融合ResNeXt的EBAC鱼类文本联合抽取方法
融合resnext的ebac鱼类文本联合抽取方法
技术领域
1.本发明属于文本实体关系联合抽取技术领域,具体涉及一种基于resnext思想的ebac(enhanced representation from knowledge integration+attention mechanism+bi-direct ional long short-term memory+conditional random field,ebac)鱼类科普文本实体关系联合抽取方法。
背景技术:
2.近年来,鱼类科普信息管理任务日益复杂,产生了大量含冗余信息的非结构化鱼类相关文本,目前,对于在这些海量文本中获得有用特征信息主要采用实体关系抽取方法。
3.miwa等人提出了一种基于bilstm和tree-lstm结构的端到端模型来同时抽取实体及关系,但获取三元组的过程仍属于流水线方式,也就是当实体全部识别出来后两两配对传送到关系分类模块预测它们之间的关系时,因为一些不存在关系的实体对也被输入到该模块中,造成了信息冗余,除此之外检测实体时,忽略了实体标签之间的长距离依赖关系(makoto miwa and mohit bansal.end-to-end relation extraction using lstms on sequences and tree structures.[j].corr,2016,abs/1601.00770.);zheng等人提出把输入句子通过公用的embedding层和bilstm模型来解决长距离依赖问题,然后分别使用一个lstm来进行实体识别和一个cnn来进行关系抽取(suncong zheng,et al.joint entity and relation extraction based on a hybrid neural network[j].neurocomputing,2016,257:59-66.);zheng等人又提出了一个标注机制以解决信息冗余问题,是将联合抽取问题转换为序列标注问题,但标签合并为实体关系三元组时因为就近组合导致关系重叠(suncong zheng,et al.joint extraction of entities and relations based on a novel tagging scheme[j].ar xiv preprint ar xiv,2017.1706(1706).);wang等人提出了通过设计一个有向图机制将联合抽取任务转换为一个有向图问题,使用基于转移的解析框架解决了一个实体与多个实体存在关系的重叠问题(shaolei wang,yue zhang,wanxiang che,et al.joint extraction of entities and relations based on a novel graph scheme[j].2018.)。但与上述通用领域相比,现有技术的篇章级鱼类科普文本除了存在重叠问题以外,还有大量的实体间语义不强的问题,因此利用基于迁移学习的知识增强预训练模型解决该问题。
[0004]
迁移学习的应用在自然语言处理任务中通常是通过预训练模型来体现。知识增强的预训练模型ernie通过海量数据建模词、实体及实体关系。sun等人针对bert在处理中文时难以学习完整地语义表示等问题,提出了ernie模型直接对先验语义知识单元进行建模,增强了该模型语义表示能力(sun y,wang s,li y,et al.ernie:enhanced representation through knowledge integration[j].2019.);牛玉婷等人将ernie预训练词模型与dpc-nn模型进行融合进行中文文本分类,改进了ernie-dpcnn模型,利用ernie模型可以捕获长距离信息等优势提高了模型的准确率并降低了成本(牛玉婷,陈伯琪,陈彬.基于改进ernie-dpcnn模型的中文文本分类[j].江苏师范大学学报(自然科学版),
2021,39(01):47-52.)。
[0005]
尽管目前已有大量的通用领域实体关系抽取研究方法来处理文本重叠问题,但不能很好的解决篇章级鱼类科普文本大量实体间语义不强、长序列语义稀释和长距离依赖问题。
技术实现要素:
[0006]
为了解决上述技术问题,本发明提供了一种融合resnext的ebac鱼类文本联合抽取方法。
[0007]
本发明的目的是提供一种融合resnext的ebac鱼类文本联合抽取方法,包括:
[0008]
将鱼类科普文本输入深度学习模型进行实体关系联合抽取;
[0009]
所述深度学习模型包括:
[0010]
ernie预训练模型,用于对所述鱼类科普文本进行编码,获得相应的字向量;
[0011]
bilstm模型,用于捕捉所述字向量中的依赖关系,获得相应的隐藏状态向量;
[0012]
attention注意力模型,用于对所述隐藏状态向量进行权重分配,生成相应的语义向量,其中所述attention注意力模型融合了resnext思想,在不增加模型复杂度的前提下提高抽取效果;
[0013]
crf解码器,用于对所述语义向量进行解码,获得相应的规范标签,根据规范标签确定实体关系。
[0014]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,在抽取所述实体关系前,需要对所述bilstm模型进行训练,训练方法为:
[0015]
获取鱼类科普文本,建立鱼类科普文本库;
[0016]
将所述鱼类科普文本库中的部分鱼类科普文本作为训练集;
[0017]
对所述训练集中的鱼类科普文本进行标注;
[0018]
将所述训练集中的鱼类科普文本输入所述ernie预训练模型,获得相应的字向量;
[0019]
将所述字向量输入所述bilstm模型,获得相应的隐藏状态向量;
[0020]
将所述隐藏状态向量输入融合了resnext思想的attention注意力模型,获得相应的语义向量;
[0021]
将所述语义向量利用crf解码器进行解码,获得相应的规范标签及实体关系;
[0022]
根据所述crf解码器解码得到的实体关系与所述训练集中的鱼类科普文本标注的实体关系的误差对所述深度学习模型进行调整,完成对所述深度学习模型的训练。
[0023]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,在将所述鱼类科普文本库中的部分鱼类科普文本作为训练集之后,还包括:
[0024]
将所述鱼类科普文本库中的部分鱼类科普文本作为测试集;
[0025]
根据所述crf解码器解码得到的实体关系与所述训练集中的鱼类科普文本标注的实体关系的误差对所述深度学习模型进行调整之后,还包括:
[0026]
采用所述测试集对调整之后的所述深度学习模型进行测试。
[0027]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,在获取所述鱼类科普文本之后,还包括:
[0028]
对所述鱼类科普文本进行清洗。
[0029]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,所述鱼类科普文本的获得及清洗方法具体如下:
[0030]
通过python爬虫的方式获取多个百科类网站的鱼类科普信息,并进行整合及清洗,去除噪声,获得鱼类科普文本。
[0031]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,所述鱼类科普信息包括鱼类级别分类、别称、主要分布位置、经常栖息的环境、喜好捕食对象、初代鱼种产地。
[0032]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,训练集和测试的鱼类科普文本数量比例为7:3。
[0033]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,对鱼类科普文本进行标注如下:
[0034]
根据鱼类科普文本特征,采用标注工具,使用“bios”的方法进行标注。
[0035]
优选的,上述融合resnext的ebac鱼类文本联合抽取方法,隐藏状态向量的获得方法如下:
[0036]
bilstm模型用于将正向隐藏层向量、反向隐藏层向量处理后的结果合并,并作为当前字符的隐藏状态向量。
[0037]
与现有技术相比,本发明具有以下有益效果:
[0038]
1、本发明为了解决篇章级鱼类科普文本大量实体间语义不强、长距离依赖、长序列语义稀释的问题,而提出了一种融合resnext的ebac鱼类文本联合抽取方法,可有效提高篇章级鱼类科普文本的抽取效果。与现有实体关系抽取方法对比,本发明在鱼类科普文本上获得效果最好,准确率(precision)、召回率(recall)和f1值(f1-score)均达到不错的效果。
附图说明
[0039]
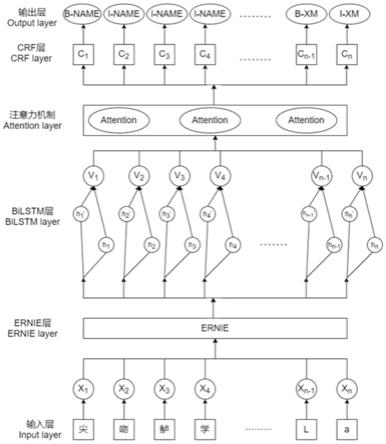
图1本发明实施例1的流程示意图。
具体实施方式
[0040]
为了使本领域技术人员更好地理解本发明的技术方案能予以实施,下面结合具体实施例和附图对本发明作进一步说明。
[0041]
本发明是一种融合resnext的ebac鱼类文本联合抽取方法,是将标注完毕的鱼类科普文本送入深度学习模型进行实体关系联合抽取,所述深度学习模型是按照图1所示步骤构建,包括以下步骤:
[0042]
步骤1:爬虫并整合及清洗多个百科类网站22万左右字符构建鱼类科普文本库,涵盖海洋鱼类级别分类、别称、主要分布位置、经常栖息的环境、喜好捕食对象、初代鱼种产地等各种海洋鱼类(以下简称鱼类)科普信息:
[0043]
具体的,通过python爬虫的方式获取万维百科、百度百科、360百科等百科网站的大量鱼类科普信息,并进行人工清洗,去除与鱼类科普信息毫无相关的噪声,获得的文本构建鱼类科普文本库,用于实体关系联合抽取研究。
[0044]
步骤2:将鱼类科普文本库划分成训练集和测试集,二者的鱼类科普文本数量比例为7:3。根据鱼类科普文本特征,采用标注工具,使用“bios”的方法进行标注,其中name表示
主体类别,oth是所有客体关系类别统称,本方法共有21种标注形式,主体3种,客体17种,非实体1种。
[0045]
针对当今鱼类科普行业需求和整个文本的特征分析,筛选出其中7种相关性高的实体关系进行抽取任务,包括拉丁学名实体关系、同位别名实体关系、上下位实体关系、捕食类型实体关系、栖息环境实体关系、分布位置实体关系和模式产地实体关系。
[0046]
传统的标注方案采用“bio”的标注方式表示每个字在实体中的位置信息,b表示该字是实体中的首位字符,i表示该字是实体中的非首位字符,o表示非实体字符。根据鱼类科普知识的特征提出“bios”标签类别定义,在“bio”的位置标签基础上增加s标签表示该实体为单字符。其中name表示主体类别,oth是所有客体关系类别统称,分别使用xm、bm、sx、bs、qx、fb、cd字母表示,共21种标注形式。
[0047]
步骤3:采用基于迁移学习领域的ernie预训练模型对获取的鱼类科普文本进行编码,将字符转换为字向量。该模型在已学习海量先验语义知识的情况下,把短语和实体找出来并进行遮掩以此来提高实体间语义表示的学习能力,增强模型的语义表现力用于解决实体间语义不强的问题。
[0048]
步骤4:将ernie得到的字向量输入到bilstm模型,bilstm模型由前向的lstm与后向的lstm结合成。
[0049]
lstm模型解决rnn模型梯度在传递过程中存在极大数量的连乘导致梯度消失或梯度爆炸的问题,其由遗忘门、输入门、内部记忆单元和输出门四部分组成,该模型可以通过训练过程学习到记忆和遗忘哪些信息从而很好的捕捉到较长距离的依赖关系每个lstm单元的状态计算表示为:
[0050]ft
=σ(wf·
[h
t-1
,x
t
]+bf)
ꢀꢀꢀ
(1)
[0051]it
=σ(wi·
[h
t-1
,x
t
]+bi)
ꢀꢀꢀ
(2)
[0052][0053][0054]ot
=σ(wo[h
t-1
,x
t
]+bo)
ꢀꢀꢀ
(5)
[0055]ht
=o
t
*tanh(c
t
)
ꢀꢀꢀ
(6)
[0056]
其中f、i、o分别为lstm模型中的遗忘门、输入门和输出门;c
t
、c
t-1
表示内部记忆单元;x为t时间的输入;w为权重矩阵;b为偏置;σ为sigmod激活函数;h
t
为t时间的输出。但lstm却存在无法编码从后到前信息的问题,bilstm因此出现。
[0057]
bilstm模型用于将正向隐藏层向量、反向隐藏层向量处理后的结果合并,并作为当前字符的隐藏状态向量,该处理过程表示为:
[0058]vt
=[h
t
:h
t
′
]
ꢀꢀꢀ
(7)
[0059]
v={v
1,
…
,v
t,
…
,v
t
}
ꢀꢀꢀ
(8)
[0060]
其中h
t
和h
t
′
分别表示正向隐藏层向量、反向隐藏层向量;v表示所有时刻隐藏层向量的组合,作为bilstm模型的输出传送给attention注意力模型;t表示时间。
[0061]
步骤5:将bilstm模型得到的隐藏状态向量传入attention注意力模型,attention注意力模型可以对信息进行权重的分配,生成不断变化的语义向量使模型关注重点信息,抑制无用信息,其中每个字输出多了注意力向量参与,注意力的权重由上一时刻隐含状态
与encoder的各个输入的隐含状态共同决定,该流程计算表示为:
[0062]
m=tanh(h)
ꢀꢀꢀ
(9)
[0063]
α=softmax(ω
t
m)
ꢀꢀꢀ
(10)
[0064]r′
=hα
t
ꢀꢀꢀ
(11)
[0065]
r=tanh(r
′
)
ꢀꢀꢀ
(12)
[0066]
其中,m是h连接一个激活函数为tanh的结果,h是上层隐藏层输出的集合,即h=v,其中h∈rdw
×
t,dw是字向量的维度,t是句子的长度;ω是训练好的参数向量,ω
t
使其转置;α是权重矩阵,同理,α
t
是其转置;r
′
是句子的分布式表达;r是该层的输出。
[0067]
除此之外,attention注意力模型融合了源于残缺网络的resnext思想,并行方式堆叠attention注意机制,并行超参数为3时效果最佳,超过3维会出现过拟合现象;每条支线串行多层注意力机制,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,该策略减少了超参数的选择,因此,attention注意力模型在不增加模型复杂度的前提下提高抽取效果。
[0068]
步骤6:最后引入crf解码器进行解码,得到规范后的规范标签,根据规范标签确定实体关系,最后对获得的实体关系以及规范标签的对比结果进行规范输出。
[0069]
需要说明的是,在应用所述深度学习模型之前,需要对所述深度学习模型进行训练,训练方法为:
[0070]
获取鱼类科普文本,建立鱼类科普文本库;
[0071]
将所述鱼类科普文本库中的部分鱼类科普文本作为训练集;
[0072]
对所述训练集中的鱼类科普文本进行标注;
[0073]
将所述训练集中的鱼类科普文本输入所述ernie预训练模型,获得相应的字向量;
[0074]
将所述字向量输入所述bilstm模型,获得相应的隐藏状态向量;
[0075]
将所述隐藏状态向量输入融合了resnext思想的attention注意力模型,获得相应的语义向量;
[0076]
将所述语义向量利用crf解码器进行解码,获得相应的规范标签,根据规范标签确定实体关系;
[0077]
根据所述crf解码器解码得到的实体关系与所述训练集中的鱼类科普文本标注的实体关系的误差对所述深度学习模型进行调整,完成对所述深度学习模型的训练。
[0078]
在将所述鱼类科普文本库中的部分鱼类科普文本作为训练集之后,还包括:
[0079]
将所述鱼类科普文本库中的部分鱼类科普文本作为测试集;
[0080]
根据所述crf解码器解码得到的实体关系与所述训练集中的鱼类科普文本标注的实体关系的误差对所述深度学习模型进行调整之后,还包括:
[0081]
采用所述测试集对调整之后的所述深度学习模型进行测试。
[0082]
本发明实施例实体关系抽取效果数据(即实体关系以及规范标签的对比结果)如表1所示。表1中从上至下分别为7种具体实体关系的抽取效果数据以及总体的抽取效果数据。
[0083]
表1实体关系抽取效果数据
[0084][0085]
本发明实施例与其它模型间性能对比效果数据如表2所示。包括与ernie+bilstm+crf模型间对比分析注意力机制影响效果,与bilstm+atttention+crf模型间对比分析是否进行预训练的影响,其中ebc和bac是指ernie+bilstm+crf和bilstm+atttention+crf模块结构。除此之外还针对本研究领域较为经典的预训练模型bert,本实验使用的近年提出的ernie模型与其进行外部模块间性能研究,考察ernie较bert是否更加适用于本领域。本发明提出的模型更准确,有效的提高了抽取效果。
[0086]
表2不同模型间性能对比效果数据
[0087][0088]
本发明实施例与未进行基于迁移学习的模型性能对比效果数据如表3所示。根据预训练模型自身的学习方式,提出基于迁移学习的领域再学习效果研究,与不进行再学习进行对比分析。结果表明通过本发明实施例构建的模型可以有效的抽取文本的实体关系,有效提高了实体关系三元组的抽取f1值。
[0089]
表3未进行基于迁移学习的模型性能对比效果数据
[0090][0091]
需要说明的是,本发明中涉及数值范围时,应理解为每个数值范围的两个端点以
及两个端点之间任何一个数值均可选用,由于采用的步骤方法与实施例相同,为了防止赘述,本发明描述了优选的实施例。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0092]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1