一种基于密度聚类的乘车点推荐方法
1.本发明属于数据挖掘技术领域,具体涉及一种基于密度聚类的乘车点推荐方法。
背景技术:
2.随着互联网行业的快速发展,网约车逐渐成为人们出行的重要选择。当乘客在打车平台上发布订单时,平台系统需要为用户匹配司机并且提供乘车点,推荐乘车点的作用在于保护乘客的实时位置隐私,并且为司机和乘客提供一个安全方便的相遇点,乘车点的选择将影响司机接载乘客的效率,同时也影响乘客的等待时间、步行距离、安全性以及周边的道路拥堵情况。
3.分析现有的订单数据可以发现,由于乘车点选取得不合理,司机和乘客经常需要通过额外的电话交流来确定乘车位置,这降低了司机接载乘客的效率,影响司机和乘客的用户体验。因此乘车点推荐技术需要挖掘历史订单的乘车点位置,提供方便合理的乘车点,进而降低司机和乘客沟通成本,提高司机的接载效率。从多角度分析订单信息,造成乘车点推荐不合理的原因在于,候选点的提取聚类算法缺乏鲁棒性,针对不同区域分布的历史乘车点无法进行准确地聚类。此外,在选定乘车点的过程中没有综合考虑司机位置和目的地的驾驶距离,司机行车方向与交通管制可能导致司机不得不绕路前往乘车点或与乘客协商重新决定乘车点。乘车点推荐技术未考虑道路附近的路况将导致乘客不得不在交通拥挤的路段等待司机,这将降低司机接载乘客的效率,同时加剧道路的拥挤程度。
4.当前国外内对于时空众包的研究更多集中在路径规划和时空热度的方向,而对乘车点推荐方向则研究较少。he等人将乘车点提取过程转换成“排序问题”和“二分问题”,使用聚类算法从历史数据中提取出候选乘车点,再根据乘客前往候选乘车点的步行路程和司机的行驶路程进行加权和选择候选乘车点,候选点应尽可能减少乘客的步行距离和司机的行驶距离。guo等人使用dbscan聚类算法挖掘候选推荐点,采用轨迹点路段匹配方法,根据车辆轨迹数据的方向矢量匹配所在道路,并将与路段匹配后的轨迹点存到一个待矫正集合中,通过判断集合点前后所属路段的差异来矫正轨迹点。在每个乘车点中设置阈值,若当前该乘车点的匹配数超过阈值则不继续匹配该乘车点,从而减少该路段交通负载。为每个乘客计算其最近的两个乘车点距离综合收益,并将乘车点优先匹配给两个距离综合收益差值较大的乘客,有效解决同一时间内单个订单堆积而导致的资源浪费,提高乘车点的使用效率。tong等人,将乘客和司机的匹配问题抽象为在时空数据中在线最小二分图匹配问题。在最小二分图匹配中,贪心算法是解决该问题最简单的方法,即为每个乘客分配最近的候选乘车点和最近的司机,现有的研究主要在理论上分析在线匹配问题的最坏情况竞争比,然而贪心算法在最坏情况下竞争比为指数级。该论文验证了在现实场景中,贪心算法所得的竞争比为常数,并且能取得较好的匹配结果。此外文中还提出了基于hst-greedy、permutation、hst-reassignment的乘客与司机匹配的模型,为乘车点推荐的设计提供思路。
5.现有乘车点推荐技术可能存在一定问题,第一,所推荐的乘车点位置不具有代表
性,具体体现在推荐乘车点的技术采用的dbscan聚类算法在一定程度上不够准确,由于聚类的地域区域不同,历史订单点的分布也存在差异,使用同一个聚类模型在不同的历史数据分布上可能无法达到较好的聚类效果;第二,推荐的乘车点位置并未考虑实时路况信息,倘若推荐点附近交通拥挤,司机前往乘车点将花费较长的时间,并且接载乘客可能加剧道路拥挤;第三,乘车点推荐技术缺少对热点区域实时变化的响应,在现实场景中打车热点区域会随时间推移而变化,现有的乘车点推荐技术缺少对该变化的捕捉,推荐点缺少实时性,热点区域的乘客可能因此增加步行距离。初始化的候选点集合可能不准确,需要新的乘车点更新集合以提高推荐效果。
技术实现要素:
6.有鉴于此,本发明的目的是提供一种基于密度聚类的乘车点推荐方法,可以提高推荐的效率以及准确性。
7.一种基于密度聚类的乘车点推荐方法,包括如下步骤:
8.步骤1、整理历史订单数据,将历史订单数据中的起始点作为一个历史乘车点,根据时间将历史乘车点划分到不同的时域之中,针对同一个时域中的历史乘车点,先根据历史乘车点的经纬度计算其所属的地理网格,再对每个地理网格中的历史乘车点进行密度峰值聚类,得到的聚类中心作为候选乘车点,存储在候选乘车点集合中;
9.步骤2、当乘客发起订单时,先在订单时间所属的时域中,找到与乘客距离最近的设定数目的候选乘车点,作为推荐乘车点,再从推荐乘车点中选出一个最终推荐乘车点及对应的车辆,推荐给乘客。
10.进一步的,还包括步骤3,具体为:
11.步骤3-1:为每个候选乘车点建立一个最终选择点集合;对于候选乘车点中的最终推荐点,收集每位乘客对于同一个最终推荐点的最终选择位置,将该最终选择位置加入对应的最终选择点集合;
12.步骤3-2:根据步骤3-1得到的最终选择点集合,当满足设定条件时,将对步骤1中的候选乘车点进行一次更新,具体为:计算最终选择点集合中所有点的质心,并计算集合中到质心最近的点,定义为最终乘车点;计算最终乘车点到最终选择点集合对应的候选乘车点的距离,若距离超过设定阈值,用该最终乘车点替换该候选乘车点,更新所述候选乘车点集合。
13.较佳的,所述步骤2中,再从推荐乘车点中选出一个最终推荐乘车点及对应的车辆的具体方法为:
14.针对每个推荐乘车点,得到与推荐乘车点直线距最近的多个推荐车辆,再计算乘客到推荐乘车点的步行距离、推荐车辆到推荐乘车点的行车距离以及推荐乘车点到目的点到行车距离的加权和,取所有推荐点中和值最小的推荐乘车点及对应的推荐车辆,推荐给乘客。
15.较佳的,所述步骤2中,进行加权求和时,乘客到推荐乘车点的步行距离、推荐车辆到推荐乘车点的行车距离以及推荐乘车点到目的点到行车距离对应的权值分别为ω1、ω2和ω3,其中,ω1:ω2:ω3=6:1:1。
16.较佳的,所述步骤1中,密度峰值聚类的具体方法为:
17.计算每个历史乘车点的局部密度ρi:
[0018][0019]
其中,d
ij
表示同一个地理网格中第i个历史乘车点到第j个历史乘车点的欧式距离,i=1,2,
…
,n;j=1,2,
…
,n;n表示该地图网格中历史乘车点的数量;dc为截断距离,其确定原则为平均每个点的邻居数为所有历史乘车点数量的1%~2%;
[0020][0021]
再定义距离δi:
[0022]
在同一个地理网格中,当存在历史乘车点j的局部密度大于历史乘车点i时,将第i个历史乘车点的δi值设为所有比点i局部密度更大点中的,且与点i最近的欧氏距离;当历史乘车点i的局部密度是最大的时候,将历史乘车点i的δi值设为与它最远点的欧式距离;
[0023]
最后计算综合考虑值γi:
[0024]
γi=ρiδi[0025]
根据各个历史乘车点的综合考虑值γi,确定聚类中心。
[0026]
较佳的,所述步骤1中,在确定聚类中心时:
[0027]
根据γi的大小排序,将γi值较大的历史乘车点当作聚类中心;
[0028]
或者,将γi根据大小进行排序,以排序后的序号作为x轴,以对应的δi值作为y轴,在二维坐标系中得到曲线,将曲线上斜率大于设定阈值的点及以后的点作为聚类中心。
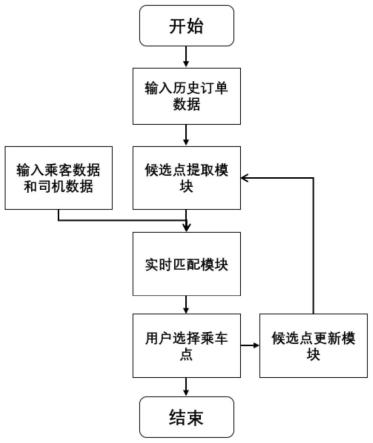
[0029]
较佳的,所述步骤1中,确定聚类中心后,在地图应用api中对聚类中心进行查询,将聚类中心中不允许停车的点剔除,剩余的聚类中心加入候选乘车点集合中。
[0030]
较佳的,所述步骤3-1中的满足设定条件为:当最终选择点集合中点的数量超过100时。
[0031]
较佳的,所述步骤2中,对于推荐乘车点,调用地图应用api获得每个推荐乘车点周边的实时路况,当实时路况为“拥挤”时,该候选乘车点删除。
[0032]
较佳的,所述步骤2中,得到与推荐乘车点直线距最近的3个推荐车辆。
[0033]
本发明具有如下有益效果:
[0034]
本发明提出的基于密度聚类的乘车点推荐方法,采用密度峰值聚类算法,该聚类算法能够避免传统聚类算法中需要手动设置参数的问题,提高了对不同分布数据的鲁棒性,能够较好地提取出不同区域的聚类中心作为候选乘车点;
[0035]
本发明还根据乘客的最终选择位置更新候选点集合,相对于传统的乘车点推荐技术,本发明的推荐点更具有实时性和准确性;
[0036]
本发明实时匹配兼顾了乘客的步行距离和司机的行驶距离,为乘客找到最合适的位置,实现乘车点推荐和司乘最佳匹配;
[0037]
在候选点匹配中加入实时路况的判断,有助于改善候选点周边的路况,提高司机的接载效率。
附图说明
[0038]
图1为本发明的方法流程图;
[0039]
图2为本发明提取候选点所用的密度峰值聚类算法流程图;
[0040]
图3为本发明实时匹配步骤的流程图;
[0041]
图4为本发明候选点集合更新步骤的流程图。
具体实施方式
[0042]
下面结合附图并举实施例,对本发明进行详细描述。
[0043]
针对上述问题,首先本发明需要改进用于推荐点提取的聚类算法,该聚类算法需要识别各种形状的簇信息,并且需要适应不同地域不同数据分布的聚类,此外为了解决了dbscan算法等聚类算法对于参数设定过于敏感的问题,该聚类算法的参数需要很容易地确定。该乘车点推荐技术将需要设计综合多因素的实时匹配机制,该匹配机制需要兼并考虑乘客的步行距离、司机的驾驶距离、道路的实况信息、地理的poi等,实现较优的全局匹配。该发明需要实现候选推荐点的更新,以解决热点区域变化问题,该方法应尽可能降低计算开销,保证系统的响应时间。
[0044]
乘车点推荐技术框架图如图1所示,主要包括候选乘车点提取模块、乘车点实时匹配模块以及候选乘车点更新模块。
[0045]
候选乘车点提取模块主要通过聚类算法从历史订单数据中得到候选乘车点。在该模块中,首先整理历史乘车点数据,将历史订单数据中的起始点作为一个历史乘车点,根据时间将乘车点划分在不同的时域之中,再根据乘车点的经纬度计算所属地理网格,通过划分地理网格减少数据聚类的计算开销,本实施例中,将每个网格的大小为500米*500米。在每个网格中进行密度峰值聚类,得到的聚类中心将作为候选乘车点,候选点将在乘车点实时匹配模块中实现乘车点、乘客和司机的实时匹配。
[0046]
乘车点实时匹配模块从候选乘车点提取模块中获得候选推荐点集合,当乘客发起订单时,先在订单时间所属的时域中,找到乘客附近距离最近的数个候选乘车点,再根据附近司机的行驶距离、乘客的步行距离、乘车点到目的点的行驶距离以及乘车点的poi(point of interesting,兴趣点是在地图上任何非地理意义的有意义的点:比如商店,酒吧,加油站,医院,车站等)和路况等数据找到最合适的位置,实现乘车点推荐和司乘匹配。
[0047]
候选乘车点更新模块用于候选点的更新。由于推荐点未必是用户的最终选择,该模块为候选点收集最终乘车点数据,并用这些数据更新候选点集合,确保候选点的实时性和准确性。
[0048]
采用所述的基于聚类的乘车点推荐技术,包括以下详细步骤:
[0049]
步骤1:提取候选点:从历史乘车点中提取出候选点位置。本发明采用基于密度峰值的快速聚类算法提取候选点,候选点是算法得到的聚类中心。
[0050]
步骤1-1:将历史乘车点根据经纬度划分网格,根据订单时间划分时域。划分网格能够降低候选点提取的计算开销,提高候选点的推荐效率,对不同时域的数据单独聚类保证了候选点在该时域内的时效性。
[0051]
步骤1-2:得到历史数据的聚类中心。根据步骤1-1所得的划分结果,对每个网格下每个时域内的数据进行密度峰值聚类,聚类算法的过程如图2所示。首先计算每个点的局部密度ρi:
[0052][0053]
其中,d
ij
表示同一个地图网格中第i个历史乘车点到第j个历史乘车点的欧式距离,i=1,2,
…
,n;j=1,2,
…
,n;n表示该网格中历史乘车点的数量;dc为截断距离,其确定原则为平均每个点的邻居数为所有历史乘车点数量的1%~2%;
[0054][0055]
再定义距离δi:
[0056]
当存在点j的局部密度大于点i时,说明点i的局部密度不是最大的,于是将δi设为所有比点i局部密度更大点中与点i最近的欧氏距离;当点i的密度是最大的时候,说明该点是中心点,于是将该点的δi设为与它最远点的欧式距离。
[0057]
聚类中心的特点在于局部密度ρi较大同时与其他局部密度较大点的距离δi也较大,因此可以对比ρi、δi的综合考虑值γi:
[0058]
γi=ρiδi[0059]
当γi较大时,该点更有可能是聚类中心,因此可以根据γi的大小排序,将γi值更大的点当作聚类中心。
[0060]
或者,将γi根据大小进行排序,以排序后的序号作为x轴,以对应的δi值作为y轴,在二维坐标系中得到曲线,从非聚类中心过渡到聚类中心时有明显的斜率变化,因此可以将曲线上斜率大于设定阈值的点及以后的点作为聚类中心。
[0061]
步骤1-3:判断聚类中心的poi是否允许停车。根据步骤1-2能够得到聚类中心,在地图应用的api中对聚类中心进行poi查询,系统内部存储禁停poi类型的集合,只有聚类中心的poi类型不属于禁停集合,该聚类中心才能加入候选乘车点集合中参与后续的匹配。
[0062]
步骤2:实时匹配,该步骤的流程图如图3所示。
[0063]
步骤2-1:根据步骤1-3得到的候选点集合,当乘客发起订单时,根据乘客的位置和时间在对应的网格和时域下查找直线距离最近的前3个候选点,组成推荐点集合。
[0064]
步骤2-2:根据步骤2-1得到的推荐点集合,调用地图应用api获得每个推荐点周边20米内的实时路况,当实时路况为“拥挤”时,该候选点不适合作为推荐点,将其从推荐点集合中去除。若集合最后为空则排除这些点,返回步骤2-1重新选择其他候选点。
[0065]
步骤2-3:根据步骤2-2得到的推荐点集合,遍历每个推荐点,得到直线距离最近的3辆车,再计算乘客到推荐点的步行距离、司机到推荐点的行车距离以及候选点到目的点到行车距离的加权和,取所有推荐点中和值最小的推荐点及车辆进行匹配,目标函数如下所示:
[0066][0067]
其中,k表示本次匹配中候选点的序号,j为订单发起的时刻,为乘客到候选点的步行距离,为司机到候选点的驾驶距离,为候选点到目的地的驾驶距离,ω1、ω2、ω3均为权重;其中,本发明根据速度倒数的比值来设定各部分的权重,人平均步行速度
约为5公里/小时,市区内的行驶速度约为30公里/小时,ω1:ω2:ω3=6:1:1,因此ω1取值0.75,ω2和ω3取值0.125
[0068]
步骤3:更新候选点集合,该步骤的流程图如图4所示。
[0069]
步骤3-1:每个候选点对应一个最终选择点集合,根据步骤2-3得到的最终推荐点,本发明将收集乘客对于同一个推荐点的最终选择位置,某个候选点作为推荐点时,乘客的最终选择位置将加入该最终选择点集合。
[0070]
步骤3-2:根据步骤3-1得到的最终选择点集合,当集合中点的数量超过100时将触发一次候选点更新,具体为:计算该集合中所有点的质心,并计算集合中到该质心最近的点,定义为乘车点;计算乘车点到该候选点的距离,若距离超过20米,说明推荐点于乘客的选择存在较大的差异,用该乘车点替换该候选点;否则说明原候选点较为满足乘客的选择,不需要进行更新。
[0071]
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1