一种提高图像分辨率的方法
1.本发明涉及一种图像优化方法,特别是一种提高图像分辨率的方法。
背景技术:
2.近几年,随着深度学习的迅猛发展,计算机视觉任务取得了非常好的效果。当前互联网上产生了大量图片,在社交媒体、新闻网页、电商购物网站等场所都存在着海量图片,图片已经成为我们每个人生活中不可或缺的角色。然而,由于各种原因,包括原始拍摄分辨率比较低、经过多次传输后质量变低等,互联网上图片的分辨率往往是非常低的,这不仅使得我们观看的视觉体验不好,甚至可能有一些关键信息无法准备判断。所以提高图片的分辨率具有非常重要的意义。
3.传统的提高图片分辨率的手段包括使用photoshop等软件编辑图片来提高图片分辨率。然而这些软件需要使用者具有一定的专业技能才能熟练使用,而且人工p图需要耗费很多时间和精力,往往效率不高。这种情况下使用机器去自动提高图像的分辨率就可以有效提高工作效率,而且,通过合适的深度学习算法,机器处理过的低分辨率图像,往往可以达到非常好的视觉效果。使用深度学习技术,只需要提前训练好一个图像超分辨率模型,这个模型体积很小,实际运行时资源占用适中,把低分辨率图像输入到训练好的模型中,就能得到更好分辨率的图像,高分辨图像有着更好的观感,能有效提升观看体验。
技术实现要素:
4.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种提高图像分辨率的方法。
5.为了解决上述技术问题,本发明公开了一种提高图像分辨率的方法,包括以下步骤:
6.步骤1,使用div2k数据集训练图像超分辨率模型,图像超分辨率即为提高图像分辨率,从div2k数据集中的图片上随机裁剪48*48大小的图像块作为训练数据;
7.步骤2,使用卷积神经网络对所述图像块进行浅层特征提取,得到特征图;
8.步骤3,使用transformer块对特征图进行深层特征提取,得到新的特征图;
9.步骤4,使用像素重组方法对步骤3中得到的特征图进行图像重建,得到输出图像o;
10.步骤5,使用最小绝对值偏差损失函数计算输出图像o和高分辨率图像hr之间的差异,并使用adam优化器进行梯度下降;重复步骤1到步骤5共50万个轮次,得到最终的图像超分辨率模型;
11.步骤6,测试时,把低分辨率图像分成若干个96*96大小的图像块;
12.步骤7,将步骤6中的图形块依次输入到步骤5中所述图像超分辨率模型中,得到高分辨率的图像块;将得到的高分辨率图像块按照其在低分辨率图像中的顺序依次拼接起来,得到最终的高分辨率图像。
13.本发明中,步骤1包括:
14.所述训练数据集采用div2k数据集,该数据集包括高分辨率图像hr和低分辨率图像lr;其中,高分辨率图像数量800张,x2倍低分辨率图像、x3倍低分辨率图像和x4倍低分辨率图像各800张;
15.根据不同任务将高分辨率图像和低分辨率图像组成图像对;
16.其中,2倍图像超分辨率任务中,高分辨率图像hr和x2倍低分辨率图像lr图像组成图像对;
17.3倍图像超分辨率任务中,高分辨率图像hr和x3倍低分辨率图像lr图像组成图像对;
18.4倍图像超分辨率任务中,高分辨率图像hr和x4倍低分辨率图像lr图像组成图像对;
19.训练批量大小batch size设为32,即图像超分辨率模型训练过程中一次性处理32张图像块。
20.本发明中,所述步骤2包括:
21.训练过程中的图像块的长和宽设为48,则输入的图像数据x的维度为[32,3,48,48],其中3代表图像的通道数是3,即rgb3个通道;
[0022]
对于输入的图像数据x,使用卷积神经网络进行浅层特征提取,得到特征图f1,f1的维度为[32,180,48,48];该过程如下:
[0023]
f1=cnn(x)
[0024]
其中,该过程的卷积神经网络cnn包含一个3x3的卷积,其输入维度为3,输出维度为180,卷积核大小为3,边缘填充像素个数为1,步长为1。
[0025]
本发明中,所述步骤3包括:
[0026]
将步骤2得到的特征图f1输入到transformer块进行深层特征提取,输出为一个新的特征图f2,其维度为[32,180,48,48];该过程包括以下步骤:
[0027]
步骤3-1,输入特征图f1的维度为[32,180,48,48],使用flatten操作将其维度转换为[32,180,2304];使用transpose操作将其维度转换为[32,2304,180],操作完成之后,得到矩阵x0,该过程如下:
[0028]
x0=f1.flatten(-2).transpose(-1,-2)
[0029]
其中,flatten操作是把矩阵展平,transpose操作是矩阵转置;
[0030]
步骤3-2,将x0输入位置编码卷积神经网络poscnn来计算x0的位置编码,位置编码卷积神经网络使用3x3的卷积实现,该卷积的输入维度为180,输出维度为180,卷积核大小为3,边缘填充像素个数为1,步长为1,组数为180;使用位置编码卷积神经网络得到x0的位置编码pos,位置编码pos的维度也是[32,2304,180],然后将位置编码pos和x0相加,得到矩阵x1,该过程表示如下:
[0031]
pos=poscnn(x0)
[0032]
x1=x0+pos;
[0033]
步骤3-3,把x1输入到transformer块中,transformer块一共包含36个transformer层结构,每个transformer层结构由2部分组成,第一部分是多头注意力方法msa或者高效全局多头注意力方法ewmsa,第二部分是多层感知机方法mlp;按照每个
transformer layer的序号(1,2
…
,36),如果是奇数,则第一部分是msa,如果是偶数,则第一部分是ewmsa;每个transformer层结构的计算过程如下:
[0034]
x2=msa(ln(x1))+x1…
(1)或者x2=ewmsa(ln(x1))+x1…
(2)
[0035]
f2=mlp(ln(x2))+x2…
(3)
[0036]
其中,msa表示multi-head self-attention方法,即多头注意力方法;ewmsa表示effective wide-area multi-head self-attention方法,即高效全局多头注意力方法;ln代表layernorm操作,即层归一化操作;mlp代表multi-layer perceptron方法,即多层感知机方法;经过transformer块方法处理得到的新的特征图f2的维度为[32,180,48,48];
[0037]
步骤3-4,把特征图f1和f2通过残差连接相加到一起,融合特征图f1和f2的特征,得到特征图f3,该过程表示如下:
[0038]
f3=f1+conv(f2)
[0039]
其中,该过程中的conv表示卷积操作,该卷积的输入维度为180,输出维度为180,卷积核大小为3,边缘填充像素个数为1,步长为1。
[0040]
本发明中,所述步骤4包括:
[0041]
将步骤3中得到的特征图f3采用像素重组方法进行上采样;该过程具体包括三个操作,分别是conv_before_upsample处理,upsample处理,conv_last处理;其中conv_before_upsample是一个卷积操作,upsample是上采样操作,conv_last也是一个卷积操作。特征图f3的维度为[32,180,48,48],经过像素重组方法处理之后,得到的输出图像o的维度为[32,180,96,96],其对应的高分辨率图像的维度为[32,180,96,96];该过程表示如下:
[0042]
f4=conv_before_upsample(f3)
[0043]
f5=upsample(f4)
[0044]
o=conv_last(f5)
[0045]
其中,f4和f5都表示计算中间步骤得到的特征图。
[0046]
本发明中,所述步骤5包括如下步骤:
[0047]
步骤5-1,使用最小绝对值偏差损失函数l1计算输出图像o和其对应的高分辨率图像hr之间的差异loss;该过程表示如下:
[0048]
loss=l1(o,hr)。
[0049]
本发明中,所述步骤5包括如下步骤:
[0050]
步骤5-2,使用adam优化器来更新网络参数,其中adam优化器的参数设置如下:
[0051]
learn rate=0.0002;weight decay=0;milestones=[250000,400000,450000,475000,500000];gamma=0.5。
[0052]
本发明中,所述步骤5包括如下步骤:
[0053]
步骤5-3,重复步骤1到步骤5共50万轮次,训练完成之后,得到最终的图像超分辨率模型m。
[0054]
本发明中,所述步骤6包括:
[0055]
准备低分辨率图像lr,测试时,低分辨率图像lr的分辨率是任意大小;将低分辨率图像lr划分成若干个大小为96*96的图像块,设最后得到n个大小为96*96的图像块,设这些图像块为xi,i=1,2
…
n,n是一个自然数。
[0056]
本发明中,所述步骤7包括如下步骤:
[0057]
步骤7-1,将步骤6得到的图像块依次输入到步骤5中得到的图像超分辨率模型m中;得到n个大小为192*192的图像块;设这些图像块为yi;方法如下:
[0058][0059][0060][0061][0062][0063][0064][0065][0066]
其中,表示第i个图像块经过卷积cnn处理之后得到的特征图,表示把特征图经过矩阵展平和矩阵转置操作之后得到的矩阵,表示矩阵加上为止编码之后得到的矩阵,表示经过mlp方法处理之后得到的特征图,表示特征图和特征图残差连接之后得到的特征图,表示经过cony_before_upsample操作处理之后得到的特征图,表示经过上采样操作之后得到的特征图,o表示经过conv_last操作之后得到的最终输出图像块;
[0067]
奇数层公式为:其中表示经过多头注意力机制操作之后得到的矩阵;
[0068]
偶数层公式为:其中表示经过高效全局多头注意力机制操作之后得到的矩阵;
[0069]
其中,transformer块方法中交替使用msa和ewmsa;即,奇数层使用的是奇数层公式(1)计算,偶数层使用的是偶数层公式(2);
[0070]
步骤7-2,步骤7-1得到n个高分辨率的图像块yi,将这n个高分辨率的图像块按照图像块xi在低分辨率图像lr中的顺序拼接在一起,得到最终的高分辨率图像y。
[0071]
有益效果:
[0072]
采用深度学习技术训练图像超分辨率模型,一旦训练完成得到最终的模型,就可以让机器自动处理低分辨率图片,得到高分辨率图片,使得图片的画质更高,观看体验更好,这可以极大提高处理效率。本发明中提出来的图像超分辨率模型包含更少的参数量,并且可以实现更好的图像重建效果。
附图说明
[0073]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
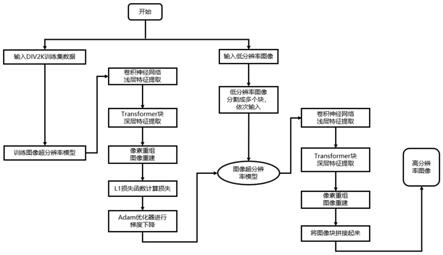
[0074]
图1是本发明实施例部分提供的一种提高图像分辨率的方法中训练和测试的工作流程示意图。
[0075]
图2是本发明实施例部分提供的一种提高图像分辨率的方法中采用的div2k数据
集结构示意图。
[0076]
图3是本发明实施例部分提供的一种提高图像分辨率的方法中div2k数据集低分辨率lr图像示意图。
[0077]
图4是本发明实施例部分提供的一种提高图像分辨率的方法中div2k数据集高分辨率hr图像示意图。
[0078]
图5是本发明实施例部分提供的一种提高图像分辨率的方法中测试时输入的低分辨率图片示意图。
[0079]
图6是本发明实施例部分提供的一种提高图像分辨率的方法中测试时模型输出的高分辨率图片示意图。
[0080]
图7是本发明实施例部分提供的一种提高图像分辨率的方法中测试时模型输出的高分辨率图片的部分细节示意图。
具体实施方式
[0081]
本发明公开了一种提高图像分辨率的方法,本方法应用于需要采用自动化手段提高图片的分辨率,使其视觉效果更好的场景。
[0082]
本发明提供一种提高图像分辨率的方法,包括以下步骤:
[0083]
步骤1,使用div2k数据集(div2k数据集为一个图像超分辨率数据集)训练图像超分辨率模型(图像超分辨率指的是提高图像分辨率),从div2k数据集中的图片上随机裁剪48*48大小的图像块作为训练数据;
[0084]
步骤2,使用卷积神经网络对所述图像块进行浅层特征提取,得到特征图;
[0085]
步骤3,使用transformer块对特征图进行深层特征提取,得到新的特征图;其中,transformer为一种深度学习网络结构;
[0086]
步骤4,使用像素重组方法对上一步得到的特征图进行图像重建,得到输出图像o;
[0087]
步骤5,使用最小绝对值偏差损失函数l1计算输出图像o和高分辨率图像hr之间的差异loss,并使用adam优化器(adam优化器为一种深度学习中常用的优化器)进行梯度下降。重复步骤1到步骤5共50万个轮次,得到最终的图像超分辨率模型m;
[0088]
步骤6,把低分辨率图像分成若干个96*96大小的图像块,将这些图形块依次输入到上面得到的图像超分辨率模型中;
[0089]
步骤7,上述图像块依次经过卷积神经网络浅层特征提取、transformer块深层特征提取和像素重组图像重建后,得到高分辨率的图像块;将得到的高分辨率图像块按照它们在低分辨率图像中的顺序依次拼接起来,得到最终的高分辨率图像。
[0090]
下面结合附图及实施例对本发明做进一步说明。
[0091]
本发明的一个实施例中,如图1所示,本发明方法所构建的提高图像分辨率的工作流程大致分为两大阶段:
[0092]
第一阶段,训练图像超分辨率模型,包括准备div2k数据集,如图2所示,每次从div2k数据集中选取32张低分辨率lr图片,其中每张lr图像如图3所示。然后分别从每张图片随机裁剪出大小为48*48的图像块,把这32个图像块作为一个batch进行训练。准备好训练数据之后,把batch输入到图像超分辨率模型中,依次经过卷积神经网络浅层特征提取、transformer块深层特征提取和像素重组图像重建得到输出o。然后使用最小绝对值偏差损
失函数l1计算输出图像o和高分辨率图像hr之间的差异,其中高分辨率图像如图4所示。最后使用adam优化器对整个网络的参数进行优化。上述过程需要重复50万次方可结束,训练完成之后得到最终的图像超分辨率模型m。
[0093]
第二阶段,使用第一阶段得到的图像超分辨率模型对输入图像进行处理,包括先把输入的低分辨率图像裁剪成若干个96*96大小的图像块,输入的低分辨率图像如图5所示。然后依次将这些图像块输入到图像超分辨率模型m中,这些图像块依次经过卷积神经网络浅层特征提取、transformer块深层特征提取和像素重组图像重建后可以得到若干个大小为192*192大小的图像块。然后将这些大小为192*192的图像块按照它们在输入图像中的顺序拼接在一起,就可以得到分辨率更高的输出图像,如图6所示。通过放大输出图像的部分区域,如图7所示,我们可以看到其相比输入的低分辨率图像的相同区域更加清晰。
[0094]
本实施例所述的一种提高图像分辨率的方法中,所述步骤1包括:
[0095]
所述训练数据集采用div2k数据集,所述div2k数据集包括高分辨率图像高分辨率和低分辨率图像lr,其中,高分辨率图像数量为800张,x2倍、x3倍、x4倍低分辨率图像各800张。以2倍图像超分辨率任务为例,高分辨率图像hr和x2倍lr图像组成图像对。训练批大小batch size设为32,即图像超分辨率模型训练过程中一次性处理32张图像块。
[0096]
本实施例所述的一种提高图像分辨率的方法中,所述步骤2包括:
[0097]
训练过程中的batch size设为32,patch size设为48,其中batchsize是模型一次性处理的图像块的个数,图像块大小patch size是图像块的长和宽。那么,输入的图像数据x的维度为[32,3,48,48],其中3代表图像的通道数是3,即rgb3个通道。对于输入数据x,首先使用卷积神经网络对x进行浅层特征提取,得到特征图f1,f1的维度为[32,180,48,48]。该过程可表示为如下公式:
[0098]
f1=cnn(x)
[0099]
该过程中的卷积神经网络方法cnn包含一个3x3的卷积,其输入维度为3,输出维度为180,卷积核大小为3,边缘填充像素个数为1,步长为1。
[0100]
本实施例所述的一种提高图像分辨率的方法中,所述步骤3包括如下步骤:
[0101]
将步骤2得到的特征图f1输入到transformer块进行深层特征提取,经过该方法处理之后,输出为一个新的特征图f2,其维度为[32,180,48,48]。该过程具体包括以下步骤:
[0102]
步骤3-1,输入特征图f1的维度为[32,180,48,48],首先使用flatten操作将其维度转换为[32,180,2304],然后再使用transpose操作将其维度转换为[32,2304,180]。该过程可表示为如下公式:
[0103]
x0=f1.flatten(-2).transpose(-1,-2)
[0104]
其中,flatten操作是把矩阵展平,transpose操作是矩阵转置。
[0105]
步骤3-2,将x0输入位置编码卷积神经网络poscnn来计算x0的位置编码,poscnn方法是使用3x3的卷积来实现的,该卷积的输入维度为180,输出维度为180,卷积核大小为3,边缘填充像素个数为1,步长为1,组数为180。使用poscnn得到x0的位置编码pos,pos的维度也是[32,2304,180],然后将pos和x0相加,得到x1,该过程可表示为如下公式:
[0106]
pos=poscnn(x0)
[0107]
x1=x0+pos
[0108]
步骤3-3,把x1输入到transformer块方法中,transformer块方法一共包含36个
transformer layer结构,每个transformer layer由2部分组成,第一部分是msa或者ewmsa,第二部分是mlp。按照每个transformer layer的序号(1,2
…
,36),如果是奇数,则第一部分是msa,如果是偶数,则第一部分是ewmsa。每个transformer layer的计算过程可由如下公式表示:
[0109]
x2=msa(ln(x1))+x1…
(1)或者x2=ewmsa(ln(x1))+x1…
(2)
[0110]
f2=mlp(ln(x2))+x2…
(3)
[0111]
其中,公式中的msa表示multi-head self-attention,即多头注意力机制方法,ewmsa表示effective wide-area multi-head self-attention,即高效全局多头注意力机制方法,ln代表layernorm操作,mlp代表multi-layer perceptron,即多层感知机。经过transformer块处理得到的f2的维度为[32,180,48,48]。
[0112]
步骤3-4,把特征图f1和f2通过残差连接相加到一起,融合f1和f2的特征,该过程可表示为如下公式:
[0113]
f3=f1+conv(f2)
[0114]
其中,该过程中的conv的输入维度为180,输出维度为180,卷积核大小为3,边缘填充像素个数为1,步长为1。
[0115]
本实施例所述的一种提高图像分辨率的方法中,所述步骤4包括:
[0116]
将步骤3中得到的f3输入像素重组方法进行上采样。该过程具体包括三个操作,分别是conv_before_upsample处理,upsample处理,conv_last处理。f3的维度为[32,180,48,48],经过像素重组方法处理之后,得到的输出o的维度为[32,180,96,96],其对应的高分辨率图像的维度为[32,180,96,96]。该过程可表示为如下公式:
[0117]
f4=conv_before_upsample(f3)
[0118]
f5=upsample(f4)
[0119]
o=conv_last(f5)
[0120]
本实施例所述的一种提高图像分辨率的方法中,所述步骤5包括如下步骤:
[0121]
步骤5-1,使用最小绝对值偏差损失函数计算输出o和其对应的高分辨率图像hr之间的差异loss。该过程可表示为如下公式:
[0122]
loss=l1(o,hr)
[0123]
步骤5-2,使用adam优化器来更新网络参数,其中adam优化器的一些主要参数设置如下所示:
[0124]
learn rate=0.0002;weight decay=0;milestones=[250000,400000,450000,475000,500000];gamma=0.5;
[0125]
步骤5-3,重复步骤1到步骤5共50万轮次,训练完成之后,得到最终的图像超分辨率模型m。
[0126]
本实施例所述的一种提高图像分辨率的方法中,所述步骤6包括如下步骤:
[0127]
准备好低分辨率图像lr,测试时,lr的分辨率是任意大小。将lr划分成若干个大小为96*96的图像块,假设最后得到n个大小为96*96的图像块,设这些图像块为xi(i=1,2
…
n)。
[0128]
本实施例所述的一种提高图像分辨率的方法中,所述步骤7包括如下步骤:
[0129]
步骤7-1,将步骤6得到的图像块依次输入到步骤5中得到的图像超分辨率模型m
中。该步骤将得到n个大小为192*192的图像块。设这些图像块为yi(i=1,2
…
n)。具体来说,该步骤可由以下公式表示:
[0130][0131][0132][0133]
或者
[0134][0135][0136][0137][0138][0139]
transformer块方法中交替使用msa和ewmsa。即,奇数层使用的是公式(1)和公式(3)计算,偶数层使用的是公式(2)和公式(3)。该步骤中符号的含义和步骤3中一样。
[0140]
步骤7-2,上述步骤得到n个高分辨率的图像块,分别为yi(i=1,2
…
n),将这n个高分辨率的图像块按照xi(i=1,2
…
n)在lr中的顺序拼接在一起,得到最后的高分辨率图像y,相比最开始的低分辨率图像lr,y有着更高的分辨率,更清晰的画面。
[0141]
在互联网上存在大量的图片,然后由于各种原因,很多图片的分辨率都比较低,这导致我们的观看体验不好,甚至有一些图片不能看清楚关键信息。所以提高图片分辨率有着很重要的意义。传统的方法如使用photoshop等软件处理图片往往需要操作人掌握比较专业的技能,且费时费力。而且得到的高分辨率图像的画质也不一样让人满意。采用深度学习技术训练图像超分辨率模型,一旦训练完成得到最终的模型,就可以让机器自动处理低分辨率图片,得到高分辨率图片,使得图片的画质更高,观看体验更好,这可以极大提高处理效率。
[0142]
具体实现中,本发明还提供一种计算机存储介质,其中,该计算机存储介质可存储有程序,该程序执行时可包括本发明提供的一种提高图片分辨率的方法的各实施例中的部分或全部步骤。所述的存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random access memory,ram)等。
[0143]
本领域的技术人员可以清楚地了解到本发明实施例中的技术可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明实施例中的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。
[0144]
本说明书中各个实施例之间相同相似的部分互相参见即可。以上所述的本发明实施方式并不构成对本发明保护范围的限定。
[0145]
本发明提供了一种提高图像分辨率的方法的思路及方法,具体实现该技术方案的
方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1