一种基于音频驱动的口罩下2D人脸还原技术
一种基于音频驱动的口罩下2d人脸还原技术
技术领域
1.本发明属于人脸生成领域,具体涉及一种基于音频驱动的口罩下2d人脸还原技术。
背景技术:
2.随着新冠疫情在全球范围流行,佩戴口罩成为了人们出行的常态,尤其是在公共场合。佩戴口罩虽然保障了安全,但在面部存在大范围遮挡的情况下,交流的有效性受到了极大的限制。根据麦格克效应,人们掌握的所有语言在一定程度上依赖于语言感知的视觉信息,在交流过程中,对方嘴唇活动以及面部表情所传递的信息也是至关重要的。
3.在高计算能力和先进技术进步的现代时代,许多曾经被认为不可能完成的复杂任务都得以实现。在人脸生成领域,已经有多个成功的模型和神经网络架构成功且有效地生成了真实的人类面孔。人脸生成作为近些年来的热门研究方向,吸引了许多研究者们的目光,具有良好的发展趋势。
4.通过音频驱动人脸生成,不仅要求展现目标的真实样貌,还要表现说话时的表情和面部动作,在实际应用中存在非常多的挑战,比如音源的稳定性、环境的复杂性、生成人脸的真实性和画面的连续性。
技术实现要素:
5.为解决上述问题,本发明公开了一种基于音频驱动的口罩下2d人脸还原技术,来真实还原说话者的完整人脸。通过音频解耦器,有效的分离了音频中包含的内容和情感信息,避免了两者之间的干扰,有效的增强了生成人脸的真实性和自然性。通过2d建模,提取了人脸的几何特征、面部装饰和肤色特征,估计出头部的三维欧拉角度,在保证生成说话人脸效果的同时有效解决了3d建模的困难和不稳定性。
6.为达到上述目的,本发明的技术方案如下:
7.一种基于音频驱动的口罩下2d人脸还原技术,包括如下步骤:
8.步骤1,获取训练视频的图像信息和与所述训练视频同步的音频信息,以及目标对象的源身份图像;
9.步骤2,在所述音频信息的基础上通过交叉重构法训练音频情感解耦器;
10.步骤3,通过特征提取网络从源身份图像中生成身份编码;
11.步骤4,对所述图像信息进行特征提取,得到每帧图像的头部姿态编码;
12.步骤5,音频情感解耦器对所述音频信息进行特征提取,得到每帧图像的情感编码;
13.步骤6:构建对抗生成网络,所述对抗生成网络用于生成渲染图像。根据身份编码、情感编码、头部姿态编码训练对抗生成网络。
14.步骤7:获得目标对象佩戴口罩的目标视频的图像信息和音频信息,重复步骤3、4、5,将得到的身份编码、情感编码、头部姿态编码作为条件信息,使用所述对抗生成网络进行
图像渲染,生成目标视频。
15.步骤1包括:
16.步骤1-1,获取的训练视频为单人正面无遮挡讲话视频。视频画面颜色为彩色,视频中人物讲话时间长度不限,3至5分钟为最佳,视频分辨率为720p、1080p,视频帧率为25帧/秒,视频的音频码率为128kb/s,音频采样率为44100hz。所述视频属性中,除视频时间长度和分辨率外,其他属性可根据实际情况自行设计。
17.步骤1-2,获取的目标对象的源身份图像为图片。图片颜色为彩色,分辨率720p、1080p,图片中人物正面面对摄像头,无遮挡,光线条件良好。
18.步骤2包括:
19.步骤2-1,对于所述音频信息,使用美尔频率倒谱系数作为音频表示得到音频向量;
20.步骤2-2,通过动态时间规整算法拉伸或者收缩音频向量,以得到长度、内容相同但情绪不同的音频训练对{x
i,m
,x
i,n
},其中x
i,m
,x
i,n
∈x,i表示内容相同,m,n分别表示两种不同的情绪;
21.步骤2-3,通过交叉重构法训练音频情感解耦器,训练得到内容编码器设置为ec、情感编码器设置为ee和解码器设置为d。
22.步骤2-1包括:
23.步骤2-1-1,对原始的视频音频重采样至固定采样频率;
24.步骤2-1-2,使用重采样后的音频,计算音频的频域特征,采用梅尔倒谱系数表示。
25.步骤2-3包括:
26.步骤2-3-1,编码解码器交叉重构损失,如公式(1)。情感编码器得到x
i,m
的情感编码与内容编码器得到x
j,n
的内容编码组合,根据解码器解码后得到音频编码x'
i,n
与x
i,n
计算损失,反向传播并训练所述编码解码网络,保证情感编码与内容编码的独立性。
27.l
cross
=||d(ec(x
i,m
),ee(x
j,n
))-x
i,n
||2+||d(ec(x
j,n
),ee(x
i,m
))-x
j,m
||2ꢀꢀ
(1)
28.步骤2-3-2,编码解码器自我重构损失,如公式(2)。同一段音频的情感编码与内容编码组合,根据解码器解码后得到的新音频与原音频计算损失,反向传播并训练所述编码解码网络,保证编码的完整性。
29.l
self
=||d(ec(x
i,m
),ee(x
i,m
))-x
i,m
||2+||d(ec(x
j,n
),ee(x
j,n
))-x
j,n
||2ꢀꢀ
(2)
30.步骤3,所述特征提取网络采用hourglass架构,包括下采样层、卷积层、上采样层和卷积层,输出k个三维点构成三维点云,包含人脸的几何特征、面部装饰和肤色特征。
31.步骤4包括:
32.步骤4-1,对于每帧进行人脸关键点检测,在口罩遮挡的情况下,得到眼部的二维人脸关键点。所涉及的关键点检测网络包括卷积层、瓶颈层、卷积层和全连接层。
33.步骤4-2,将所获的二维人脸关键点输入姿态估计网络,估计人脸的三维欧拉角,得到12维的头部姿态编码,包括9位旋转编码和三位偏转编码。所涉及的姿态估计网络包括卷积层和全连接层。
34.步骤5,通过训练得到的音频情感解耦器,输入目标视频的音频信息,得到情感编码。
35.步骤6包括:
36.步骤6-1,对抗生成网络自我评价;由于对抗生成网络采用的渐进式增长结构,对于生成器所生成的图像和训练所用的图像通过高斯平滑和亚采样获得一系列下采样图像,形成高斯金字塔,对于金字塔的每一层级n分别计算损失,反向传播训练对应分辨率的生成器网络,有损失函数
[0037][0038]
其中m表示样本数,disc为鉴别器,img
generated
为生成器生成的图像,img
real
为训练视频的图像信息;
[0039]
步骤6-2,特征提取网络的自我评价。
[0040]
步骤6-2包括,
[0041]
步骤6-2-1,特征提取网络的特征评价。根据生成图像与训练视频图像在同一位置的像素点计算特征提取网络损失,反向传播训练特征提取网络,有损失函数公式(4)
[0042][0043]
其中,h为输入的训练视频图像的高度,w为输入的训练视频图像的宽度,gen表示生成图像,real为输入的训练视频图像。
[0044]
步骤6-2-2,特征提取网络的点云分布评价。为避免三维点云的信息冗余,根据点云u中k个点之间的欧氏距离计算距离损失函数,反向传播训练特征提取网络,有损失函数公式(5)。
[0045][0046]
步骤6-3,对抗生成网络姿态评价。计算生成人脸和训练视频图像信息对应帧中人脸的头部姿态编码之间的欧氏距离,作为姿态损失反向传播训练生成网络;
[0047]
步骤6-4,对抗生成网络情感评价。获得生成人脸和训练视频图像信息对应帧中人脸,分别提取二维关键点,得到对应的关键点集合p
gen
,p
real
,根据关键点集合p
gen
,p
real
计算情感损失,如公式(6),反向传播训练生成网络;
[0048][0049]
步骤7包括:
[0050]
步骤7-1,获取的条件视频为单人讲话视频。视频中人物的动作为佩戴口罩的讲话视频,视频画面颜色为彩色,视频中人物讲话时间长度不限,视频分辨率为720p、1080p,视频帧率为25帧/秒,视频的音频码率为128kb/s,音频采样率为44100hz。所述视频属性中,除视频时间长度和分辨率外,其他属性可根据实际情况自行设计。
[0051]
步骤7-2,通过特征提取网络从源身份图像中生成身份编码;
[0052]
步骤7-3,对所述图像信息进行特征提取,得到每帧图像的头部姿态编码;
[0053]
步骤7-4,音频情感解耦器对所述音频信息进行特征提取,得到每帧图像的情感编码;步骤7-5,将得到的身份编码、情感编码、头部姿态编码作为条件信息,使用所述对抗生成网络进行图像渲染,生成当前视角及音频条件下的目标图像。
[0054]
本发明的有益效果为:
[0055]
本发明所述的一种基于音频驱动的口罩下2d人脸还原技术,来真实还原说话者的完整人脸。通过音频解耦器,有效的分离了音频中包含的内容和情感信息,避免了两者之间的干扰,有效的增强了生成人脸的真实性和自然性。通过2d建模,提取了人脸的几何特征、面部装饰和肤色特征,估计出头部的三维欧拉角度,在保证生成说话人脸效果的同时有效解决了3d建模的困难和不稳定性。
附图说明
[0056]
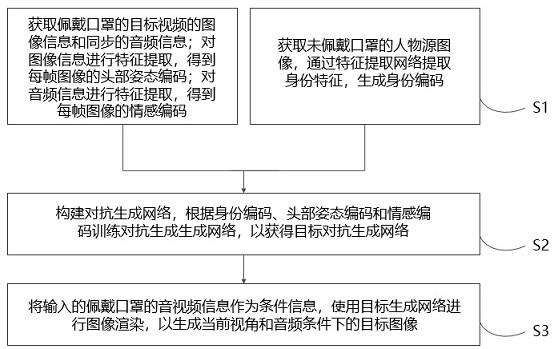
图1为本发明方法的流程图;
[0057]
图2为音频情感解耦器的训练方法;
[0058]
图3为口罩下眼部关键点提取及头部姿态估计网络示意图;
[0059]
图4为对抗生成网络示意图。
具体实施方式
[0060]
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
[0061]
本技术公开了一种实时音频驱动人脸生成方法,方法是根据一段佩戴口罩的人脸讲话视频,通过使用编码器和解码器结构的音频情感解耦器,以mobilenet回归器为骨干网络的口罩状态下头部姿态估计网络,以及对抗生成网络结构的风格生成网络,生成了高质量的基于音频驱动的口罩下人脸还原视频。
[0062]
示例性的,给定一张人物的正面、采光良好、面部无遮挡的彩色照片作为身份特征源图像。获取的目标视频为单人讲话视频,其中,目标对象佩戴口罩,视频画面颜色为彩色,视频分辨率为720p、1080p、2k或4k,帧率为30帧/秒,视频的音频码率为128kb/s,音频采样率为44100hz。在上述视频属性中,除视频时间长度和分辨率外,其他属性可根据实际情况自行设计。特征提取网络从源图像中获取身份特征,音频情感解耦器从目标视频的音频信息中解耦出情感编码,头部姿态从目标视频的图像信息中提取出头部姿态编码。最终,生成符合照片中人物身份特征,目标视频中人物无遮挡面部表情以及头部姿态的说话人脸视频。
[0063]
如图1所示,是本发明方法流程图,包括:通过交叉重构法训练得到音频情感解耦器;通过特征提取网络从源身份图像中生成身份编码;获得佩戴口罩的目标视频的图像信息,头部姿态评估网络进行特征提取,得到每帧的头部姿态编码;获得佩戴口罩的目标视频的音频信息,音频情感解耦器对音频信息进行特征提取,得到每帧的情感编码;将身份特征编码、情感编码、头部姿态编码输入对抗生成网络中,生成说话人脸视频。
[0064]
(1)获取训练视频的图像信息和所述训练视频同步的音频信息,以及目标对象的源身份图像,要求如下:
[0065]
(11)获取的训练视频为单人正面无遮挡讲话视频。视频画面颜色为彩色,视频中人物讲话时间长度不限,3至5分钟为最佳,视频分辨率为720p、1080p,视频帧率为25帧/秒,视频的音频码率为128kb/s,音频采样率为44100hz。所述视频属性中,除视频时间长度和分辨率外,其他属性可根据实际情况自行设计。
[0066]
(12)获取的目标对象的源身份图像为图片。图片颜色为彩色,分辨率720p、1080p,
图片中人物正面面对摄像头,无遮挡,光线条件良好。
[0067]
(2)在获得了训练视频的音频信息的基础上,通过交叉重构法训练音频情感解耦器,音频情感解耦器的训练过程如下:
[0068]
(21)对于所述音频信息,使用美尔频率倒谱系数作为音频表示得到音频向量;
[0069]
(211)对原始的视频音频重采样至固定采样频率;
[0070]
(212)使用重采样后的音频,计算音频的频域特征,采用梅尔倒谱系数表示。
[0071]
(22)通过动态时间规整算法拉伸或者收缩音频向量,以得到长度、内容相同但情绪不同的音频训练对{x
i,m
,x
i,n
},其中x
i,m
,x
i,n
∈x,i表示内容相同,m,n分别表示两种不同的情绪;
[0072]
(23)通过交叉重构法训练音频情感解耦器,训练得到内容编码器设置为ec、情感编码器设置为ee和解码器设置为d。
[0073]
(231)编码解码器交叉重构损失,如公式(1)。情感编码器得到x
i,m
的情感编码与内容编码器得到x
j,n
的内容编码组合,根据解码器解码后得到音频编码x'
i,n
与x
i,n
计算损失,反向传播并训练所述编码解码网络,保证情感编码与内容编码的独立性。
[0074]
l
cross
=||d(ec(x
i,m
),ee(x
j,n
))-x
i,n
||2+||d(ec(x
j,n
),ee(x
i,m
))-x
j,m
||2ꢀꢀ
(1)
[0075]
(232)编码解码器自我重构损失,如公式(2)。同一段音频的情感编码与内容编码组合,根据解码器解码后得到的新音频与原音频计算损失,反向传播并训练所述编码解码网络,保证编码的完整性。
[0076]
l
self
=||d(ec(x
i,m
),ee(x
i,m
))-x
i,m
||2+||d(ec(x
j,n
),ee(x
j,n
))-x
j,n
||2ꢀꢀ
(2)
[0077]
公开的三维关键点算法稳定性难以保证,对于设备以及算力的要求也相对苛刻,为了避免这些问题,采用二维方式建模,通过无监督学习来达到生成三维点云的目标。对应的特征提取网络与对抗生成网络的训练同时进行。
[0078]
(3)通过特征提取网络从源身份图像中生成身份编码;
[0079]
(4)为了应对口罩状态下存在大范围遮挡的情况,采用以mobilenet回归器为骨干网络的口罩状态下头部姿态估计网络来获得头部姿态编码,网络结构如图3所示。
[0080]
(41)对每帧进行人脸关键点检测,在口罩遮挡的情况下,得到眼部的二维人脸关键点。所涉及的关键点检测网络包括卷积层、瓶颈层、卷积层和全连接层;
[0081]
(42)将二维人脸关键点输入姿态估计网络,估计人脸的三维欧拉角,得到12维的头部姿态编码,包括9位旋转编码和三位偏转编码。所涉及的姿态估计网络包括卷积层和全连接层;
[0082]
(5)通过训练得到的音频情感解耦器,输入训练视频的音频信息,得到情感编码。
[0083]
(6)构建对抗生成网络,所述对抗生成网络用于生成渲染图像。根据身份编码、情感编码、头部姿态编码训练对抗生成网络,如图4所示,a为身份编码,b为头部姿态编码,c为情感编码,训练过程如下:
[0084]
(61)对抗生成网络自我评价;由于对抗生成网络采用的渐进式增长结构,对于生成器所生成的图像和训练所用的图像通过高斯平滑和亚采样获得一系列下采样图像,形成高斯金字塔,对于金字塔的每一层级n分别计算损失,反向传播训练对应分辨率的生成器网络,有损失函数
[0085][0086]
其中m表示样本数,disc为鉴别器,img
generated
为生成器生成的图像,img
real
为训练视频的图像信息;
[0087]
(62)特征提取网络的自我评价。
[0088]
(621)特征提取网络的特征评价。根据生成图像与训练视频图像在同一位置的像素点计算特征提取网络损失,反向传播训练特征提取网络,有损失函数公式(4)
[0089][0090]
其中,h为输入的训练视频图像的高度,w为输入的训练视频图像的宽度,gen表示生成图像,real为输入的训练视频图像。
[0091]
(622)特征提取网络的点云分布评价。为避免三维点云的信息冗余,根据点云u中k个点之间的欧氏距离计算距离损失函数,反向传播训练特征提取网络,有损失函数公式(5)。
[0092][0093]
(63)对抗生成网络姿态评价。计算生成人脸和训练视频图像信息对应帧中人脸的头部姿态编码之间的欧氏距离,作为姿态损失反向传播训练生成网络;
[0094]
(64)对抗生成网络情感评价。获得生成人脸和训练视频图像信息对应帧中人脸,分别提取二维关键点,得到对应的关键点集合p
gen
,p
real
,根据关键点集合p
gen
,p
real
计算情感损失,如公式(6),反向传播训练生成网络;
[0095][0096]
(7)获得目标对象佩戴口罩的目标视频的图像信息和音频信息,重复步骤3、4、5,将得到的身份编码、情感编码、头部姿态编码作为条件信息,使用所述对抗生成网络进行图像渲染,生成目标视频:
[0097]
(71)获取的条件视频为单人讲话视频。视频中人物的动作为佩戴口罩的讲话视频,视频画面颜色为彩色,视频中人物讲话时间长度不限,视频分辨率为720p、1080p,视频帧率为25帧/秒,视频的音频码率为128kb/s,音频采样率为44100hz。所述视频属性中,除视频时间长度和分辨率外,其他属性可根据实际情况自行设计。
[0098]
(72)通过特征提取网络从源身份图像中生成身份编码;
[0099]
(73)对所述图像信息进行特征提取,得到每帧图像的头部姿态编码;
[0100]
(74)音频情感解耦器对所述音频信息进行特征提取,得到每帧图像的情感编码;
[0101]
(75)将得到的身份编码、情感编码、头部姿态编码作为条件信息,使用所述对抗生成网络进行图像渲染,生成当前视角及音频条件下的目标图像。
[0102]
需要说明的是,以上内容仅仅说明了本发明的技术思想,不能以此限定本发明的保护范围,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰均落入本发明权利要求书的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1