一种分类多重宽度学习注意力机制的热负荷曲线预测方法
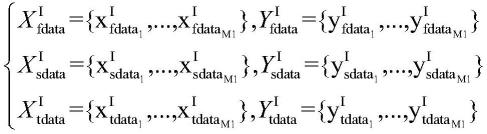
1.本发明属于电力系统多能互补领域,涉及基于人工智能的预测方法,适用于电力系统的分布式地源热泵蓄热器用户的热负荷曲线预测,适用于电网新能源消纳。
背景技术:
2.在需要热能的季节人们希望能有充足的热量供应,分布式地源热泵蓄热器可以将多余的风能和太阳能利用起来,在风能或太阳能过剩时作为电负荷运行去存储热能。分布式地源热泵蓄热器用户的热负荷曲线预测对热能和电能调度至关重要。对于家里有两个或多个白天在外工作者的用户来说,热负荷曲线高峰期一般为早上7:00到9:00和晚上7:00到11点,曲线波动较大;但如果是居家办公工作者或者是老人和小孩居住的用户则一整天时间都需要供暖,但曲线比较平稳。将相似的曲线分为一类更有利于后续预测模型的建立。
3.而现有方法:(1)不能考虑分类,对分布式地源热泵蓄热器用户的热负荷曲线预测的不准确;(2)单次建模,准确度不高;(3)神经网络(如深层神经网络和bp神经网络)的预测模型的建立需要繁杂的计算,所花费的时间较长;(4)未考虑用户的历史数据可作为先验知识。
4.所提方法中的分类多重宽度学习注意力机制沿袭了宽度学习本身结构简单运算速度快的优点,还对热负荷进行了分来,考虑了先验知识,并通过二次建模中增加的优化系数矩阵提高了所提方法的预测精度,比深层神经网络和bp神经网络更加适用于即时性负荷预测。
技术实现要素:
5.本发明提出一种分类多重宽度学习注意力机制的热负荷曲线预测方法,该方法在提高风能和太阳能利用率的步骤为:
6.步骤(1),给出分布式地源热泵蓄热器用户相邻四天的全部热负荷曲线,并将热负荷曲线分为两类,第一类为曲线较为平稳,第二类为曲线波动较大,对两类热负荷曲线分别建立对应的热负荷预测模型;
7.给出冬季任意相邻四天的全部热负荷曲线,并将这四天中每一天的所有热负荷曲线分别分为两类:第一类曲线较为平稳,第二类曲线波动较大;在有m个热负荷时,每条热负荷曲线为96个时间点,每个时间点为5分钟,如果满足:
[0008][0009]
则为第一类;否则,为第二类;abs(
·
)表示求绝对值;为第m个热负荷在第j个时间点的热负荷值,abs(
·
)表示求绝对值;为第m个热负荷在第j+1个时间点的热负荷值;
[0010]
步骤(2),采用上一周的历史数据形成具有先验知识的注意力机制值,突出重要元素,形成的第m个热负荷在第j个时间点注意力机制值为:
[0011][0012]
为上一周第m个热负荷在第j个时间点的热负荷值;softmax()为softmax激活函数;
[0013]
步骤(3),将第一天和第二天的热负荷曲线数据作为初次训练集,第二天和第三天的热负荷曲线数据作为增强训练集,第三天和第四天的热负荷曲线数据作为测试集;
[0014]
初次训练集用于多重宽度学习进行第一次模型的建立,称为一次建模,并将一次建模过程中求得的权重存储起来;
[0015]
再将增强训练集输入第一次所建立的模型进行模型的优化,称为二次建模,并在第二次建模中将求出的增加的优化系数矩阵存储起来;
[0016]
然后,与步骤(2)计算得到的注意力机制权值相乘;
[0017]
其次,将测试集中的输入数据输入所建立的多重宽度学习预测模型并求出预测值,算出预测值与测试集中的输出真实值的均方根误差,则求得所建立模型的误差;
[0018]
(3.1)将第一天和第二天的热负荷曲线数据作为初次训练集,第二天和第三天的热负荷曲线数据作为增强训练集,第三天和第四天的热负荷曲线数据作为测试集;
[0019]
第一类热负荷为m1个,第二类负荷为m2个,m1+m2=m;
[0020]
分别给出第一类和第二类热负荷的初次训练集、增强训练集和测试集的数据集表示为:
[0021]
第一类:
[0022]
第二类:
[0023]
其中,和为第一类热负荷的初次训练集,和为第一类热负荷的增强训练集,和为第一类热负荷的测试集;和为第二类热负荷的初次训练集,和为第二类热负荷的增强训练集,和为第二类热负荷的测试集;
[0024]
(3.2)输入初次训练集中的产生第p组映射特征节点矩阵:
[0025][0026]
其中,w
rp
为生成的随机权重矩阵,并存储起来,β
rp
为生成的随机偏差矩阵,并存储起来,k表示映射特征节点矩阵的数量;sigmoid()为sigmoid激活函数;
[0027]
(3.3)由映射特征节点矩阵产生第q组增强节点矩阵:
[0028]rq
=tanh(jkw
eq
+β
eq
),q=1,2,...,n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0029]
其中,w
eq
为生成的随机权重矩阵,并存储起来,β
eq
为生成的随机偏差矩阵,并存储起来,jk=[j1,j2,...,jk],rn=[r1,r2,...,rn],n表示增强特征节点矩阵的数量;tanh()为tanh激活函数;
[0030]
(3.4)求出随机权重矩阵:
[0031][0032]
其中[jk|rn]为jk和rn的组合矩阵;
[0033]
(3.5)进行二次建模,输入增强训练集中的输入到上述训练好的模型中,根据已存储和已求出的权重,求出预测值求解过程为:
[0034]
更新第p组映射特征节点矩阵:
[0035][0036]
利用更新后的映射特征节点矩阵来更新第q组增强节点矩阵:
[0037]rq
=tanh(jkw
eq
+β
eq
),q=1,...,n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0038]
考虑注意力机制的二次的输出预测值:
[0039][0040]
其中α为注意力机制值组成的行向量;
[0041]
(3.6)求出二次建模中增加的优化系数矩阵:
[0042][0043]
(3.7)输入测试集中的按照步骤(3.2)到步骤(3.6)中求出的权重得到最后的预测值,与真实值作比较,求出预测值与测试集中的输出真实值的均方根误差,即所述多重宽度学习注意力机制预测模型的误差:
[0044][0045]
(3.8)对第二类热负荷按照步骤(3.2)到步骤(3.7)进行建模,得到两类热负荷的热负荷曲线的预测模型;
[0046]
步骤(3),将所建多重宽度学习注意力机制模型用于对分布式地源热泵蓄热器用户的热负荷曲线预测;
[0047]
步骤(4),在风能和太阳能过剩时,电力系统调度中心依据分布式地源热泵蓄热器用户的热负荷曲线预测结果,将风能和太阳能过剩的电能作为电负荷运行存储热能,将热能供给分布式地源热泵蓄热器用户,提高风能和太阳能的利用率,提升电力系统对风能和太阳能的消纳能力。
[0048]
本发明相对于现有技术具有如下的优点及效果:
[0049]
(1)本发明采用基于查询的注意力机制,对不同类型的分布式地源热泵蓄热器用户的时段形成先验知识,形成具有“记忆”的符合人类活动的先验知识,能获得更加准确的热负荷曲线。
[0050]
(2)本发明为分类预测,即“分类”的多重宽度学习;将每一天的热负荷曲线分为两类,第一类曲线较为平稳,第二类曲线波动较大。将相似的曲线分为一类更有利于后续预测模型的建立及提高预测模型的精确性。
[0051]
(3)本发明分为两次建模,即“多重”的宽度学习;初次训练集用于多重宽度学习进
行第一次模型的建立,称为一次建模;再将增强训练集输入第一次所建立的模型进行模型的优化,进行二次建模。经过二次建模对模型的优化可以提高负荷预测的精确度。
[0052]
(4)本发明的方法能为电力系统调度中心提供调度依据,实现多能互补,从而提高风能和太阳能的利用率,提升电力系统对风能和太阳能的消纳能力。
附图说明
[0053]
图1是本发明方法的热负荷分类流程图。
[0054]
图2是本发明方法所建立多重宽度学习注意力机制预测模型的训练过程。
[0055]
图3中是本发明方法所提到的分布式地源热泵蓄热器用户的热负荷曲线在电网的工作原理图。
具体实施方式
[0056]
本发明提出一种分类多重宽度学习注意力机制的热负荷曲线预测方法,结合附图详细说明如下:
[0057]
图1是本发明方法的热负荷分类流程图。首先,给出一天中所有分布式地源热泵蓄热器用户的热负荷曲线,然后,判断每条热负荷曲线每两个相邻时间点之间的差值是否均小于1kw,如果是,表示曲线较为平稳,为第一类热负荷的热负荷曲线;如果不是,则表示曲线波动较大,为第二类热负荷的热负荷曲线。
[0058]
图2是本发明方法所建立多重宽度学习注意力机制预测模型的训练过程。首先,通过初次训练集进行一次建模,求出相应的权重矩阵。其次,根据一次建模中所求的权重矩阵与增强训练集中的输入数据求出输出预测数据,再根据求出的输出预测数据与增强训练集中的输入真实数据求出优化系数矩阵,第二次建模输出乘以注意力机制权值。最后,根据测试集来验证所建立预测模型的精确性。
[0059]
图3中是本发明方法所提到的分布式地源热泵蓄热器用户的热负荷曲线在电网的工作原理图。分布式地源热泵蓄热在风能和太阳能过剩时作为电负荷运行存储热能,再将热能供给分布式地源热泵蓄热器用户,提高风能和太阳能的利用率。
[0060]
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1