一种适用于分布式密码协议的随机数批量预处理系统的制作方法
1.本发明涉及密码学技术领域,特别涉及一种适用于分布式密码协议的随机数批量预处理系统。
背景技术:
2.随着空气污染和拥堵的加剧,越来越多的城市收紧机动车号牌的发放,而采用摇号的方式发放机动车牌照。现有的摇号算法有的采用集中式的,由单台计算机生成摇号结果,这导致摇号结果不被公众信服。有的摇号方法采用分布式,但性能不好,每次都是触发多次多方通信,很难大量生成随机数。
3.在企业举办的一些市场营销活动中,经常举办一些一二三等奖的抽奖活动。现在抽奖软件是单机执行的,与单机生成摇号结果一样,抽奖结果容易被抽奖方控制抽奖结果。参与活动的人总是担心大奖被内定,从而抑制了参与活动的积极性。
4.现代计算机编程语言几乎都提供了伪随机数生成算法,如java语言的java.util.random类。但计算机语言的随机数生成算法是中心化的,很容易受到攻击。受区块链去中心化思想、安全多方计算思想的影响,专家们设计了很多分布式随机数生成协议,其基本思想是随机数由多个参与方协商生成。每个参与方提供一个随机数,最终的随机数是由各方提供的随机数通过某种方式计算得到,类似于一种投票机制。
5.随机数分布式生成的意义在于,在n个参与方中只要存在一个诚实的参与方,最终生成的随机数仍然是“随机”的,最终随机数不受控制。即使n-1个参与方合谋,也无法控制生成的结果随机数。
6.分布式密码学以容错的方式在多个参与方之间传播密码系统的操作。考虑n方的门限故障模型,其中最多f方有故障;这种分布式密码系统称为门限密码系统。
7.分布式密码系统是以秘密共享为基础的,组成了能够容忍故障参与方的分布式协议。它们通常只用于公钥密码系统,因为它们具有“良好”的代数特性。
8.秘密共享是门限密码学的基础。在(f+1)-out-of-n中秘密共享方案中,有限域fq的一个元素s,在n个方之间共享,这样至少需要f+1方的合作才能恢复s。任何由f或更少的方组成的组不应获得关于s的任何信息。
9.以musig为代表的“多重”密码协议,是一种n-out-of-n门限密码方案,是一种简化方案,该方案要求所有参与方都参与计算。多重密码方案的特点是简单,而且不需要秘密分发者角色。
10.基于当前抽取随机数的过程中存在的问题,本发明提出了一种适用于分布式密码协议的随机数批量预处理系统。
技术实现要素:
11.本发明为了弥补现有技术的缺陷,提供了一种简单高效的适用于分布式密码协议的随机数批量预处理系统。
12.本发明是通过如下技术方案实现的:
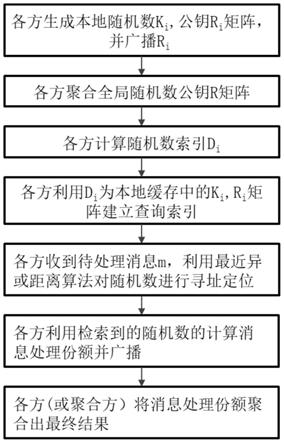
13.一种适用于分布式密码协议的随机数批量预处理系统,其特征在于:包括分布式集群,随机数聚合模块,随机数提取模块,寻址定位模块和消息份额处理模块;
14.所述分布式集群的各个节点分别生成本地随机数,u*v个随机数组成矩阵ki,随机数公钥矩阵ri,并广播ri;
15.所述随机数聚合模块将各个节点的随机数公钥聚合起来,成为u*v个全局随机数公钥,全局随机数公钥组成矩阵r:
16.所述分布式集群的各个节点利用r矩阵计算随机数索引,利用随机数索引将矩阵r、矩阵ri和矩阵ki的同一行标识和连接起来,保证各个节点使用同一行进行后续的密码计算;
17.所述寻址定位模块计算m的哈希与随机数id之间的距离,并找到距离最近的随机数id;
18.所述分布式集群的各个节点收到待处理的消息m后,通过随机数提取模块从本地缓存中提取随机数和随机数公钥;
19.所述分布式集群的各个节点通过消息份额处理模块计算检索到的随机数的消息处理份额,并广播,聚合得到最终结果。
20.所述分布式集群的n个节点生成u*v个随机数,组成矩阵ki,在本地缓存中保存;各节点利用公式(其中1≤i≤u,1≤j≤v))生成随机数公钥矩阵ri,各节点广播随机数公钥矩阵ri;所述分布式集群的节点pi的在本地缓存中保存随机数矩阵ki和随机数公钥矩阵ri,形式如下:
[0021][0022]
矩阵ki和矩阵ri的第一列是查询键(索引),后面的列是值(value),上标r(i)表示第i个节点生成的矩阵。
[0023]
所述随机数聚合模块利用公式或(1≤j≤v,1≤i≤u)将分布式集群的各个节点随机数公钥聚合起来,成为u*v个全局随机数公钥,全局随机数公钥组成矩阵r如下:
[0024][0025]
根据不同的分布式密码协议采用乘法或者加法进行聚合。乘法即全局随机数公钥等于各节点随机数公钥的乘积,计算公式为加法即
[0026]
所述分布式集群的各个节点计算随机数索引的计算公式为idi=h(r
1,1
,r
2,2
,...,r
i,v
),其中h()表示哈希算法,1≤i≤u。
[0027]
所述分布式集群的各个节点有两个本地缓存,分别为随机数矩阵ki和随机数公钥矩阵ri;矩阵ki和矩阵ri都采用idi作为查询键(索引)。
[0028]
所述分布式集群的各个节点的随机数索引idi(查询键)是相同的,值(value)是不同的,各节点计算出来的矩阵r是相同的。
[0029]
所述寻址定位模块使用kademlia算法计算m的哈希h与随机数id之间的距离,找到与m的哈希h距离最近的随机数id0:
[0030]
所述随机数提取模块将找到的与m的哈希h距离最近的随机数id0作为查询键,从本地缓存中提取随机数k
i,1
,k
i,2
,...,k
i,v
和随机数公钥r
i,1
,r
i,2
,...,r
i,v
,分布式集群的各个节点按分布式密码协议进行后续处理。
[0031]
例如,对于musig2,以节点p1为例,后续计算如下:
[0032][0033]
然后计算:
[0034][0035][0036]
其中,s1为节点节点p1的签名份额,x1为节点p1的私钥,为聚合公钥。
[0037]
当分布式集群的某个节点从其他所有节点那里接收到全部消息处理份额si(1≤i≤n)后,通过随机数聚合模块将消息处理份额聚合出最终结果,聚合公式为如下:
[0038][0039]
本发明的有益效果是:该适用于分布式密码协议的随机数批量预处理系统,不依赖计数器,利用kademlia算法的异或距离来计算消息与随机数的绑定关系,实现了随机数的一致性选取,能够减少分布式密码协议的实时计算轮次,减少延迟,尤其适用于并发场景,能够同时处理多个消息,保证各方挑选的随机数一致。
附图说明
[0040]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0041]
附图1为本发明适用于分布式密码协议的随机数批量预处理方法示意图。
具体实施方式
[0042]
为了使本技术领域的人员更好的理解本发明中的技术方案,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚,完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员
在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
[0043]
在分布式密码协议中,一般需要多轮并发通信。往往在首轮(或前两轮)多方协商出v个随机数(v≥1),是后续轮次的消息处理的基础。
[0044]
为了提高分布式协议的执行效率,尤其是有多个消息需要处理时(如签名或解密),如果预先批量执行第一轮(或前两轮),就可以在收到要处理的消息时,快速执行后续轮次,这称为批量预处理。批量预处理的目的是提前准备好多套随机数,需要时直接取出来使用。
[0045]
假定分布式密码协议有n个参与方,共需要协商出u套随机数,每套随机数包含v个随机数(v≥1)。每个参与方都需要在本地缓存u*v个随机数,即缓存下图所示的矩阵(u行v列),参与方pi的本地随机数矩阵表示为ki:
[0046]
(随机数ki矩阵)
[0047]
随机数矩阵缓存在本地,是要保密的。利用公式(其中1≤i≤u,1≤j≤v)生成随机数公钥矩阵,参与方pi的随机数公钥矩阵表示为ri:
[0048]
(随机数公钥ri矩阵)
[0049]
各参与方的这个随机数公钥矩阵需要广播给其他参与方。
[0050]
当收到要处理的消息时,各方需要从上述的两个矩阵中选取一行(1套)参与计算,但各方选取的随机数必须一致,即如果选择第t行,则所有的参与方必须都选择第t行,否则计算结果将不一致。
[0051]
比较直觉的想法是维护一个全局计数器,从1开始,一直增长到m。但这种做法往往不可靠,尤其在并发场景下。
[0052]
在并发场景下,当各个参与方在同时处理多个消息时,很难将消息与计数器建立有效的关联。例如,当a和b两个参与方当同时收到消息a、b时,很容易发生a方认为a是第1个消息,b是第2个消息,而b方认为a是第2个消息,b是第1个消息。这导致a使用r
1,1
,...,r
1,v
来处理消息a,而b使用r
2,1
,...,r
2,v
来处理消息a,这会导致分布式协议失败。
[0053]
该适用于分布式密码协议的随机数批量预处理系统,包括分布式集群,随机数聚合模块,随机数提取模块,寻址定位模块和消息份额处理模块;
[0054]
所述分布式集群的各个节点分别生成本地随机数,u*v个随机数组成矩阵ki,随机数公钥矩阵ri,并广播ri;
[0055]
所述随机数聚合模块将各个节点的随机数公钥聚合起来,成为u*v个全局随机数公钥,全局随机数公钥组成矩阵r:
[0056]
所述分布式集群的各个节点利用r矩阵计算随机数索引,利用随机数索引将矩阵r、矩阵ri和矩阵ki的同一行标识和连接起来,保证各个节点使用同一行进行后续的密码计算;
[0057]
所述寻址定位模块计算m的哈希与随机数id之间的距离,并找到距离最近的随机数id;
[0058]
所述分布式集群的各个节点收到待处理的消息m(例如对消息m进行多重签名)后,通过随机数提取模块从本地缓存中提取随机数和随机数公钥;
[0059]
所述分布式集群的各个节点通过消息份额处理模块计算检索到的随机数的消息处理份额,并广播,聚合得到最终结果。
[0060]
所述分布式集群的n个节点生成u*v个随机数(矩阵ki),在本地缓存中保存随机数。各节点利用公式(其中1≤i≤u,1≤j≤v))生成随机数公钥矩阵ri,各节点广播随机数公钥矩阵。对于musig风格,中间要增加承诺/打开的步骤,但最终还是会形成和广播随机数公钥矩阵。这时任意一个节点都会形成下列的矩阵集合:
[0061][0062]
其中,上标r(i)表示第i个节点生成的矩阵。
[0063]
所述随机数聚合模块利用公式或(1≤j≤v,1≤i≤u)将分布式集群的各个节点随机数公钥聚合起来,成为u*v个全局随机数公钥,全局随机数公钥组成矩阵r如下:
[0064][0065]
根据不同的分布式密码协议采用乘法或者加法进行聚合。,乘法即全局随机数公钥等于各节点随机数公钥的乘积,计算公式为加法即
[0066]
所述分布式集群的各个节点计算随机数索引的计算公式为idi=h(r
1,1
,r
2,2
,...,r
i,v
),其中h()表示哈希算法,1≤i≤u。
[0067]
所述分布式集群的各个节点有两个本地缓存,分别为随机数矩阵ki和随机数公钥矩阵ri;矩阵ki和矩阵ri都采用idi作为查询键(索引)。例如,对于某个节点pi,本地缓存矩阵ri中第i个记录的key(键)是idi=h(r
i,1
,r
i,2
,...,r
i,v
),值(value)是r
i,1
,r
i,2
,...,ri,v;对于矩阵ki,则key是idi=h(r
i,1
,r
i,2
,...,r
i,v
),值(value)是k
i,1
,k
i,2
,...,k
i,v
;
[0068]
所述分布式集群的各个节点的随机数索引idi(查询键)是相同的,值(value)是不同的,各节点计算出来的矩阵r是相同的。这保证了随机数索引确定后,各节点分别从矩阵的同一行取数据。节点pi的本地缓存形式如下:
[0069]
随机数随机数公钥
[0070]
矩阵ki和矩阵ri的第一列是查询键(索引),后面的列是值(value)。
[0071]
所述寻址定位模块使用kademlia算法计算m的哈希h与随机数id之间的距离,首先
计算h=h(m),根据多方协议的不同,h()中可能会添加其他的值,例如计算h=h(m),根据多方协议的不同,h()中可能会添加其他的值,例如是多重签名的聚合公钥。然后进行下列循环,找到与m的哈希h距离最近的随机数id0:
[0072][0073]
所述随机数提取模块将找到的与m的哈希h距离最近的随机数id0作为查询键,从本地缓存中提取随机数k
i,1
,k
i,2
,...,k
i,v
和随机数公钥r
i,1
,r
i,2
,...,r
i,v
,分布式集群的各个节点按分布式密码协议进行后续处理。
[0074]
例如,对于musig2,以节点p1为例,后续计算如下:
[0075][0076]
然后计算:
[0077][0078][0079][0080]
其中,s1为节点节点p1的签名份额,x1为节点p1的私钥,为聚合公钥。
[0081]
当分布式集群的某个节点pi从其他所有节点那里接收到全部消息处理份额si(1≤i≤n)后,通过随机数聚合模块将消息处理份额聚合出最终结果,聚合公式为如下:
[0082][0083]
对于其他的分布式密码协议也是类似的,只是公式有所不同。
[0084]
分布式集群的各个节点使用kademlia算法建立待处理的消息与随机数之间的关联关系,并进行目标寻址。当消息确定时,各方一致性地选择与消息“距离”最近的随机数公钥,然后利用选中的随机数公钥和秘密进行后续的分布式多方计算,如阈值签名、多重签名等。同时,这些随机数集合可以复用,即随机数集合可以保存在该节点的缓存中,在一个时间段内可以反复使用。
[0085]
以上所述的实施例,只是本发明具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1