一种基于深度学习模型的文本纠错方法与流程
1.本发明涉及机器人对话及文本检索领域,具体涉及一种基于深度学习模型的文本纠错方法。
背景技术:
2.在检索或者对话场景下,错别字意味着搜索不到内容或者机器人检索不到相关对话,对于用户而言,就是需求无法满足,造成了很差的体验,因此在机器人对话或者检索领域,就很必要去纠错。
技术实现要素:
3.本发明为了克服以上技术的不足,提供了一种使预训练模型自带的tokenzier对输入文本进行编码并输入到模型中,对模型输出的logits解码即得到改正之后的文本的方法。
4.本发明克服其技术问题所采用的技术方案是:
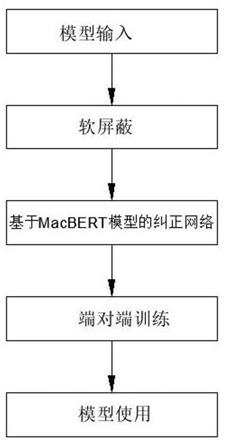
5.一种基于深度学习模型的文本纠错方法,包括如下步骤:
6.a)建立模型,该模型由检测网络、软屏蔽网络和纠正网络构成;
7.b)将文本转换为能够输入进模型的嵌入;
8.c)检测网络输出文本中第i个字符是错别字的概率pi;
9.d)软屏蔽网络软屏蔽嵌入本文第i个字符,将其定义为ei′
;
10.e)将ei′
输入纠正网络,纠正网络为基于macbert的序列多分类标记模型,检测网络的输出特征作为macbert模型12层transformer模块的输入,将macbert模型最后一层的输出与macbert模型input部分的embedding特征进行残差连接,将残差连接结果作为每个字符最终的特征表示;
11.f)模型通过端对端进行学习训练;
12.g)将训练完成后的模型通过transformers库加载产生bin文件与txt文件,bin文件为训练完成保存的模型,txt文件为保存的词表;
13.h)使用transformers库中的tokenizer对原始文本进行编码,将编码结果输入到训练好的模型中,输出结果为张量tensor,对张量tensor输出取每行的最大值位置下标,使用tokenizer.decode对位置下标进行解码,将解码后的文本作为纠错后的文本。
14.进一步的,步骤b)中通过bert模型的embedding层的输出或word2vec嵌入将将文本转换为能够输入进模型的嵌入。
15.进一步的,步骤c)中检测网络由双向门控神经网络bi-gru构成,双向门控神经网络bi-gru学习输入文本的上下文信息,输出文本每个字符是错别字的概率pi。进一步的,步骤d)中软屏蔽网络通过ei′
=pi*e
mask
+(1-pi)*ei计算得到ei′
,式中ei为本文第i个字符的输入嵌入,e
mask
为掩码的嵌入。
16.进一步的,步骤f)中模型训练时损失函数由检测网络和纠正网络的损失函数加权
得到。
17.本发明的有益效果是:使用端对端的文本纠错模型,其模型首先要有预测词语的能力。bert模型使用了transformer模型的编码器部分,可以理解为bert旨在学习庞大语料库文本的内部信息。对于bert模型的升级版macbert,其在预训练时策略有所调整,bert模型的缺点是预训练和微调阶段任务不一致,pretrain有[mask]字符,而finetune没有。macbert用目标单词的相似单词,替代被mask的字符,减轻了预训练和微调阶段之间的差距。并且原始下一个句子预测任务贡献不大,其引入了句子顺序预测任务。基于上两个预训练任务的设置,macbert便有了强大的文本建模能力。
附图说明
[0018]
图1为本发明的方法流程图。
具体实施方式
[0019]
下面结合附图1对本发明做进一步说明。
[0020]
一种基于深度学习模型的文本纠错方法,包括如下步骤:
[0021]
a)建立模型,该模型由检测网络、软屏蔽网络和纠正网络构成。
[0022]
b)将文本转换为能够输入进模型的嵌入。
[0023]
c)检测网络输出文本中第i个字符是错别字的概率pi,概率pi值越大表示该位置出错的可能性越大。
[0024]
d)软屏蔽相当于输入嵌入和掩码嵌入的加权和,误差概率pi作为权重,软屏蔽网络软屏蔽嵌入本文第i个字符,将其定义为ei′
。
[0025]
e)将ei′
输入纠正网络,纠正网络为基于macbert的序列多分类标记模型,检测网络的输出特征作为macbert模型12层transformer模块的输入,将macbert模型最后一层的输出与macbert模型input部分的embedding特征进行残差连接,将残差连接结果作为每个字符最终的特征表示。最终,将每个字符特征通过一层softmax分类器,从候选词表中输出概率最大的字符认为是每个位置的正确字符。
[0026]
f)模型通过端对端进行学习训练。
[0027]
g)将训练完成后的模型通过transformers库加载产生bin文件与txt文件,bin文件为训练完成保存的模型,txt文件为保存的词表。
[0028]
h)使用transformers库中的tokenizer对原始文本进行编码,将编码结果输入到训练好的模型中,输出结果为张量tensor,对张量tensor输出取每行的最大值位置下标,使用tokenizer.decode对位置下标进行解码,将解码后的文本作为纠错后的文本。
[0029]
将文本纠错分为检测网络和纠正网络两部分,训练损失函数以检测损失函数det_loss与纠正损失函数乘比例系数之和作为整体的损失函数。
[0030]
具体来看,模型输入是字粒度的embedding,检测网络是由bi-gru组成,充分学习输入的上下文表示,输出每个位置i可能是错别字的概率pi,值越大表示该位置出错的可能性越大。将每个位置的特征以pi的概率乘上masking字符的特征,以(1-pi)的概率乘上原始的输入特征,最后两部分相加作为每一个字符的特征输入到纠正网络中。纠正网络是一个基于macbert的序列多分类标记模型。检测网络输出的特征作为macbert 12层transformer
模块的输入,最后一层的输出+input部分的embedding特征作为每个字符最终的特征表示。最终,将每个字特征经过一层softmax分类器,从候选词表中输出概率最大的字符认为是每个位置的正确字符。
[0031]
使用训练好的文本纠错模型整个流程如下:使用开源库transformers中的tokenizer对输入文本进行编码,得到input_ids,将input_ids输入到训练好的模型中得到张量(tensor),使用transformer中的tokenizer.decode对张量中每行最大值的位置序号进行解码,得到的文本即正确的文本。
[0032]
实施例1:
[0033]
步骤b)中通过bert模型的embedding层的输出或word2vec嵌入将将文本转换为能够输入进模型的嵌入。
[0034]
实施例2:
[0035]
步骤c)中检测网络由双向门控神经网络bi-gru构成,双向门控神经网络bi-gru学习输入文本的上下文信息,输出文本每个字符是错别字的概率pi。
[0036]
实施例3:
[0037]
步骤d)中软屏蔽网络通过ei′
=pi*e
mask
+(1-pi)*ei计算得到ei′
,式中ei为本文第i个字符的输入嵌入,e
mask
为掩码的嵌入。如果出错的概率高,则软屏蔽嵌入ei′
接近掩码嵌入e
mask
,否则它接近输入嵌入ei。
[0038]
实施例4:
[0039]
步骤f)中模型训练时损失函数由检测网络和纠正网络的损失函数加权得到。
[0040]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1