一种基于NLP的数据脱敏方法与流程
一种基于nlp的数据脱敏方法
技术领域
1.本发明涉及自然语言处理技术领域,特别涉及一种基于nlp的数据脱敏方法。
背景技术:
2.在大数据时代下,通过大数据分析等手段,海量数据中隐藏的价值得以挖掘;但大数据分析也带来用户隐私信息泄漏与关键性敏感数据保护失效等方面的问题。为规避数据风险,相关技术中采用数据脱敏技术以进行数据保护。其中,保护个人隐私、确保信息安全的“数据脱敏”环节是关键环节。但目前的数据脱敏大多依靠人工手动处理,存在处理效率低、手动产生的随机误差多等问题,最终导致数据不具备开放、应用支撑条件。因此,急需一种高效、准确、系统化的个人数据脱敏方法来解决这一问题。
3.目前数据脱敏技术已经广泛应用于对隐私信息的保护,防止敏感信息的泄露。通过命名体识别技术可以实现对不同关键词的信息筛选。例如公开号为cn111709052a的发明专利提提出了一种隐私数据识别和处理方法、装置、设备和可读介质,主要以bieo标注方式(即,采用begin,intermediate,end,other标注)。采用了命名体识别模型来识别隐私数据,通过序列标注的方式进行数据中隐私序列的识别。然而,该现有技术无法对表格中的信息进行提取脱敏,其次,其正则筛选覆盖内容不够全面。
技术实现要素:
4.发明目的:针对现有技术存在的数据脱敏处理效率低、随机误差多的问题,本发明提供一种基于nlp的数据脱敏方法,能够显著提高数据脱敏的可靠性和易用性。
5.技术方案:一种基于nlp的数据脱敏方法,包括如下步骤:
6.(1)根据机器视觉,对文本内容进行识别,然后进行格式转换,将表格型文件转换为可编辑文件txt;
7.(2)对步骤(1)得到的可编辑文件txt进行分割处理;
8.(3)通过自然语言处理,采用bert-bilstm-crf模型进行命名体识别;
9.(4)利用正则表达式,使用规则筛选出身份证号和手机号码;
10.(5)对步骤(3)以及步骤(4)的结果进行脱敏,输出脱敏后文件数据。
11.进一步的,步骤(1)中,采取基于光学字符识别预判断的表格文件转换方法将表格型文件转换为可编辑文件txt,具体内容如下:
12.首先解析表格文件,判断该表格文件中各处是否需要进行光学字符识别;
13.针对需要进行光学字符识别的页面,通过光学字符识别得到文本信息;针对不需要进行光学字符识别的页面,直接从表格文件中文本对象的文字编码信息中提取文本信息;
14.最后通过表格解析算法和office文件重构算法将得到的文本信息变成对应的可编辑文档txt。
15.进一步的,步骤(2)包括如下内容:
16.(2.1)得到可编辑文档txt后,按文档的先后次序依次进行文本处理,将各个文本中的数据在句号处切断,完成对文本内容的分句初始划分;所述文本中的数据包括通过光学字符识别得到的文本信息以及直接从表格文件中文本对象的文字编码信息中提取的文本信息;
17.(2.2)采用垂直投影法切分字符,得到分割块;
18.(2.3)采用字宽融合校正法纠正错误切分的字符。
19.优选的,在垂直投影法和字宽融合校正法之间,还包括极值去除的步骤,具体内容如下:
20.首先计算分割块的宽度均方误差和宽度初始均值,然后计算分割块的宽度与宽度初始均值的差值:
[0021][0022]
变量表示分割块宽度和宽度初始均值之间的差异;常数表示原始计算的宽度初始均值;常数m表示输入图像中文本分割块的数量,变量wi表示输入图像中文本的每个分段的宽度,i值取自0到m;
[0023]
将分割块的宽度均方误差放在如下高斯正态分布函数中:
[0024][0025]
通过高斯正态分布函数将预设范围内的坏值表示出来;
[0026]
重新计算字宽融合校正的自适应阈值(即宽度均值),公式如下:
[0027][0028]
其中w
β
表示自适应阈值,ω
l
表示从过小概率中排除的一组可能的坏值概率;
[0029]
将去除掉坏值的分割块重新纳入计算,所述去除掉坏值的分割块满足自适应阈值w
β
的要求。
[0030]
进一步的,在命名体识别中,条件随机场crf被嵌入到bilstm模块中来作为输出;对于一个句子instance={x1,x2,......xn},其中xi是句子中的文字,将其输入识别框架,得到预测序列,其概率公式表示为:
[0031][0032]
其中,x为句子instance={x1,x2,......xn}中词向量和词信息特征向量的组合;t是转移矩阵,t
yi,yi+1
表示标签yi转移到yi+1的概率,并且分别表示句子的开始和结束标签;p是bilstm输出的分数矩阵,p
i,yi
表示句子的第i个词映射到该词的非归一化概率yi标签;score(x,y)的预测有多种可能性,得分概率分类输出通过softmax层实现,概率最高的y为正确的序列标签,表示为:
[0033][0034]
进一步的,对于序列隐私类型为“手机号”的隐私序列,使用如下正则表达式一:
[0035]
(^13\d{7,11}|^14[5|7]\d{6,10}|^15\d{7,11}
[0036]
|^166\d{6,10}|^17[3|6|7]\d{6,10}|^18\d{7,11})
[0037]
正则表达式一的筛选过程如下:
[0038]
s1:^从当前位置开始匹配;
[0039]
s2:在满足s1的情况下,13表示前两位数字是13,\d表示匹配一个数字字符,{7,11}表示量词可以重复前面匹配的字符7-11次,搭配\d{7,11}就是表示匹配一个7到11位的数字字符;或者在满足s1的情况下,14表示前两位数字是14,[5|7]表示匹配字符为5或者字符为7的任意一个,\d{6,10}表示匹配一个6位到10位的数字字符;或者在满足s1的情况下,15表示前两位数字是15,\d表示匹配一个数字字符,{7,11}表示量词可以重复前面匹配的字符7-11次,搭配\d{7,11}就是表示匹配一个7到11位的数字字符;或者在满足s1的情况下,166表示前三位数字是166,\d表示匹配一个数字字符,{6,10}表示量词可以重复前面匹配的字符6-10次,搭配\d{6,10}就是表示匹配一个6到10位的数字字符;或者在满足s1的情况下,17表示前两位数字是17,[3|6|7]表示匹配字符为3或者字符为6或者字符为7中任意一个,\d表示匹配一个数字字符,{6,10}表示量词可以重复前面匹配的字符6-10次,搭配\d{6,10}就是表示匹配一个6到10位的数字字符;或者在满足s1的情况下,18表示前两位数字是18,\d表示匹配一个数字字符,{7,11}表示量词可以重复前面匹配的字符7-11次,搭配\d{7,11}就是表示匹配一个7到11位的数字字符。
[0040]
进一步的,对于序列隐私类型为“身份证号”的隐私序列,使用如下正则表达式二:
[0041]
(^1[1,2,4,5]\d{13,17}x$|^1[1,2,4,5]\d{13,17}x$|^1[1,2,4,5]\d{14,18}
[0042]
|^[2,3,4,5,6]\d{14,18}x$|^[2,3,4,5,6]\d{14,18}x$|^[2,3,4,5,6]\d{15,19})
[0043]
正则表达式二的筛选过程如下:
[0044]
s1’:^表示从当前位置开始匹配,$表示匹配前表达式结尾。
[0045]
s2’:在满足s1’的情况下,1表示以数字1作为第一个字符,[1,2,4,5]表示第二位是字符1,2,4,5中任意一个,\d表示匹配一个数字字符,{13,17}表示量词可以重复前面匹配的字符13-17次,搭配\d{13,17}就是表示匹配一个13到17位的数字字符,x$表示最后一位字符是x;或者在满足s1’的情况下,1表示以数字1作为第一个字符,[1,2,4,5]表示第二位是字符1,2,4,5中任意一个,\d表示匹配一个数字字符,{13,17}表示量词可以重复前面匹配的字符13-17次,搭配\d{13,17}就是表示匹配一个13到17位的数字字符,x$表示最后一位字符是x;在满足s1’的情况下,1表示以数字1作为第一个字符,[1,2,4,5]表示第二位是字符1,2,4,5中任意一个,\d表示匹配一个数字字符,{14,18}表示量词可以重复前面匹配的字符14-18次,搭配\d{14,18}就是表示匹配一个14到18位的数字字符;或者在满足s1’的情况下,[2,3,4,5,6]表示第一位是字符2,3,4,5,6中任意一个,\d表示匹配一个数字字符,{14,18}表示量词可以重复前面匹配的字符14-18次,搭配\d{14,18}就是表示匹配一个14到18位的数字字符,x$表示最后一位字符是x;或者在满足s1’的情况下,[2,3,4,5,6]表示第一位是字符2,3,4,5,6中任意一个,\d表示匹配一个数字字符,{14,18}表示量词可以重复前面匹配的字符14-18次,搭配\d{14,18}就是表示匹配一个14到18位的数字字符,x$表示最后一位字符是x;或者在满足s1’的情况下,[2,3,4,5,6]表示第一位是字符2,3,4,5,6中任意一个,\d表示匹配一个数字字符,{15,19}表示量词可以重复前面匹配的字符15-19次,搭配\d{15,19}就是表示匹配一个15到19位的数字字符。
[0046]
进一步的,采用原文输出或者字符替换两种方式进行脱敏;
[0047]
所述原文输出只对读取的数据进行拼接,不做处理原文输出,写入结果文件,主要针对不涉及个人隐私和分析需要的数据项;
[0048]
所述字符替换读取每条数据的加密字段,对需要替换的字段以*替换,输出为****,实现隐藏敏感信息,拼接所有字段,最后将替换字符后的完整数据写入文件。
[0049]
有益效果:
[0050]
1、本发明将原本繁杂的数据按指定方式分隔开,更加方便数据的处理。
[0051]
2、本发明基于自然语言处理,通过使用预设处理算法对数据进行自然语言处理,得到语言处理结果;然后根据用户需求制定与语言处理结果对应的脱敏策略,即可得到脱敏后的数据,由于这种脱敏方式是机器直接根据自然语言进行处理并脱敏的,因此只需要提供用户需求即可,不需要人工干预,配置成本低,提高了数据脱敏的可靠性和易用性。
附图说明
[0052]
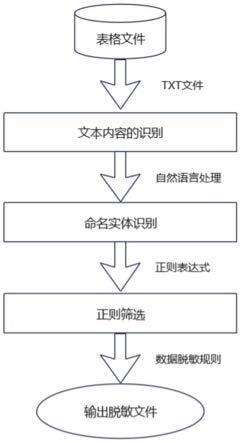
图1是本发明实施例提供的一种基于nlp的数据脱敏方法的流程图。
具体实施方式
[0053]
为了使本技术领域的人员更好的理解本发明方案,下面将结合说明书附图和实施例,对本发明的技术方案进行清楚、完整的解释和说明。
[0054]
如图1所示,一种基于nlp(nature language processing,nlp)的数据脱敏方法,包括以下步骤:
[0055]
步骤1:根据机器视觉,对文本内容进行识别,然后进行格式转换,将表格型文件转换为可编辑文件txt。
[0056]
步骤2:按需求对步骤1得到的txt文件进行处理。
[0057]
步骤3:通过自然语言处理,利用bert-bilstm-crf模型进行命名体识别。
[0058]
步骤4:利用正则表达式,使用规则筛选出身份证号和手机号码。
[0059]
步骤5:对步骤3以及步骤4的结果进行脱敏,并输出脱敏后文件数据。
[0060]
步骤1中,对文件格式的转换的具体内容如下:
[0061]
采取基于ocr(optical character recognition,光学字符识别)预判断的表格文件转换方法。
[0062]
首先解析表格文件,判断该表格文件中各处是否需要进行ocr。
[0063]
其次,针对需要进行ocr的页面,则通过光学字符识别得到文本信息;针对不需要进行ocr的页面则直接从该表格中文本对象的文字编码信息中提取文本。
[0064]
最后通过表格解析算法和office文件重构算法将得到的文本信息变成对应的可编辑文档txt。
[0065]
对所获得的可编辑文档txt进行如下处理:
[0066]
步骤2.1得到可编辑文档txt后,按文档的先后次序依次进行文本处理,将各个文本中的数据在句号处切断,完成对文本内容的分句初始划分;其中,文本中的数据包括通过光学字符识别得到的文本信息以及直接从表格文件中文本对象的文字编码信息中提取的文本信息。
[0067]
步骤2.2采用垂直投影法切分字符,得到分割块。
[0068]
步骤2.3采用字宽融合校正法纠正错误切分的字符。
[0069]
为了获得高精度的分割结果,在步骤2.2的垂直投影法和步骤2.3的字宽融合校正法之间设计了高斯极值去除模块,垂直投影法进行切分是单个字符,高斯极值去除模块能够实现极值去除,最后采用字宽融合法进行自适应文本字宽融合以获得更好的文本切分结果。
[0070]
极值去除的具体步骤如下:
[0071]
首先计算分割块的宽度均方误差和宽度初始均值,然后计算分割块的宽度与宽度初始均值的差值,利用高斯分布函数计算极值;
[0072]
计算过程如下:
[0073][0074]
变量表示分割块宽度和宽度初始均值之间的差异;常数表示原始计算的宽度初始均值;常数m表示输入图像中文本分割块的数量,变量wi表示输入图像中文本的每个分段的宽度,i值取自0到m;
[0075]
然后将分割块的宽度均方误差放在如下高斯正态分布函数中:
[0076][0077]
通过高斯正态分布函数将预设范围内的坏值表示出来。
[0078]
重新计算字宽融合校正的自适应阈值(即宽度均值),公式如下:
[0079][0080]
其中w
β
表示自适应阈值,ω
l
表示从过小概率中排除的一组可能的坏值概率。
[0081]
将分割块中的坏值滤除,重新纳入计算,能够重新纳入计算范围的分割块满足高斯正态分布函数所对应的自适应阈值的要求。
[0082]
进一步地,基于变压器的双向编码器表示(bidirectional encoder representation from transformers,bert),利用双向长短期记忆神经网络模型(biomedical long short-term memory,bilstm)结合条件随机场(conditional random field,crf)进行命名体识别(named entity recognition,ner),具体内容如下:
[0083]
先从网络下载所需的人名数据集,国家省市数据集等,然后选择了bert-bilstm-crf模型进行命名体识别。bert的输入表示是三种embeddings的直接相加。其中,token embeddings表示为词向量,position embeddings表示位置信息。由于基于自注意力机制(self-attention)的模型无法感知每个词之间的位置关系,所以需要使用position embeddings来标记每个词的序列顺序信息。segment embeddings用于多个句子之间的分割向量。
[0084]
bert使用基于微调的多层双向transformer作为编码器。encoder和decoder部分都使用了transformer,这样句子中的每个文字都可以直接与句子中其他的任何文字进行编码,而不管方向或距离,而其中self-attention部分是最重要的模块。transformer完全
基于注意力机制对文本进行建模,如公式(4)所示:
[0085][0086]
q、k、v是输入词向量矩阵,dk是输入向量的维度,qk
t
用于计算输入词向量之间的关系,通过softmax归一化得到权重表示。最后,输出是句子中所有词向量的加权和,这样每个字表示包含了句子中其他字的信息,这比传统的词嵌入更具有上下文相关性和全局性。
[0087]
每个文字都可以合并它左右两侧的信息。encoder的每个模块都包含一个多头自注意力机制(multi-head self-attention)和一个全连接的前馈网络。多头注意力是指计算多个注意力,每个注意力集中在句子中的不同信息上,然后将所有注意力信息拼接在一起,如下式(5)(6)所示,w0是附加权重矩阵:
[0088]
multihead(q,k,v)=concat(head1,.....headk)w0(5)
[0089]
headi=attention(qw
iq
,kw
ik
,vw
iv
)
ꢀꢀꢀꢀꢀꢀꢀ
(6)
[0090]
此外,在transformer中加入了残差网络和归一化层来改善退化问题,如下公式(7)(8):
[0091][0092]
fnn=max(0,xw1+b1)w2+b2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0093]
α和β是要学习的参数,v是均值,σ是输入层的方差。与其他词嵌入模型相比,bert预训练语言模型可以充分利用上下文信息来获得更好的词向量表示。
[0094]
在命名体识别中,输出标签之间存在很强的依赖性。crf可以通过考虑相邻标签之间的关系来获得全局最优标签序列。在本发明中,crf被嵌入到bilstm模块中来作为输出。对于一个句子instance={x1,x2,......xn},其中xi是句子中的文字,将其输入识别框架,得到预测序列,其概率公式(9)如下表示为:
[0095][0096]
其中,x为句子instance={x1,x2,......xn}中词向量和词信息特征向量的组合;t是转移矩阵,t
yi,yi+1
表示标签yi转移到yi+1的概率,并且分别表示句子的开始和结束标签。p是bilstm输出的分数矩阵,p
i,yi
表示句子的第i个词映射到该词的非归一化概率yi标签。score(x,y)的预测有很多可能性。得分概率分类输出通过softmax层实现,概率最高的y为正确的序列标签,如公式(10)所示:
[0097][0098]
关于使用正则筛选身份证号以及手机号的具体实现方式如下:
[0099]
正则表达式(regular expression),又称正则表示法、规则表达式、常规表示法,它是基于约定的语法规则,构建单个字符串来描述、匹配一系列符合某个句法规则的字符串。re.compile()是用来优化正则的,它将正则表达式转化为对象,再通过re.search,就转换为pattern.search(string)的调用方式,多次调用一个正则表达式就重复利用这个正则对象,可以实现更有效率的匹配。
[0100]
对于序列隐私类型为“手机号”的隐私序列,可以使用如下正则表达式(11):
[0101][0102]
公式(11)的处理过程如下:
[0103]
第一步:^从当前位置开始匹配。
[0104]
第二步:在满足第一步的情况下,13表示前两位数字是13,\d表示匹配一个数字字符,{7,11}表示量词可以重复前面匹配的字符7-11次,搭配\d{7,11}就是表示匹配一个7到11位的数字字符。或者在满足第一步的情况下,14表示前两位数字是14,[5|7]表示匹配字符为5或者字符为7的任意一个,\d{6,10}表示匹配一个6位到10位的数字字符。或者在满足第一步的情况下,15表示前两位数字是15,\d表示匹配一个数字字符,{7,11}表示量词可以重复前面匹配的字符7-11次,搭配\d{7,11}就是表示匹配一个7到11位的数字字符。或者在满足第一步的情况下,166表示前三位数字是166,\d表示匹配一个数字字符,{6,10}表示量词可以重复前面匹配的字符6-10次,搭配\d{6,10}就是表示匹配一个6到10位的数字字符。或者在满足第一步的情况下,17表示前两位数字是17,[3|6|7]表示匹配字符为3或者字符为6或者字符为7中任意一个,\d表示匹配一个数字字符,{6,10}表示量词可以重复前面匹配的字符6-10次,搭配\d{6,10}就是表示匹配一个6到10位的数字字符。或者在满足第一步的情况下,18表示前两位数字是18,\d表示匹配一个数字字符,{7,11}表示量词可以重复前面匹配的字符7-11次,搭配\d{7,11}就是表示匹配一个7到11位的数字字符。
[0105]
例如:^2[3|6|8]\d{5,8}。
[0106]
另一示例,对于序列隐私类型为“身份证号”的隐私序列,可以使用如下正则表达式(12):
[0107][0108]
公式(12)的处理过程如下:
[0109]
第一步:^表示从当前位置开始匹配,$表示匹配前表达式结尾。
[0110]
第二步:在满足第一步的情况下,1表示以数字1作为第一个字符,[1,2,4,5]表示第二位是字符1,2,4,5中任意一个,\d表示匹配一个数字字符,{13,17}表示量词可以重复前面匹配的字符13-17次,搭配\d{13,17}就是表示匹配一个13到17位的数字字符,x$表示最后一位字符是x。或者在满足第一步的情况下,1表示以数字1作为第一个字符,[1,2,4,5]表示第二位是字符1,2,4,5中任意一个,\d表示匹配一个数字字符,{13,17}表示量词可以重复前面匹配的字符13-17次,搭配\d{13,17}就是表示匹配一个13到17位的数字字符,x$表示最后一位字符是x。在满足第一步的情况下,1表示以数字1作为第一个字符,[1,2,4,5]表示第二位是字符1,2,4,5中任意一个,\d表示匹配一个数字字符,{14,18}表示量词可以重复前面匹配的字符14-18次,搭配\d{14,18}就是表示匹配一个14到18位的数字字符。或者在满足第一步的情况下,[2,3,4,5,6]表示第一位是字符2,3,4,5,6中任意一个,\d表示匹配一个数字字符,{14,18}表示量词可以重复前面匹配的字符14-18次,搭配\d{14,18}就是表示匹配一个14到18位的数字字符,x$表示最后一位字符是x。或者在满足第一步的情况下,[2,3,4,5,6]表示第一位是字符2,3,4,5,6中任意一个,\d表示匹配一个数字字符,{14,18}表示量词可以重复前面匹配的字符14-18次,搭配\d{14,18}就是表示匹配一个14到18位的数字字符,x$表示最后一位字符是x。或者在满足第一步的情况下,[2,3,4,5,6]表示第
一位是字符2,3,4,5,6中任意一个,\d表示匹配一个数字字符,{15,19}表示量词可以重复前面匹配的字符15-19次,搭配\d{15,19}就是表示匹配一个15到19位的数字字符。
[0111]
例如:^3[4,5]\d{14,18}或者^2[5,6,7]\d{14,18}x$。
[0112]
最后,采用原文输出、字符替换两种脱敏方式进行脱敏方式。
[0113]
原文输出方式:只对读取的数据进行拼接,不做处理原文输出,写入结果文件,主要针对不涉及个人隐私和分析需要的数据项。
[0114]
字符替换方式:读取的每条数据的加密字段,对需要替换的字段以*替换,输出为****,实现隐藏敏感信息,然后拼接所有字段,最后将替换字符后的完整数据写入文件。
[0115]
实施例:
[0116]
本实施例选择医院病人模拟数据作为输入数据集进行实验,并选择pycharm作为仿真平台。
[0117]
实验环境中所涉及的参数如表1所示。
[0118]
表1方法执行过程所涉及的参数设置
[0119]
实验参数取值姓名开头b-per姓名中间i-per地点开头b-loc地点中间i-loc其他o
[0120]
bert-bilstm-crf模型把识别任务当作序列标注任务来处理,模型输入是汉字序列,输出是标签序列。在命名实体识别任务上,bert-bilstm-crf已经取得良好效果,要素标注转换成序列标注时采用bio标签,其中b-xx表示要素xx的第一个汉字,要素的其他汉字标注为i-xx,而非要素汉字都标注为o。
[0121]
采用该参数设置可以更方便的实现对特定实体的识别提取,提高脱敏效率。
[0122]
可以更好的实现命名体识别。在模型中,对于输入的汉字序列,首先通过双向lstm来构造神经元特征,然后组合这些特征输入到crf层进行标签预测。整个模型分为三个主要部分:1)字向量表示:把输入字串表示为字向量,即把离散型输入转换成低维神经元输入;2)特征抽取:通过双向lstm和线性变换把字向量转换成神经元特征;3)实体标注:把特征输入到crf层,使用标注模块获取实体标签。
[0123]
综上,本发明根据机器视觉,利用光学字符识别法对文本内容进行识别,然后通过表格解析算法和office文件重构算法将得到的文本信息变成对应的可编辑文档txt,再利用垂直投影法结合高斯分布函数以及字宽融合法分割文本块,之后通过自然语言处理,利用bert-bilstm-crf模型进行命名体识别和正则表达式筛选出身份证号和手机号码,进而实现脱敏,并输出脱敏后文件数据。
[0124]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1