基于时序特征的虚拟现实视频情感识别方法及系统
1.本发明属于认知心理学、虚拟现实技术和情感连续识别的交叉融合领域,具体为基于时序特征的虚拟现实视频情感识别方法及系统。
背景技术:
2.情感诱发和情感识别是情绪研究领域的热点之一,其在推荐系统、游戏设计、心理学研究、人机交互和人机情感感知等领域都有重要的应用和研究价值。虚拟现实场景凭借其高沉浸度、高代入感在教育、医疗、娱乐、脑机接口等方面得到了广泛的应用,同时在情绪诱发领域获得了广泛关注和研究,因此如何对虚拟现实场景视频进行连续情感评价显得尤为重要。
3.当前基于虚拟现实场景的情感诱发和情感识别研究中,虚拟现实诱发态下带有连续情感标签的虚拟现实场景素材库较少,对情感诱发材料的情感标注主要是采用sam量表进行离散评价,耗时耗力,具有较大的主观性,且无法从时间维度上对情感诱发素材进行连续的情绪标注。且针对虚拟现实场景在时间维度上进行动态跨范式连续情绪标注的回归模型尚未完善,这是行业内急需探索和思考的问题。
技术实现要素:
4.为了解决虚拟现实场景视频情感识别层面缺少在时间维度上进行跨范式连续情感标注回归模型的问题,从建立虚拟现实场景音视频连续情感数据集出发,本发明提出基于时序特征的虚拟现实视频情感识别方法及系统。
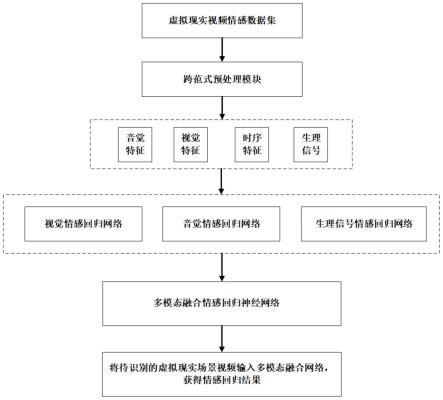
5.本发明方法通过以下技术方案实现:基于时序特征的虚拟现实视频情感识别方法,包括以下步骤:
6.s1、建立带有连续情感标签的虚拟现实场景音视频数据集,数据集内容包括手动提取的连续情绪标签、音频特征、视觉特征及生理信号特征;
7.s2、对待识别的虚拟现实场景视频进行跨范式数据预处理;
8.s3、对预处理后的数据进行特征提取,用深度学习网络提取来自音频、视觉、时序和生理信号的深度特征;
9.s4、训练单模态虚拟现实场景视频情感回归模型,并融合生成多模态情感回归神经网络模型;
10.s5、训练多模态情感回归神经网络模型;
11.s6、将待识别虚拟现实场景视频输入多模态情感回归神经网络模型,输出连续情感回归结果。
12.本发明系统通过以下技术方案实现:基于时序特征的虚拟现实视频情感识别系统,包括:
13.数据集建立模块,用于建立带有连续情感标签的虚拟现实场景音视频数据集,数据集内容包括手动提取的连续情绪标签、音频特征、视觉特征及生理信号特征;
14.预处理模块,用于对待识别的虚拟现实场景视频进行跨范式数据预处理;
15.特征提取模块,对预处理后的数据进行特征提取,用深度学习网络提取来自音频、视觉、时序和生理信号的深度特征;
16.多模态回归模型生成及训练模块,训练单模态虚拟现实场景视频情感回归模型,并融合生成多模态情感回归神经网络模型,并训练多模态情感回归神经网络模型;
17.情感识别模块,用于将待识别虚拟现实场景视频输入多模态情感回归神经网络模型,输出连续情感回归结果。
18.本发明能够基于时序、视觉、音频、生理信号四种模态特征,为虚拟现实场景视频的情感评估提供了一种新的途径,能够高效准确地对虚拟现实场景视频进行情感连续识别。本发明与现有技术相比,具有如下优点和有益效果:
19.1、本发明对虚拟现实场景视频进行连续情感回归提供了一种新的途径,通过充分探索视觉特性、音频特性、生理特性和时序特性,经过主成分分析、特征对齐和归一化等途径综合分析影响情感的特征矩阵,并基于多模态融合,建立多模态融合情感回归网络,增加通道注意力模块和空间注意力模块,自主学习并分配各特征权重,同时使得图像输入更加丰富,避免噪声干扰。
20.2、本发明通过建立多模态融合跨范式情感回归网络,通过数据预处理,减少个体差异和数据主观性,能够对虚拟现实场景视频进行连续情感回归,情感评价相比sam更加高效准确。
附图说明
21.图1是本发明实施例中基于时序特征的虚拟现实视频情感识别方法流程图;
22.图2是本发明实施例中建立虚拟现实场景音视频连续情感数据集的流程图;
23.图3是本发明实施例中虚拟现实视频跨范式多模态融合情感回归模型中的通道注意力模块;
24.图4是本发明实施例中虚拟现实视频跨范式多模态融合情感回归模型中的空间注意力模块。
具体实施方式
25.为了使本发明的目的、技术方案及优点更加清晰,下面结合附图及实施例对本发明作进一步的说明,此处所描述实施例仅适用于解释本发明,本发明的实施方式并不限于此。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明的保护范围。
26.实施例1
27.如图1所示,本实施例提供基于时序特征的虚拟现实视频情感识别方法,该方法主要包括以下步骤:
28.s1、建立带有连续情感标签的虚拟现实场景音视频数据集,数据集内容包括手动提取的连续情绪标签、音频特征、视觉特征、生理信号特征等(eeg、bvp、gsr、ecg)。
29.本步骤建立带有连续情感标签的虚拟现实场景音视频数据集,如图2所示,具体过程包括:
30.s11、搜集包含不同情感内容的虚拟现实场景视频,通过m名健康受试者对搜集到的n个虚拟现实场景视频进行sam自我评估,根据评估得分,在各个情感象限分别筛选出f个虚拟现实场景视频。
31.s12、搭建连续sam自我评估实验范式,由p个健康受试者对虚拟现实场景视频进行连续sam情感评估实验,受试者在头戴虚拟头显观看虚拟现实场景视频时,实时进行sam自我评估。每个虚拟现实场景视频在播放完毕后有19s的黑屏时间,以供受试者情感平复。同时收集受试者的连续生理信号和对虚拟现实场景视频在愉悦度、唤醒度和支配度三个维度上的评分。评分范围为1-9,根据计算每个虚拟现实场景视频在愉悦度、唤醒度和支配度三个维度上的平均值和标准差,标准差小于1.5的认为是有效数据,并将p个受试者的连续评分平均值作为虚拟现实场景视频的情绪标签。
32.s13、对每个虚拟现实场景视频进行处理,提取其在视觉、音频方面的手工特征和生理信号特征,并与连续情感标签相对应,实现虚拟现实场景音视频连续情感数据集的构建。
33.其中,对每个虚拟现实场景视频进行处理,包括手工特征提取、特征对齐和归一化处理,具体细节如下:
34.s131、提取虚拟现实场景视频在视觉、音频方面的手工特征、时序特征、动作信息特征和生理信号特征,其中生理信号特征包含eeg、bvp、gsr、ecg、hr等,视觉特征包括颜色特征、灰度特征、形状特征、纹理特征、共生矩阵特征等。
35.s132、将来自不同维度的特征与情感标签对齐,并作各维度与情感高相关的情感特征选择和归一化处理。
36.s2、对待识别的虚拟现实场景视频进行跨范式数据预处理。
37.本实施例中,跨范式数据预处理指以每个虚拟现实场景视频为单位形成不同的数据划分方式,即虚拟现实场景音视频连续情感数据集中共有n个视频,以待参与情感回归的视频作为验证集数据样本,其他视频作为训练集,跨范式预处理模块将数据集划分为具有n种训练方式的数据集。
38.s3、对预处理后的数据进行特征提取,用深度学习网络提取来自音频、视觉、时序和生理信号的深度特征;
39.本实施例中,深度学习网络提取的音频特征被转化为灰度图谱图片,与视觉特征一同由cnn网络和rnn网络提取视觉、音频和时序特征,由rnn网络提取生理特征;并将所提取的特征进行特征主成分分析、对齐和归一化处理。
40.s4、训练单模态虚拟现实场景视频情感回归模型,并融合生成多模态情感回归神经网络模型;
41.单模态情感回归模型包括视觉情感回归网络、音频情感回归网络和生理信号情感回归网络,其网络主要架构均为cnn-rnn网络,并在cnn网络中添加了注意力机制模块cabm,从通道和空间维度强调重要情感特征,抑制不必要的特征。图3和图4分别为注意力机制模块cabm中的通道注意力模块和空间注意力模块。
42.本步骤训练单模态虚拟现实场景视频情感回归模型主要过程为:
43.s41、分别训练视觉情感回归网络、音频情感回归网络和生理信号情感回归网络三种单模态虚拟现实场景视频情感回归模型;
44.s42、根据特征层融合、决策层融合和混合融合的方式,生成多模态情感回归神经网络模型。所述特征层融合指各单模态神经网络在提取到特征后,通过add和concat的方式合并各模态的多层特征,随后输入到池化层和全连接层;所述决策层融合指各单模态模型获得回归结果后根据最大池化、平均池化、加权池化的方式得到最终回归结果;混合融合指将特征层融合和决策层融合结合的方式获得回归结果。
45.s5、训练多模态情感回归神经网络模型;
46.多模态情感回归网络的训练方法主要有以下几点:
47.s51、多模态融合指根据特征层融合、决策层融合和混合融合的方式,生成多模态情感回归神经网络模型。
48.s52、特征层融合指各单模态神经网络在提取到特征后,通过add和concat的方式合并各模态的多层特征,随后输入到池化层和全连接层;
49.s53、决策层融合指各单模态模型获得回归结果后根据最大池化、平均池化、加权池化的方式得到最终回归结果;混合融合意指将特征层融合和决策层融合结合的方式获得回归结果。
50.s6、将待识别虚拟现实场景视频输入多模态情感回归神经网络模型,输出连续情感回归结果。
51.在本步骤中,多模态情感回归神经网络用于对虚拟现实场景视频进行情感回归预测,并输出回归结果。
52.实施例2
53.与实施例1基于相同的发明构思,本实施例提供的是基于时序特征的虚拟现实视频情感识别系统,包括:
54.数据集建立模块,用于建立带有连续情感标签的虚拟现实场景音视频数据集,数据集内容包括手动提取的连续情绪标签、音频特征、视觉特征及生理信号特征;
55.预处理模块,用于对待识别的虚拟现实场景视频进行跨范式数据预处理;
56.特征提取模块,对预处理后的数据进行特征提取,用深度学习网络提取来自音频、视觉、时序和生理信号的深度特征;
57.多模态回归模型生成及训练模块,训练单模态虚拟现实场景视频情感回归模型,并融合生成多模态情感回归神经网络模型,并训练多模态情感回归神经网络模型;
58.情感识别模块,用于将待识别虚拟现实场景视频输入多模态情感回归神经网络模型,输出连续情感回归结果。
59.本实施例的各模块分别用于实现实施例1的相应步骤,在此不赘述。
60.上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1