土壤重金属污染风险区划分方法、装置、电子设备及介质
1.本发明属于环境污染评价技术领域,具体涉及一种区域土壤重金属污染风险区划分方法、装置、电子设备及介质。
背景技术:
2.土壤是地球生态系统的重要组成部分、人类赖以生存的自然资源,在人类的生产生活中占据着至关重要的位置。土壤重金属污染关系国家粮食安全和人民身体健康,污染风险区的准确划分是开展土壤重金属污染风险评估、风险管控及修复治理的重要基础性工作。
3.土壤重金属的空间分布受自然和人为多种因素综合影响,是具有高度异质性的复合体。目前,土壤重金属污染风险区划分普遍采用地统计空间插值方法,旨在利用有限的采样点数据的空间相关性,对非采样点处的土壤重金属含量进行无偏最优估计,这不仅要求采样数据真实且具有代表性,采样点的数量更是至关重要。理论上,提高采样密度可获得高精度空间数据信息,然而对于土壤重金属检测,检测精度和准确性较高的实验室检测法具有检测周期长、工作繁琐的问题,因此,采样密度越高,所需的人力、物力、财力和时间越多,土壤重金属污染风险区划分的成本越高。
技术实现要素:
4.本发明所要解决的技术问题在于针对上述现有技术的不足,提供了一种区域土壤重金属污染风险区划分方法、装置、电子设备及介质。该划分方法能够提高土壤重金属采样检测数据的利用效率,实现土壤重金属污染风险区划边界准确度的有效提高、而且还无需提高采样密度,减少人力、财力、物力和时间的耗费,
5.为解决上述技术问题,本发明采用的技术方案是:一种区域土壤重金属污染风险区划分方法,包括:
6.根据待划分风险区域内各采样点的土壤重金属含量计算各采样点的土壤重金属污染风险等级;
7.获取所述待划分风险区域的重要因素的空间连续分布数据,所述重要因素影响土壤重金属时空分布,再从所述空间连续分布数据中提取所述各采样点的重要影响因素值;
8.将所述各采样点的坐标位置与各采样点的土壤重金属污染风险等级和重要影响因素值的一一映射,整合映射后的各采样点数据生成土壤重金属污染风险区划分采样点数据集;
9.将所述土壤重金属污染风险区划分采样点数据集划分为训练集和测试集,构建基于随机森林算法的土壤重金属污染风险等级预测模型;
10.计算所述影响土壤重金属时空分布的重要因素间的相关性,结合所述相关性和所述基于随机森林算法的土壤重金属污染风险等级预测模型产生的因素重要性,筛选最优因素,生成最优输入变量集;
11.优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,将所述最优参数组和所述最优输入变量集输入基于随机森林算法的土壤重金属污染风险等级预测模型,生成优化的土壤重金属污染风险等级预测模型;
12.提取代表所述待划分风险区域的规则间隔点集,利用所述优化的土壤重金属污染风险等级预测模型计算所述规则间隔点集的风险等级,优化处理由所述规则间隔点集的风险等级数据生成所述待划分区域的土壤重金属污染多级风险区。
13.进一步地,计算所述待划分风险区域各采样点的土壤重金属污染风险等级,包括:按照土壤重金属污染风险评价方法,根据所述各采样点的土壤重金属含量计算其土壤重金属污染风险值;根据所述土壤重金属污染风险评价方法的风险等级阈值评估所述各采样点的风险等级。
14.进一步地,所述影响土壤重金属时空分布的重要因素包括自然因素和人为因素,自然因素至少包括海拔、坡度、坡向和土壤类型,人为因素至少包括土地利用类型、与居住区、道路和河流的距离。
15.进一步地,获取所述待划分风险区域的重要因素的空间连续分布数据的方法,包括:
16.基于dem数据提取待划分风险区域的海拔、坡度和坡向数据;
17.栅格化待划分风险区域的土壤类型和土地利用类型数据;
18.基于待划分风险区域的土地利用类型数据计算所述各采样点与居住区、道路和河流的距离的数据。
19.进一步地,提取所述各采样点的重要影响因素值,包括:将所述各采样点叠加到影响土壤重金属时空分布的重要因素的空间连续分布数据,按照所述各采样点的坐标位置提取所述各采样点的土壤重金属时空分布的重要影响因素值。
20.进一步地,优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,包括:
21.按照设定的参数空间建立参数字典,对所述参数字典的重要参数采用循环嵌套、逐一遍历的优化模式,在未优化参数中选择一个作为待优化参数,固定已优化参数值,设定其他未优化参数值;
22.其中,待优化参数的遍历循环优化过程具体包括:利用参数随机搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,以生成的最优参数组为标准更新参数范围,形成优化参数字典;再按照所述优化参数字典,利用参数网格搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,生成所述模型的最优参数组;
23.其中,所述重要参数至少包括:决策树个数、最大特征数和最大深度。
24.进一步地,提取代表所述待划分风险区域的规则间隔点集,包括:按照设定距离创建覆盖所述待划分风险区域的规则网格;提取网格中心点生成代表所述待划分风险区域的规则间隔点集;计算所述规则间隔点集的坐标位置,提取所述规则间隔点集的土壤重金属时空分布的重要影响因素值。
25.进一步地,优化处理所述规则间隔点集的风险等级数据生成所述待划分区域的土壤重金属污染多级风险区,包括:空间连接所述规则间隔点集的风险等级至所述规则格网;
按照所述规则格网各格网单元的风险等级融合相邻格网单元,按照设定规则消除细小格网单元,生成多级风险区划多边形;按照设定容差平滑所述多级风险区划多边形边界。
26.根据本发明的另一个方面,提供一种区域土壤重金属污染风险区划分装置,包括:计算模块,用于根据待划分风险区域内各采样点的土壤重金属含量计算各采样点的土壤重金属污染风险等级;提取模块,用于获取所述待划分风险区域的重要因素的空间连续分布数据,所述重要因素影响土壤重金属时空分布,再从所述空间连续分布数据中提取所述各采样点的重要影响因素值;第一生成模块,用于将所述各采样点的坐标位置与各采样点的土壤重金属污染风险等级和重要影响因素值的一一映射,整合映射后的各采样点数据生成土壤重金属污染风险区划分采样点数据集;训练模块,用于将所述土壤重金属污染风险区划分采样点数据集划分为训练集和测试集,构建基于随机森林算法的土壤重金属污染风险等级预测模型;第一优化模块,用于计算所述影响土壤重金属时空分布的重要因素间的相关性,结合所述相关性和所述基于随机森林算法的土壤重金属污染风险等级预测模型产生的因素重要性,筛选最优因素,生成最优输入变量集;第二优化模块,用于优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,将所述最优参数组和所述最优输入变量集输入基于随机森林算法的土壤重金属污染风险等级预测模型,生成优化的土壤重金属污染风险等级预测模型;第二生成模块,用于提取代表所述待划分风险区域的规则间隔点集,利用所述优化的土壤重金属污染风险等级预测模型计算所述规则间隔点集的风险等级,优化处理由所述规则间隔点集的风险等级数据生成所述待划分区域的土壤重金属污染多级风险区。
27.进一步地,所述优化模块还包括:第一优化单元,用于利用参数随机搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,以生成的最优参数组为标准更新参数范围,形成优化参数字典;第二优化单元,用于按照所述优化参数字典,利用参数网格搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,生成所述模型的最优参数组。
28.根据本发明的另一个方面,提供一种电子设备,所述电子设备包括:
29.至少一个处理器;以及,
30.与所述至少一个处理器通信连接的存储器;其中,
31.所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的区域土壤重金属污染风险区划分方法。
32.根据本发明的另一个方面,提供一种计算机可读存储介质,其存储有计算机指令,所述计算机指令被操作以执行所述的区域土壤重金属污染风险区划分方法。
33.本发明与现有技术相比具有以下优点:
34.1、本发明充分利用易获取的影响土壤重金属时空分布的重要因素,能够有效提高土壤重金属污染风险区划分的准确度,解决现有方法中地统计空间插值方法对采样点代表性和数量的依赖性强问题。优化后的土壤重金属污染风险等级预测模型的建立,提高了对真实存在的土壤重金属含量极值等异常值和噪声值的容忍度,更适用于受人为因素影响较大、空间变异性强、异常值真实存在、且通常呈非正态分布的土壤重金属污染风险区的划分,通过预测结果的优化处理,进一步实现了土壤重金属污染风险区划边界精准度的有效
提高。
35.下面通过附图和实施例对本发明的技术方案作进一步的详细说明。
附图说明
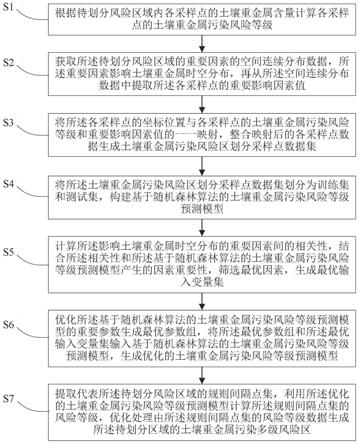
36.图1是本技术实施例的一种区域土壤重金属污染风险区划分方法流程示意图;
37.图2是图1中计算待划分风险区域各采样点的土壤重金属污染风险等级的方法流程示意图;
38.图3是图1中优化基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组的方法流程示意图;
39.图4是根据本技术实施例的一种区域土壤重金属污染风险区划分装置结构示意图。
具体实施方式
40.如图1所示,本技术实施例的一种区域土壤重金属污染风险区划分方法该方法包括如下步骤:
41.步骤s1,根据待划分风险区域内各采样点的土壤重金属含量计算各采样点的土壤重金属污染风险等级。
42.步骤s2,获取所述待划分风险区域的重要因素的空间连续分布数据,所述重要因素影响土壤重金属时空分布,再从所述空间连续分布数据中提取所述各采样点的重要影响因素值。
43.步骤s3,将所述各采样点的坐标位置与各采样点的土壤重金属污染风险等级和重要影响因素值的一一映射,整合映射后的各采样点数据生成土壤重金属污染风险区划分采样点数据集。
44.步骤s4,将所述土壤重金属污染风险区划分采样点数据集划分为训练集和测试集,构建基于随机森林算法的土壤重金属污染风险等级预测模型。
45.步骤s5,计算所述影响土壤重金属时空分布的重要因素间的相关性,结合所述相关性和所述基于随机森林算法的土壤重金属污染风险等级预测模型产生的因素重要性,筛选最优因素,生成最优输入变量集。
46.步骤s6,优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,将所述最优参数组和所述最优输入变量集输入基于随机森林算法的土壤重金属污染风险等级预测模型,生成优化的土壤重金属污染风险等级预测模型。
47.步骤s7,提取代表所述待划分风险区域的规则间隔点集,利用所述优化的土壤重金属污染风险等级预测模型计算所述规则间隔点集的风险等级,优化处理由所述规则间隔点集的风险等级数据生成所述待划分区域的土壤重金属污染多级风险区。
48.通过步骤s1至步骤s7,计算待划分风险区域各采样点的土壤重金属污染风险等级,获取各采样点的影响土壤重金属时空分布的重要因素值,筛选最优因素,生成最优输入变量集,并且优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,在利用最优输入变量集和最优参数组输入基于随机森林的土壤重金属污染风险等级预测模型,生成优化的土壤重金属污染风险等级预测模型,提取代表待划分风
险区域的规则间隔点集并计算各点处的土壤重金属污染风险等级,优化处理计算结果生成区域土壤重金属污染多级风险区。
49.通过上述方法,达到了区域土壤重金属污染风险区精确划分的目的,充分利用易获取的影响土壤重金属时空分布的重要因素,实现了提高区域土壤重金属污染风险区划分精度的技术效果,进而解决了由于采样点代表性差、数量少导致的预测精度低的技术问题。
50.图2是图1中步骤s1中计算待划分风险区域各采样点的土壤重金属污染风险等级的方法流程示意图,如图2所示,本实施例提供的待划分风险区域各采样点的土壤重金属污染风险等级的计算,可以包括:
51.步骤s11,按照土壤重金属污染风险评价方法,根据所述各采样点的土壤重金属含量计算其土壤重金属污染风险值;
52.步骤s12,根据所述土壤重金属污染风险评价方法的风险等级阈值评估所述各采样点的风险等级。
53.具体地,这里的土壤重金属污染风险评价方法包括背景值法、单因子污染指数法、内梅罗综合指数法、地累积指数法、潜在生态危害指数法、污染负荷指数法、模糊数学法、回归过量分析法等。首先,按照土壤重金属污染风险评价方法,根据各采样点的土壤重金属含量计算其土壤重金属污染风险值。然后,根据土壤重金属污染风险评价方法的风险等级阈值评估各采样点的风险等级。
54.作为一种可选的实施方式,步骤s2中获取所述待划分风险区域的重要因素的空间连续分布数据的方法,可以包括:
55.步骤s21,基于dem数据提取待划分风险区域的海拔、坡度和坡向数据。
56.步骤s22,栅格化待划分风险区域的土壤类型和土地利用类型数据。
57.步骤s23,基于待划分风险区域的土地利用类型数据计算所述各采样点与居住区、道路和河流的距离。
58.具体地,这里的影响土壤重金属时空分布的重要因素包括自然因素和人为因素,自然因素至少包括海拔、坡度、坡向和土壤类型,人为因素至少包括土地利用类型、与居住区、道路和河流的距离。步骤s21,通过地理空间数据云平台下载待划分区域的dem(数字高程)数据,应用arcgis 空间分析模块提取坡度和坡向数据。步骤s23中各采样点与居住区、道路和河流的距离,是基于采样点位置和待划分风险区域的土地利用矢量数据,应用arcgis邻域分析模块的近邻分析算法计算得到。
59.作为一种可选的实施方式,步骤s2中提取所述各采样点的重要影响因素值中,可以包括:将所述各采样点叠加到影响土壤重金属时空分布的重要因素的空间连续分布数据,按照所述各采样点的坐标位置提取所述各采样点的土壤重金属时空分布的重要影响因素值。
60.具体地,首先,叠加各采样点及影响土壤重金属时空分布的重要因素的空间连续分布数据,应用arcgis空间分析模块的提取值到点工具,分别提取各采样点坐标位置处土壤重金属时空分布的重要影响因素的值。然后,根据各采样点坐标位置创建多列组合唯一索引,根据唯一索引建立各采样点坐标与各采样点土壤重金属含量和影响因素值的一一映射,整合映射后的各采样点数据生成土壤重金属污染风险区划分采样点数据集。
61.图3是图1中优化土壤重金属污染风险等级预测模型的重要参数的方法流程示意
图,如图3所示,本实施例提供的优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,包括:
62.按照设定的参数空间建立参数字典,对所述参数字典的重要参数采用循环嵌套、逐一遍历的优化模式,在未优化参数中选择一个作为待优化参数,固定已优化参数值,设定其他未优化参数值;
63.其中,待优化参数的遍历循环优化过程具体包括:
64.s61,利用参数随机搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,以生成的最优参数组为标准更新参数范围,形成优化参数字典;
65.s62,按照所述优化参数字典,利用参数网格搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,生成所述模型的最优参数组;
66.具体地,所述重要参数至少包括:决策树个数、最大特征数和最大深度。首先,将土壤重金属污染风险区划分采样点数据集划分为训练集和测试集,构建基于随机森林的土壤重金属污染风险等级预测模型。然后,计算土壤重金属时空分布的重要影响因素间的相关性,结合因素间的相关性和由所述基于随机森林算法的土壤重金属污染风险等级预测模型产生的因素重要性,筛选最优因素,生成最优输入变量集。这里因素间的相关性度量指标包括但不限于person相关系数、spearman相关系数等。在步骤 s6优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,将生成的最优参数组和最优输入变量集输入s4 中的基于随机森林算法的土壤重金属污染风险等级预测模型,生成优化的土壤重金属污染风险等级预测模型。这里参数字典的内容包括各参数的名称、数据类型和参数取值范围等参数描述信息。
67.作为一种可选的实施方式,步骤s7提取代表所述待划分风险区域的规则间隔点集,可以包括:
68.s711,按照设定距离创建覆盖所述待划分风险区域的规则网格。
69.s712,提取s711中所述规则网格中心点生成代表所述待划分风险区域的规则间隔点集。
70.s713,计算s712中所述规则间隔点集的坐标位置,提取所述规则间隔点集的土壤重金属时空分布的重要影响因素值。
71.具体地,在步骤s711至步骤s713中,首先,按照设定距离创建覆盖待划分风险区域的规则网格,这里设定距离可以是全域等距离、也可以是不等距离。然后,应用arcgis几何计算功能提取规则网格的各网格中心点,生成代表待划分风险区域的规则间隔点集,计算规则间隔点集中各点的坐标位置,应用步骤s2的方式提取规则间隔点集中各点的土壤重金属时空分布的重要影响因素值。
72.作为一种可选的实施方式,步骤s6优化处理所述规则间隔点集的风险等级数据生成所述待划分区域的土壤重金属污染多级风险区,可以包括:
73.步骤s621,空间连接s612中所述规则间隔点集的风险等级至s611 中所述规则网格。
74.步骤s622,按照所述规则网格中各格网单元的风险等级融合相邻格网单元,按照设定规则消除细小格网单元,生成多级风险区划多边形。
75.步骤s623,按照设定容差平滑所述多级风险区划多边形边界。
76.具体地,在步骤s621至步骤s623中,首先,利用空间连接将规则间隔点集的风险等级连接至与其一一对应的规则格网的各格网单元,应用 arcgis数据管理工具的消除模块融合风险等级相同的相邻格网单元。然后,按照设定规则消除细小格网单元,生成多级风险区划多边形,这里的设定规则包括面积小于设定值和/或边长小于特定值。最后,按照设定容差平滑所述多级风险区划多边形边界,这里的容差可以是距离或像素。
77.图4是本实施例提供的一种区域土壤重金属污染风险区划分装置结构示意图,如图4所示,本实施例提供的区域土壤重金属污染风险区划分装置包括:
78.计算模块41,用于计算待划分风险区域各采样点的土壤重金属污染风险等级;
79.提取模块42,用于获取所述待划分风险区域的影响土壤重金属时空分布的重要因素的空间连续分布数据,提取所述各采样点的重要影响因素值;
80.第一生成模块43,用于根据所述各采样点坐标位置创建多列组合唯一索引,建立所述各采样点与土壤重金属含量及其影响因素值的一一映射,汇集映射后的各采样点数据生成土壤重金属污染风险区划分采样点数据集;
81.训练模块44,用于将所述土壤重金属污染风险区划分采样点数据集划分为训练集和测试集,构建基于随机森林的土壤重金属污染风险等级预测模型;
82.第一优化模块45,用于计算所述影响土壤重金属时空分布的重要因素间的相关性,结合所述相关性和所述基于随机森林算法的土壤重金属污染风险等级预测模型产生的因素重要性,筛选最优因素,生成最优输入变量集;
83.第二优化模块46,用于优化所述基于随机森林算法的土壤重金属污染风险等级预测模型的重要参数生成最优参数组,将所述最优参数组和所述最优输入变量集输入基于随机森林算法的土壤重金属污染风险等级预测模型,生成优化的土壤重金属污染风险等级预测模型;
84.第二生成模块47,用于提取代表所述待划分风险区域的规则间隔点集,利用所述优化的土壤重金属污染风险等级预测模型计算所述规则间隔点集的风险等级,优化处理所述规则间隔点集的风险等级数据生成所述待划分区域的土壤重金属污染多级风险区。
85.可选的,所述第二优化模块还包括:第一优化单元461,用于利用参数随机搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,以生成的最优参数组为标准更新参数范围,形成优化参数字典;第二优化单元462,用于按照所述优化参数字典,利用参数网格搜索交叉验证的方式训练所述基于随机森林算法的土壤重金属污染风险等级预测模型,生成所述模型的最优参数组。
86.具体地,本实施例中各模块的作用及相应的操作流程和方法与上述方法类实施例是一一对应的,在此不再赘述。
87.本实施例还提供一种电子设备,所述电子设备包括:至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的区域土壤重金属污染风险区划分方法。
88.本实施例还提供一种计算机可读存储介质,其存储有计算机指令,所述计算机指令被操作以执行所述的区域土壤重金属污染风险区划分方法。
89.在本发明所提供的几个实施例中,应该理解到,所揭露的设备,装置和方法,可以
通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
90.所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。
91.另外,在本发明各个实施例中的各功能模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能模块的形式实现。
92.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。
93.因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本发明内。不应将权利要求中的任何附关联图标记视为限制所涉及的权利要求。
94.此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。系统权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第二等词语用来表示名称,而并不表示任何特定的顺序。
95.最后应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或等同替换,而不脱离本发明技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1