一种基于自适应性节点特征生成的信息推荐方法
1.本发明涉及信息推荐技术领域,具体涉及一种基于自适应性节点特征生成的信息推荐方法。
背景技术:
2.大数据时代的诞生和蓬勃发展丰富着人们的线上体验,同时也便利着人们的线下生活。其诞生之初,在集海量多媒体大数据为一体的互联网平台上,人们首次能够阅读到相比纸质报刊更加实时的新闻、能够观看到相比传统电视更加丰富的视频、能够进行着相比久别重逢更加便利的交流。然而,随着大数据时代的日新月异,其面临的“数据过载”难题也愈加突出:由于信息的数量越来越多、质量越来越参差不齐,人们在如此嘈杂的信息环境中,不可避免地需要花费更多的时间和精力来从中筛选出对自己更有价值的一部分。为了解决这一难题,大数据时代的蓬勃发展为如今带来了一项全新的技术:推荐系统。通过分析用户偏好和提取物品(比如:新闻或视频)特征来对用户和物品进行匹配,推荐系统能够自动化地为用户在海量信息中预测并筛选出他们最感兴趣的一部分。诸如,“今日头条”定制的个性化专栏,“抖音”推送的感兴趣视频,“淘宝”首页的相关联商品等等,无不降低了人们对信息的筛选成本、丰富了人们对信息的感官体验、便利了人们对信息的实际运用。显然,在大数据时代下,推荐系统已然成为了一项不可或缺的信息技术。
3.目前,作为推荐系统的核心成分,推荐模型的构造已从传统方法论迈入到机器学习方法论。相比之下,基于传统方法论的推荐模型更加注重模型的可解释性,即解释清楚“为什么会向这位用户推荐这个物品”,而基于机器学习方法论的推荐模型更加注重模型的准确性,即“推荐物品中有多少是用户真正感兴趣的”。不可否认,由于前者大多不具备特征识别与挖掘能力,后者能够发挥出超越前者的模型准确性,尤其是在大数据上。然而,由于机器学习的基于多项式逼近理论的这一“黑箱”特性,后者往往不具备良好的可解释性。模型超参数的设置是其中的一个主要原因,同时还是一个困扰学术界和工业界的世纪难题:如何花尽可能少的人力和算力等资源,尽可能快地搜索出一组能够使得特定模型的表现最优的模型超参数。
技术实现要素:
4.本发明提供了一种基于自适应性节点特征生成的信息推荐方法。其结合了传统推荐模型的可解释性优势,以及基于机器学习的推荐模型的特征识别与挖掘能力,在不涉及到用户隐私信息的条件下,基于网络结构的方法实现了一种精确、可解释、无超参数以及具有特征识别与挖掘能力的推荐方法。
5.为了达到上述目标,本发明采取的技术方案如下:
6.s1、从推荐系统中的数据库出发,将m位用户和n个物品的交互记录构造为“用户-物品”二部图g=(v,e);
7.s2、基于二部图g,构造出邻接矩阵am×n;
8.s3、基于邻接矩阵am×n,构造出对称矩阵b
(m+n)
×
(m+n)
;
9.s4、将对称矩阵b
(m+n)
×
(m+n)
进行矩阵的谱分解,得到m+n个(m+n)
×
(m+n)维的矩阵{bi,i=1,2,...,m+n}及其对应的m+n个特征值{λi,i=1,2,...,m+n};
10.s5、将一种对全图的图嵌入算法degree-h-index-coreness entropy(dhc-e)依次作用到{bi,i=1,2,...,m+n}中的每一个矩阵,生成m+n个s维向量{fi,i=1,2,...,m+n}。
11.s6、将{fi,i=1,2,...,m+n}中的每一个向量对应到二部图g=(v,e)中的节点,作为节点的特征向量,即用户或物品的特征向量;
12.s7、根据步骤s6中生成的m位用户和n个物品的s维特征向量{fi,i=1,2,...,m+n},构造出用户的特征矩阵和物品的特征矩阵
13.s8、用相似性度量指标作用到用户的特征矩阵和物品的特征矩阵计算得到“用户-物品”相似性度量矩阵sm×n;
14.s9、分别对“用户-物品”相似性度量矩阵sm×
n“按行”和“按列”进行归一化和求权重处理,得到用户的权重矩阵和物品的权重矩阵
15.s10、基于步骤s2构造出的邻接矩阵am×n和步骤s9构造出的用户的权重矩阵及物品的权重矩阵计算得出“用户-物品”评分矩阵rm×n;
16.s11、基于“用户-物品”评分矩阵rm×n对用户实施信息推荐。
17.进一步地,所述步骤s1中,v=v1∩v2,其中v1代表用户的集合,v2代表物品的集合,e代表“用户-物品”交互,且仅存在于v1和v2之间。当任意用户与任意物品发生过交互,则二部图g中对应的用户和物品之间存在一条连边。该转换为推荐模型的实施提供了匹配的输入数据组织形式。
18.进一步地,上述步骤s2中,构造出的邻接矩阵am×n是一个行名为用户编号、列名为物品编号的m
×
n维的矩阵。当任意用户i和任意物品j之间在二部图g中存在一条连边时,邻接矩阵am×n中位置(i,j)的元素值为1,否则值为0。该转换为节点特征生成方法提供了匹配的输入数据组织形式。
19.进一步地,上述步骤s3中,其中o为零矩阵,即元素全为0的矩阵。该构造为矩阵的谱分解提供了必要的先决条件。
20.进一步地,上述步骤s4中,由于b
(m+n)
×
(m+n)
是一个对称矩阵,则它是一个单纯矩阵,则它是一个正规矩阵。因此,根据矩阵的谱分解定理,有
21.进一步地,上述步骤s5中,以{bi,i=1,2,...,m+n}中的任意一个矩阵bi为例,通过将dhc-e算法作用到矩阵bi生成一个si维向量的具体过程如下:
22.a1、通过将非零元素转换为1,零元素仍然为0,基于矩阵b
i(m+n)
×
(m+n)
构造出邻接矩阵c
i(m+n)
×
(m+n)
;
23.a2、根据步骤s2中基于图g构造出邻接矩阵am×n的方法,实施其逆过程,从而能够基于邻接矩阵c
i(m+n)
×
(m+n)
构造图gi;
24.a3、分别计算出图gi中m+n个节点的度值,记为将其作为香农熵计算公式的输入,计算得到香农熵h
(0)
;
25.a4、定义任意节点i的值为“节点i至少有个邻居的值不小于”中的最大值。分别计算出图gi中m+n个节点的值,记为值,记为将其作为香农熵计算公式的输入,计算得到香农熵h
(1)
;
26.a5、用同样的方法迭代地定义任意节点i的值,即任意节点i的值为“节点i至少有个邻居的值不小于”中的最大值,以及值,...分别迭代地计算出h
(2)
,h
(3)
,...;
27.a6、根据dhc定理,任意节点i的hi值最终将在si步迭代后收敛至即该节点在图gi中的k-core值。计算出
28.a7、取图g中m+n个节点的生成向量中最大向量维度为s;
29.a8、对g中任意节点i,其生成向量维度为si。若si《s,则用该节点生成向量的最后一个元素进行填补,使该节点的填补后的生成向量维度为s。此时,该节点的填补后的生成向量记为fi。
30.进一步地,上述步骤s6中,对于任意fi,若i≤m,则fi对应于图g中的第i位用户的特征向量;若m《i≤m+n,则fi对应于图g中的第i-m个物品的特征向量。
31.进一步地,上述步骤s7中,分别将用户和物品对应的特征向量{fi,i=1,2,...,m+n}按行拼接成用户的特征矩阵和物品的特征矩阵
32.进一步地,上述步骤s8中,本发明所使用的相似性度量指标包括“皮尔逊相关系数”计算指标、“余弦相似性”计算指标、“点积”计算指标、“协方差”计算指标和“欧氏距离”计算指标。以“皮尔逊相关系数”计算指标为例:其中
[0033][0034][0035]
通过相似性矩阵,计算得到用户和物品之间的相似性,表征出用户对物品的偏好,以及物品对用户的吸引力等实际含义。
[0036]
进一步地,上述步骤s9中,基于上一步表征出的用户对物品的偏好,以及物品对用户的吸引力,为基于网络结构的推荐方法中的资源传播过程设置了权重。以“按行”为例,由“用户-物品”相似性度量矩阵sm×n得到用户的权重矩阵的过程中,进行的归一化处理为其中代表hadamard乘积。进行的求权重处理为代表hadamard乘积。进行的求权重处理为
[0037]
进一步地,上述步骤s10中,计算得出“用户-物品”评分矩阵rm×n所采用的公式为:
[0038]
进一步地,上述步骤s11中,基于“用户-物品”评分矩阵rm×n对用户实施信息推荐的
方法为:对任意用户i,将其在rm×n中对应的行向量r
i*
中的元素值进行降序排列,截选出前k个元素值所对应的物品编号作为对该用户的top-k推荐结果。
[0039]
本技术方案的技术效果是:借助于网络科学领域的相关研究成果,本发明首创性地提出了用节点影响力来表征节点特征属性的策略,实现了一种具备良好的可解释性的自适应性节点特征生成的方法。
附图说明
[0040]
图1是在分别固定特征向量维度为16、32、48、64和128的条件下,本发明提供的推荐方法与一些在工业界落地的基于机器学习的推荐方法在模型精确性方面的对比测试结果;其中,recall@10、mrr@10和precision@10是3个衡量在推荐列表长度为10的条件下推荐结果准确性的指标;图例标签中括号里的数字为对应推荐方法的超参数个数;
[0041]
图2是在分别固定学习率为0.001、0.005、0.01、0.05和0.1的条件下,本发明提供的推荐方法与一些在工业落地的基于机器学习的推荐方法在模型精确性方面的对比测试结果;
[0042]
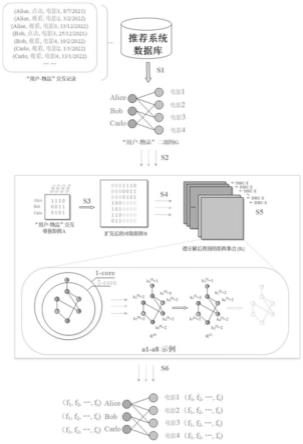
图3是本发明提供的自适应性节点特征生成方法的具体实施示例图;
[0043]
图4是本发明提供的基于自适应性节点特征生成的推荐方法的具体实施示例图。
具体实施方式
[0044]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0045]
推荐系统中对用户和物品的特征属性提取,本质上是为了更好地理解用户的需求和刻画物品的属性。相比于基于机器学习方法所拟合出的不具备可解释性的特征属性。该方法具备了与机器学习类似的特征识别与挖掘能力,能够识别和挖掘出用户和物品在不同的推荐系统中所隐含的多维影响力因子。该方法能够提取和表征每一位用户和每一个物品对推荐系统的全局影响形式。即被矩阵bi所表征的用户或物品的“画像”,以不同的λi为权重,共同还原出推荐系统中用户和物品的交互场景。对于任意用户或物品的全局影响矩阵bi,用dhc定理迭代生成的{hi,i=1,2,...,m+n}提取出了它们在推荐系统中的影响因子。再用dhc-e算法对每一步迭代过程中的该影响因子计算香农熵,进而融合该用户或物品的影响力。最终能够生成该用户或物品的多维影响力。由该方法生成的用户或物品的属性特征,是可解释且无超参数的。
[0046]
基于用户和物品的特征属性,用可解释的相似性度量指标还生成“用户-物品”相似性矩阵。基于该矩阵,为一种基于网络结构的传统推荐方法中的资源传播过程设置了权重,实现了一种可解释、无超参数的推荐方法。该方法能够溯源到用户对物品的偏好成因,助于对业务场景及模型的构造思路的完善。
[0047]
通过基于网络结构的推荐方法实现了推荐过程的无超参数和可解释性,同时赋予了基于网络结构的推荐方法特征识别与挖掘能力,提高了推荐结果的准确性,测试效果请参见图1和图2,其中将本发明提供的推荐方法命名为aiprobs。本发明提供的方法,比起基于机器学习的推荐方法,在推荐结果的准确性和稳定性方面整体更优,且不会面临因超参数设置不同而导致模型性能波动的问题。
[0048]
实施例
[0049]
请参照图3,本实施例在一个由3位用户(分别是alice、bob和carlo)、4个物品(分别是电影1、电影2、电影3和电影4)及它们之间的交互记录所组成的推荐系统,具体如下:
[0050]
s1、从推荐系统中的数据库出发,这3位用户和4个物品的7条交互记录构造为“用户-物品”二部图g。
[0051]
在本实施例中,当任意用户与任意物品发生过交互,则二部图g中对应的用户和物品之间存在一条连边。比如,在数据库中alice和电影1之间存在“点击”交互,因此在二部图g中alice和电影1分别对应的节点之间存在一条连边。
[0052]
s2、基于二部图g,构造出邻接矩阵am×n。
[0053]
在本实施例中,构造出的邻接矩阵a3×4是一个行名为用户编号、列名为物品编号的3
×
4维的矩阵。当任意用户i和任意物品j之间在二部图g中存在一条连边时,邻接矩阵a3×4中位置(i,j)的元素值为1,否则值为0。比如,在二部图g中alice节点和电影1节点之间存在一条连边,则矩阵a中对应位置(alice,电影1)的元素值为1。
[0054]
s3、基于邻接矩阵am×n,构造出对称矩阵b
(m+n)
×
(m+n)
。
[0055]
在本实施例中,其中o为零矩阵,即元素全为0的矩阵。
[0056]
s4、将对称矩阵b7×7进行矩阵的谱分解,得到7个7
×
7维的矩阵{bi,i=1,2,...7}及其对应的7个特征值{λi,i=1,2,...,7}。
[0057]
在本实施例中,由于b7×7是一个对称矩阵,则它是一个单纯矩阵,则它是一个正规矩阵。因此,根据矩阵的谱分解定理,有
[0058]
s5、通过将dhc-e算法作用到7个矩阵{bi,i=1,2,...7}分别生成一个si维向量。
[0059]
在本实施例中,对于其中的任意矩阵b
i7
×7,为其生成特征向量的具体过程如下:
[0060]
a1、通过将非零元素转换为1,零元素仍然为0,基于矩阵b
i7
×7构造出邻接矩阵c
i7
×7;
[0061]
a2、根据步骤s2中基于图g构造出邻接矩阵a7×7的方法,实施其逆过程,从而能够基于邻接矩阵c
i7
×7构造图gi;
[0062]
a3、分别计算出图gi中7个节点的度值,记为将其作为香农熵计算公式的输入,计算得到香农熵h
(0)
;
[0063]
a4、定义任意节点i的值为“节点i至少有个邻居的值不小于”中的最大值。分别计算出图gi中m+n个节点的值,记为值,记为将其作为香农熵计算公式的输入,计算得到香农熵h
(1)
;
[0064]
a5、用同样的方法迭代地定义任意节点i的值,即任意节点i的值为“节点i至少有个邻居的值不小于”中的最大值,以及值,...。分别迭代地计算出h
(2)
,h
(3)
,...;
[0065]
a6、根据dhc定理,任意节点i的hi值最终将在si步迭代后收敛至即该节点在图gi中的k-core值。计算出
[0066]
a7、取图g中m+n个节点的生成向量中最大向量维度为s;
[0067]
a8、对g中任意节点i,其生成向量维度为si。若si《s,则用该节点生成向量的最后一个元素进行填补,使该节点的填补后的生成向量维度为s。此时,该节点的填补后的生成向量记为fi。
[0068]
s6、将{fi,i=1,2,...,m+n}中的每一个向量对应到二部图g=(v,e)中的节点,作为节点的特征向量,即用户或物品的特征向量。
[0069]
在本实施例中,对于任意fi,若i≤3,则fi对应于图g中的第i位用户的特征向量;若3《i≤7,则fi对应于图g中的第i-3个物品的特征向量。
[0070]
请参照图4。基于图3的步骤s6后生成的用户和物品的特征属性,实施推荐方法,具体如下:
[0071]
s7、根据步骤s6中生成的3位用户和4个物品的s维特征向量{fi,i=1,2,...,7},构造出用户的特征矩阵和物品的特征矩阵
[0072]
在本实施例中,分别将用户和物品对应的特征向量{fi,i=1,2,...,7}按行拼接成用户的特征矩阵和物品的特征矩阵
[0073]
s8、用相似性度量指标作用到用户的特征矩阵和物品的特征矩阵计算得到“用户-物品”相似性度量矩阵s3×4。
[0074]
在本实施例中,本发明所使用的相似性度量指标包括“皮尔逊相关系数”计算指标、“余弦相似性”计算指标、“点积”计算指标、“协方差”计算指标和“欧氏距离”计算指标。以“皮尔逊相关系数”计算指标为例:其中
[0075][0076][0077]
s9、分别对“用户-物品”相似性度量矩阵s3×
4“按行”和“按列”进行归一化和求权重处理,得到用户的权重矩阵和物品的权重矩阵w
i3
×4。
[0078]
在本实施例中,以“按行”为例,由“用户-物品”相似性度量矩阵s3×4得到用户的权重矩阵的过程中,进行的归一化处理为的过程中,进行的归一化处理为其中代表hadamard乘积。进行的求权重处理为hadamard乘积。进行的求权重处理为
[0079]
s10、基于步骤s2构造出的邻接矩阵a3×4和步骤s9构造出的用户的权重矩阵及物品的权重矩阵计算得出“用户-物品”评分矩阵r3×4。
[0080]
在本实施例中,计算得出“用户-物品”评分矩阵rm×n所采用的公式为:
[0081]
s11、基于“用户-物品”评分矩阵r3×4对用户实施信息推荐。
[0082]
在本实施例中,基于“用户-物品”评分矩阵r3×4对用户实施信息推荐的方法为:对任意用户i,将其在rm×n中对应的行向量r
i*
中的元素值进行降序排列,截选出前k个元素值所对应的物品编号作为对该用户的top-k推荐结果。
[0083]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1