一种数据不平衡目标识别方法、系统、设备及存储介质
1.本发明属于机器学习技术领域,具体涉及一种数据不平衡目标识别方法、系统、设备及存储介质。
背景技术:
2.近年来,机器学习和数据挖掘的研究越发火热,相关应用也正在为世界带来越来越多的实际价值。监督学习,作为机器学习中的几大主流问题之一,常常被用于目标的分类或者身份的识别。其作用原理是利用已知类别的数据样本训练机器学习的模型,再基于得到的模型来预测未知样本的类别,在分类问题中,这个训练好的模型被称为“分类器”。随着越来越多的模型和算法从学术界走向工业界,许多困难也渐渐凸显并影响着这些算法的落地。数据不平衡可以说是其中的一个非常显著的问题,数据不平衡问题又可以叫做“样本比例失衡”,是指数据分布不均匀,而这种不平衡不均匀的现象往往体现在两个方面:一方面表现在每类样本的数量不平衡,少数类和多数类的数量之比可达1:10甚至1:100及以上,极端情况或许能达到1:10000;另一方面表现在少数类样本的分布和多数类样本的分布间存在一些类间重叠、噪声以及不可分的部分。其中前者被一些学者称为“类间不平衡”,而后者被称为“类内不平衡”。在许多学术研究中往往存在一些“数据分布均匀”的前提假设,但当把算法应用于实际场景中,在多数情况下无法取得理想结果的原因很有可能就是忽略了对数据不平衡问题的处理。这样的忽略带来的后果是:多数类样本的预测准确率非常高,而少数类样本的预测准确率非常低,测试集样本的总体准确率“虚高”。在不平衡的数据集上得到这样一个虚高的预测准确率的意义不大,因为此时的模型只需要将任何未知类别的样本都预测成多数类样本就可以得到一个非常高的预测准确率。但在实际的问题中,往往更加关注少数类样本的识别准确率,其原因包括:(1)多数类样本在实际场景中出现次数很频繁,其特征明显,在应用分类模型之前或许就可以通过其他方式(如从业经验、样本的某一显著特征等)准确判断出多数类样本的身份。(2)少数类样本在实际场景中往往具备更高的价值(比如某一品质非常上佳的白酒、银行的潜在高额储蓄用户、具有研究价值的疑难杂症病例等),它们的出现代表着“物以稀为贵”。
3.目前解决数据不平衡问题的途径大致分为两类:(1)从数据的角度出发,对数据进行预处理,通过对多数类样本的欠采样或者少数类样本的过采样处理,使得各类样本之间的数量更加平衡
[1,2,3]
。(2)从算法模型的角度出发,通过调节模型中和代价相关的参数,增大错分少数类样本的代价
[4]
,或者基于集成学习的思想集成多个单分类器的结果,用一个更高层次的模型去给出预测结果
[5,6]
。在样本集的总体规模较小的情况下,通过过采样或者欠采样的方式对数据进行预处理的思路不一定能够取得较好的效果,因为预处理往往是通过插值的方式产生许多人造样本,在一个数据规模本就很小的问题上,无法保证人造样本和真实样本具有同等的真实性。
[0004]
[1]he h,garcia e a.learning from imbalanced data[j].ieee transactions on knowledge and data engineering,2009,21(9):1263-1284.
[0005]
[2]chawla n v,bowyer k w,hall l o,et al.smote:synthetic minority over-sampling technique[j].2011.
[0006]
[3]liu x y,wu j,zhou z h.exploratory undersampling for class-imbalance learning[j].ieee transactions on systems man&cybernetics part b,2009,39(2):539-550.
[0007]
[4]金鑫,李玉鑑.不平衡支持向量机的惩罚因子选择方法[j].计算机工程与应用,2011,47(33):5.
[0008]
[5]sun y,kamel m s,wong a,et al.cost-sensitive boosting for classification of imbalanced data[j].pattern recognition,2007,40(12):3358-3378.
[0009]
[6]sukhanov s,merentitis a,debes c,et al.bootstrap-based svm aggregation for class imbalance problems[c]//2015 23rd european signal processing conference(eusipco).ieee,2015.
技术实现要素:
[0010]
本发明的目的在于针对上述现有技术中的问题,提供一种数据不平衡目标识别方法、系统、设备及存储介质,基于集成学习的思路来改进机器学习算法在小样本、数据不平衡问题上的性能表现,在多分类器系统中添加了为每个待预测样本选择合适的分类器集合的动态选择环节,并且基于贝叶斯理论组合各分类器的输出结果,实现在总体准确率不受影响的情况下,提高相对重视且数量珍惜的少数类样本的识别能力。
[0011]
为了实现上述目的,本发明有如下的技术方案:
[0012]
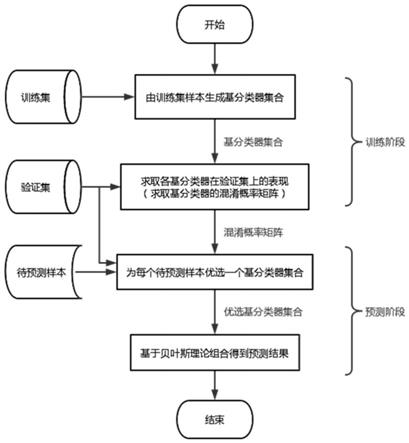
第一方面,提供了一种数据不平衡目标识别方法,包括:
[0013]
由训练集样本生成基分类器集合;
[0014]
将训练集样本生成的基分类器集合作用于验证集上,求取每个基分类器的混淆概率矩阵;
[0015]
动态为每个待预测样本优选一个基分类器集合;
[0016]
依据得到的每个基分类器的混淆概率矩阵,基于贝叶斯理论组合所优选基分类器集合的输出结果,得到待预测样本一个最终的预测类别。
[0017]
作为本发明方法的一种优选方案,所述由训练集样本生成基分类器集合的步骤具体包括:
[0018]
对于训练集中含有l类目标组成集合ω={ω1,ω2,...,ω
l
},每类目标包含ni,i=1,2,...,l个样本,则训练集总共包含个样本;针对基分类器集合包含m个基分类器,设定随机抽样比例为randomfactor;
[0019]
在每类目标中有放回地随机抽取ni×
randomfactor,i=1,2,...,l个样本,组成基分类器训练集,基于此训练集训练基分类器模型ci,i=1,2,...m,重复m次,得到基分类器集合c={c1,c2,...,cm}。
[0020]
作为本发明方法的一种优选方案,所述将训练集样本生成的基分类器集合作用于验证集上,求取每个基分类器的混淆概率矩阵的步骤包括:
[0021]
将某一基分类器ci,i=1,2,...m的混淆矩阵cmi定义如下:
[0022][0023]
该矩阵中的表示验证样本集中真实类别为ω
l
,而被基分类器ci识别成ωq的样本数;根据混淆矩阵计算出一个l
×
l维矩阵lmi,该矩阵被称为混淆概率矩阵,其形式为:
[0024][0025]
该矩阵中的表示验证样本集中属于模式类ω
l
,而被基分类器ci分类成ωq的概率的估计值,通过下式计算:
[0026][0027]
式中,oi表示基分类器ci输出的类别,p(oi=ωq|ω
l
)表示当样本属于模式类ω
l
时oi=ωq的概率,这个概率值的意义相当于贝叶斯理论中的似然概率。
[0028]
作为本发明方法的一种优选方案,所述动态为每个待预测样本优选一个基分类器集合的步骤包括,对于一群待预测类别的样本组成了未知样本集合x
test
={x
testi
|i=1,2,...,n
test
},在动态选择环节中,根据每个样本x
testi
的特点,找到该样本在验证集上的一个邻域neighborhoodi,然后在该邻域上评价各个基分类器的性能,选择排名靠前的基分类器构成一个优选的基分类器集合。
[0029]
作为本发明方法的一种优选方案,所述在动态选择环节中,根据每个样本x
testi
的特点,找到该样本在验证集上的一个邻域neighborhoodi的步骤包括:
[0030]
针对待预测样本x
testi
,在验证集x
veri
上找到与其距离最近的k个验证集样本,组成邻域neighborhoodi={x
neighbori
|i=1,2,...,k},这里的距离度量采用欧式距离,即dist
testi,neighbork
=||x
testi-x
neighbork
||,该距离越小,判定验证集上的样本就和待测样本越相似。
[0031]
作为本发明方法的一种优选方案,所述在该邻域上评价各个基分类器的性能,选择排名靠前的基分类器构成一个优选的基分类器集合包括:
[0032]
设置动态选择的评价指标,根据动态选择的评价指标排序,取排名前m
′
的基分类器组成优选基分类器集合c
′i={c1,c2,...,cm′
},i=1,2,...,n
test
。
[0033]
作为本发明方法的一种优选方案,所述依据得到的每个基分类器的混淆概率矩阵,基于贝叶斯理论组合所优选基分类器集合的输出结果,得到待预测样本一个最终的预测类别包括:
[0034]
由下式计算得到待预测样本x
testi
属于类别l的支持度s
l
(xi):
[0035][0036]
式中,为基分类器ci的混淆概率矩阵lmi中的元素,表示验证样本集中属于模式类ω
l
,而被基分类器ci分类成ωq的概率的估计值;p(ω
l
)表示样本属于ω
l
类的先验概率;oj代表分类器cj,j=1,2,...,m
′
给出的预测结果;选取最大支持度的类别作为基分类器集合的预测类别。
[0037]
第二方面,提供一种数据不平衡目标识别系统,包括:
[0038]
训练集基分类器集合生成模块,用于由训练集样本生成基分类器集合;
[0039]
混淆概率矩阵求取模块,用于将训练集样本生成的基分类器集合作用于验证集上,求取每个基分类器的混淆概率矩阵;
[0040]
待预测样本基分类器集合优选模块,用于动态为每个待预测样本优选一个基分类器集合;
[0041]
贝叶斯组合预测模块,用于依据得到的每个基分类器的混淆概率矩阵,基于贝叶斯理论组合所优选基分类器集合的输出结果,得到待预测样本一个最终的预测类别。
[0042]
第三方面,提供一种电子设备,包括:
[0043]
存储器,存储至少一个指令;及
[0044]
处理器,执行所述存储器中存储的指令以实现所述的一种数据不平衡目标识别方法。
[0045]
第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现所述的一种数据不平衡目标识别方法。
[0046]
相较于现有技术,本发明第一方面至少具有如下的有益效果:
[0047]
一方面,在多分类器系统中添加了动态选择环节,能够为少数类样本寻找到更有利于其类别预测的分类器集合,提高少数类样本的预测可信度。另一方面,在分类器组合过程中引入贝叶斯理论,结合基分类器之前的性能表现,给出每一个预测结果的置信度,最终得到的组合置信度向量更能反映样本所属类别的细节信息,同样提高了少数类样本的预测可信度。
[0048]
可以预见的是,上述第二方面至第四方面同样具有同上述第一方面相同的技术效果,因而在此处不再赘述。
附图说明
[0049]
图1(a)串行集成结构mcs系统框图;
[0050]
图1(b)并行集成结构mcs系统框图;
[0051]
图2本发明方法对应的mcs系统框图;
[0052]
图3本发明方法的算法流程图;
[0053]
图4邻域示意图;
[0054]
图5动态选择的合理性示意图;
[0055]
图6(a)以g-mean作为动态选择的评价指标三种模型在不同数据集上的准确率对比图;
[0056]
图6(b)以准确率作为动态选择的评价指标三种模型在不同数据集上的准确率对比图;
[0057]
图7(a)以g-mean作为动态选择的评价指标三种模型在不同数据集上的g-mean对比图;
[0058]
图7(b)以准确率作为动态选择的评价指标三种模型在不同数据集上的g-mean对比图;
[0059]
图8(a)以g-mean作为动态选择的评价指标三种模型在不同数据集上的少数类平均召回率对比图;
[0060]
图8(b)以准确率作为动态选择的评价指标三种模型在不同数据集上的少数类平均召回率对比图。
具体实施方式
[0061]
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
[0062]
请参阅图1(a)和图1(b),集成学习,作为机器学习领域的一个重要分支,一直都是整个领域的研究热点。集成学习在日常生活,实际场景中的应用十分广泛,收效也非常可观。在解决分类问题上面,集成学习方法针对同一问题训练多个基分类器,重点研究如何利用多个分类器的优点和互补特性,结合多个分类器的预测结果来预测未知样本的类别,集成学习为提升算法泛化能力提供了另一种思路。在分类问题中,集成学习也被称为多分类器系统(multiple classifier system,mcs),本发明的方法也可以被看作是一种多分类器系统的实现方式。
[0063]
在集成学习领域大致存在有两大类方法:串行集成和并行集成。前者的基本思想是在新生成的基分类器中,不断纠正前一个分类器犯下的错误,通过改变上一个基分类器错分样本的权重,使得错分样本在下一个分类器的训练中受到更多的关注,串行集成的代表算法是adaboost算法[7]。后者的基本动机是结合相互独立的基分类器形成最终的决策结果,“相互独立”指的是针对同一问题所训练得来的相互独立的基分类器,比如由若干相关性不大的数据子集训练而来的基分类器,并行集成的代表算法是bagging算法[8]。
[0064]
[7]freund y,schapire r e.a decision-theoretic generalization of on-line learning and an application to boosting[j].journal of computer and system sciences,1997.
[0065]
[8]leobreiman.bagging predictors[j].machine learning.
[0066]
通常情况下,一个多分类器系统的结构主要由三个环节构成,即:基分类器生成、分类器选择、分类器组合。基分类器生成环节就是针对同一机器学习问题(同一数据集),生成一系列“准确且多样的”基分类器,后续组合这些基分类器的预测结果,得到一个统一的预测类别。分类器选择环节的作用是在基分类器池中选出最适合于处理当前的某一特定子问题的分类器或者分类器集合,后续的组合环节只组合优选出来的基分类器结果,分类器选择又可分为静态选择和动态选择两种方式。静态选择的特点是一旦基分类器(集合)被选出来,后续就不再变动。静态选择的操作可以离线进行,在整个mcs的工作流程中,静态选择只进行一次。与静态选择不同,动态选择对每个标签未知的待测样本,都可以根据样本的特
点选出基分类器(集合)来进行分类,其核心思想在于每个基分类器都是样本空间中不同区域的“专家”,该方法想要选出最适合某一待分类样本的基分类器(集合)。动态选择需要在线实时进行,有多少个待分类样本,mcs就进行多少次动态选择。动态选择的方式更适合于数据不平衡问题的识别,因为从直觉上来看对于难以分辩的少数类样本,优选出来的“专家分类器”应该要比不经选择的所有基分类器更加合适。本发明的方法采用了动态选择的方式来优选基分类器,值得一提的是,分类器选择环节不是一个必需的环节,比如经典的adaboost和bagging算法就都没有包含这一环节。分类器组合环节的作用是组合各个基分类器的输出结果,得到一个统一的输出结果,根据基分类器的输出形式不同,组合方法也可以有多种,在这里不予详细介绍。本发明所描述的方法基于贝叶斯理论的组合方法来得到最终的组合置信度向量,进而给出最终的分类结果。图2直观地展示了本发明所对应的mcs系统框图。
[0067]
上述一些经典的集成学习方法和与之对应的mcs系统结构直接应用于数据不平衡的场景时,不一定能够解决数据不平衡所带来的问题,反而可能加重对于少数类样本预测性能的影响,这一点将在后文的实验结果中看到。
[0068]
在简单介绍了数据不平衡问题的背景以及多分类器系统的结构之后,下面将具体描述本发明的方法如何结合动态选择技术和贝叶斯理论来进行数据不平衡问题的识别。
[0069]
请参阅图3,本发明数据不平衡识别方法包括以下步骤:
[0070]
第一步:生成基分类器集合;
[0071]
基分类器是整个mcs中最基本的元素,是分类器选择算法和分类器组合算法的作用对象。在基分类器生成这一环节,一个包含多个基分类器的集合从训练集数据中训练生成,这个集合c={c1,c2,...,cm}被称为基分类器池。对于基分类器池,一个基本的要求是池中的基分类器应该“准确而多样”。原因很显然,首先参与后续组合环节的分类器必须自身具有较高的准确率,其次各分类器之间应该有所差异,具备互补特性。本发明采用“自助采样”的方式,通过随机生成的训练集的不同数据子集来产生m个“准确且多样”的基分类器,具体步骤如下:
[0072]
(1)假设训练集中含有l类目标组成集合ω={ω1,ω2,...,ω
l
},每类目标包含ni,i=1,2,...,l个样本,训练集总共包含个样本。设定基分类器集合的规模为m,即包含m个基分类器,设定随机抽样比例为randomfactor。
[0073]
(2)在每类目标中有放回地随机抽取ni×
randomfactor,i=1,2,...,l个样本,组成基分类器训练集,基于此训练集训练基分类器模型ci,i=1,2,...m。重复m次,得到基分类器集合c={c1,c2,...,cm}。
[0074]
第二步:求取基分类器的混淆概率矩阵;
[0075]
将第一步的输出结果,即基分类器集合作用于验证集x
veri
={x
verii
|i=1,2,...,n
veri
}上,用于预测验证集样本的类别,并得到每个分类器的混淆矩阵confumati,i=1,2,...m。某一基分类器ci,i=1,2,...m的混淆矩阵cmi定义如下:
[0076][0077]
该矩阵中的表示验证样本集中真实类别为ω
l
,而被基分类器ci识别成ωq的样本数。根据混淆矩阵可以计算出一个l
×
l维矩阵lmi,该矩阵被称为混淆概率矩阵,其形式为:
[0078][0079]
该矩阵中的表示验证样本集中属于模式类ω
l
,而被基分类器ci分类成ωq的概率的估计值,通过下式计算:
[0080][0081]
这里oi表示基分类器ci输出的类别,p(oi=ωq|ω
l
)表示当样本属于模式类ω
l
时oi=ωq的概率,这个概率值的意义相当于贝叶斯理论中的“似然概率”。至此,通过训练集样本和验证集样本得到了基分类器模型和基分类器在验证集上的混淆概率矩阵,训练阶段就完成了。
[0082]
第三步:动态选择基分类器;
[0083]
设一群待预测类别的样本组成了未知样本集合x
test
={x
testi
|i=1,2,...,n
test
},在动态选择环节中,需要根据每个样本x
testi
的特点,找到该样本在验证集上的一个邻域neighborhoodi,然后在该邻域上评价各个基分类器的性能,选择排名靠前的基分类器进入之后的分类器组合阶段,其具体步骤如下:
[0084]
针对待预测样本x
testi
,在验证集x
veri
上找到与其距离最近的k个验证集样本,组成邻域neighborhoodi={x
neighbori
|i=1,2,...,k}。这里的距离度量采用欧式距离,即dist
testi,neighbork
=||x
testi-x
neighbork
||。该距离越小,验证集上的样本就和待测样本越相似,在该邻域上表现较好的基分类器也有很大概率在待预测样本上表现良好。邻域的示意图如图4所示。
[0085]
在邻域neighborhoodi上计算每个基分类器的性能表现,基分类器的表现需要某一具体的指标来定量衡量。这里以分类准确率为例,来阐述动态选择这一过程,准确率的定义为:
[0086][0087]
将准确率排序,取排名前m
′
的基分类器组成优选基分类器集合c
′i={c1,c2,...,cm′
},i=1,2,...,n
test
。这里需要说明的是,并非一定要以分类准确率作为动态选择的评价
指标,该评价指标可以根据不同的场景和需求合理选取。
[0088]
第四步:组合基分类器输出结果;
[0089]
在第三步优选出针对待预测样本x
testi
的基分类器集合c
′i后,最后一个步骤便是组合基分类器的输出结果,得到一个最终的预测类别。这个最终的预测类别实质上由一个“支持度向量”转化而来,定义样本x
testi
支持度向量为一个l维的向量s(x
testi
)。则组合结果中,样本x
testi
属于类别l的支持度s
l
(xi)可以由下式算得:
[0090][0091]
即是每个基分类器取各自的混淆矩阵中的相应项的连乘。其中oj代表分类器cj,j=1,2,...,m
′
给出的预测结果。最终,选取支持度向量中,取得最大支持度的类别作为基分类器集合的统一决策。
[0092]
本发明所基于动态选择和贝叶斯理论的数据不平衡方法具有理论支撑,主要体现在动态选择的合理性以及组合方法中结合的贝叶斯理论。下面将详细介绍相关原理。
[0093]
(1)动态选择的合理性
[0094]
对于数据不平衡问题而言,常规分类算法所得到的结果对少数类样本类别预测的影响非常大,也就是不容易识别出少数类样本。动态选择方法首先在验证集x
veri
上通过特征向量之间的欧式距离寻找和待预测样本特征相似的邻域,然后在邻域上评估每个基分类器的性能表现,试想如图5所示的这种存在一定重叠和噪声的类间不平衡情况,假设待预测样本确实也是一个少数类样本,那么在该种邻域上表现较好的分类器在预测一个少数类样本时的可信度就会好于一个未经挑选的基分类器。
[0095]
(2)结合贝叶斯理论的组合方法合理性
[0096]
简单的组合方法如绝对多数投票法、相对多数投票法、置信度平均法等,虽然符合日常生活中做出决策的直觉,但并没有考虑某一分类器做出某一类预测是否可信,或者说可信的程度有多高,也就是组合方法没有和预测类别挂钩。而在数据不平衡问题的识别中,参与组合的分类器做出何种类别的预测显然至关重要,不仅需要关注分类器输出了“哪个类别”这种离散的标签,而且还要考虑分类器输出这个类别标签的置信度有多大,这种信息对少数类样本的预测至关重要。这里的置信度也就是上述组合方法中所定义的支持度向量s(x
testi
)。
[0097]
下面从贝叶斯理论的角度去描述组合方法的合理性:
[0098]
基分类器ci的混淆概率矩阵lmi中的元素可以表示验证样本集中属于模式类ω
l
,而被基分类器ci分类成ωq的概率的估计值(根据大数定理,验证集的规模越大,这个估值越准确),也就是贝叶斯理论中的“似然概率”p(oi=ωq|ω
l
),这代表“该分类器做出这一预测的可信度的大小”,这同样是从基分类器的历史表现(也就是验证集上的表现)提取出来的信息:
[0099][0100]
如果假设各个基分类器之间的决策是相互独立的(注意这个假设对于并行集成范式是比较合理的,因为从基分类器生成的角度来看,基分类器之间没有关联性,而这一点在
串行集成中则不然),对于一个本就属于ω
l
的样本,各个分类器做出决策oi,i=1,2,...,m的概率为似然概率的连乘:
[0101][0102]
再根据贝叶斯公式,可以求得该样本属于ω
l
的后验概率:
[0103][0104]
这个后验概率p(ω
l
|o1,o2,
…
,om)也就可以代表“样本属于ω
l
类的可信程度”。其中p(ω
l
)表示样本属于ω
l
类的先验概率。由于p(ω
l
)往往难以得到,所以在这里提出两个如何设定各类样本先验概率的建议方法:(1)如果认为数据不平衡的根本原因是本来可以获取更多的少数类样本而因为各种原因没有条件获取少数类样本,那么建议可以将每类样本出现的先验概率设定为即各类出现的概率均等;(2)反之,如果认为数据不平衡的根本原因是少数类样本本就非常稀有(比如罕见病病例,珍稀矿石等),此时可以根据现有的知识自行设定p(ωi),或者也可以根据已有数据集所含的先验信息来设定p(ωi)(前提是现有的数据能够较好地反应各类样本的真实分布)。此外,上式中的分母p(o1,o2,
…
,om)也与类别ω
l
无关,从而在分类器组合规则中可以用步骤描述中的下式来计算待预测样本属于每个类别的支持度:
[0105][0106]
下面结合部分uci数据集的识别结果,来验证本发明方法在数据不平衡识别问题上取得的性能改善,用实验结果来体现算法的可行性。实施例的实验采用matlab r2019a作为程序的软件运行环境,硬件处理器为intel(r)core(tm)i5-8400。实验环境设置如下:
[0107]
(1)实验的数据集划分方式描述:
[0108]
由于数据集划分和基分类器训练集的有放回重复采用具有随机性的特征,所以实验最终所得的性能指标为10次重复实验的平均结果。
[0109]
在每一次重复实验中,采用9折交叉验证的方式来划分每一类数据,即将l类样本每类随机等分为9份,每份记为d
li
,l=1,2,...,l,i=1,2,...,9。在每折实验中,训练集、验证集、测试集(这里的测试集就相当于实际场景中的待预测样本)的划分为“1:1:1”,按序号顺序取3份d
l{1,2,3}
作为训练集、3份d
l{4,5,6}
作为验证集、3份d
l{7,8,9}
作为测试集,这样以此类推总共可以得到9种不同的划分,即9折交叉验证。结合交叉验证的划分方式保证了9折数据中的每一个样本都能够成为训练集、验证集、或者测试集的样本,每次重复实验所得的性能指标为9折实验的平均结果。
[0110]
(2)实验采用的评价指标:
[0111]
①
准确率
[0112][0113]
在许多数据不平衡的实际场景中,准确率已经不能很好地反应算法的真实性能,
因为只要将类别的预测都倾向于多数类,就一定能够达到一个较高的总体准确率,这样做的实质意义不大。这里的准确率是算法在数据集上的总体准确率,虽然总体准确率在数据不平衡问题中意义不大,但可以作为一个参考,毕竟一个好的学习算法所取得的总体准确率也不能太差。
[0114]
②
类召回率
[0115]
类召回率的定义为:
[0116][0117]
可以看出,类召回率无论从名称上还是定义上都体现了每类样本之间的差异性,可以认为它是一种“针对每一类样本的识别准确率”,也叫类查全率。在之后的实验结果中,将重点关注少数类的类召回率。由于每个数据集的类型数不相同,姑且就将除了样本数量最多的类的其他类称作少数类。
[0118]
③
几何平均准确率
[0119][0120]
几何平均准确率g-mean,是整个问题中所有类的类召回率的几何平均值。由定义式可以看出,g-mean在数据不平衡问题上是一个比较中肯的评价,只有每一类(不管是多数类还是少数类)的召回率都比较高的时候,才能得到一个较高的g-mean,在任何类别上的表现不佳都会大幅拉低g-mean的数值。在实验结果中,本发明重点关注算法的g-mean指标。
[0121]
(3)实验采用的uci公开数据集:
[0122]
①
献血数据集blood,共748个样本
[0123]
每类样本比例1:3.16,少数类表示愿意献血并且已经献血的人。
[0124]
②
避孕方式选择数据集cmc,共1473个样本
[0125]
每类样本比例1:1.53:1.89,少数类表示选择长期避孕方式和短期避孕方式的人。
[0126]
③
乳腺癌手术患者存活数据集haberman,共306个样本。
[0127]
每类样本比例为1:2.78,少数类表示5年内死亡的患者
[0128]
④
汽车评估数据集car,共1728个样本。
[0129]
每类样本比例为5.91:18.62:1:1.06,少数类表示表现好和表现非常好的车型。
[0130]
⑤
红葡萄酒品质数据集winequality_red,共1599个样本。
[0131]
每类样本比例为1:20.94:3.44,少数类表示品质非常差(3~4分)和品质非常高(7~8分)的酒种。
[0132]
⑥
白葡萄酒品质数据集winequality_white,共4898个样本。
[0133]
每类样本比例为1:19.97:5.79,少数类表示品质非常差(3~4分)和品质非常高(7~9分)的酒种。
[0134]
⑦
银行数据集bank,共4521个样本。
[0135]
每类样本比例为1:7.68,少数类表示会定期存款的用户。
[0136]
⑧
德国人信用数据集germancredit,共1000个样本。
[0137]
每类样本比例为1:2.33,少数类表示信用不佳的用户。
[0138]
从上述数据集的简单描述可以看出,这些数据集都带有一些不同程度的数据不平
衡问题,且在这些实际情况中,也印证了“少数类样本往往更加受到关注”的观点,比如存在信用风险的用户、品质上佳的葡萄酒、避孕产品的潜在消费者等等。
[0139]
下面通过对比基分类器(基分类器的学习模型采用决策树)、并行集成范式中的经典算法bagging以及本发明所描述的方法,以下简称“动态贝叶斯组合方法”(图例中标记为dynamicbayesian)在以上8个数据集上的性能表现,分析图表来说明动态贝叶斯组合方法的优势。涉及对比的性能指标有准确率、g-mean以及少数类的平均召回率等。其中动态选择环节的评价指标采用了基分类器在验证集邻域上的分类器准确率和g-mean。
[0140]
分析上面得到的实验结果,可以总结出以下结论:
[0141]
(1)分析图6(a)和图6(b),从总体准确率这一指标来看三种模型,经典的并行集成算法bagging在绝大多数数据集上都能取得比另外两种模型更高的准确率。在以准确率作为选择指标时,本发明的动态贝叶斯组合算法(下简记为“db”算法)也能取得比基分类器稍高一些的准确率,除了在两个葡萄酒数据集这种不平衡程度非常高的问题上。在以g-mean作为选择指标时,db算法在blood、haberman、bank数据集上的准确率略低于基分类器。总的来说,db算法在准确率这一指标上,和基分类器持平甚至略优于基分类器,但不及bagging算法。正如上文介绍到,在数据不平衡的场景中,准确率只能作为一个参考,从另一方面也印证了其他算法在数据不平衡问题中准确率“虚高”的现象。图6(a)和图6(b)说明了为了追求更优秀的少数类识别能力,db算法的准确率并没有受到影响,甚至还略优于基分类器。
[0142]
(2)分析图7(a)和图7(b),两张子图清晰地说明了,无论是选用准确率还是g-mean作为分类器的选择指标,db算法所取得的g-mean都较大幅度领先于另外两种模型。以8个数据集的平均值计算,在准确率作为选择指标时,db平均领先基分类器16.69%,平均领先bagging算法15.81%;在g-mean作为选择指标时,db平均领先基分类器17.93%,平均领先bagging算法17.10%。此外,经典的bagging算法应用于两个葡萄酒数据集这种不平衡程度非常高的问题上时,会拉低g-mean这一指标,说明此时的bagging算法实质上是扩大了数据不平衡问题的影响,它提高了多数类的识别效果,却使得少数类的识别效果更加糟糕。
[0143]
(3)分析图8(a)和图8(b),将每个数据集上少数类样本的类召回率进行平均,更加印证了结论2中的说法:db算法提升了少数类样本的识别效果,能够找出更多待预测样本中稀有、高价值的少数类样本;而bagging在多数情况下对少数类的识别能力甚至不如基分类器,它扩大了数据不平衡问题的影响。另外还能从图8(a)和图8(b)中看到不同选择指标对于少数类识别效果的影响,采用g-mean作为分类器的选择指标比采用准确率作为分类器的选择指标能够获得更高的少数类召回率。(这在理论上也可以得到解释,更高g-mean的基分类器肯定比更高准确率的基分类器有着更强识别少数类样本的能力)但从结论1中也得知,以gmean作为选择指标的db算法在准确率上又不及以准确率作为识别指标的db算法,所以到底以何种指标来选择基分类器应该结合实际需求。
[0144]
以上3点结论,充分说明了本发明所描述的基于动态选择和贝叶斯理论的一种数据不平衡目标识别方法应用在数据不平衡的实际场景中,有优于传统统计学习模型(决策树)和经典集成学习算法(bagging)的识别能力。
[0145]
在基于本方法应用于数据不平衡问题的识别时,需要主观地或者基于先验知识设定一些参数,下面对这些参数的设置给出一些意见和说明:
[0146]
在生成基分类器集合这一环节,设置基分类器集合中基分类器的数量为21(这是
为了应对一般的二分类问题,使bagging算法中的投票环节不至于出平票);基分类器在训练集上的随机抽样比例randomfactor=0.5。
[0147]
在动态选择这一环节,验证集上的邻域样本数目为即取1/10离待预测样本最近的验证集样本作为评价基分类器的邻域。这一参数可以根据实际问题的数据集规模大小进行调整。
[0148]
基分类器组合环节的类先验概率p(ω
l
)的设置:由于p(ω
l
)往往难以得到,所以在这里提出两个如何设定各类样本先验概率的建议方法:(1)如果认为数据不平衡的根本原因是本来可以获取更多的少数类样本而因为各种原因没有条件获取少数类样本,那么可以将每类样本出现的先验概率设定为即各类出现的概率均等;(2)反之,如果认为数据不平衡的根本原因是少数类样本本就非常稀有(比如罕见病病例,珍稀矿石等),此时可以根据现有的知识自行设定p(ωi),或者也可以根据已有数据集所含的先验信息来设定p(ωi)(前提是现有的数据能够较好地反应各类样本的真实分布)。在实验中设置为
[0149]
此外,对实验环境做一些补充说明:采取10次9折交叉验证实验,基分类器模型采用决策树。
[0150]
本发明另一实施例还提出一种数据不平衡目标识别系统,包括:
[0151]
训练集基分类器集合生成模块,用于由训练集样本生成基分类器集合;
[0152]
混淆概率矩阵求取模块,用于将训练集样本生成的基分类器集合作用于验证集上,求取每个基分类器的混淆概率矩阵;
[0153]
待预测样本基分类器集合优选模块,用于动态为每个待预测样本优选一个基分类器集合;
[0154]
贝叶斯组合预测模块,用于依据得到的每个基分类器的混淆概率矩阵,基于贝叶斯理论组合所优选基分类器集合的输出结果,得到待预测样本一个最终的预测类别。
[0155]
一种电子设备,包括:
[0156]
存储器,存储至少一个指令;及
[0157]
处理器,执行所述存储器中存储的指令以实现所述的数据不平衡目标识别方法。
[0158]
一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现所述的数据不平衡目标识别方法。
[0159]
示例性的,所述存储器中存储的指令可以被分割成一个或多个模块/单元,所述一个或者多个模块/单元被存储在计算机可读存储介质中,并由所述处理器执行,以完成本发明所述的数据不平衡目标识别方法。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机可读指令段,该指令段用于描述所述计算机程序在服务器中的执行过程。
[0160]
所述电子设备可以是智能手机、笔记本、掌上电脑及云端服务器等计算设备。所述电子设备可包括,但不仅限于,处理器、存储器。本领域技术人员可以理解,所述电子设备还可以包括更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述电子设备还可以包括输入输出设备、网络接入设备、总线等。
[0161]
所述处理器可以是中央处理单元(central processing unit,cpu),还可以是其他通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现成可编程门阵列(field-programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0162]
所述存储器可以是所述服务器的内部存储单元,例如服务器的硬盘或内存。所述存储器也可以是所述服务器的外部存储设备,例如所述服务器上配备的插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)等。进一步地,所述存储器还可以既包括所述服务器的内部存储单元也包括外部存储设备。所述存储器用于存储所述计算机可读指令以及所述服务器所需的其他程序和数据。所述存储器还可以用于暂时地存储已经输出或者将要输出的数据。
[0163]
需要说明的是,上述模块单元之间的信息交互、执行过程等内容,由于与方法实施例基于同一构思,其具体功能及带来的技术效果,具体可参见方法实施例部分,此处不再赘述。
[0164]
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将所述装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。实施例中的各功能单元、模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中,上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。另外,各功能单元、模块的具体名称也只是为了便于相互区分,并不用于限制本技术的保护范围。上述系统中单元、模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0165]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术实现上述实施例方法中的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质至少可以包括:能够将计算机程序代码携带到拍照装置/终端设备的任何实体或装置、记录介质、计算机存储器、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、电载波信号、电信信号以及软件分发介质。例如u盘、移动硬盘、磁碟或者光盘等。
[0166]
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。
[0167]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围,均应
包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1