参考图7,车辆100可以根据上面参考图6所描述的操作来识别声音样本(702)。
124.车辆100可以识别所识别的声音样本是否包括声音效果和/或音乐(704)。
125.当所识别的声音样本包括声音效果时,车辆100可以执行操作706。当所识别的声音样本包括音乐时,车辆100可以执行操作714。
126.当所识别的声音样本包括声音效果时,车辆100可以识别声音样本是否已改变(706)。
127.当目前识别的声音样本与之前识别的声音样本不同时,车辆100可以识别出声音样本已改变。当目前识别的声音样本与之前识别的声音样本相同时,车辆100可以识别出声音样本未改变。
128.当所识别的声音样本改变时,车辆100可以执行操作708。当所识别的声音样本未改变时,车辆100可以执行操作710。
129.车辆100可以将声音效果的回放次数设置成一次(708)。
130.车辆100可以在最大重复次数内重置声音效果的回放次数(710)。
131.例如,最大重复次数可以是三次。
132.车辆100可以响应于操作708或操作710而准备声音效果的音频流(712)。
133.当所识别的声音样本包括音乐时,车辆100可以识别声音样本是否已改变(714)。
134.当目前识别的声音样本与之前识别的声音样本不同时,车辆100可以识别出声音样本已改变。当目前识别的声音样本与之前识别的声音样本相同时,车辆100可以出识别声音样本未改变。
135.当所识别的声音样本改变时,车辆100可以执行操作716。当所识别的声音样本未改变时,车辆100可以执行操作720。
136.当所识别的声音样本改变时,车辆100可以将包括在所识别的声音样本中的音乐的回放时间设置为第一预设时间(716)。
137.第一预设时间可以被称为初始基本回放时间,例如,30秒。
138.车辆100可以将淡出滤波器添加至包括在之前音乐的之前声音样本中并且可以将淡入滤波器添加至包括在当前音乐的当前声音样本中(718)。
139.当所识别的声音样本未改变时,车辆100可以将之前音乐的回放时间设置成预定的最大回放时间(720)。
140.例如,预定的最大回放时间可以是3分钟。
141.车辆100可以响应于操作718或操作720而准备音乐的音频流(722)。
142.当所识别的声音样本包括声音效果和音乐时,车辆100可以将声音效果与音乐混合(724)。
143.当所识别的声音样本包括声音效果或音乐时,车辆100可以省去操作724。
144.车辆100可以输出音频流(726)。
145.车辆100可以输出根据操作712的音频流、输出根据操作722的音频流、或输出根据操作724的音频流。
146.在图7的实施例中描述了当在操作706中识别出声音样本改变时,将声音效果的回放次数设置成一次。然而,根据另一实施例,当第一次识别声音样本时,可以根据车辆100开始行驶而将声音效果的回放次数设置成一次。
147.此外,在图7的实施例中描述了当在操作714中识别出所识别的声音样本改变时,将音乐的回放时间设置成第一预设时间。然而,根据另一实施例,当第一次识别声音样本时,可以根据车辆100开始行驶而将音乐的回放时间设置成第一预设时间。
148.根据图7的实施例,车辆100可以根据基于所获取的图像而识别的声音样本是否包括声音效果或音乐来设置用于使对应的音频流不同地回放的变量。
149.当声音样本包括声音效果并且在当前识别的声音样本之前不存在识别的声音样
本时(当执行初始回放时),车辆100可以将回放时间设置成第一预设时间(即,初始基本回放时间)并且输出声音效果。之后,当获取下列图像、但所识别的声音样本与之前相同时,车辆100可以使声音样本重复地回放,直至达到预定的最大重复次数,以防止由于重复而感到厌烦。
150.当所识别的声音样本包括音乐并且在当时识别的声音样本之前不存在识别的声音样本时,车辆100可以将回放时间设置成第一预设时间(即,初始基本回放时间)并且输出音乐。之后,当获取下列图像、但所识别的声音样本与之前相同时,车辆100可以在不再从开始回放音乐的情况下通过延长当前的音乐而使音乐回放,直至达到预设的最大回放时间,并且由此可以减少音乐被切断的感觉。
151.当包括音乐的声音样本被识别并且然后包括另一音乐的声音样本被识别时,车辆100可以将淡出滤波器添加至之前识别的声音样本并且可以将淡入滤波器添加至当前识别的声音样本,并且由此能够使两个不同的音乐曲子彼此自然地连接。当声音样本包括声音效果和音乐时,车辆100可以分别设置用于使声音效果回放的变量和用于使音乐回放的变量、并且使声音效果与音乐混合,以输出音频流。
152.可以根据用于获取图像的预定时间周期来重复地执行根据图7的实施例的上述操作。
153.根据上述所述实施例,车辆100可以基于车辆100周围的图像来提供声景。车辆100可以通过相机102获取图像,以识别车辆100的周围环境。车辆100可以通过将所获取的图像输入至第一cnn、提取图像的特征、将图像的特征与声音样本的特征进行比较、并且选择适合图像的声音样本来执行基于深度学习的图像-声音提取。此外,车辆100可以根据车辆100的行驶环境而设置适当的变量,以使所选择的声音样本回放。
154.图8a、图8b、图8c、以及图8d是示出根据实施例的车辆100的行驶环境的每个图像的声景的实现方式的示图。
155.参考图8a、图8b、图8c、以及图8d,车辆100可以在行驶过程中获取图像,例如,图8a中所示的高速公路的图像、图8b中所示的公园的图像、图8c中所示的湖泊的图像、和/或图8d中所示的视野的图像。根据上述所述实施例,车辆100可以输出与所获取的图像相对应的声音,例如,声音效果和/或音乐。
156.从上面显而易见,根据本公开的实施例,车辆及其控制方法能够在行驶过程中为乘客提供适合外部环境的声音。
157.例如,车辆及其控制方法能够在行驶过程中使乘客在视觉以及听觉上享受外部环境,这使得乘客感觉如同乘客处于开放空间中、而非车辆中,并且由此能够提供情绪舒适性。此外,与外部环境协调的声音能够使得乘客感觉情绪上得到治愈。
158.由此,能够通过介质中/上的计算机可读代码/指令来实现实施例,例如,计算机可读介质,用以控制至少一个处理元件实现任意上述示例性实施例。介质能够对应于允许存储和/或传输计算机可读代码的任意介质/媒介。
159.计算机可读代码能够被记录在介质上或能够通过互联网发送。介质可以包括只读存储器(rom)、随机存取存储器(ram)、磁带、磁盘、闪存存储器、以及光学记录介质。
160.尽管已经出于示出性目的对实施例进行了描述,然而,本领域技术人员应当认识到,在不偏离本公开的范围和实质的情况下,可以做出各种改造、添加、以及替换。因此,并
未出于限制之目的而描述实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1