一种文本大数据的图谱分析方法与流程
1.本发明涉及网络信息技术领域,特别涉及一种文本大数据的图谱分析方法。
背景技术:
2.随着互联网信息的大幅膨胀,信息量呈指数增长,浩瀚的网络数据远远超出了人们的掌控能力,中小型公司企业更不用说,他们需要通过各种渠道找寻适合自身发展的信息数据。但是,由于历年积累的数据量非常庞大,企业难以从众多信息中快捷地提取自己所需要的信息,此外,如何解读文本大数据信息,如何评估企业数据与文本大数据的匹配度,也是企业发展的一大难点。
3.因此,提出一种解决上述问题的文本大数据的图谱分析方法实为必要。
技术实现要素:
4.本发明的目的是克服现有技术的不足,提供了一种文本大数据的图谱分析方法,不仅降低了文本大数据分析的复杂度,对文本大数据信息的解读也更加方便,还提高了文本大数据分析的准确性,进一步提高企业数据与文本大数据的匹配度。
5.本发明的目的是通过以下技术方案来实现的:
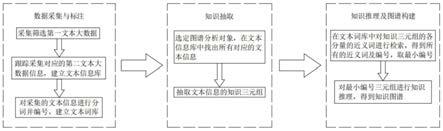
6.一种文本大数据的图谱分析方法,包括以下步骤:
7.(1)采集筛选公布的文本大数据,并对筛选后的文本大数据进行标注;
8.(2)从筛选的文本大数据中选定图谱分析对象,并通过模型对选定的图谱分析对象抽取知识三元组;
9.(3)对抽取的知识三元组进行检索,得到所有编号三元组,取最小编号,并对最小编号三元组进行知识推理,得到知识图谱。
10.进一步地,所述步骤(1)具体为:
11.1.1、采集公布的文本大数据,并筛选出第一文本大数据;
12.1.2、跟踪筛选后的第一文本大数据,并采集对应的第二文本大数据信息,建立文本信息库;
13.1.3、采用bert模型及预训练模型,对采集到的第二文本大数据信息进行分词并编号,建立文本词库。
14.进一步地,所述步骤1.2中,对于一类第一文本大数据,需要跟踪一个月或一年时间;对于每年不断更新的第一文本大数据,则应跟踪多年直到文本大数据停止更新。
15.进一步地,所述步骤1.2中的第二文本大数据信息包括公布的文本名称、起止时间、匹配条件以及数据平台。
16.进一步地,所述步骤1.3的所有分词中,对存在近义词关系的分词进行标注,且记录近义词编号。
17.进一步地,所述步骤(2)具体为:
18.2.1、选定一个图谱分析对象tx0,在文本信息库中找出所有对应的第二文本大数
据信息txi,i=1,2,3,
…
;
19.2.2、采用bert模型及其预训练模型,抽取第二文本大数据信息txi的知识三元组spoi=(si,pi,oi)。
20.进一步地,所述步骤2.1中的图谱分析对象tx0为一组文本大数据或一数据平台。
21.进一步地,所述步骤(3)具体为:
22.3.1、在文本词库中对知识三元组spoi的各分量的近义词进行检索,得到所有近义词及编号,取最小编号;
23.3.2、采用最大流算法,对最小编号三元组spo_idi进行知识推理,得到图谱分析对象tx0的知识图谱。
24.进一步地,所述步骤3.1具体为:
25.3.1.1、在文本词库中检索知识si的所有近义词并记录编号idj,j=1,2,3,
…
,设id0为知识si对应的编号,取最小编号s_idi=min{id0,id1,id2,id3,
…
};
26.3.1.2、针对知识pi,oi采用上述同样的方法得到最小编号p_idi,o_idi;
27.3.1.3、综上所述,得到知识三元组spoi对应的最小编号三元组spo_idi=(s_idi,p_idi,o_idi)。
28.与现有技术相比,本发明具有如下的有益效果:
29.本发明通过从文本大数据中筛选出第一文本大数据,从而进一步地对第一文本大数据进行跟踪,并采集相对应的第二文本大数据信息,采用bert模型及其预训练模型既对采集的文本信息进行分词,提取重要的分词信息,过滤掉无关信息,又对采集的第二文本大数据信息抽取知识三元组,提高了知识三元组抽取的准确性,同时也保证了工作效率;此外,运用最大流算法对其进行知识推理,在最大流算法中,通过多条路径进行推理,所得到的知识图谱更加精准,使得企业数据与文本大数据匹配度更高。
附图说明
30.图1为本发明一种文本大数据的图谱分析方法的结构流程图。
具体实施方式
31.下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
32.本发明提供了一种文本大数据的图谱分析方法,包括以下步骤:
33.(1)采集筛选公布的文本大数据,并对筛选后的文本大数据进行标注,具体步骤为:
34.1.1、采集公布的文本大数据,并筛选出第一文本大数据;
35.1.2、跟踪筛选后的第一文本大数据,并采集对应的第二文本大数据信息,建立文本信息库;
36.1.3、采用bert模型及预训练模型,对采集到的第二文本大数据信息进行分词并编号,建立文本词库。
37.优选的技术方案,对于一类第一文本大数据,需要跟踪一个月或一年时间;对于每年不断更新的第一文本大数据,则应跟踪多年直到文本大数据停止更新,根据不同类型的
文本大数据,设置不同的跟踪的时间,可在有效的时间内获得更多的文本大数据信息,缩短寻找文本大数据信息的时间;所需要采集的第二文本大数据包括公布的文本名称、起止时间、匹配条件以及数据平台;在所有分词中,对存在近义词关系的分词进行标注,且记录近义词编号。
38.(2)从筛选的文本大数据中选定图谱分析对象,并通过模型对选定的图谱分析对象抽取知识三元组,具体步骤为:
39.2.1、选定一个图谱分析对象tx0,在文本信息库中找出所有对应的第二文本大数据信息txi,i=1,2,3,
…
;
40.2.2、采用bert模型及其预训练模型,抽取第二文本大数据信息txi的知识三元组spoi=(si,pi,oi)。
41.优选的技术方案,通过将图谱分析对象tx0选定为一组文本大数据或一数据平台,对第二文本大数据或数据平台的分析,可清楚了解第二文本大数据所需要的匹配条件,有利于企业更好地评估企业数据与文本大数据的匹配度。
42.优选的技术方案,本发明采用bert模型及其与训练模型,既要对文本信息库中的文本大数据进行分词,又要从中抽取知识元组,而bert模型采用mlm对双向的transformers进行预训练,可生成深层的双向语言表征,且在预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现,在这过程中并不需要对bert模型进行任务特定的结构修改,大大提高了工作效率。
43.(3)对抽取的知识三元组进行检索,得到所有编号三元组,取最小编号,并对最小编号三元组进行知识推理,得到知识图谱,具体步骤为:
44.3.1、在文本词库中对知识三元组spoi的各分量的近义词进行检索,得到所有近义词及编号,取最小编号;
45.优选的技术方案,步骤3.1具体为:
46.3.1.1、在文本词库中检索知识si的所有近义词并记录编号idj,j=1,2,3,
…
,设id0为知识si对应的编号,取最小编号s_idi=min{id0,id1,id2,id3,
…
};
47.3.1.2、针对知识pi,oi采用上述同样的方法得到最小编号p_idi,o_idi;
48.3.1.3、综上所述,得到知识三元组spoi对应的最小编号三元组spo_idi=(s_idi,p_idi,o_idi)。
49.本发明通过同样的方式,快速抽取最小编号三元组,从而使下一步运用最大流算法对编号三元组进行知识推理时,可找到更多的增广路,提高知识图谱构建的准确性。
50.3.2、采用最大流算法,对最小编号三元组spo_idi进行知识推理,得到图谱分析对象tx0的知识图谱。
51.优选的技术方案,本发明采用最大流算法对最小编号三元组进行知识推理,在最大流算法中,可寻找增广路再进行增广,直到无法增广为止,算法结束,通过多条路径进行推理,所得到的知识图谱更加精准,使得企业数据与文本大数据匹配度更高。
52.本发明根据采集的文本大数据,并对文本大数据信息做分析,主要针对第二文本大数据信息,并跟踪此类文本大数据后期更新的、对应的文本信息,建立知识图谱,为企业数据提高匹配度提供了决策性依据,通过这种文本大数据图谱的分析方法,不仅提高了企业解读文本大数据的速度,且也进一步提高了企业数据与文本大数据的匹配度。
53.需要声明的是,上述具体实施方式仅仅为本发明的较佳实施例及所运用技术原理,在本发明所公开的技术范围内,任何熟悉本技术领域的技术人员在未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都应涵盖在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1